
基于WEKA的高速公路换卡逃费问题研究
2013-11-10 06:18夏苏哲唐又林
上海船舶运输科学研究所学报 2013年4期
夏苏哲, 瞿 辉, 唐又林
中海网络科技股份有限公司,上海200135
0 引 言
随着我国高速公路建设的快速发展,各省市联网收费的路网规模不断扩大,进出路网只缴纳一次费用的特点一方面方便了高速公路的用户,另一方面,随着单次最大收费额的不断增加,偷逃通行费所带来的高额利润使得该行为呈日益增长趋势。为了维护高速公路的正常秩序,保证收费工作健康稳定进行,收费稽查显得尤为重要。现有的稽查方式主要是人工手动稽查,智能手段相对缺乏,而相当一部分偷逃通行费行为会在收费数据中留下痕迹,引发相关数据异常,如何利用这些痕迹发现并解决偷逃费问题已成为收费稽查工作关注的重点。
“数据挖掘”可以从大量的数据中提取有用的信息,发现数据之间潜在的关系,并有可能发现问题所在,帮助找出解决办法。现有的联网收费系统交易流水数据大而齐全,可能隐含着丰富但尚未发现的偷逃费信息,因此,将数据挖掘技术应用于高速公路收费稽查,研究高速公路换卡逃费问题,进而打击和防范偷逃费行为,具有非常重要的现实意义。
1 偷逃通行费现象分析
联网收费的基本特征是行驶于路网的车辆只需要缴纳一次通行费,入口发卡、出口验卡收费,实现路网内“一卡通”的服务目标[1]。由于单次最大通行费的增加、各路段管理的差异,使得偷逃通行费现象日趋严重。经分析,偷逃通行费现象大致可分为四类,每一类又包括若干种方式,如表1所示。
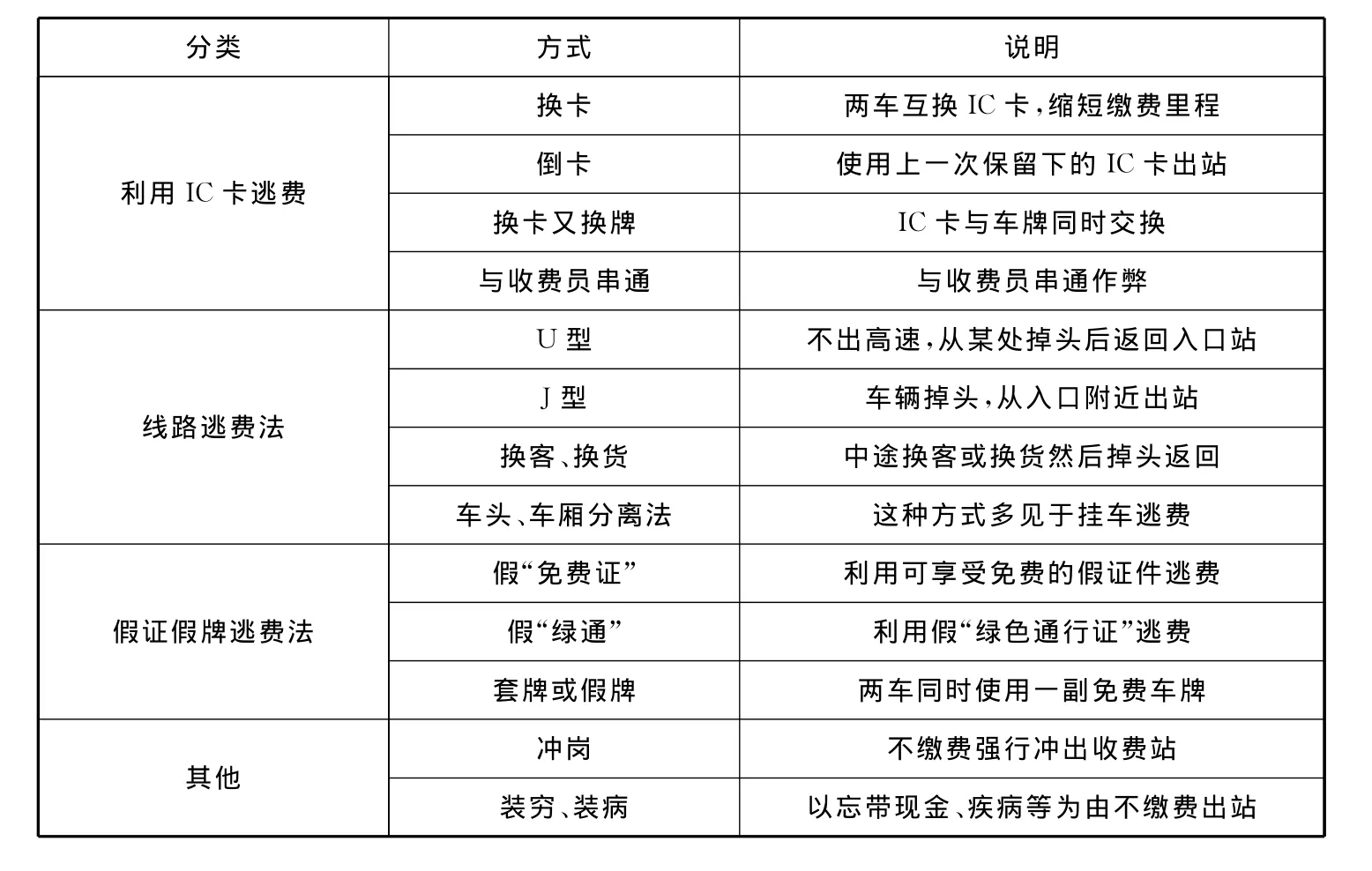
表1 偷逃通行费行为分类
收费稽查作为查处偷逃通行费行为的重要措施,正面临着越来越大的挑战。现有的收费稽查方式对规范收费操作流程起到了很好的作用,但对于日益严重的逃缴费行为和花样繁多的偷逃费方式却效率不高。
目前,联网高速公路的收费稽查主要采用现场稽查和事后稽查两种方式。现场稽查指现场就能发现作弊行为,由收费工作人员和稽查人员直接处理偷逃费事件,例如损坏通行卡、假冒军警车\绿通车、假证、U转车等。事后稽查主要包括两种情况:
(1)收费员现场很难判断(或者判断时间比较长),为避免影响车道畅通,收费员让可疑车辆正常通行,并把通行记录交由后台稽查人员进行详细判断,如果存在逃缴费行为,则把该车辆加入黑名单,下次再进入高速时进行处理。
(2)对系统数据库进行分析,发现隐藏在正常通行记录中且未被发现的可疑数据,然后通过比较出入口抓拍的图片等方式进一步判断,如果确认存在违规行为,则把该车辆加入黑名单。
这里针对第(2)种情况进行数据挖掘。
2 关键技术及挖掘环境
2.1 数据挖掘关键技术
