
深部地下工程岩爆预测的筛选蚁群聚类算法*
2012-12-12 06:23张飞君
爆炸与冲击 2012年6期
高 玮,张飞君
(1.武汉大学土木建筑工程学院,湖北 武汉430072;2.武汉建工(集团)有限公司,湖北 武汉430023)
为了满足社会与经济发展日益增长的需求,我国在向空中发展的同时,地下空间的开发也不断地向深部发展。水电工程方面,西北、西南地区修建的大型水电站都普遍进入了深部,如锦屏二级水电站引水隧道埋深2 600m;金沙江溪洛渡水电站地下厂房设计最大埋深700m。在矿产资源开发方面,随着对矿产资源的需求日益增加,加上浅部矿产资源的日益枯竭,开发和利用深部矿产资源已经变得越来越普遍。而且,随着国家战略能源储存工作的发展,深部能源战略储存也是我国必须开展,同时又是富有挑战性的综合性研究课题。
深部地下工程面临的一个主要问题就是岩爆,岩爆是高地应力下地下工程施工中必然要遇到的一种动力失稳工程灾害[1]。岩爆研究的核心问题就是其发生程度的预测,目前在岩爆预测领域比较实用的技术是基于工程资料类比的方法。分析工程类比法可以发现该法的实质就是聚类分析,目前采用聚类分析进行岩爆预测已经有了不少研究[2-5],其中,采用仿生聚类方法——蚁群聚类算法是一条较好的途径[5]。但传统的蚁群聚类算法搜索效率不高,严重影响了其使用效果,为了提高聚类算法的计算效率,对传统的蚁群聚类算法进行改进,提出一种筛选蚁群聚类算法,并把该算法用来解决岩爆预测问题,提出一种岩爆预测的新方法。
1 筛选蚁群聚类算法
筛选蚁群聚类算法的基本思想为:在初始化阶段N 个数据被随机地划分为K类。每个初始化的数据类中必定存在一些和本类其他数据相似性比较低的数据,这些数据都被一一筛选出并且放置到他们各自最适合的数据类中去。最终,各个数据堆中的数据呈现出下面的属性:同一个数据堆中数据属性的差异要比不同的数据堆中数据的属性差异小得多。算法的实现过程如下:
(1)初始化。所有N 个数据被随机分配到K(K≤N)个数据堆中。
