
几种CUDA加速高斯滤波算法的比较
2013-07-22 03:03刘进锋
计算机工程与应用 2013年23期
刘进锋
宁夏大学 数学计算机学院,银川 750021
几种CUDA加速高斯滤波算法的比较
刘进锋
宁夏大学 数学计算机学院,银川 750021
1 引言
图像滤波是图像处理时常用的方法。图像滤波总体上讲包括空域滤波和频域滤波。频域滤波需要先进行傅里叶变换至频域处理,然后再反变换回空域还原图像。空域滤波是一种邻域运算,即输出图像中任何像素的值都是通过采用一定的算法,根据输入图像中一定邻域内像素的值得来的。如果输出像素是输入像素邻域像素的线性组合则称为线性滤波(例如最常见的均值滤波和高斯滤波),否则为非线性滤波(中值滤波、边缘保持滤波等)。线性滤波器使用连续窗函数内像素加权和来实现滤波,特别典型的是,同一模式的权重因子可以作用在每一个窗口内,也就意味着线性滤波器是空间不变的,这样就可以使用卷积模板来实现滤波。高斯滤波函数[1-2]为其中x,y是坐标值,σ是正态分布的标准偏差。这个公式生成的曲面的等高线是从中心开始呈正态分布的同心圆。滤波时中心像素的值有最大的高斯分布值,所以有最大的权重,周围像素随着距离中心像素越来越远,其权重也越来越小。这样进行处理比其他的均衡滤波器更好地保留了边缘效果。
近十年来,计算机图形处理器(Graphics Processing Unit,GPU)由原本只是处理计算机图形的专用设备发展成为高并行度、多线程、多核的处理器。目前主流GPU的运算能力已超过主流通用CPU,从发展趋势上来看将来差距会越拉越大。GPU卓越的性能对开发GPGPU(使用GPU进行通用计算)非常具有吸引力。统一计算设备架构(Compute Unified Device Architecture,CUDA)是NVIDIA公司推出的一种通用的GPU编程模型[3],它使得通用计算过程不必再像过去的GPGPU那样必须将计算映射到图形API中,也就不需要学习艰涩的显示芯片指令,因此开发门槛大大降低。目前,基于GPU的通用计算成为高性能计算领域的热点研究课题[4]。某些图像处理对实时性要求很高,如何将GPU所提供的强大并行计算能力运用到实时图像处理中,成为一个很有意义的研究课题。
目前,基于CUDA的GPU加速图像滤波的研究有不少成果。
盒型滤波器(boxFilter)将输入图像每个像素点用周围像素平均值代替得到输出图像。文献[5]给出使用滑窗技术实现快速盒型滤波器的方法。中值滤波是平滑与去噪应用中常用的技术,文献[6]利用CUDA实现了无分支向量化中值(BVM)滤波器。实验表明,使用该方法消除环状伪影时处理速度是优化了的基于CPU的方法的3.7倍。文献[7]介绍了两种基于CUDA加速的图像滤波方法,其中直观的实现方法是一个线程将相应位置处与滤波核大小相同的图像元素拿出来和滤波核做乘加计算,产生一个输出像素,多个线程并行处理并输出该图像块的滤波结果。另外一种是分离滤波器方法,将二维滤波分离为两次一维滤波,即分两趟处理。Nvidia提供了CUDA加速的CUFFT库[8],利用该库可方便高效地实现频域滤波[9]。此外,Nvidia的SDK提供了CUDA实现递归高斯滤波器的方法[10]。
这些CUDA加速的图像滤波方法有的描述不清楚,也没有人对这些算法的性能进行详尽的比较,这样就给理解及应用中如何选择这些算法带来了困难。这些算法应用场合不完全相同,其中很多算法可用于高斯滤波。研究CUDA加速的高斯图像滤波有很好的代表性。本文描述了几种CUDA加速的图像高斯滤波算法,包括直观的实现方式、使用共享内存的分离滤波器方法、使用纹理内存的分离滤波器方法、基于CUFFT的卷积滤波以及递归高斯滤波器。强调了这些算法的核心思想,比较了它们的时间复杂度,通过实验对它们的性能进行了分析。本研究成果对于理解及选择合适的CUDA加速的图像高斯滤波算法有较高的参考价值。
2 几种基于CUDA的图像高斯滤波方法
2.1 直观的实现方法
