
基于支持度矩阵的关联规则挖掘算法在公安情报分析中的应用*
2014-03-03 08:04李为王池重庆市公安局巴南分局
警察技术 2014年3期
李为 王池 重庆市公安局巴南分局
基于支持度矩阵的关联规则挖掘算法在公安情报分析中的应用*
李为 王池 重庆市公安局巴南分局
将关联规则算法引入公安情报的数据挖掘中,以求发现情报信息中的相关规律,提高执法效率与快速反应能力,并及时预防和打击犯罪行为。由于关联规则Apriori算法存在多次扫描数据库并且时间性能较低的缺陷,提出了一种基于矩阵的关联规则挖掘算法。该算法通过对矩阵操作,只需扫描数据库一次,就能一次产生所有频繁项集,大大减少了计算项集的工作,有效提高了挖掘效率。
数据挖掘 频繁项集 支持度矩阵 Apriori算法
一、引言
随着现代科学技术的发展、科技强警的不断推进,全国公安机关依托“金盾工程”进行了一场公安信息化的现代警务新变革,公安信息化系统建设已成为打击违法犯罪活动的有力工具,但在实际工作中收集和积累的海量社会信息和数据信息越来越多、数据规模日益增大、复杂程度不断增加已成为公安信息系统处理的难题[1]。为了适应信息动态管理,如何从这些蕴涵大量有用情报的信息数据中及时发现、总结各种犯罪的规律性、最新规则以及社会治安的变化特点,以制定有利于社会稳定和发展的决策,提高执法效率与快速反应能力,及时预防和打击犯罪行为,并采取相应的措施显得越来越重要。将数据挖掘技术应用于公安情报分析,能够为公安部门提供各种决策信息以及解决方案,大大提高决策的质量和效率,已成为当前公安工作中亟需进一步研究解决的问题,也是公安信息化建设进一步发展的方向。
在绝大多数犯罪活动中,犯罪活动之间或内部拥有错综复杂的联系,犯罪数据挖掘得到了很大关注,各种数据挖掘技术的研究为社会安全提供了帮助[2]。现有关联规则数据挖掘算法[3]已不太适应当前公安信息系统的发展。针对在关联规则挖掘中如何高效挖掘频繁项集,本文提出了生成支持度矩阵并利用矩阵理论的频繁项集挖掘算法。该算法通过对矩阵操作,只需扫描数据库一次,就能一次产生所有频繁项集,大大减少了计算项集的工作,有效提高了挖掘效率。
二、基于矩阵的关联规则信息挖掘高效算法
(一)关联规则的基本概念及定义
关联规则是描述数据库中数据项之间存在的潜在关系的规则,即反映一个事物与其它事物之间的相互依存性和关联性。问题可以描述如下[4]:I={i1,i2,...,im}由m个不同项组成,是所有项的集合;D={T1,T2,...,Tn}由一系列具有唯一标识TID的事物组成,是所有事物的集合。每个事物T由I中的若干项组成,是I的子集,记为T={t1,t2,...tn},t1I。若X、Y是数据项集,X中含有的项数目为k,则称为k-项集。事物集D中的关联规则表示为蕴涵式X Y,且X I,Y I,X∩Y=φ,X为规则的前提,Y是结果。