(2)迭代。在迭代开始时,蚂蚁被随机分配到一个数据堆,并且这个数据堆作为蚂蚁第一个访问的数据堆。每只蚂蚁在算法中都走Nc,max步来一个个地访问数据堆,在此过程中,蚂蚁所访问到的每个数据堆中最不属于此数据堆的数据都被筛选出来并被放到他们最适合的数据堆中去。
在迭代过程中,每只蚂蚁都遵循如下原则:
(1)如某只蚂蚁访问某一个数据堆,而这个数据堆仅含有一个数据,那么这个数据被蚂蚁以概率1拾起并放到它最适合的数据堆中去。
(2)如某蚂蚁未负载,它当前访问的数据堆中数据不止一个,那么计算当前数据堆中所有数据oi的“局部密度”(即该数据与堆中其他数据的相似性),蚂蚁以概率拾起该堆中最不适合的数据并随机地访问下一个数据堆。
每个数据oi在当前数据堆中的局部密度由下式表示
人脸匹配技术能够对各个交通路口进出学校的行人进行检测,并通过人脸对身份进行识别,通常用于检测某个人在哪里出现,用于考勤或者是定位嫌疑人的移动轨迹。
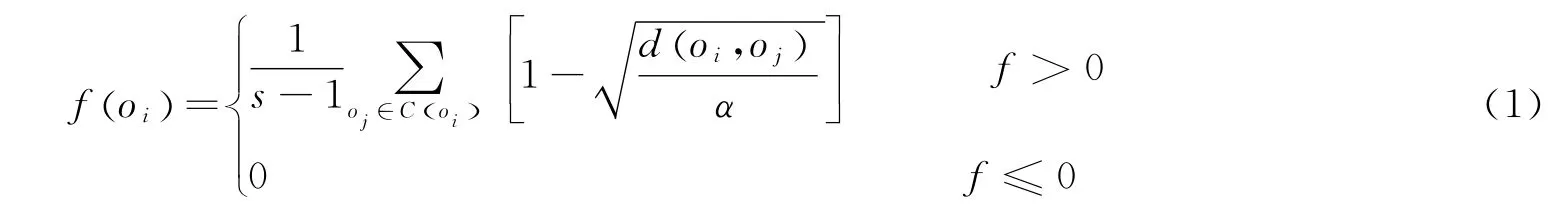
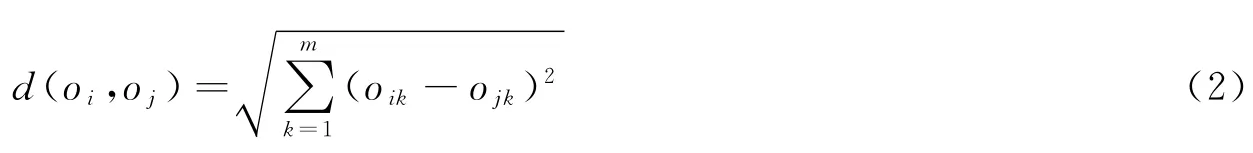
式中:m为属性个数;α是为调节数据对象间相似性的参数,同时它也决定了聚类的数目和收敛的速度。α越大时,对象间相似程度越大,会使不太相同的对象归为一类,其聚类数目越少,收敛速度也越快。反之,α越小,对象间相似程度越小,在极端情况下可能将一个大类分成了许多小类,同时聚类数目增多,收敛速度变慢。因此,实际计算中应该根据实际问题通过经验或试算进行合理确定。
当前数据堆中数据oi被筛选出来的概率如下式表示

式中:kp是一个拾起数据对象的阈值。如果则pp≈1,那么,蚂蚁将很有可能拾起这个与堆中其他数据都不相似的数据。类似地,如果则pp≈0,这表明该数据对象oi与堆中的其他数据都很相似,那么,该数据对象被拾起的概率很小。
(3)如果某负载数据oi的蚂蚁访问一个至少包含一个数据的数据堆,那么蚂蚁首先放下其负载的数据,把它加到当前的数据堆中,而后该堆中所有数据的局部密度都被计算出来,最后与堆中其他数据最不相容的数据将被以概率拾起。随之,蚂蚁负载这个新选择的数据继续访问下一个数据堆。