总体上,该方法使用高斯函数生成高斯核,然后使用该核对图像做卷积。离散的高斯卷积核 H的计算方法其中 σ为方差,k为核矩阵的半径。比如:取k=1,σ=1,即可得到3×3的高斯卷积核如下:

进行加权滤波,权系数之和必须为1,对上面所求出的高斯滤波核函数进行归一化后:

不同要求的其他高斯卷积核可以同法得到。
直观的CUDA加速高斯滤波的具体实现方法是将高斯滤波核存储在常量内存,将图像划分为多个块[7],一个线程块加载图像的一块到共享内存,对该块滤波。该线程块中,一个线程将共享内存相应位置处与滤波核大小相同的图像元素拿出来和滤波核做乘加计算,产生一个输出像素;多个线程并行处理并输出该图像块的滤波结果。调入共享内存的图像块边缘像素在与滤波核做计算时,会依赖不在共享内存中的像素。因此,在要做滤波计算的图像块周围,需要一圈滤波器半径宽度的像素“围裙”。这样每个线程块既要加载需要滤波的像素,又要额外加载围裙像素到共享内存。如果每个像素加载到共享内存都需要用一个线程,那么加载围裙像素的线程在滤波器计算期间会处于空闲状态。如果滤波器的半径较大,空闲线程的比例就较大,这浪费了GPU大量的并行计算能力,显然,这种方式性能不会好。
2.2 基于CUDA的分离滤波器
通常二维卷积滤波器要为每个输出像素做W×H次乘法;W和H是滤波器核的宽度和高度。分离滤波器是将二维滤波器表达为两个一维滤波器,一个作用于图像的行,另一个作用于图像的列。分离滤波器只需为每个输出像素做W+N次乘法。比如对图像做二维滤波,与先做一维滤波,再做[- 1 0 1]一维滤波的效果一样。
分离滤波器在执行时可提供更多的灵活性,另外也减少了计算复杂度和计算每个像素点需要的带宽。只有一部分二维滤波器可分离为两个一维滤波器,高斯滤波器核是可分离的。
2.2.1 使用共享内存实现分离滤波
基于CUDA的分离滤波器方法是将二维滤波分离为两次一维滤波[7],即分两趟处理,每趟一维滤波将需要处理的图像块首先加载到共享内存后再做滤波计算。由于一维滤波计算边缘像素时需要的“围裙”像素较少,因此可以减少不必要的数据加载量。
实际上,程序在处理时,更多的是受到线程块大小的限制,而不是共享内存的大小。为了达到更高的效率,每个线程必须处理多个输出像素。分离滤波的方法能更灵活地增加单个线程块所处理图像块的宽度,这会带来显著的性能改进。
设备内存的带宽理论上远远高于主机内存。为了实现高内存吞吐量,GPU会尝试将多个线程访问合并为单个内存事务,这称为内存合并优化(Coalescence)。如果一个warp中所有的线程(32个线程)同时读取连续的字,GPU可以用优化方式读取内存,加块内存访问速度。如果读取32个随机内存地址,读取性能会降低很多,只能达到设备内存总带宽的一小部分。为了使0号线程总是从正确对齐的地址读取从而满足所有warp内存对齐的约束,行滤波器中使用的方法是在要处理的一条数据的边缘前端增加线程。这看起来像是在浪费线程,但这没太大关系,因为当数据块足够大时,围裙像素相比输出像素是很少的。在列滤波时,围裙并不影响合并的对齐要求,只要图像条的宽度是16的倍数。
分离的行滤波和列滤波对应的CUDA内核都分为两个阶段。第一阶段将数据从全局内存加载到共享内存中,第二阶段执行滤波,并将结果写回到全局内存。
行滤波过程:在加载阶段,每个活动的线程加载一个像素。在计算阶段,每个线程的循环次数是滤波器半径宽度的两倍加1,每个像素乘以存储在常量内存中的相应的滤波器核系数。在半warp中的每个线程访问相同的常量内存地址,因此,没有常量内存bank冲突开销。此外,连续的线程始终访问连续的共享内存地址,所以也没有共享内存bank冲突。
列滤波过程:列滤波操作很像行滤波。主要的区别在于线程号的增加跨过了滤波区域。和行滤波一样,单个半warp中的线程始终访问不同的bank共享内存,但下一个地址根据列宽递增,而不是加1。列滤波加载阶段,没有行滤波那样为了合并对齐而加上的处于非活动状态的线程,因为假定列宽度是合并读取大小的倍数。为了减少围裙像素与输出像素的比率,希望图像列尽可能长,为了尽量利用共享内存,就要使图像列尽可能窄,综合考虑,使用16列。
