
云计算环境下基于信任推理的服务评价方法
2011-08-10 01:51胡春华罗新星王四春刘耀
通信学报 2011年12期
胡春华,罗新星,王四春,刘耀
(1. 湖南商学院 计算机与信息工程学院,湖南 长沙 410205;2. 中南大学 商学院,湖南 长沙 410083)
1 引言
云计算环境下的服务(又称Web服务,网格服务)正成为一种基于标准技术的计算应用平台,它基于SOAP、WSDL和UDDI等一组技术标准,用户可以有效地发布、查找和使用Web服务,通过在运行时刻对其进行动态选择和组装,构建松散耦合的跨组织分布式系统协作流程,从而使得基于Web服务的相关技术获得了广泛的研究[1~3]。在实际应用中,需选择较高服务质量的服务聚合形成更大粒度的服务。随着云计算和Web Services技术的广泛应用,网络间功能相似的服务逐渐增多,基于服务质量对 Web服务进行查找和选择以提高服务组合的质量已成为热点研究问题之一[3,4]。
因此,作为服务选择中的重要考虑因素,服务质量(QoS, quility of service)评价的准确性是其选择的重要前提与基础。虽有不少关于服务QoS评价研究,但服务质量评价仍然是一个开放性问题,还存在许多值得研究的问题[5,6]。
早期研究中,大多假定服务提供者(SP, services provider)和服务消费者(SC, services consumer)给出的QoS数据都是真实可信[2,7],因而在进行服务选择时,直接使用SP发布的QoS数据(如可用性等)[8],或者采用 SC反馈的 QoS数据(例如用户评价等)[9,10],这时的服务选择主要关注如何从多维QoS中选取多目标优化的服务,而对服务的可信性考虑不足[11]。随后的研究认识到:对QoS数据真实性的假设往往很难保证:一方面,服务提供者可能为达到某种目的,发布虚假的QoS数据,以欺骗用户;另一方面,服务消费者也有可能出于某种目的,从而给出虚假反馈的QoS数据,或者受到自身因素的影响,反馈的QoS数据往往与真实情况不符合[11,12]。这些不可信的 QoS数据将直接影响 QoS评价的准确性和可靠性。虽然有较多的研究提出了如何评价与获取服务的可信性,并依据可信性来对服务的QoS进行修正,以保障服务选择得到的是真实的高QoS的服务。但如何获取与识别实体的可信度与QoS的真实性却存在很大的挑战。
为此,本文利用概率论原理来表征服务实体间的信任度,系统地给出了基于概率密度信任关系的计算、推理及合并等演化方法。具体概括为如下内容。
1) 采用改进的概率密度方法来表示实体的可信度,和其他信任表示方法相比具有如下优点。
可准确表达不同交互过程中服务实体反馈信息权重。以往研究中[14,15],服务信任度采用交易的成功与否来表示,虽然成功与否可以表示信任与不信任,但不能表示出信任程度。而实际上,同样是成功交互其可信程度并不相同,而这类研究并不能区分这种不同性。本文中采用了定量描述方法,其原则是:一次高可信性的交易可信权重值大于多次可信度不高的交易。这是与实际社会交往类似的,从一个可信度非常高的实体中得到的评价结论往往比从多个可信度不高实体中得到评价结论更加准确。因此,本文对可信度高实体返回的评价值应该给予较高的权重;反之,信任度低的服务实体评价值应给予较低的权重。本文中以信任程度的高低来标记服务交互行为的重要程度,避免了以往研究中每次服务交互行为的权重都认为相等的不足。
为获得对某个事物的信任度,在现实生活中,常需从多个渠道来获取对此事物的评价,若从多个渠道获得一致的信息越多,则对此事物所做评价结论的可靠程序越高。因此,本文采用贝塔分布的概率密度分布函数能较好地综合不同渠道的信任评价。信任模型采用概率密度函数,不但较好地描述了信任交互情况,而且依据贝塔分布概率密度的函数特征,提出了信任的累加、乘等运算法则,建立了基于概率密度计算的信任演化方法,能为较全面地刻画服务实体间的直接与推荐信任度,具有较好的普遍性。
