
k阶Erlang分布的Pearson-χ2距离
2012-06-08 07:08季海波
淮阴工学院学报 2012年3期
季海波
(宿迁学院教师教育系,江苏 宿迁 223800)
0 引言
在数理统计中,通常使用Pearson-χ2距离来比较两个密度函数的差异性。尽管其已经不再满足距离公理中的某些条件,但是它们确实能够在某种程度上描述两个密度函数的差异程度。近年来,人们在讨论极值分布的大样本问题、分布函数的计算机模拟样本的收敛性时,都将Pearson-χ2距离作为衡量标准来判断一个密度函数列是否收敛到某个确定的密度函数。
k阶Erlang分布是排队论中常用的一个重要的服务时间分布,它与指数分布有密切的关系。若X1,X2,…,Xk是一列独立的随机变量,且都服从指数分布E(μ),则随机变量T=X1+X2+…+Xk具有概率密度:

称T服从参数为μ的k阶Erlang分布。
文献[5]中给出了两个指数分布之间的Pearson-χ2最大距离。本文着重讨论两个k阶Erlang分布的Pearson-χ2距离和Pearson-χ2最大距离,并与两个指数分布之间的Pearson-χ2距离进行比较。
1 相关定义及引理
定义1 设随机变量X、Y分别具有密度函数f(x)、g(x),且f(x)>0,若
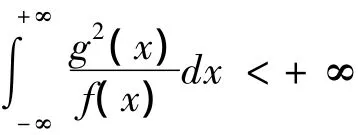
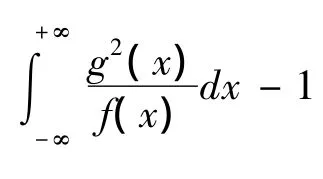
定义2 设随机变量X、Y分别具有密度函数f(x)、g(x)且f(x)>0,g(x)>0,若d2(f,g)、d2(g,f)都存在,记 d2m(f,g)=max{d2(f,g),d2(g,f)},称(f,g)为两个密度函数f(x)、g(x)之间的最大距离。
由定义可以得到如下引理:
引理1 如果函数f(x)是指数分布E(μ1)的密度函数,g(x)是指数分布E(μ2)的密度函数,那么
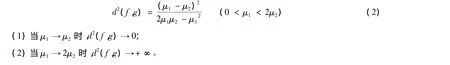
引理2 如果函数f(x)是指数分布E(μ1)的密度函数,g(x)是指数分布E(μ2)的密度函数,当<μ1< 2μ2时,则有:
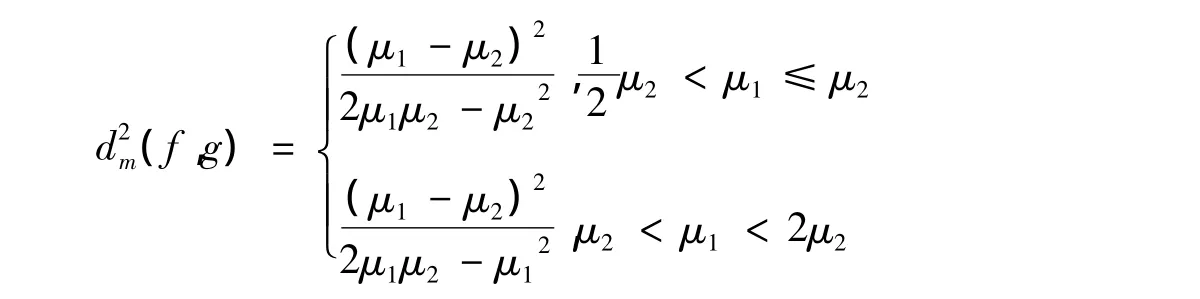
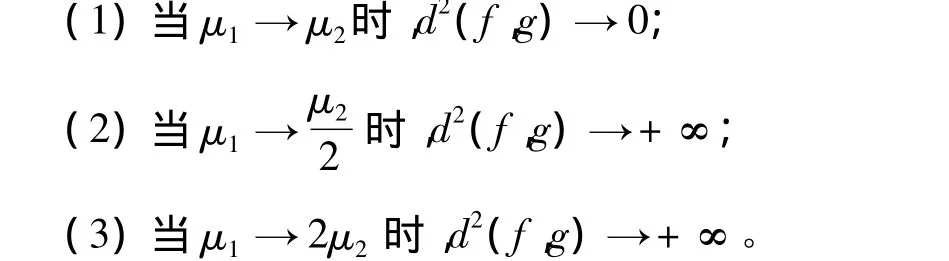
2 k阶Erlang分布的Pearson-χ2距离和Pearson-χ2最大距离