在行和列滤波的内部循环中,计算较少,循环分支的开销很大,为了提高性能,可以将滤波计算的循环展开,这样会获得一定的性能提升。
2.2.2 使用CUDA纹理内存实现分离滤波
CUDA纹理内存是CUDA内存的重要组成部分,在很多图像处理中都能用到,使用纹理内存是加速CUDA程序的有效途径之一。
在执行CUDA程序前,都要把数据先从主机内存复制到设备内存中;一般情况下,主要使用设备的全局内存进行存取。但在某些应用场合,使用纹理内存代替全局内存进行数据存取能有效地提高性能。
相对于全局内存和常量内存来说,纹理内存主要有以下优点:
(1)与常量内存类似,纹理内存也具有数据缓存能力,但容量比常量内存的64 kB大很多。
(2)对于随机存取数据的效能可能更好。
(3)可以套用filter,使用内建的功能来做内插取值,并且可以设定要用clamping或repeat模式来处理边界数据(即如果访问数据的索引地址在边界以外,可以选择取0或重复边界数据,该特性对于卷积等操作,编程上方便了很多)。
在CUDA中,使用纹理的大流程分为三步:Host端的纹理建立部分;Device端使用纹理;Host端删除纹理。
使用CUDA纹理内存实现分离滤波器的具体实现过程不是像2.2.1节介绍的将全局内存中的数据分块使用共享内存来加速访问,而是使用CUDA纹理内存的方式。首先将存储在主机内存中的数据传到纹理内存,然后执行行滤波,将行滤波的结果再传到纹理内存,最后执行列滤波。
由于纹理内存的特点,所以在实现上不需要使用共享内存时要考虑的边缘像素,也不需要特别考虑全局内存访问对齐,因而实现代码相对简单。但从实验结果看,性能比使用共享内存的分离滤波器要差一些。
2.3 基于CUFFT的卷积滤波
假设图像大小为 dataW×dataH,卷积核的大小为kW×kH。傅里叶变换二维卷积滤波分为以下五个步骤:
(1)要对图像和卷积核分别作扩展[9,11],扩展后的大小都是 fftW×fftH,要求 fftW≥dataW+kW-1,fftH≥dataH+ kH-1。如果不扩展就直接进行傅里叶变换和乘积,会产生折叠误差(卷绕),不能得到准确结果。
卷积核扩展:卷积核扩展方式如图1所示,左边是卷积核,图中标号为12的位置是空域中卷积操作时卷积核与图像数据点对准的位置,kx和ky是相对于标号12的值。右图是卷积核扩展后的状况,中间数据补0。

图1 卷积核扩展方式实例
图像数据扩展:卷积计算会到图像边界以外,图像边界以外数据或者以0扩展或者是将边界数据复制向外扩展。图像数据扩展如图2所示,图示的是边界数据复制向外扩展的情况,如果是0扩展,就将源图像以外的数据填0。
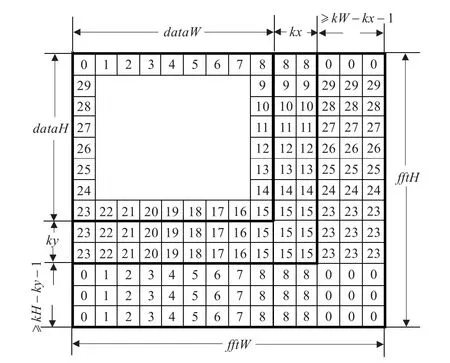
图2 图像数据的扩展
(2)对扩充后的图像和卷积核分别进行傅里叶变换。
(3)傅里叶变换后的结果相乘。
(4)相乘的结果进行傅里叶逆变换,并取实部。
(5)将左上部的矩形修剪为原始大小。
CUDA架构下基于FFT卷积的方法在实现时,在对图像和卷积核作扩展时,采用了GPU并行计算方法,加快了速度。
FFT变换自身具有可“分治”实现的特点,因此能高效地在GPU平台上实现。CUDA提供了封装好的FFT实现库,称为CUFFT[8],能够让使用者轻易地挖掘GPU的强大浮点处理能力,又不用自己去实现专门的FFT内核函数。CUFFT提供了与CPU上广泛使用的FFTW库相似的接口[12],CUFFT与FFTW的性能比较请参考文献[13]。
CUFFT使用步骤:
(1)使用cufftPlan类型的函数设置状态,可以分别设置1维、2维、3维和多维状态。
(2)使用cufftExec类型的函数执行FFT,可以实现实数、复数的FFT变换,支持单精度和双精度。
(3)使用cufftDestroy函数释放GPU资源。
2.4 基于CUDA的递归高斯滤波器