给定一个事物集D,挖掘关联规则就是产生支持度和置信度分别大于用户给定的最小支持度(min_supp)和最小置信度(min_conf)的关联规则。当规则的置信度和支持度分别大于min_supp、min_conf时,我们认为规则是有效的,称为强关联规则。当数据项集X的支持度大于min_supp时,称X为高频数据项集。
定义1项的向量表示:
Ii则项Ii相应的支持度表示为
cup_count[Ii]=(Ii表示项,j表示事物标号)。
定义2项集I的矩阵记为:

定义3k-项集的支持度计数:
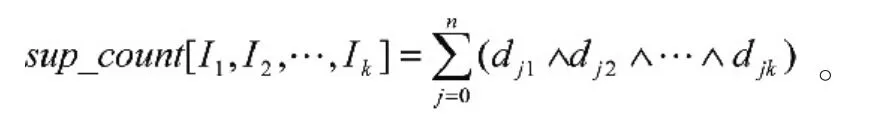
定义4关联规则的置信度:
性质1一个频繁项集的任一子集必定是频繁项集。
性质2一个非频繁项集的任一超集也是非频繁项集。
(二)基于矩阵的关联规则挖掘算法
算法的具体实现过程描述如下:
1. 把事物数据库构造成矩阵,求频繁1-项集
对给定的事务数据库D,根据定义2构造矩阵M1。以事物表示成行向量,项表示成列向量,若第i个事物中包含了第j个项,则矩阵的第i行第j列的值为1,否则值为0。该矩阵中的每一个位置在内存中仅占一位。
对该矩阵各列向量扫描,根据定义1,由矩阵的各列数字和就可以得到支持度计数。当支持度计数sup_count[Ii]>min_supp,则Ii为频繁项,将该项加入频繁1-项集L1中。否则Ii非频繁项集,将其从事务矩阵中删除。
2. 构造二项集的支持度矩阵,快速找出频繁2-项集
由频繁1-项集构造|L1|阶2-项集支持度矩阵M2,此矩阵为对称矩阵。根据定义3,依次求出矩阵中各元素对应的2-项集支持度计数。当M2[i,j]=mis_supp(i
3. 利用支持度矩阵,寻找所有频繁项目集
对于每个候选k(k≥3)项集X,从X在Ck之后的位置中查找以X后k-1个项开始的其它候选k项集,若找到这样一个候选k项集Y,则把X的第一个项Ir和Y的最后一个项Is的标号连接形成矩阵坐标[r,s],到矩阵M2中查找这个坐标上的值是否大于最小支持度计数min_supp,如果大于或等于,则生成候选k+1项集;如果不大于,则不予连接,继续查找下一个,直到Ck中的最后一个k项集。至此候选k+1项集表构造结束。
4. 由频繁项集产生关联规则
从事物数据库D中挖掘出所有的频繁项集后,就可以产生关联规则,即产生满足最小支持度和最小置信度的强关联规则。根据定义4中的公式,具体产生关联规则的操作如下:
(1)对于找出的每个频繁项集l,产生l的所有非空子集s;
(2)对于每个非空子集s,如果包含l的事务数与包含s的事务数的比值大于最小置信度,即support(l) /support(s)≥min_conf,则输出规则“s l-s”,其中min_conf是最小置信度。
由于关联规则是通过频繁项集直接产生的,因此关联规则所涉及的所有项集均满足最小支持度。
(三)算法在公安情报分析中的应用
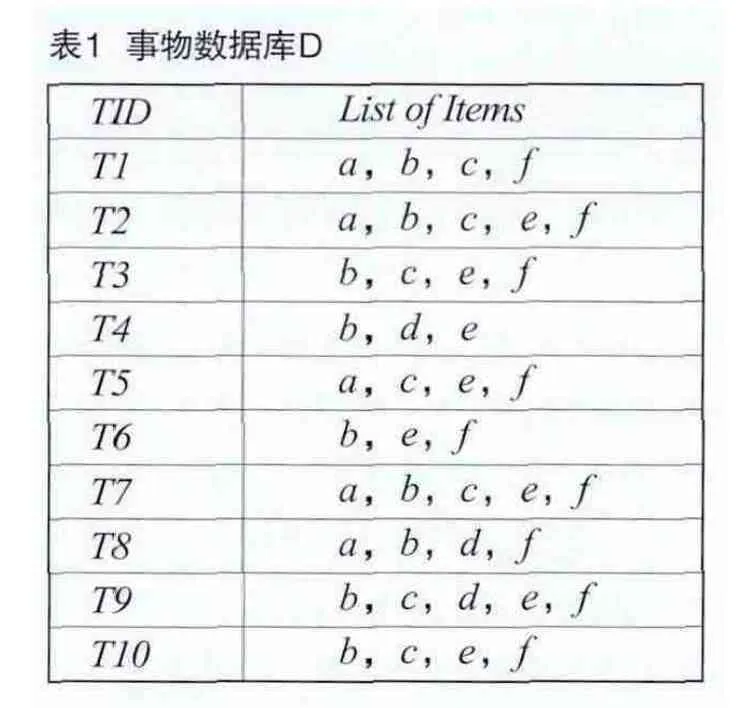
选取少量登记在案的犯罪嫌疑人员数据,由此算法进行数据挖掘。假定T1~T10为案件编号,a~f分别为案件相关信息,则案件与事件信息之间的关系如表1所示,假设最小支持度计数为4。
?
