
基于声韵拼接的中文孤立词语音识别方法的研究
2013-09-30 06:39张志楠李琳琳贾玉辉
中国信息化·学术版 2013年6期
关键词:语音识别
张志楠 李琳琳 贾玉辉
[摘要]本文提出了一种基于HTK搭建的中文孤立词语音识别系统的方法,系统采用中文特有的声韵拼接结构作为建模基元,通过频谱归一化处理(Cepstral Mean Normalization,CMN)之后一定程度上提升了识别准确度,并且结合三音素(Triphones)的状态绑定(Tied-State)策略又给出一种词表的自动更新过程,可以针对任意给定的词表做识别,在一定程度上实现了识别词表的可定制性。
[关键词]语音识别;频谱归一化;三音素;状态绑定;
[中图分类号]G71 [文献标识码]A [文章编号]1672-5158(2013)06-0325-02
目前,现已发行的HTK稳定版是3.4。本系统即是在其基础上来搭建。可以方便有效的建立及操作HMM。HMM已经被广泛地应用在了诸多的科研领域,比如AI(Artificial Intelligence,人工智能)和生物工程,HTK也主要针对智能语音技术的应用及研究而设计。
本系统是针对所有的中文词汇能够做识别,这种识别过程是基于三音素(Triphone)的自动拼接过程,因此,我们设计了一个词库,包含403个中文词汇,覆盖了所有的声韵拼接,并且我们借助HTK的辅助录音工具来采集足够的语音数据用于模型训练。此外,为能够使得识别系统能够针对不同的采样率做识别,又特别加入了一种采用率下采样(Downsampling)自动转换机制,以使得系统能够针对待识别语音做采用率自动转换识别的功能。
1 声韵母基元
1.1 模型基元定义
模型识别基元的选择对于语音识别率以及训练数据量的大小都有较大的影响。音素(Phoneme)、声韵母(Initial/Final)、音节(Syllable)、整词(Word)都是中文语音识别中常用到的建模单元,汉语中有409个无调音节和1300多个有调音节。
采用声韵母建立声学模型是相对比较合适的,特别说明本文中使用的问题集是基于语音学知识的。基于音素(Phoneme)的语音识别已经被广泛地应用在英文识别中并且取得了很好的识别性能。本文所采用的基元集是由37个韵母,24个声母和1个静音模型共同组成,参见(表1):
2 基于Triphones模型的自动拼词识别机制实现
2.1 原理介绍
首先解码原始音频数据进行识别,得到初步的单音素以及前后阶音素的关系,然后依据得到的这种上下文依赖关系,查找其对应的映射文件,进而确定相应的三音素模型。再根据这种声韵拼接信息,通过查找Triphone模型的上下文相关模型映射文件生成了最终的全词匹配结果。
2.2 实现过程
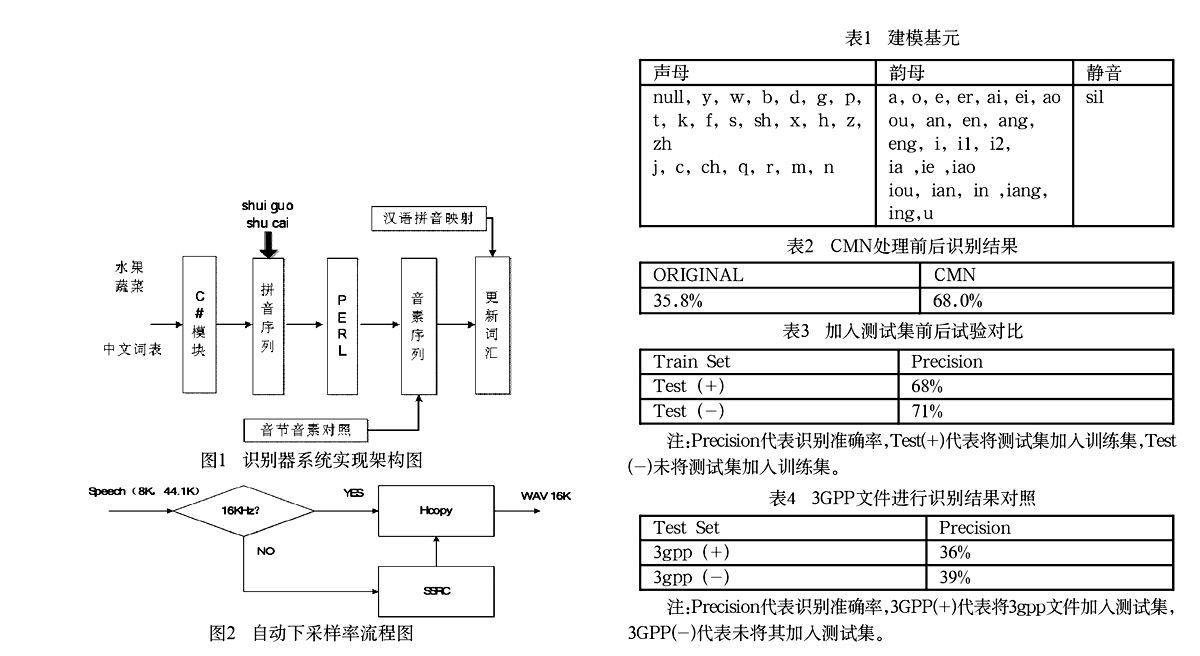
该模块旨在实现待识别词汇表的自动更新识别功能。整个识别过程是不需要重新训练的。之前已经完成了汉字转拼音的转换程序,在此基础之上又进—步实现了系统自动拼词的机制。其目的在于允许用户传送词汇表(并不在训练集当中),自动做拼接识别。
处理结束后,还要调用自动映射处理模块将用户传过来的新词汇表映射到已存在的词表当中,并相应的标出汉语,以便于在反馈用户结果的时候将拼音对应的汉语一并反馈给用户(图1)。
3 HTK上实现Downsampling自动转换机制
3.1 原理介绍