高斯窗常用于对图像进行滤波,但是随着高斯半径的增加,时间消耗会逐级增加。如高斯半径为N时,计算每个输出采样点需要的乘法次数为(2N+1)×(2N+1),这种情况下,当N=100甚至更大时,计算量是非常大的。使用CPU计算时,即使进行SIMD指令集优化,很多情况下仍然不能满足应用要求,比如N=100时,优化后的汇编代码的执行时间也通常在几百毫秒以上,远不能达到实时处理的要求。
高斯窗方法是使用高斯窗口对准原理实现的,属于FIR(有限长单位冲激响应)型滤波,对于半径大于N的像素点,其权重取为0,即对当前点无贡献。然而在实际情况下,即使在3倍标准差外的像素也应该对中心点有贡献的,虽然很小。
由于高斯滤波器应用普遍,对它的性能优化非常必要,这样就出现了IIR(有限长单位冲激响应)型的高斯滤波器,也称为递归高斯滤波器(Recursive Gaussian Filter)。
递归高斯滤波器的工作过程[14-15]:
考虑xn是输入信号,yn是输出信号。高斯滤波器的二阶递归实现可以使用如下的因果序列和非因果序列相加来实现,其中:

具体处理方式是图像水平方向处理一遍,垂直方向处理一遍,每遍都有前后两趟。当然,第一遍和第二遍的处理次序也可以颠倒。
第一遍,按水平方向计算,分为两趟。
第一趟,从左到右,按照公式(1)展开:y1(n)=a0× x(n)+a1×x(n-1)-b1×y1(n-1)-b2×y1(n-2)。
第二趟,从右到左,按照公式(2)展开:y2(n)=a2× x(n)+a3×x(n+1)-b1×y2(n+1)-b2×y2(n+2)。
其中,x(n-1)、x(n)和 x(n+1)是第n-1个、第n个和n+1个输入,y1(n-2)、y1(n-1)和 y1(n)是第一趟的第n-2个、n-1个和第n个输出,y2(n)、y2(n+1)和 y2(n+2)是第二趟的第n个、n+1个和n+2个输出。a0、a1、a2、a3、b1、b2为滤波系数,它们的值可以根据公式(1)和(2)及k值算出来。
将两趟的输出结果相加得到第一遍的处理结果,该结果作为第二遍的输入。
第二遍,按垂直方向计算,分为两趟。第一趟,从上到下计算,计算公式与水平方向的第一趟相同。
第二趟,从下到上计算。计算公式与水平方向的第二趟相同。将两趟的输出相加,得到最终结果。
二维无限滤波器在该递归实现时,不管高斯半径为多少,每个输出采样点的计算量是相同的。每个输出元素只需要16次乘法和14次加法,计算结果与无限情况误差很小,这就是递归高斯滤波器的优点。
CUDA实现递归高斯滤波器的方法与上述方法基本相同,为了提高CUDA实现的效率,在具体实现时,做了一些并行化工作[10]。首先,第一遍处理时,每个进程计算一列数据,先从上到下,再从下到上,这样的处理可以满足全局内存合并的要求。第一遍处理完后,第二遍本来需要按行计算。为了提高程序效率,满足全局内存合并的要求,将第一遍的计算结果做矩阵转置,转置后,仍然按照与第一遍相同的程序做处理。第二遍得到的结果需要再转置,得到最终的结果。
3 几种高斯滤波实现的时间复杂度分析
假设图像的大小为M×N,滤波核的半径是r。
直观实现方法的时间复杂度是O(M×N×r2),也就是,对每个像素而言,复杂度是O(r2),与滤波器大小成二次关系。如果增加滤波器大小,算法会明显减慢。
分离滤波器的算法复杂度是O(M×N×r),针对每个像素,滤波器的算法复杂度为O(r)。
基于FFT卷积的计算复杂性仅取决于填充后的图像大小,而填充图像的大小由图像和卷积核的大小决定。如果填充后的图像大小为(fftH,fftW),每个元素的计算复杂度是:

增加卷积核的大小,仍然假设它比图像小得多(使用中多半如此),可以看到基于 FFT卷积的计算复杂度大约保持不变。由于直观实现方法的计算复杂度按卷积核中元素的数目同比增加,因此,对于“足够大”的输入的图像,从某一卷积核大小开始,基于FFT的卷积比直观实现方法的性能越来越好。当滤波器大小较小时,该算法不如使用可分离滤波,而当滤波器大小较大(r>lb(M×N))时,基于FFT卷积的速度会比较快。
对于递归高斯滤波器,每个输出采样点的计算与高斯半径没有关系,而6个滤波系数是高斯半径的函数,只计算一次,这样,对高斯半径为50、100、300等的处理,每个输出像素点的计算量是相同的,都是16次乘法,14次加法,计算量大幅下降,很多时候能满足图像处理的性能需求,并且质量不会下降。