定理1 设f(x)、g(x)是分别具有参数μ1、μ2的k阶Erlang分布的密度函数,则:
证明:由于f(x)、g(x)是分别具有参数μ1、μ2的k阶Erlang分布的密度函数,则:
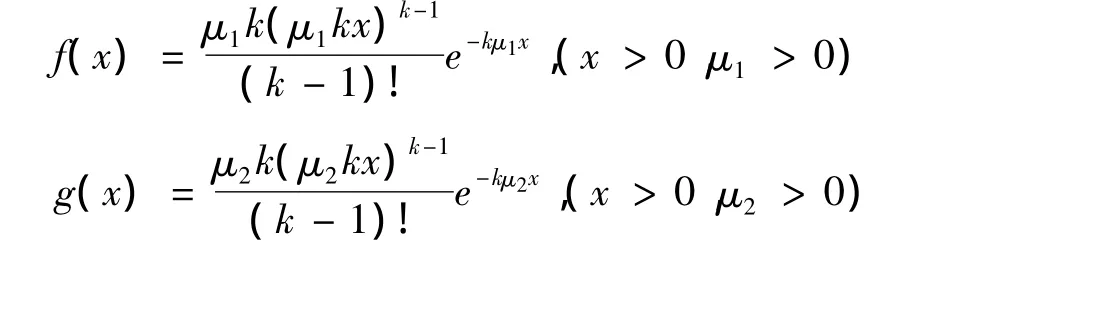
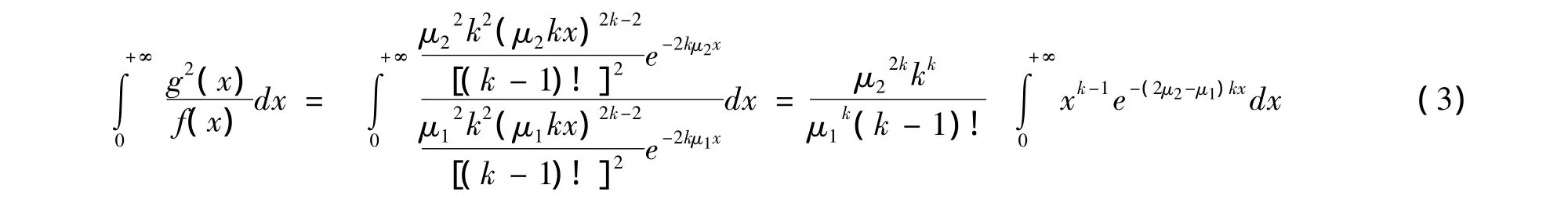
当0<μ1<2μ2时,由分部积分法可得:

将式(4)代入式(3)可得:

显然还有:
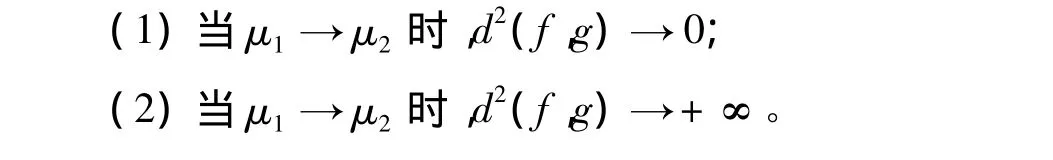
则定理1得证。
类似地还可以得到:

由引理1和定理1还可得到下面一些性质。
推论1 如果f1(x)、g1(x)分别是具有参数μ1、μ2的指数分布的密度函数,f2(x)、g2(x)分别是具有参数μ1、μ2的k阶Erlang分布的密度函数,则:
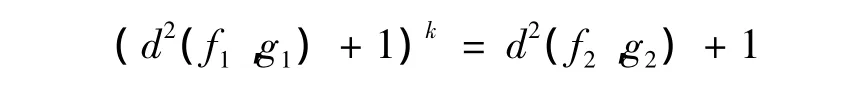
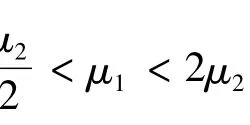