2) 以往研究中[5,10],有些研究规定服务交互中需向信任评价方面报告信任状态,这种强制性的策略很难适应无中心的分布式服务计算环境;此外,即使这种强制性的措施可实施,也难以保证报告的可信性,因而依据这些难以保证数据的可信性,导致得到的结论也存在不少缺陷。本文中无需实效强制性的报告,从而使方法具有更广泛的适用性。
本文利用概率密度函数来表征服务实体间的信任关系,提出了基于概率密度信任关系的计算、推理及合并的演化方法,并给出了依据信任推理与QoS修正的服务评价算法。理论分析和实验结果表明该方法能有效评价服务参与者的信任度,削弱不可信的实体对服务评价的影响,提高服务选择过程的质量及准确性。
2 系统模型定义及信任值表示
本文假设服务交互的实体可将评价信息向外公布,但与以往研究不同的是,本文认为公布自己的评价信息不是强制性的,允许服务实体不公布自己的评价信息。而服务实体公布的评价信息也可让其他所有实体获取,这些公布的QoS评价信息可假设存储在公共服务中心,这与大多数前人的研究类似[11, 16]。
2.1 系统模型
集合 S P ={ sp1, sp2,… ,s pm}表示系统中的m个SP实体,称为SP实体域。
每个SP实体在向服务代理注册时,会声明自己的QoS等属性。设实体A在ti时宣称的QoS表示为

其中,u为服务质量的维数,表示不同维的质量信息,例如可用性、响应时间、用户满意度等。
所有SP实体只存储最近tw时间段内宣称的服务质量矩阵在公共平台中的存储如下:
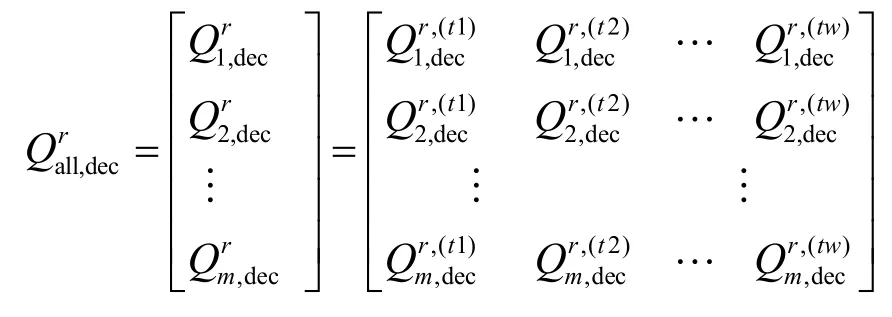
集合 S C ={ sc1,sc2,… ,scn}表示系统中的n个服务消费者实体,称为SC实体域。
与文献[15]类似,服务交互过程中的评价结果如表1所示。在表1中,服务交互的结果评价矩阵共有n行代表n个服务消费者实体,m列代表m个服务提供者SP实体。

表1 服务交互后的评价信息
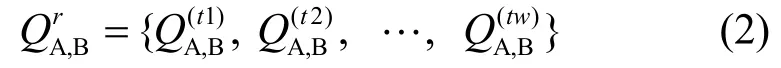
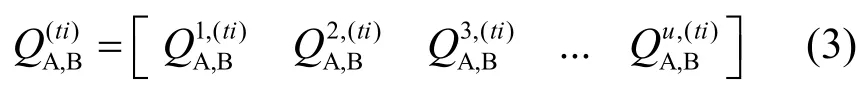
值得注意的是,在实际应用中SC实体对SP实体的QoS评价并不一定是SC实体对SP实体的真实评价,因为在复杂云计算环境下存在如下2种可能。
1) 虚假SC实体报告的SP实体QoS评价可能是虚假的,即SC实体有意提高与降低报告SP实体的QoS值。
2) 真实的 SC实体由于自身的条件限制,给出的报告并不一定真实反映了SP实体的QoS值,因此,本文承认这种评价的不真实性,也不强求SC实体必需对与其交互的SP实体做出如表1所示的评价值。
2.2 信任度量的表示方法
以往信任值的表示中,一般采用成功(成功表示可信,用T代表)与失败(失败表示不可信,用F代表)表示,信任度用 C = T /(F + T )表示,其中,T和F分别表示成功与不成功的交互次数。每次交互仅用成功与不成功来代表对实际情况过于简单化描述。在实际系统中,用户难以用成功与不成功来表示,而且在这种信任的度量表示中,每个交互实体的评价作用是相等的,但在实际中往往是信任度比较高的实体评价的结论更有可信性。
为达到以上目标,本文采用概率论中的贝塔(β,beta)分布的概率密度分布函数来表达信任的度量,能够克服以上的不足。
贝塔分布的概率密度分布函数,对任何一个给定的p,概率密度 f ( p|α, β)代表一个后验概率,即在系统的已有交互记录中,SC实体X成功执行的次数为α-1,没有成功的次数为β-1,在此基础上,估计SP实体X次成功执行的概率。