数据挖掘是从大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的过程。数据挖掘的任务有特征化与区分、频繁模式、关联和相关性挖掘、分类与回归、聚类分析、离群点分析等。这些任务可以分为两类:描述性和预测性。描述性挖掘任务刻画目标数据中数据的一般性质;预测性挖掘任务在当前数据上进行归纳,以便做出预测[2]。这里主要介绍分类方法,属于预测性挖掘。
分类算法通过对已知类别训练集的分析,从中发现分类规则,以此预测新数据的类别。主要分析出口流水数据中哪些字段与换卡逃费现象有关,多字段输入,单字段输出。决策树算法最适合解决这类问题。决策树是以实例为基础的归纳学习算法,它从一组无次序、无规则的元组中推理出以决策树形式表示的分类规则。
ID3算法是由J Ross Quinlan提出的、起初最著名的决策树算法,此算法的目的在于减少树的深度,但是忽略了叶子数目的研究。C4.5是最常用、最经典的决策树分类算法之一,它继承了ID3算法的优点,并对ID3算法进行了补充和完善。该算法采用信息增益率作为选择分支属性的标准,克服了ID3算法中信息增益选择属性时偏向选择取值多的属性的不足,而且能够对连续型数据和不完整数据进行处理,其原理如下:
设训练数据集为X,目的是将训练集分为n类,表示为A={X1,X2,…,Xn},训练实例属于第i类的概率为P(A)=i表示第i类的训练实例个数,|X|表示X中的实例总数。

由式(1)、式(2)可知:属性c的信息增益为:Z(X;c)=B(X)-B(X/c)。信息增益越大,说明测试属性c提供给分类的信息越大,所以选择属性c后对分类的不确定度越小。ID3算法选择使得信息增益值最大的属性作为测试属性。
C4.5算法继承了ID3算法的优点,并在此基础上进行了优化。与ID3算法不同,C4.5算法采用信息增益率选择属性。信息增益率定义如下:
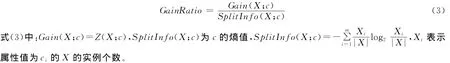
当不同属性提供相同的增益Gain(X;c)时,Split Inf o(X;c)的值越小越好。C4.5算法选择具有最高信息增益率的属性作为给定集合X的测试属性,创建一个节点,以该属性作为标记,对属性的每个值创建分支,并据此划分样本。
2.2 挖掘环境简介
怀卡托智能分析环境(Waikato Envir on ment f or Knowledge Analysis,WEKA)是一款免费的、非商业化的基于JAVA环境下开源的机器学习以及数据挖掘软件,主要开发者来自新西兰。WEKA作为公开的数据挖掘工作平台,集成了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理、关联分析、分类、回归、聚类以及在新的交互式界面上的可视化[3]。