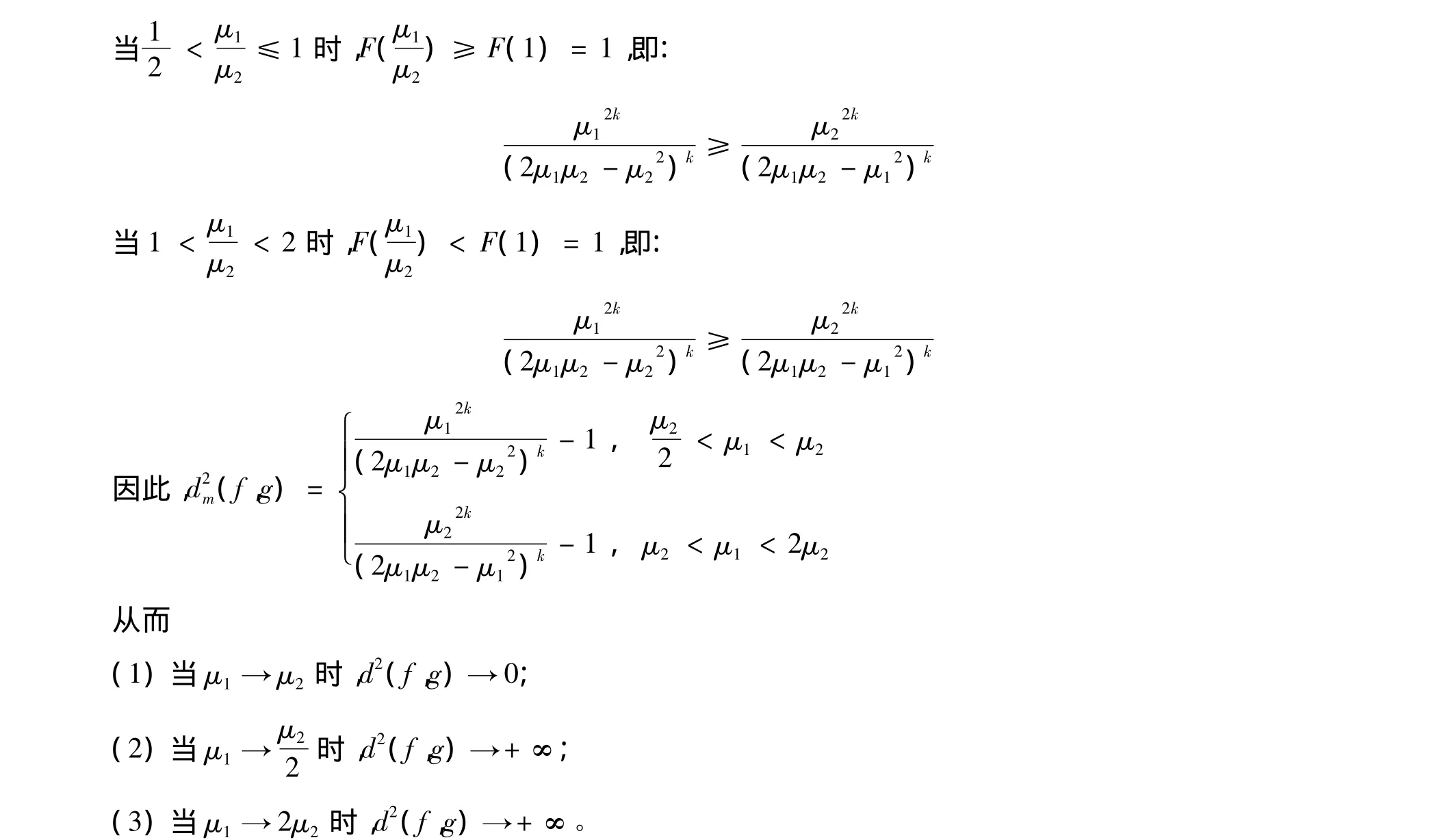
推论2 两个指数分布间的Pearson-χ2最大距离和两个k阶Erlang分布Pearson-χ2最大距离具有相同的渐近性。
[1]Robert G O,Shau S K.Updating schemes,correlation structure,blocking and parameterization for the Gibbssampler[J].J R Statist Soc B,1997,59:291-317.
[2]Liu S J,Wong W H,Kong A.Correlation structure and convergence rate of the Gibbs sampler with various scans[J].J R Statist Soc B,1995,57:157-169.
[3]Reiss R D.Approximate Distributions of Order Statistics[M].New York:Springer,1980.
[4]胡运权.运筹学基础及应用[M].北京:高等教育出版社,1986.
[5]陈光曙.Pearson-χ2的最大距离的性质[J].辽宁师范大学学报:自然科学版,2005,28(4):402-404.
猜你喜欢
华人时刊(2022年17期)2022-02-15
今日农业(2020年23期)2020-12-15
数学学习与研究(2020年15期)2020-11-28
中国医院院长(2017年21期)2018-01-19
大学数学(2016年5期)2016-12-19
大学数学(2015年5期)2016-01-28
数学年刊A辑(中文版)(2015年1期)2015-10-30
河北建筑工程学院学报(2015年2期)2015-04-29
振动工程学报(2015年2期)2015-03-01
中国卫生(2014年2期)2014-11-12