4 实验结果及分析
4.1 实验结果
实验是在NVIDIA GeForce GTX9800+上实现的,该GPU有128个频率为1.836 GHz的流处理器,分为16个SM,896 MB显存,装配在CPU是Intel Core 2 Duo E7400,时钟频率为2.8 GHz,内存为1 GB的计算机上。
基于CUDA的滤波实验分别做了2.2.1节的采用共享内存的分离滤波器,2.2.2节采用纹理内存的分离滤波器,2.3节CUFFT卷积以及2.4节递归高斯滤波。为了做对比,在CPU上也实现了分离滤波器滤波。为了比较滤波核大小对算法的影响,这些方法又分别采用了7×7和41×41两种大小的滤波核,图像的大小分别为1 024×1 024,2 048× 2 048,3 072×3 072,4 096×4 096。
图3是滤波核大小为7×7的几种高斯滤波方法性能比较,图4是滤波核大小为41×41的几种高斯滤波方法性能比较,图5是CPU上使用分离滤波器方法滤波的性能。由于CPU上实现的滤波耗时太长,如果和GPU上基于CUDA的几种方法放在同一个图中比较会比例失调,所以它单独成图。

图3 滤波核大小为7×7的几种高斯滤波方法性能比较
基于CUDA的几种滤波方法所消耗的时间都没有包括申请设备内存、将数据从主机内存拷贝到设备内存以及释放设备内存的时间。
4.2 结论与分析
(1)CPU与GPU上实现的高斯滤波性能差距巨大。两种滤波核大小,四种图像大小的组合情况下,CPU上分离滤波器比GPU上分离滤波器都慢了上百倍。这一方面是因为确实GPU加速效果明显,另外也是由于基于CUDA的方法在耗时上没有包括数据辅助处理时间。
(2)GPU上基于CUDA的四种方法中,采用共享内存的分离滤波器是最快的,采用纹理内存的分离滤波器次之,两者性能比较接近。CUFFT卷积与循环高斯滤波方法性能差不多。
分离滤波器算法本身时间复杂度就低,再加上CUDA实现时满足了共享内存bank和设备内存合并访问的要求,提高了吞吐量,因此性能优越。
(3)由于基于CUDA的高斯滤波器可以快速地实现,完全能够达到实时显示的要求,因此,可以采用CUDA与OpenGL结合的技术[16],随时动态改变高斯滤波器的参数,观察滤波效果。
(4)基于CUDA的滤波实现方式中,直观的实现方法和基于CUFFT卷积的方法适用性最广,除了可用于高斯滤波器外,还可用于其他滤波器。分离滤波器只能用于二维滤波可分离为两个一维滤波的情况,使用场合有限。

图4 滤波核大小为41×41的几种高斯滤波方法性能比较

图5 CPU上采用分离滤波器滤波的性能
[1]Haddad R A,Akansu A N.A class of fast Gaussian binomial filtersforspeech and image processing[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1991,39:723-727.
[2]Nixon M S,Aguado A S.Feature extraction and image processing[M].[S.l.]:Academic Press,2008:88-89.
[3]NVIDIA Corporation.NVIDIA CUDA programming guide version 3.2[EB/OL].[2011-03-27].http://developer.nvidia.com/cuda.
[4]Hwu Wen-mei.GPU computing gems[M].New York:Morgan Kaufmann,2011.
[5]NVIDIA Corporation.Boxfilter[EB/OL].[2011-03-27].http:// developer.nvidia.com/gpu-computing-sdk/.