但上面的信任度量方法还不足以描述实际系统的信任关系,一般来说较为全面地反映实体的信任关系一般采用= ( b, d, u, a)来表示实体A对实体B的信任程度,这里b、d、u分别代表了信任、不信任和不确定。 b, d, u ∈ [ 0,1],而且 b +d+u=1。这里的参数a∈[0,1],它是用来计算u转换成b的概率,所以 E ()=b+au。也就说a决定了不确定性转化为信任的程度,即实际的信任度量是采用四元向量的形式来表示的,可以通过如下转换来获得[18]:
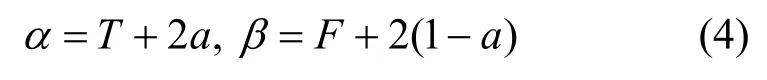
有式(4)同样就可以构造出贝塔函数。同时,利用式(4)可将信任的四元向量和 beta密度函数的参数之间做双向转换,如式(5)所示:
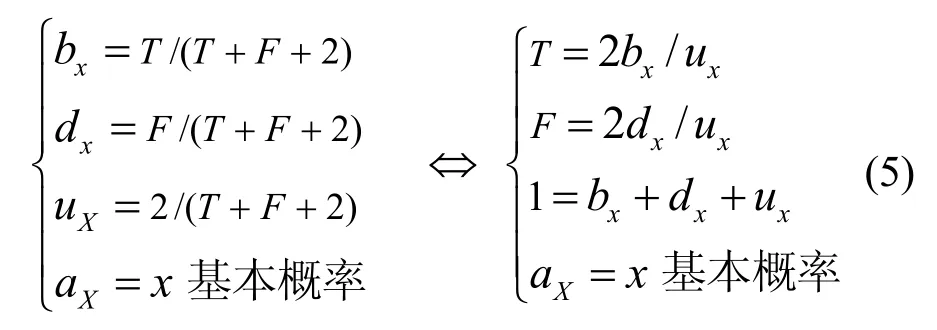
经过上面的变换,beta密度函数可以表达出交互过程中实际情况,但目前采用基于贝塔函数的信任模型还存在如下2个问题。
1) 问题1:目前的贝塔函数不能反映不同信任度的不同权重,需要对其进行改造使其能对信任度高的交互记录提高其权重,反之对信任度低的交互记录降低其权重。
2) 问题2:目前函数还不能表达时间维度对信任度的影响,SP实体本身也随时间变化,可能在不同时期其QoS与信任度都不相同。而且越是最新的交互记录越能够反映 SP实体的实际情况,其重要程度越高,这些也能在beta密度函数中反映出来。
因此,结合以上分析,提出采用如下方法来确定服务实体的信任值。
1) 对于问题1的解决方法。设基本信任度用∂表示,第i次交互过程中,得到对实体A的正向信任度为基本信任度的ki倍,即ki∂;在第j次交互过程中得到的负向信任度为gj∂。那么式(4)和式(5)中的T和F按下式计算:
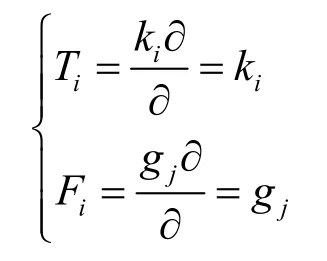
由此可看出,信任度越高的交互行为,其权重越大;越是不可信交互行为,其不可信的权重也越大,这就解决了第1个问题。
2) 对于问题2的解决方法。设在时间ti时,得到的对实体A的T的值为Ti,F的值为Fi。那么总的T与F的值如式(6)所示。
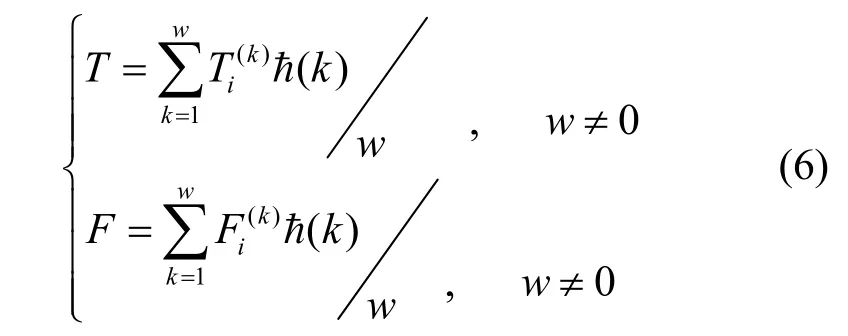
其中, ħ(k)∈ [0, 1]是衰减函数,用来对发生在不同时刻的直接信任信息进行合理的加权,定义与文献[5]中的相同,限于篇幅,此处不在赘述。
经过对贝塔函数的改进,改变了原 β ( p |α, β)密度函数,其中α+β能得到当前交互次数的信息,为了保留实体实际交互次数的信息,为贝塔函数增加参数γ,其表示实体间交互的次数,从上面论述可看出必定有α+β≥γ,这样本文使用的概率密度函数为 f ( p |α, β, γ) 。
经过以上分析,解决了信任采用的模型与信任密度表示方法,下面论述如何准确获取与判别服务实体的QoS及信任值。
3 服务间信任关系及评价
开放的云计算环境下每个服务实体都可在公共系统中发布自己的评价信息,这些信息纷繁复杂,且真假难辨。SC实体进行服务选择时,如何在云计算环境下不增加新限制(如强制信任评价提交),而根据服务间的交互作用形成 QoS与信任度的识别机制,较准确地表达实体间的信任关系以及SP实体的QoS值依然是一个重要的挑战。为此,本文提出了一种新颖的服务信任关系推理及评价方法。
3.1 SC实体对SP实体直接信任评价
本文依据服务实体间的直接交互过程从而获得了SC实体对SP实体的QoS及信任评价计算方法,从而丰富与扩展SC实体的认知范围。
3.1.1 SC实体对SP实体的QoS评价计算
首先计算SC实体对与其直接交互的SP实体的QoS评价,由于SC实体直接与SP实体进行过交互,SC实体依据自己获得QoS,从而对SP实体有一个评价值。这个评价值对SC实体自己来说是可信的,真实的(自己的评价)。下面给出SC实体对与自己直接交往的SP实体的QoS评价计算方法。
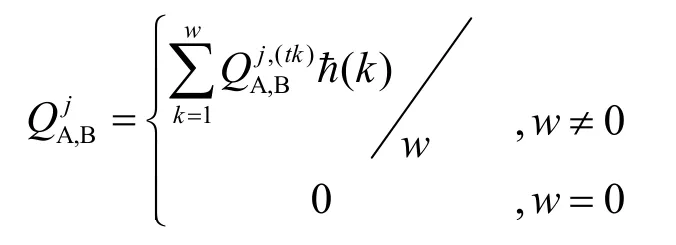
其中, ħ ( k)∈[0, 1]是衰减函数,同前面式(6)。