(4)如果某一蚂蚁负载一个数据走完了Nc,max步仍找不到能包容该数据的数据堆,那么在蚂蚁的第Nc,max步,蚂蚁把该数据放到一个新的数据堆中去。
尽管蚂蚁在迭代过程中严格遵循了上述的各条规则,由蚁群产生的聚类数可能还是要多于实际的类数目,那些原本应该在同一个堆中的数据也可能被分散到不同的数据堆中去了。为了克服这一缺点,在算法中加入了一个数据堆的合并机制,即在蚂蚁把它访问的当前数据堆中最不相似的数据挑选出来之前,蚂蚁先把当前堆与现在已有的其他数据堆相比较,而后以一定的概率合并相似的数据堆。
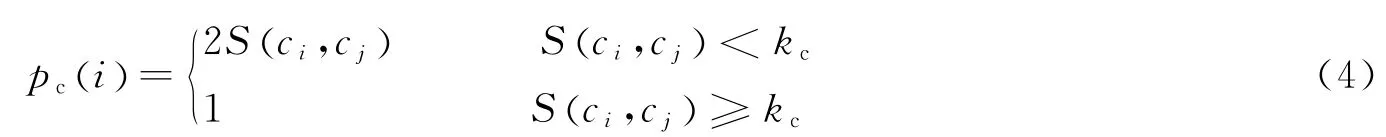

式中:dcicj是数据堆i和j中心的欧氏距离,ci为数据堆i的中心,cj为数据堆j的中心;α1是一个衡量数据相异度的参数,kc是一个阈值常数。
2 工程实例
岩爆是煤矿深部生产中常见的动力灾害,岩爆的预测一直是矿井灾害预测中的难点。影响矿山岩爆的因素是多样而复杂的,在建立模型列举的影响因素时必须具有代表性,各影响因素应尽可能相互独立或相关系数较小,同时影响因素数据应尽可能易于获得。通过对深部煤矿地下工程中岩爆发生条件的分析,基于大量相关研究,遵循重要性、独立性和易测性原则,并考虑工程中的实际应用性,同时考虑到实际工程经验,并综合煤矿开采引发岩爆的原因和结果的实际情况,这里把影响煤矿地下工程发生岩爆的因素归纳为9项。各指标的量化参考国家标准和行业规程确定,也可参考前人的研究成果确定[6],只要各类比工程的量化标准相同即可。其分类和量化标准见表1。

表1 岩爆影响因素Table 1 Influence factors of rock burst
根据文献[7]提供的25个实例进行研究,工程实例汇总如表2所示。
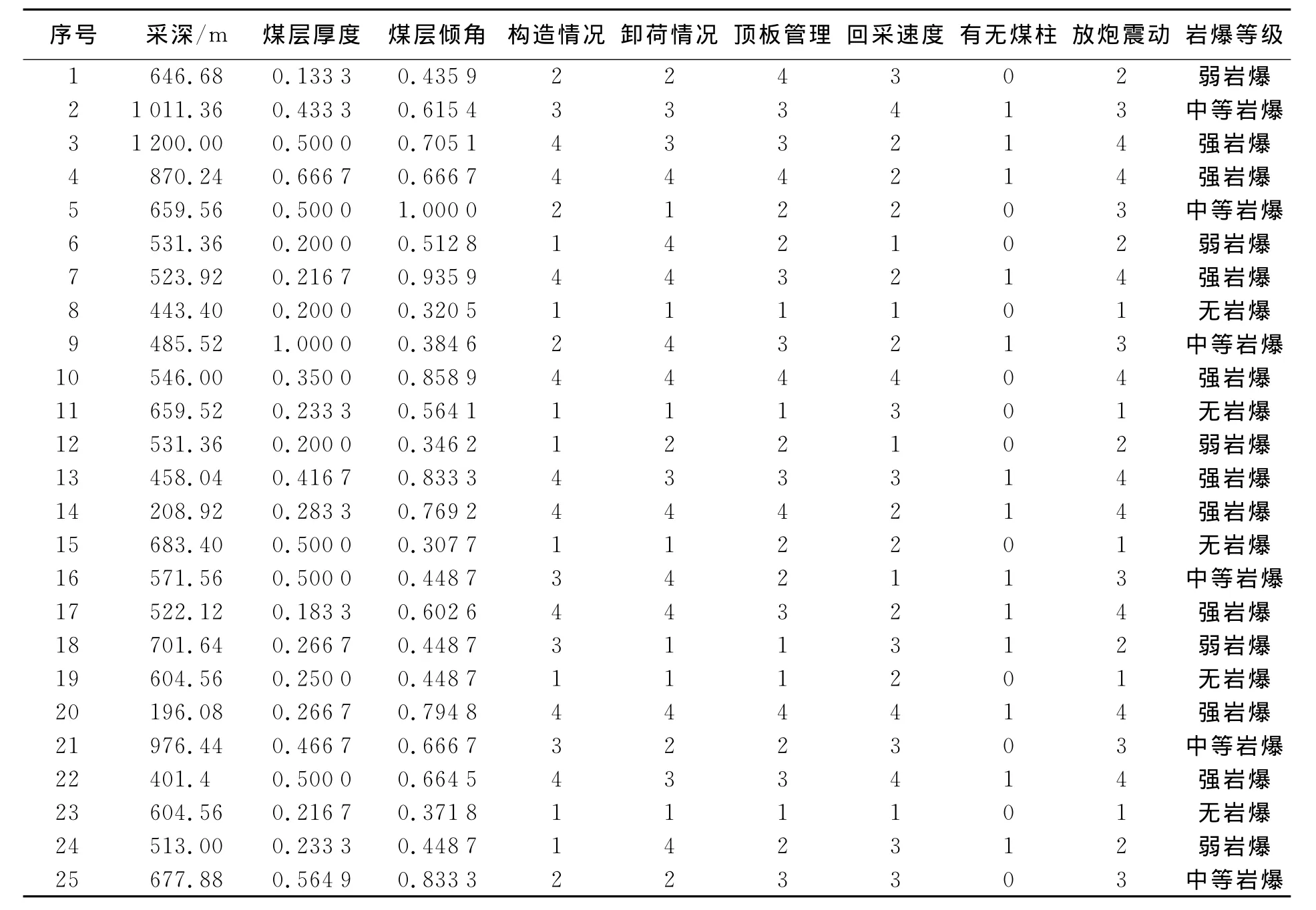
表2 岩爆工程实例Table 2 Engineering examples of rock burst
由于原文献没有列出具体各实例的煤层厚度及倾角的实际数值,本文中只能采用文献中实际数值除以最大值得到的处理值。另外,为了量化岩爆等级,计算中以1、2、3、4分别表示无岩爆、弱岩爆、中等岩爆、强岩爆等4级岩爆。