[6]Chen Wei.High performance median filtering using commodity graphics hardware[C]//Nuclear Science Symposium Conference Record(NSS/MIC),2009:4142-4147.
[7]Podlozhnyuk V.Image convolution with CUDA[EB/OL]. [2011-03-20].http://developer.nvidia.com/gpu-computing-sdk/.
[8]NVIDIA Corporation.CUFFT Library documentation[EB/OL]. [2011-03-27].http://developer.nvidia.com/gpu-computing-sdk/.
[9]Podlozhnyuk V.FFT-based 2D Convolution[EB/OL].[2011-03-20]. http://developer.nvidia.com/gpu-computing-sdk/.
[10]NVIDIA Corporation.Recursive Gaussian[EB/OL].[2011-03-27]. http://developer.nvidia.com/gpu-computing-sdk/.
[11]William K.Digital image processing[M].4th ed.Hoboken,New Jersey:Wiley-Interscience,2007:203-247.
[12]Frigo M,Johnson S.The Faster Fourier Transform in the West(FFTW)[EB/OL].[2012-01-21].http://www.fftw.org/.
[13]Merz H.CUFFT vs FFTW comparison[EB/OL].[2012-01-25]. http://www.sharcnet.ca/~merz/CUDA_benchFFT/.
[14]Alvarez L,Deriche R,Santana F.Recursivity and PDE’s in image processing[C]//Proceedings of the International ConferenceonPatternRecognition(ICPR 2000),Barcelona,Spain,2000:242-248.
[15]Bharti B.IIR Gaussian blur filter implementation using Intel® advanced vector extensions[EB/OL].[2010-09-17].http://software.intel.com/sites/default/files/m/d/4/1/d/8/Gaussian_Filter.pdf.
[16]刘进锋,郭雷.CUDA和OpenGL互操作的实现及分析[J].微型机与应用,2011(23):40-43.
LIU Jinfeng
School of Mathematics and Computer,Ningxia University,Yinchuan 750021,China
There are some image filtering algorithms based on CUDA,but some of them are not clearly described,and no one to compare the performance of these algorithms,which brings difficulties for understanding and using these algorithms.This paper discusses five different Gaussian image filters based on CUDA,they are naive method,separable share memory method,separable texture memory method,FFT convolution filtering and recursive Gaussian filter.Core ideas are emphasized,time complexities are compared,and performances are analyzed through experiments.
Gaussian filter;separable filter;recursive Gaussian filter;Compute Unified Device Architecture(CUDA);Graphics Processing Unit(GPU)
目前已有几种CUDA加速的图像高斯滤波算法,但这些算法有的描述不清楚,也没有人对它们的性能进行详尽的比较,这给理解及应用带来了困难。描述了几种CUDA加速的图像高斯滤波算法,包括直观的实现方式、使用共享内存的分离滤波器方法、使用纹理内存的分离滤波器方法、基于CUFFT的卷积滤波以及递归高斯滤波器。强调了这些算法的核心思想,比较了它们的时间复杂度,通过实验对它们的性能进行了分析。
高斯滤波;可分离滤波器;递归高斯滤波器;统一计算设备架构;图形处理器
A
TP391
10.3778/j.issn.1002-8331.1306-0035
LIU Jinfeng.Comparation of several CUDA accelerated Gaussian filtering algorithms.Computer Engineering and Applications,2013,49(23):14-18.
宁夏自然科学基金(No.NZ12163)。
刘进锋(1971—),男,在读博士,副教授,研究领域为GPU通用计算、图形学、图像处理。E-mail:ljf@sjtu.org
2013-06-07
2013-07-22
1002-8331(2013)23-0014-05
CNKI出版日期:2013-07-29 http://www.cnki.net/kcms/detail/11.2127.TP.20130729.1104.002.html
猜你喜欢
小天使·二年级语数英综合(2019年4期)2019-10-06
山西电子技术(2019年4期)2019-09-07
小学生学习指导(低年级)(2019年6期)2019-07-22
科技视界(2018年28期)2018-01-16
科技风(2017年20期)2017-07-10
环球市场(2017年36期)2017-03-09
四川师范大学学报(自然科学版)(2015年2期)2015-02-28
计算机与网络(2014年6期)2014-05-25
组合机床与自动化加工技术(2013年1期)2013-12-23
计算机工程与科学(2013年2期)2013-06-07