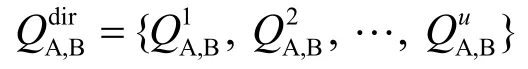
设SC实体A与z个SP实体进行过交互,因此可以得到SC实体A对这z个SP实体的QoS的评价,如式(7)所示:
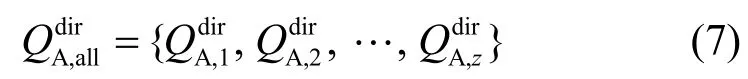
3.1.2 SC对SP实体的信任值评价计算
前面论述了SC实体对SP实体QoS的评价,下面论述SC实体对所有与其交互过的z个SP实体信任值的计算。依据前面系统模型中表1的评价信息,可知这z个SP实体在ti时刻宣称的QoS为
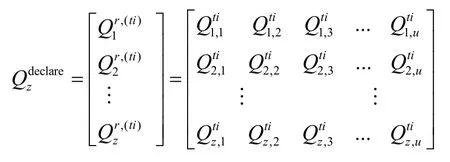
SC实体A交互得到的QoS与实体B宣称QoS的差异度用τ ( A , B, ti)表示;而SC实体A对SP实体B在ti时刻的一次交互差异度为
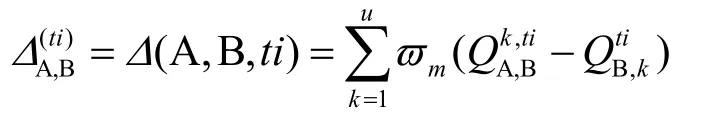
同样,计算得到差异度的比例为
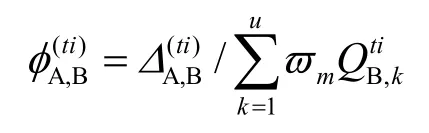
根据SC实体A得到QoS与实体B所宣称的服务质量的差异大小来决定SC实体A对SP实体B的信任度。
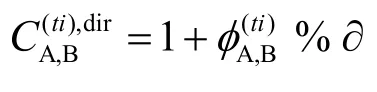
其中,∂表示梯度划分的量,%表示取模,用差异值对梯度取模表示当前SC实体A交互得到的差异值与SP实体B宣称的服务质量间相差多少梯度,若正向相差越多,表示服务越可信;而负向相差越多,表示服务虚假的程度越高。当差异的绝对值小于∂时,表示服务是可信的,计算得到的可信度为1,当负向差异值大于∂时,表示其宣称的QoS小于实体与其交互时得到的 QoS,且超过了一定限度,这时计算得到的信任值小于等于0,表示信任度较低。
从而,SC实体A与SP实体B交互过程中得到的服务评价结果存在信任评价向量。
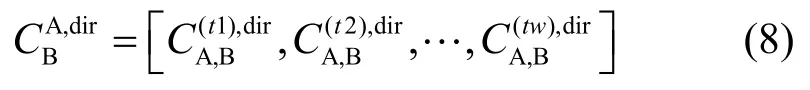
式(8)中的元素表示了SC实体A对SP实体B在不同时间的信任评价,这样SC所有与之交互的SP评价如下:
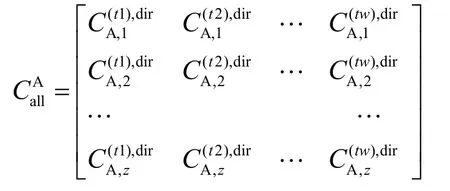
但是,上述信任模型难以进行服务的推理与运算,运算过程难以保持信任的信息。将上面的信任评价转化为概率密度函数,概率密度函数主要是确定贝塔(β,beta)分布函数中,α β值,做如下转换。
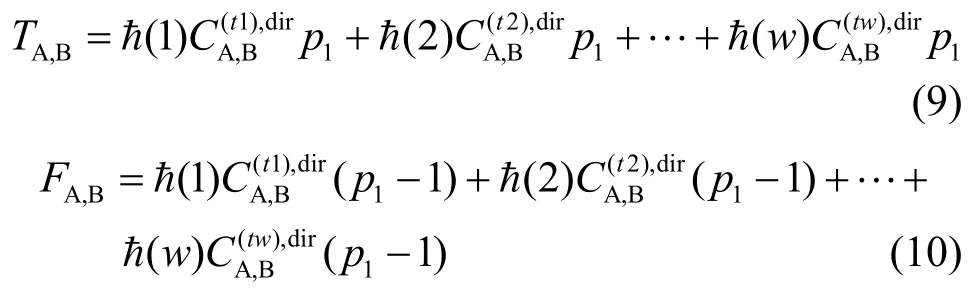
式(9)解决了较高信任度的SP实体一次交互的结果会使T成比例的增加,能使其信任度成比例的提高。式(10)导致可信度差的SP实体会使F成比例的增加,而使其信任度成比例的下降。而ħ(i)函数表示了时间因素对信任值的影响,越是新的交互结果对结果影响越大,而离现在最远的交互行为对信任值的影响权重越小,这样就解决了2.2节的2个问题。
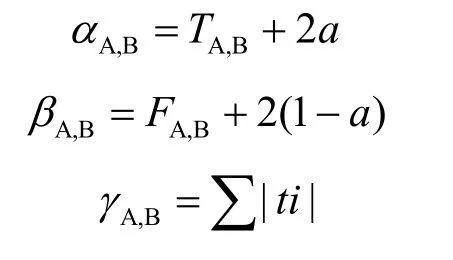
经过上面的转化方法,则SC实体A对所有交互过的SP实体的概率密度函数为
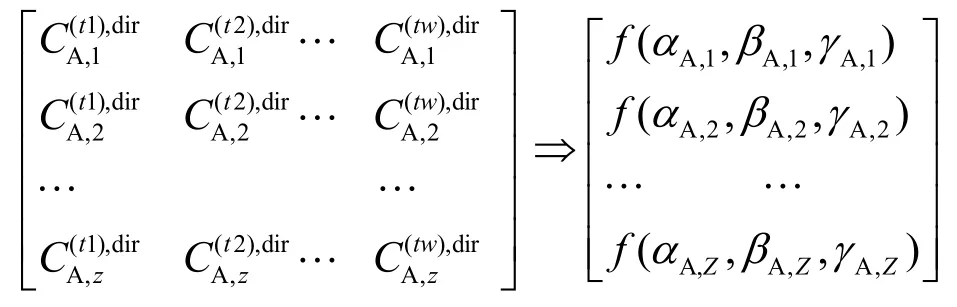
用式(10)表示SC实体A对所有交互过的SP实体的信任概率密度函数向量。
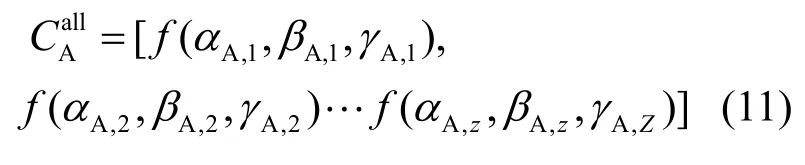
3.2 SC实体的信任度评价
这节将利用上述的信息来对其他SC实体的信任度进行评价。有了对其他SC实体的信任评价,就可扩展SC实体的认知范围,从而有利于信任推理与QoS评价的开展。
与SC实体A交互过的SP为[SP1, SP2,…,SPz],设与这z个SP交互过的SC实体个数为y个,从表1的公共平台中得到对其交互的评价记录如下矩阵:
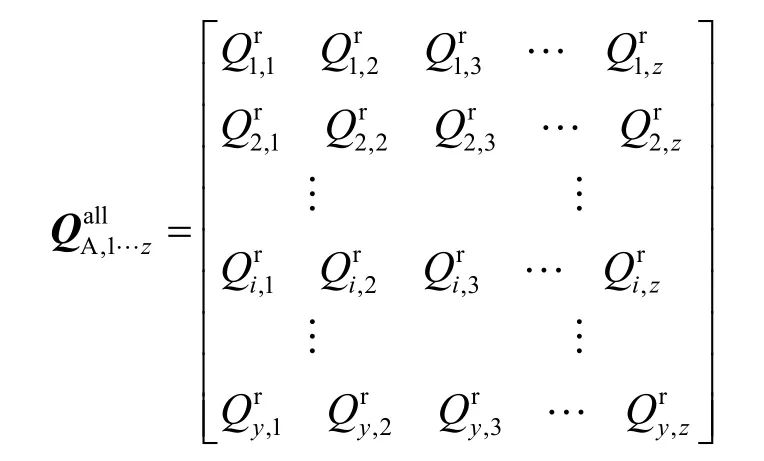