把表2中的实例样本代入筛选蚁群聚类算法进行计算,计算中的算法参数取值如下:Nc,max=5 000,kp=0.15,kc=0.2,α=0.5,N=10,α1=0.4。
为了便于比较,现把传统蚁群聚类算法也应用于这个工程实例,传统蚁群聚类算法的参数设置[5]如下:Nc,max=5 000,N=10,kp=0.1,kd=0.15,α=0.5,s=3。
在这些条件下进行计算,分类结果如表3所示。由表3可以发现,传统蚁群聚类算法和筛选蚁群聚类算法的计算结果同实际情况均基本相同,其中,传统蚁群聚类算法的正确率达88%,筛选蚁群聚类算法的正确率达92%,说明2个算法都可以很好地进行岩爆预测,但筛选蚁群聚类算法的正确率更高。
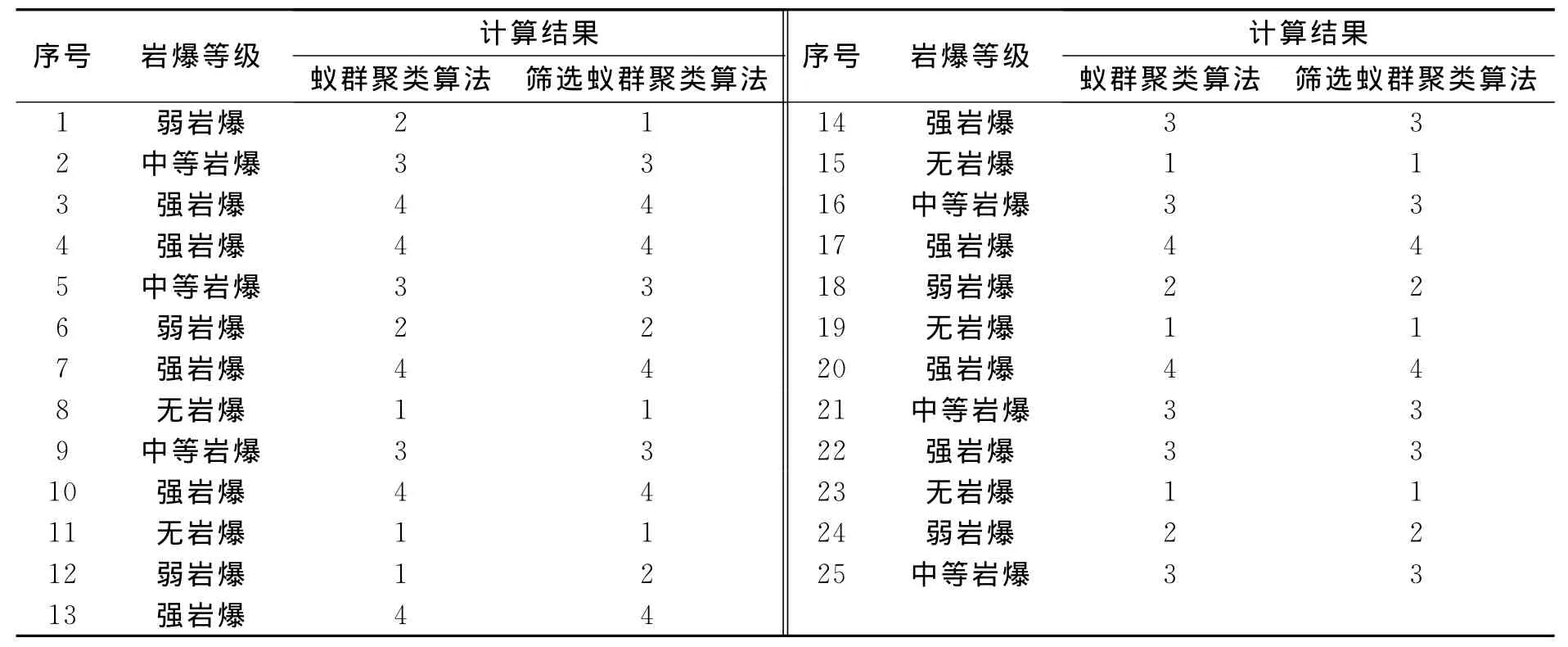
表3 计算结果Table 3 Computing results
为了比较2个算法的计算效率,这里以每种算法独立运行10次的平均值进行对比,其计算结果如表4所示,表中n为运算次数,t1为蚁群聚类算法运算时间,t2为筛选蚁群聚类算法运算时间。通过表4的比较可以发现,筛选蚁群聚类算法比传统蚁群聚类算法的计算速度有较大幅度的提高,其计算时间缩短近40%,说明筛选蚁群聚类算法的计算效率有了很大的提高,适合于解决复杂的大型工程问题。
由表3和表4可以发现,筛选蚁群聚类算法不但计算的准确性更高,聚类效果更好,而且,计算速度更快,计算效率更高,因此,筛选蚁群聚类算法是解决复杂工程岩爆问题的较理想方法。
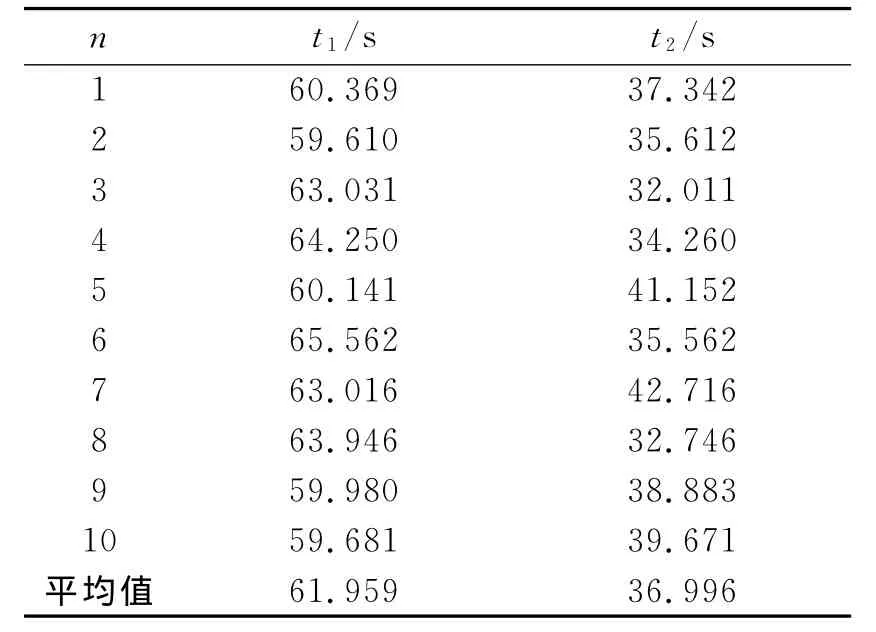
表4 计算速度比较Table 4 Comparison of computing speed
3 结 论
深部地下工程的岩爆预测问题意义重大,实际工程中基于聚类分析的工程类比法是一种常用的方法。由于岩爆发生因素的极端复杂性,聚类问题是一个非常复杂的模糊、随机优化问题,为了解决该问题,采用一些新型的聚类方法非常必要。蚁群聚类算法是一种新近提出的仿生优化算法,可以解决很多传统算法难以解决的复杂聚类问题。