把WEKA集成到My Eclipse中,便于对WEKA进行二次开发;修改或添加一些最新的数据挖掘算法,还可以把挖掘的结果以各种形式展示出来,使用户能够方便、清晰地找到所需的知识。在进行挖掘前,需要配置JDBC,加载数据库的驱动。
3 实例应用
3.1 换卡逃费的表现形式
换卡逃费是一种很常见的逃缴费行为,如果只交换通行卡,车辆在出站时卡内保存的入口车牌信息会与出口识别的车牌信息不同,该类问题车辆能被及时查出。如果车牌与通行卡同时交换,出站时收费员则很难发现存在的问题。现主要讨论的是车牌与通行卡同时交换的情况。
1)双向对开换卡:两车双向对开,中途互换通行卡,在对方入口收费站附近站下路。一般情况下两车严重超时,车型相似(相同),车牌号套牌或者中途换牌,都短途下路。
2)两车同向换卡:两车在到达目的地附近收费站时,轻车先下路后上路,然后与重车互换通行卡;重车短途下路,轻车长途下路。
3)轻车换卡:重车在接近目的地收费站时,附近一轻车上路,然后两车互换通行卡,在目的地收费站下路。两车一般情况下车型相似,车牌号套牌或者中途换牌,重车短途下路,轻车长途下路。
这几种方式具有很多共同的特征,例如超时、里程记录较短等,通过选取与换卡逃费可能相关的字段流水数据进行分析,找出换卡逃费问题的数据特征。
3.2 数据预处理
任意选取某收费站10天内的出口通行记录,删除非正常收费车、非正常通行的记录,把余下的正常通行记录分为两部分,一部分作为训练集,余下的作为测试集。同样,在特殊事件稽核表中选取1个月内判定为换卡逃费问题车辆的出口通行记录,部分添加到训练集,剩下的添加到测试集。
通过对出口流水数据的分析,选取了Deal Stat us(是否超时)、Veh Plate(出入口车牌是否相符)、Veh-Class(车型)、Toll Mode(收费模式)、Total Exceed Weight(是否超重)、Distance(出入口之间的里程)等6个可能与换卡逃费问题相关的字段,并用ChangeCard字段保存是否换卡逃费的结果。对每个字段的值预先进行处理(见表2)。
3.3 建模及预测
在My Eclipse中创建工作目录weka_wor k,在 WEKA的安装目录中找到weka-src.jar,解压并把main文件中的weka文件夹拖入到weka_wor k工程中的src文件夹下。打开weka.gui包,找到类GUIChooser或Main,以”java application”的方式运行,即可得到 WEKA主界面,见图1。
WEKA Expl orer是集成的数据挖掘测试模块,其中包含了大量的挖掘算法和功能强大的可视化工具。先使用open file打开保存为arff格式的训练集,也可以直接选择open DB连接数据库获取数据。在Classif y界面上选择J48决策树算法(C4.5算法在WEKA中的名称)建立模型,见图2。