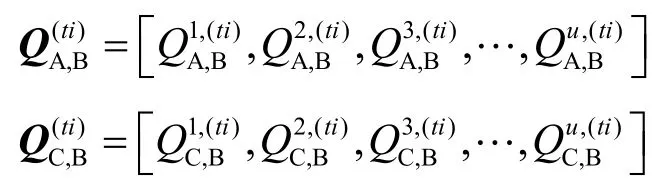
可认为第i个SC实体对自己直接得到的对第j个SP实体的QoS评价是真实的,因此,用自己得到的QoS来检测其他SC实体给出的评价是否真实。采用与前相同的方法可计算两者评价值间的差距:
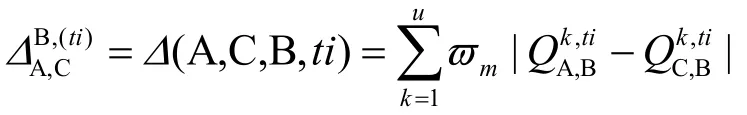
同样,计算得到差异度的比例为
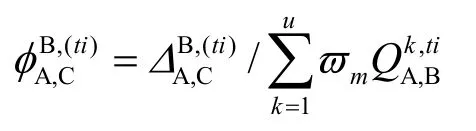
根据SC实体A得到的QoS来评价SC实体C所评价的QoS的差异大小来决定SC实体C的信任度。
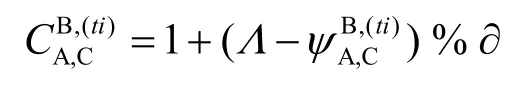
其中,∂表示梯度划分的量,%表示取模,Λ为一常数,当差异值小于此阈值常数时表示可信任,越小信任度越高;而差异值大于此阈值Δ时,则不可信,差异值越大越不可信,得到的可信度为负值。这样得到的服务信任评价结果存在信任评价向量。
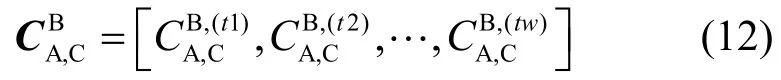
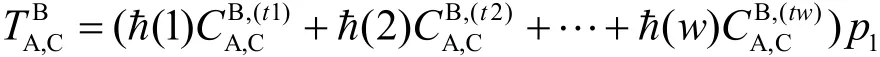
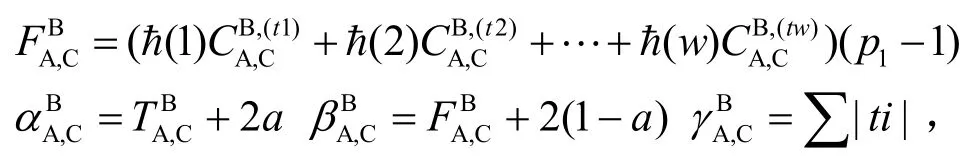
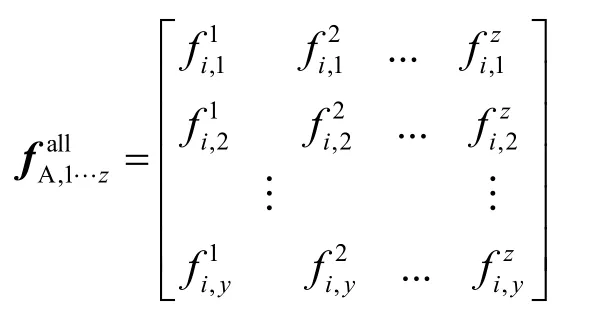
上述矩阵的第j行表示通过SC实体A依据SC实体j对z个不同的SP的评价推理出对SC实体j的信任评价值。由于beta密度函数具有很好的相加性,因此,对每行进行下面计算得到SC实体A对其他每个SC实体的总体评价值,例如SC实体A对SC实体C的计算方法如下:

这样,得到对其他SC实体的总体信任评价:
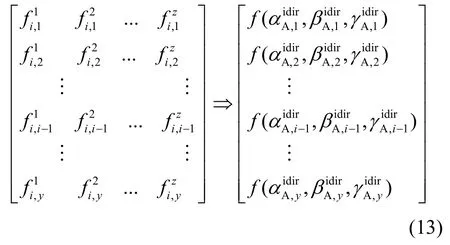
4 基于信任推理的服务评价算法
综合前面的论述,算法1给出了SC实体S对SP实体T的信任与QoS评价。
算法 1 FindBestService(SC S, SP T,int ε0,int ε1)
//算法为SC实体返回优化的SP实体T,单个实体的信任度>ε0
//算法最后输出对SP实体T的QoS评价。
第1阶段:信任计算网络图的建立与直接信任关系的计算;
1) 查找与S直接交互过的SP实体集合SP0,并按3.1.1节的方法计算出对SP0集合的QoS评价:;按3.1.2节的方法计算出对SP1集合的信任评价:
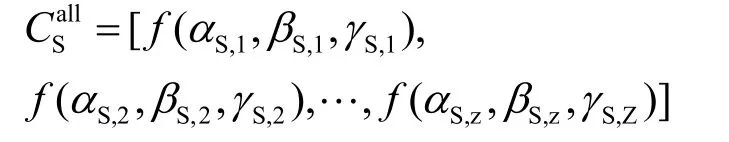
2) 查找获得与SP0交互过的SC实体集合SC0,按3.2节的方法计算出对SC0集合的信任评价。
3) 从表1中查找与建立SC0集合交互过的SP实体集合,从此集合中减去集合 SP0,得到 SP1集合。采用3.1.2节的方法计算出SC0集合对SP1集合的信任函数。
4) 查找与建立与SP1集合交互过的SC实体且不属于SC0的SC集合SC1。采用3.2节的方法计算出SC0集合对SC1集合的信任函数。
5) 反复采用第 3)和第 4)步的方法,一直递推 K次,直到推导出 SCk-1对 SPk的信任值的计算。
第2阶段:信任路径的合并
2) 对每条信任推理路径,反复采用式(13)合并得到对 SP实体的信任度。设得到的合并信任度为T.unionCredit。
T宣称的QoS为T.q,则推理得到的QoS为:T.Q=T.unionCredit*T.QoS
3) 输出:综合的QoS评价:
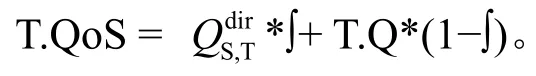
End
由于算法的运行空间只在与此服务实体相关的信任推理路径上进行,而不是全部的空间范围,因此大大减少了运算的复杂度。
5 性能分析与仿真实验
5.1 仿真实验环境设置
实验运行在本课题组前期开发并升级形成的服务组合性能评价系统SWES中,该试验系统由用户流程定制器、服务注册中心、调度算法库、试验日志组等部件构成[17]。