通过修改功能模块,我们将SSRC自动采样率的转换功能嵌套在HTK当中,实现了下采样的自动转换功能,前端采样自动检测准确与否,直接影响到语音识别系统的识别性能。
3.2 实现方法
该模块提供一种采样速率自动转换机制,用于提高最终的语音识别率。首先,我们需要引入一个新的开源工具包SSRC,其功能是实现采样率的自动转换。通过做SSRC使测试语音与训练时语音采样速率保持一致,也是优化识别系统整体识别性能的一种方法,进一步减少因为采样率不一致而导致的误识率(图2)。
整体的采样率自动转换功能模块参照下面步骤运行:
对从客户端采集到的声音文件进行初步的判断,采样率是否满足系统的要求,如果上图第一次判断走了“NO”分支,要接着进行SSRC的采样率自动转换,统一将从客户端采集到的声音文件的采样率标准化;然后,抽取相应的Mel频谱参数(MFCC),再将特征参数传人识别系统的核心模块Recognizer,得到识别结果。
4 实验结果
本实验采用的训练数据是由12个人借助HTK录音工具共同录制的包含4200个词条的语音库。测试数据集是由三个人采用平板电脑录制的30个连续发音词条(每人10条)。然后又通过CoolEdit工具[9]将其手工切分为彼此分离开来的词条,即每一个单独的词汇保存与一个独立的WAV文件中,然后对所有这些WAV片段做识别(表2)。
由上面结果容易看出,CMN可以大大提升识别系统的识别性能。倒谱均值归一化算法(CMN)对于语音识别系统抗噪声性能的提高十分有效。接下来,我们将测试语音经过SSRC做采样率自动转换,都同一转换为16KHz,然后将录音测试词(2/3)加入训练集。剩余1/3做集外测试,并重估参数,得出的实验结果如(表3):
①在未将测试词加入训练集,并作CMN,SSRC:识别结果18/28=68%
②将测试词加入训练集,并作CMN,SSRC处理:识别结果20/28=71%
③将测试词加入训练集,并作CMN处理,采样率按照初始(44100HZ),未作SSRc处理:识别结果很低,基本不能识别。另外,以上是针对原始音频格式wAV所做的识别结果。而对于3GPP音频文件的识别结果准确度却比较低(图4):
由以上实验结果可以看出,本识别系统对于3gpp格式的媒体文件尚不能够有很好的识别率,因此,综上所述本系统目前对3GPP格式的识别相对较低(39%),而对WAV格式的音频支持相对较好(71%)。
5 结束语
本文依照中文发音的特性,选取了扩展的声韵母基元XIF作为识别基元,问题集的设计也建立在当今中文语音学知识体系架构之上,再结合基于Triphones的模型训练,得到了一个可以自动按照中文声韵拼接规则对任意词汇做识别,与其它识别基元作对比。借助决策树以Triphones模型来共同搭建语音识别系统,能够有效地降低其对于识别阶段所带来的负面影响,并且提升了识别器对于识别环境的鲁棒性。
猜你喜欢
科技创新与应用(2017年3期)2017-02-18
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年12期)2016-06-14
物联网技术(2015年9期)2015-09-22
现代电子技术(2015年11期)2015-07-28
现代电子技术(2015年8期)2015-07-09
电子技术与软件工程(2015年6期)2015-04-20
无线互联科技(2015年2期)2015-04-02
物联网技术(2015年3期)2015-03-31
软件导刊(2015年1期)2015-03-02