由结果可知,在3 722个实例中,3 653个实例判断正确,69个实例判断错误,模型的准确率为98.1462%.生成的决策树模型见图3,其表示为:未超时的车辆不存在换卡逃费问题;当车辆处于超时状态时,出入口车牌不符的车辆有96.88%的可能存在换卡逃费问题,出入口车牌相同时,出口与入口站间的里程>100 k m则有87.5%的可能不存在换卡逃费问题;出入口站的里程在60~100 k m时,有74.07%的可能不存在换卡逃费问题;出入口站的里程在30~60 k m时,有78.18%的可能存在换卡逃费问题;当出入口站的里程在0~30 k m时,车辆为1型或2型客车则有76.47%的可能存在换卡逃费问题,车辆为3型或4型客车则有73.33%的可能不存在换卡逃费问题,车辆为1型或2型货车则有69.05%的可能存在换卡逃费问题,车辆为3型、4型或5型货车则有80.65%的可能存在换卡逃费问题。
图1 My Eclipse中WEKA运行主界面
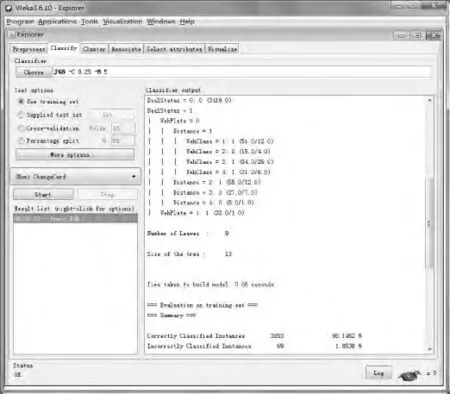
图2 模型及误差分析
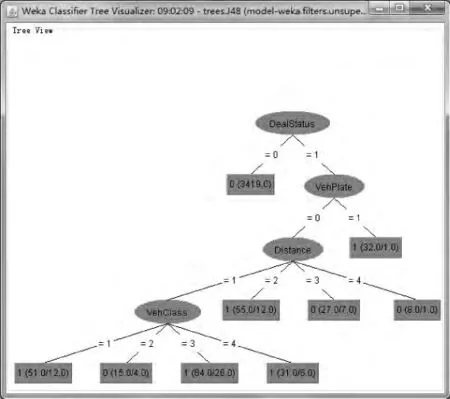
图3 决策树模型
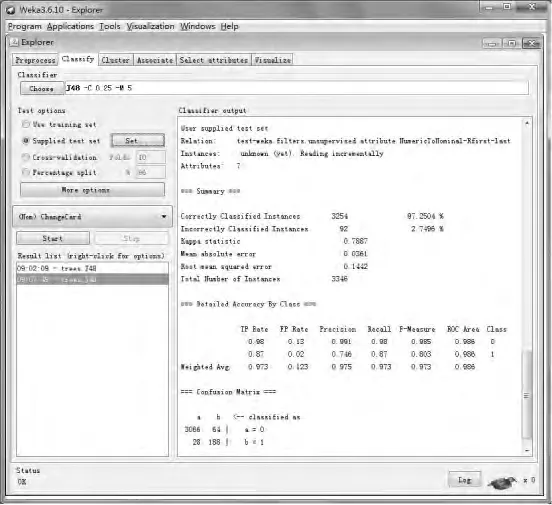
图5 模型预测结果分析
为了保证生成模型的准确性,使之不至于出现过拟合现象,选择10折交叉验证来评估模型,具体方法是在Test options中选择Cr oss-validation选项,Fol ds中填写10,执行后,模型的准确率为97.931 2%,表明此模型的准确率比较高,能达到应用要求。

图4 十折交叉验证模型准确率
WEKA一般有两种方法可对生成的模型进行测试:1)方法一
选择Supplied test set,插入测试集数据,在Result list中右键选择Re-eval uate model on current test set,由结果得知,在3 346个实例中,3 254个实例预测正确,92个实例预测错误,模型预测的正确率为97.250 4%(见图5)。
Result list中右键选择Visualize classifier err ors,保存预测误差的散点图,然后从Prepr ocess界面中打开,可发现倒数第二列多了1个字段predicted Change Car d,这个属性的值就是模型对每个记录的预测值(见图6)。
2)方法二
WEKA也可以用命令行语句来对模型进行预测,具体方法为打开Si mple CLI模块,输入命令:java weka.classifiers.trees.J48-C 0.25-M 5-t E:\model.arff-d E:\model.model说明:-C 0.25为J48算法的默认参数;