为检验本文提出方法的有效性,实验环境以贴近真实随机、复杂网络的实际情况为目标,设置了如下的实验网络环境,实体交互行为场景。实验中的SP与SC实体进行如下设置。
SP实体设置成如下3种类型。
1) 真实的SP实体(简称Sp(1)):该服务总能遵守所宣称的服务水平,真实对外宣称自己所能提供的服务级别。
2) 恶意且有共谋欺骗SP实体(简称Sp(2)):该服务有共谋同伙并提供虚假服务信息,实际上提供的服务质量较低。
3) 不真实的SP实体(简称Sp(3)):该服务能提供的服务水平总是小于对外宣称的服务质量,但无共谋同伙。
SC实体设置成如下4种类型。
1) 真实的SC实体(简称Sc(1)):总是给出真实的服务质量评价。
2) 恶意且有共谋欺骗SC实体(简称Sc(2)):对同伙给出较好信任评价,对其他实体给出贬低的信任评价。
3) 有共谋欺骗SC实体(简称Sc(3)):对同伙给出较好评价,对其他实体给出随机的评价。
4) 随机性SC实体(简称Sc(4)):对评价存在不确定性,有时能做出客观评价,但有时给出随意性评价。
实验中服务实体交互情况设置如下。
1) 对于Sc(1)类服务实体的交互将遵循如下原则:
对无法做出评价的 SP实体以一定概率λ与未感知网络环境进行交互,以扩展其视野。
对能获得评价的SP实体选择信任度高者发起访问请求,将低QoS与恶意SP实体排除在计算之外。
2) Sc(2)、Sc(3)和Sc(4)类实体的交互行为遵循原则为:以一定概率与网络中的服务实体随机交互,然后依据此类的评价原则做出自己的QoS评价。
实际网络的情况比以上还要复杂,但以上这网络设置情况基本概括了当前网络实体的主要情况,是符合网络实际情况的,这些可信与非可信实体的外在行为在很多情况下是非常相似的,难以区分,因而其研究极其困难。正因为难以对SP实体的QoS做出正确的评价,导致假设对SP实体QoS能够知晓的服务选择算法虽然非常完美,但是得到的结果却不太理想。
下面通过实验验证本文的策略能否区分这几类实体,以及为服务选择算法提供较真实的QoS评价,从而为服务选择研究打下基础性工作。
5.2 实验结果及性能分析
本节实验设置的SP实体总数是3 000个,其中Sp(1)类实体占80%,Sp(2)类和Sp(3)类实体各占10%。SC实体的总数是5 000,其中Sc(1)类实占60%,Sc(2)类和Sc(3)类各占10%,Sc(4)类占20%。这样设置与网络中的实际情况网络中真实的实体要大于恶意实体的比例,与实际情况比较符合。实验的交互过程是以轮(round)为单位,SC实体A在每轮中与SP实体交互的个数为10个,每轮结束后,再统计此轮中交互的情况。
图 1是从总体来说明随着交互次数增长,SC实体能够做出评价的SC与SP实体数量,从图可以看出随着交互次数的增长,SC实体A的认知也快速增长;这意味着:只要稍许增加实体的交互行为,实体能够做出QoS评价的范围增长得很多,给出评价结论的准确性也提高很多。
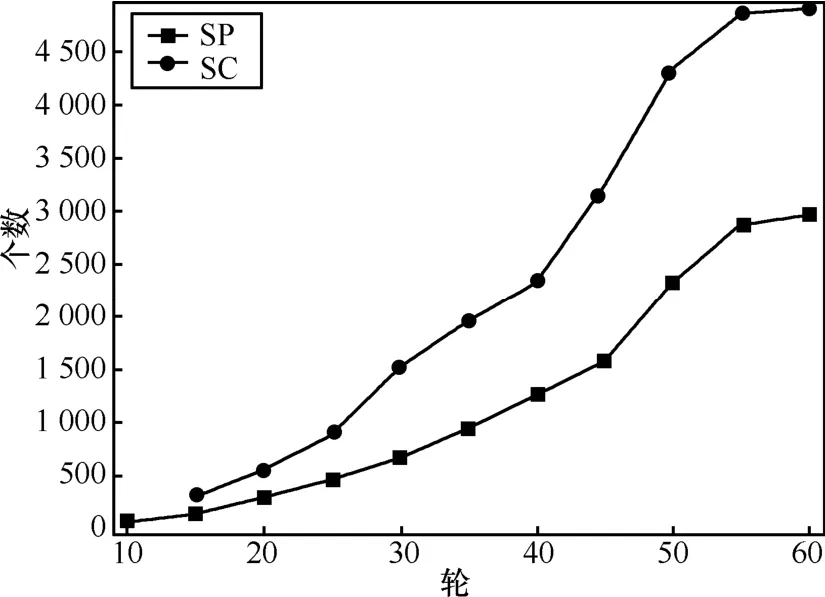
图1 交互次数与实体数量的关系
图2表示的是SC实体A随着交互次数的增长,与恶意实体交互的次数。从图中可以看出:随着交互次数的增长,与恶意 SP实体交互的次数快速减少,这也能表明在正常网络环境中,本文的策略能较好地甄别虚假服务信息。
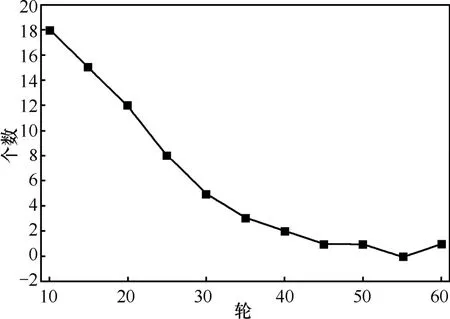
图2 SC实体与恶意实体的交互情况