但传统蚁群聚类算法的计算效率低是阻碍其工程应用的主要问题,为了解决这个问题,提出了一种筛选蚁群聚类算法,并把该算法引入岩爆预测领域,提出一种岩爆预测的新方法。通过深部煤矿开采岩爆工程实例的计算,证明了新算法不但计算效果更好,而且计算效率更高,是一种很好的工程岩爆预测实用方法。由于该算法在岩爆预测中是初步应用,算法本身还有需要深入研究的地方,且工程应用也比较少,这些都是下一步要进行的工作。
[1]Board M,Fairhurst C.Rockbursts:Prediction and control[M].London:Institution of Mining and Metallurgy,1983:150-190.
[2]陈海军,郦能惠,聂德新,等.岩爆预测的人工神经网络模型[J].岩土工程学报,2002,24(2):229-232.CHEN Hai-jun,LI Neng-hui,NIE De-xin,et al.A model for prediction of rockburst by artificial neural network[J].Chinese Journal of Geotechnical Engineering,2002,24(2):229-232.
[3]祝云华,刘新荣,周军平.基于v-SVR算法的岩爆预测分析[J].煤炭学报,2008,33(3):277-281.ZHU Yun-hua,LIU Xin-rong,ZHOU Jun-ping.Rockburst prediction analysis based on v-SVR algorithm[J].Journal of China Coal Society,2008,33(3):277-281.
[4]冯夏庭,赵洪波.岩爆预测的支持向量机[J].东北大学学报:自然科学版,2002,23(1):57-59.FENG Xia-ting,ZHAO Hong-bo.Prediction of rockburst using support vector machine[J].Journal of Northeastern University:Natural Science,2002,23(1):57-59.
[5]高玮.基于蚁群聚类算法的岩爆预测研究[J].岩土工程学报,2010,32(6):874-880.GAO Wei.Prediction of rock burst based on ant colony clustering algorithm[J].Chinese Journal of Geotechnical Engineering,2010,32(6):874-880.
[6]徐凤银,王桂梁,龙荣生.模糊聚类分析在矿山地质构造划分中的应用[J].阜新矿业学院学报,1991,10(2):30-35.XU Feng-yin,WANG Gui-liang,LONG Rong-sheng.An application of fuzzy clastering analysis in coal mine classifying of geology structure[J].Journal of Fuxin Mining Institute,1991,10(2):30-35.
[7]裴磊,杨子荣.RBF神经网络在岩爆预测上的运用[J].煤炭技术,2008,27(3):137-139.PEI Lei,YANG Zi-rong.Prediction forecast of rockburst based on RBF neural network[J].Coal Technology,2008,27(3):137-139.
猜你喜欢
交通世界(2022年11期)2022-05-11
有色金属(矿山部分)(2021年4期)2021-08-30
铁道建筑技术(2021年4期)2021-07-21
铁道建筑技术(2020年11期)2020-05-22
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
制导与引信(2015年1期)2015-04-20
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