-M 5表示每个叶的最小实例数量为5;
-t为训练集的路径;
-d为模型保存的路径。
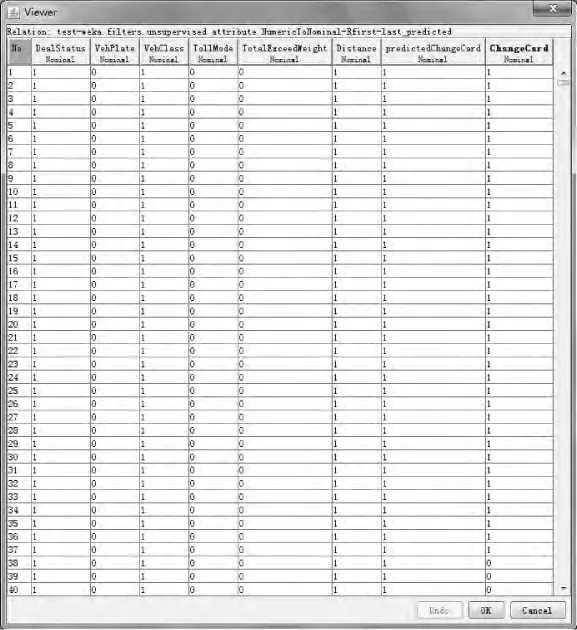
图6 预测数据
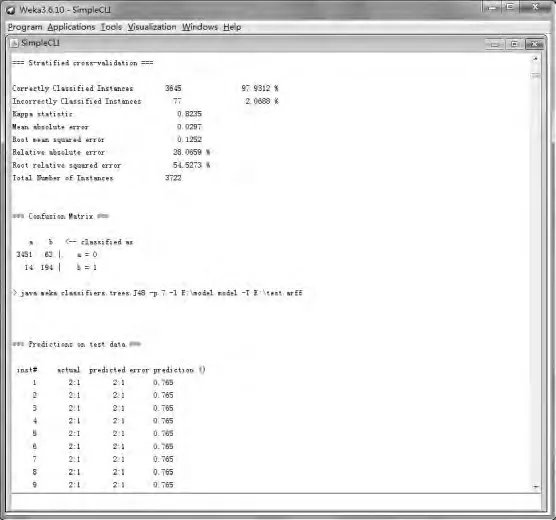
图7 命令行预测结果及置信度
输入上述命令即可得到决策树模型,Si mpleCLI显示结果与图形界面显示相同。然后把得到的模型应用到测试集当中,命令如下:

输入上述命令得到结果如图7所示。其中第3列为预测列,第4列为预测结果的置信度,例如第一个记录有76.5%的可能存在换卡逃费问题,可根据置信度有选择的对数据进行最后判定。运用命令行的好处是不用每次重新建模,直接使用保存好的模型即可,还可以根据置信度采纳预测结果。
由预测结果可知,共有216个实例Change Car d为1,通过核对188个实例判断正确,正确率为87.04%,表明模型预测效果很好。在实际工程中,稽查人员需对模型预测出的存在问题的实例进行核实,找出偷逃费记录。由于时效性,模型内容要经常更新,使用最新的训练数据集建立模型能更加有效地稽查偷逃费行为。
4 结 语
针对高速公路常见的换卡逃费问题,运用数据挖掘算法建立模型,解决了隐藏在正常收费记录中、原有系统不能发现的逃缴费问题,减少了通行费的损失。本模型易于理解、准确率较高,有一定的实用价值。随着模型训练集的不断增大和包含换卡逃费现象种类的增多,本研究模型将会进一步完善。此外,把WEKA集成到My Eclipse中,便于后期对算法进行改进及开发更多的可视化图形,加深用户对结果的理解。
[1] 赵智明.高速公路跨区域电子联网收费系统的研究与实现[D].华北电力大学,2006.
[2] Han J,Kamber M,Pei J.Data Mining Concepts and Techniques[M].China Machine Press,2012.
[3] 张晓航,任文龙.基于数据挖掘的高速公路联网收费稽查研究[J].软件,2011(11):57-59.
猜你喜欢
中国交通信息化(2022年7期)2022-11-19
中国交通信息化(2022年2期)2022-04-26
中国交通信息化(2020年1期)2020-07-27
中国交通信息化(2020年12期)2020-02-06
中国交通信息化(2020年12期)2020-02-06
中国交通信息化(2019年8期)2019-11-04
中国交通信息化(2019年7期)2019-10-08
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
环球时报(2009-05-05)2009-05-05