图3检验的是∂取值对实体信任度的影响以及∂对Sp(1)类实体信任度的影响。∂是指SP实体宣称的QoS与SC实体交互时得到的QoS的差异值除了梯度∂得到信任度。∂越小,只要SP实体宣称的QoS与实际的QoS存在很小的偏差,则不可信。这说明对SP实体检验的要求越严格,反之,∂越大,则系统容忍 SP实体存在较大的偏差时也可信。因此,在图3中,∂允许误差达到QoS百分比上升时,对SP实体的信任度上升。可见,实体是否可信还与判断的标准相关,实际上网络中实体的QoS总是变化,任意2个实体对相同SP实体的评价不会是完全相同的,因而需要根据实际情况确定适当的∂。
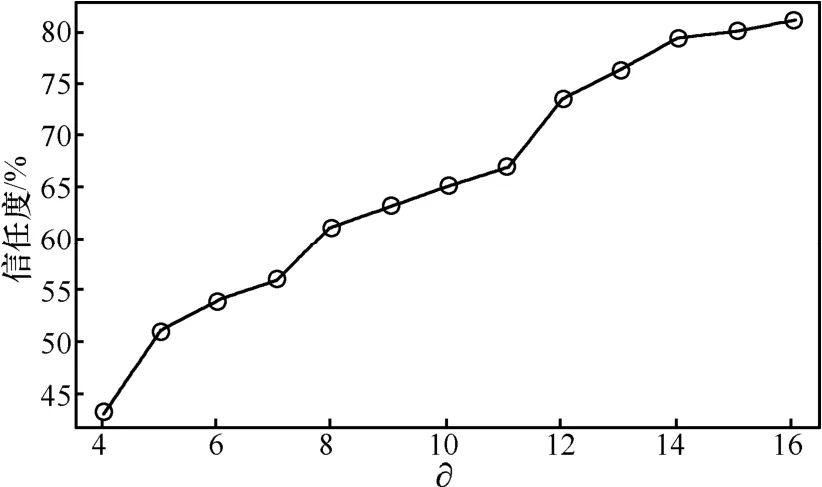
图3 ∂取值对信任度计算的影响
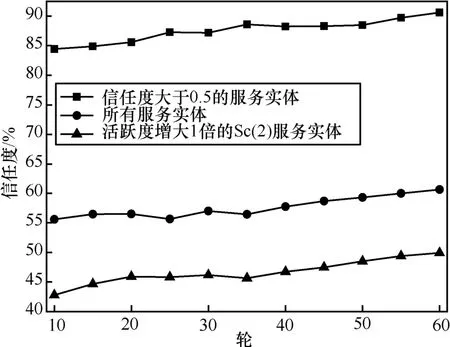
图4 不同阈值的信任值变化情况
图4是对参与信任推理加以限制与不加限制情况下,对真实Sp(1)类服务信任值的计算情况。由4图可见如果在信任推理的过程中只对信任值大于 0.5的节点参与计算,这样实际意义是只对基本可信的实体才参与信任推导。在这种情况下,Sp(1)类节点的可信度是与实际情况相符合的。如果对所有服务实体都参与计算,这时Sp(1)类实体的可信度比实际情况偏低,因为不可信节点本身是不可信的,采用其推理的结果必然是不准确的,因而得到这样的实验结果。而如果将Sc(2)类实体的活跃度提高一倍,也就是将Sc(2)类实体的交互次数增长一倍,这样得到的对Sp(1)类实体信任值更加偏低。这说明实体的信任值不仅与自己有关,也与网络的情况相关,即使网络中真实可信实体远大于不可信实体的情况下,由于真实实体保持正常的活跃程度,而恶意实体往往比较活跃,导致用户感觉到的组织间可信性远不如上述的数据。可见可信评价系统需要有限制不可信实体的机制才能保证结论的可靠性,而传统方法简单的采用交互成功与失败的比例来表征实体的可信性存在一定的局限性。
图5表示随着交互次数增多,4类SC实体信任度的变化情况。SC实体的信任度在对SP实体的评价中起到重要作用,信任度高的SC实体表示对SP实体的评价是准确可信,因而可以依据可信高的SC实体的评价来做出对未直接交互 SP实体的评价。相反,不可信SC实体的评价往往起到误导与欺骗的作用。因此,考察对SC实体的可信度识别具有同样重要的意义。
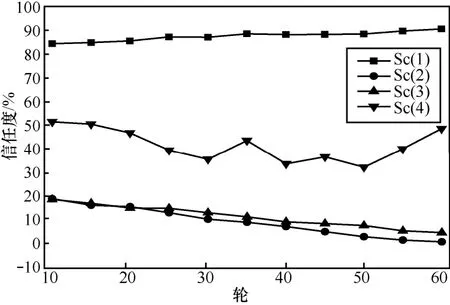
图5 不同类SC实体的可信度变化情况
从图5中还可看出,真实的Sc(1)类SC实体随着交互的进行,其信任度总体趋势是缓慢增长,而随机的Sc(4)类SC实体信任度不高,而且波动。恶意的Sc(2)类SC实体,由于对同伙与非同伙的评价都是相反的评价。在本文的策略中,如果对QoS高的实体做出低的评价,或者反之,而且给出的评价相差越大,其信任度下降得越快。因而方法很容易识别这种虚假的行为,其可信度下降得最快,恶意的 Sc(3)类 SC实体由于只对同伙做出虚假的高评价,对其他实体做出随机的评价,因而更难识别,反映在实验中就是其信任度下降不如恶意的 Sc(2)类SC实体。
6 结束语
云计算环境下服务的关系较为复杂,不可信、恶意甚至欺骗实体的真实信息常难以获得,而通过实体交互行为来判断其可信度也受到很多限制和干扰。因此,获得服务的真实QoS变得较为复杂,导致以此为基础的更高应用(如服务组合等)面临较大的挑战。为此,本文提出了一种新颖的基于QoS的服务实体信任评价方法,经过有效性验证,为复杂环境下的服务评价提供了较好的思路。
本文虽引入了贝塔分布密度函数来表征服务实体间的信任关系,具有信任间的可“加”,可“乘”等良好特性,能够综合多个信息源来对实体的可信度进行判断。但是,更细致地识别和评价服务实体间,尤其信任传递路径间的多条路径综合关系非常重要,这是下一步准备研究的工作。
[1] MICHAEL H, MUNINDAR P S. Service-oriented computing: key concepts and principles[J]. IEEE Internet Computing, 2005, 9(1):75-81.
[2] DOU W C, CHEN J, LIU J X, et al. A workflow engine-driven SOA-based cooperative computing aradigm in grid environments[J].International Journal of High Performance Computing Applications,2008, 22(3): 284-300.
[3] 冯登国, 张敏, 张妍等. 云计算安全研究[J]. 软件学报, 2011,22(1):71-83.FENG D G, ZHANG M, ZHANG Y, et al. Study on cloud computing security[J]. Journal of Software, 2011, 22(1): 71-83.
[4] ZAKI M, ATHMAN B. Reputation bootstrapping for trust establishment among Web services[J]. IEEE Internet Computing, 2009, 13(1):40-47.
[5] 胡春华, 刘济波, 刘建勋. 云计算环境下基于信任演化及集合的服务选择[J]. 通信学报, 2011, 32(7): 71-79.HU C H, LIU J B, LIU J X. Services selection based on trust evolution and union for cloud computing[J]. Journal on Communications, 2011,32(7): 71-79.
[6] 范小芹, 蒋昌俊, 王俊丽等. 随机QoS 感知的可靠Web 服务组合[J]. 软件学报, 2009, 20(3): 546-556.FAN X Q, JIANG C J, WANG J L, et al. Random-QoS-aware reliable Web service composition[J]. Journal of Software, 2009, 20(3):546-556.
[7] CARDOSO J, SHETH A, MILER J, et al. Quality of service for workflows and Web service processes[J]. Journal of Web Semantics,2004, 13(3): 281-320.
[8] OH S C, LEE D W, KUMARA R T S. Effective Web service composition in diverse and largescale service networks[J]. IEEE Transactions on Services Computing, 2008, 1(1): 15-32.
[9] ROSENBERG F, CELIKOVIC P, MICHLMAYR A, et al. An end-toend approach for QoS-aware service composition[A]. 13th IEEE International Enterprise Distributed Object Computing Conference[C]. 2009.151-160.
[10] CHEN W N, ZHANG J. An ant colony optimization approach to a grid workflow scheduling problem with various QoS requirements[J].IEEE Transactions on Systems, Man and Cybernetics Part C: Applications and Reviews, 2009, 39(1): 29-43.
[11] SURYANARAYANA G. Selection and Architecture-based Composition of Trust Models in Decentralized Applications[D]. University of California, Irvine, 2007.
[12] 潘静, 徐锋, 吕建. 面向可信服务选取的基于声誉的推荐者发现方法[J]. 软件学报, 2010, 21(2): 388-400.PAN J, XU F, LU J. Reputation-based recommender discovery approach for service selection[J]. Journal of Software, 2010, 21(2):388-400.
[13] JURCA R, FALTINGSI B. Eliciting truthful feedback for binary reputation mechanisms[A]. Proceedings of the 2004 IEEE/WIC/ACM International Conference on Web Intelligence[C]. Los Alamitos, CA: IEEE Computer Society Press. 2004. 214-220.
[14] DAMIANI E, VIMERCATI S D, PARABOSCHI S. A reputation based approach for choosing reliable resources in P2P networks[A].Proceedings of ACM conference on Computers and Communications Security[C]. New York: ACM Press, 2002. 18-22.
[15] LIMAN N, BOUTABA R. Assessing software service quality and trustworthiness at selection time[J]. IEEE Transactions on Software Engineering, 2010, 36(4): 559-574.
[16] 蒋哲远, 韩江洪, 王钊. 动态的QoS感知Web服务选择和组合优化模型[J]. 计算机学报, 2009, 32(5): 1014-1026.JIANG Z Y, HAN J H, WANG Z. An optimization model for dynamic QoS-aware Web services selection and composition[J]. Chinese Journal of Computers, 2009, 32(5): 1014-1026.
[17] 胡春华, 吴敏, 刘国平. Web服务工作流中基于信任关系的QoS调度[J]. 计算机学报, 2009, 32(1): 42-53.HU C H, WU M, LIU G P. QoS scheduling based on trust relationship in Web service workflow[J]. Chinese Journal of Computers, 2009,32(1): 42-53.
猜你喜欢
中国外汇(2019年18期)2019-11-25
环球时报(2018-01-23)2018-01-23
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
桃之夭夭B(2017年2期)2017-02-24
汽车维护与修理(2015年5期)2015-02-28
高中生·青春励志(2014年11期)2014-11-25
IT经理世界(2014年5期)2014-03-19