(1)扫描数据库,得到事物矩阵M1。
(2)构造支持度矩阵M2。
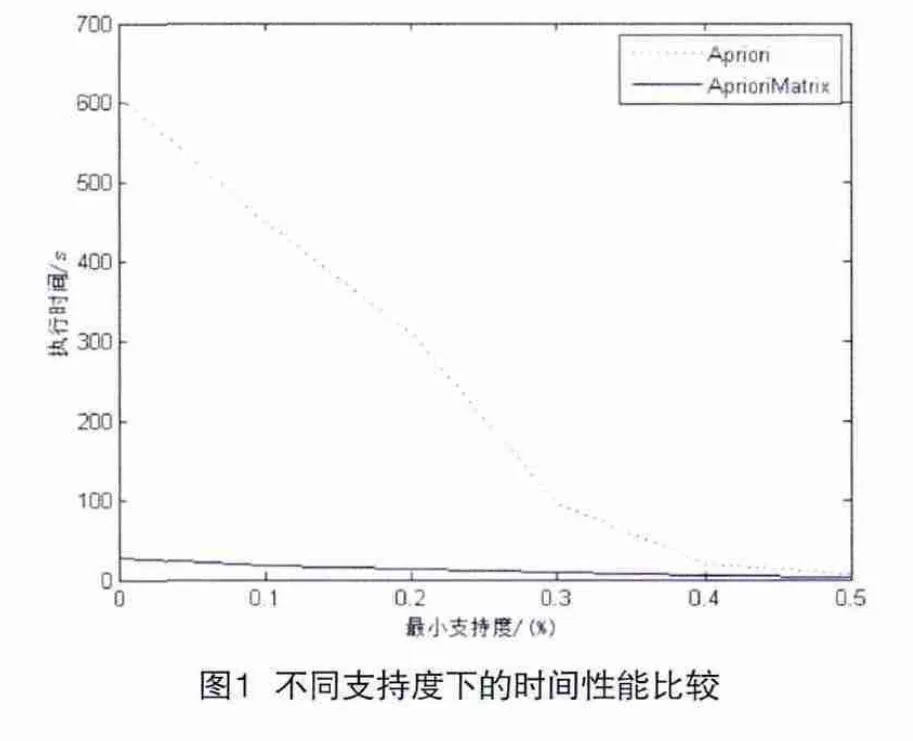
根据定义3,依次求出M2[i,j](i ? 把M2中元素与最小支持度min_supp=4比较,得到频繁2-项集L2={{a,b},{b,c},{a,c},{c,e},{b,e},{e,f},{c,f},{b,f},{a,f}}。 (3)对a行的二项集进行扫描,发现二项集{a,b}大于最小支持度,于是转到b行,搜索b行中大于最小支持度计数的二项集,得到{b,c},{b,e},{b,f}。然后定位到矩阵[a,c][a,e][a,f],发现M2[a,e] (4)发现候选4-项集以及更高维的k项集,对于三项集{b,c,e},从它的位置之后在C3中查找以{c,e} 开头的其它三项集,发现符合条件的三项集{c,e,f},于是定位到矩阵坐标[b,f]中,发现{b,f} 是频繁2-项集。于是生成候选四项集{b,c,e,f},此时已不能再生成其它候选四项集以及更高维的k项集,生成k项集表的连接剪枝过程至此结束。L4为{{b,c,e,f}}。 1. 时间复杂性 Apriori算法是逐层搜索的迭代算法,通过频繁(k-1) -项集搜索频繁k-项集。其时间复杂度为其中xx为交易事务数据库中包含的交易数量,k为频繁项集大小。Apriori算法在挖掘每一层中所包含的频繁项目集时都需要进行一次数据库扫描,来获得候选项集的支持度。而且在发现频繁项目集的过程中,产生了大量的候选项目集。当遇到海量数据库时,耗时太长,难以满足实际应用的需求。同时Apriori算法的效率不高,利用频繁(k-1)-项集连接产生候选k-项集,判断连接条件时重复次数太多[5]。 而本文算法中只需要一次扫描数据库得出事务矩阵,并求出支持度,构造二项集的支持度矩阵。根据支持度矩阵的性质产生频繁k-项集。利用矩阵可以更方便地处理数据,减少候选项集的生成,大大地提高了挖掘关联规则的效率,并且基于矩阵的算法也便于在实际应用中被实现和理解。 2. 空间复杂性 Apriori算法会产生大量的候选项集,并且所有具有相同长度的候选项集必须被存储在内存中,这将会占用大量的内存空间,导致内存不停地换进换出操作。而本文算法采用矩阵进行存储,大量减少所需的I/O次数,减小了存储空间,不需要在内存中存储所有的候选项集,具有良好的空间特性。 为了对算法的优势进行验证,将其进行实验验证。在Inter(R) Core(TM) i3 CPU 2.27GHz,4.00GB内存,Windows 7 64Bit操作系统的实验环境下,算法采用Java语言实现。实验数据采用T40I10D100K,将本文所述的优化算法与Apriori算法进行比较。图1是在最小支持度不同时,挖掘所有频繁项集执行时间的区别。由图1可知,Apriori算法当支持度减少时,耗费的时间会增大,而本文算法受最小支持度的影响较小;并且当最小支持度越小时,优化后算法的执行时间比Apriori算法的执行时间少得越多,这说明优化后的算法在给出支持度较小时具有较高的执行效率。 图2给出了当数据库中事务记录数不同时两种算法执行时间的区别。由图2可知,两种算法执行时间都会呈上升趋势,但当事物记录适当大时,优化后算法的效率比Apriori算法的效率要高一些,这说明优化后的算法在所给数据库中记录较大时具有较高的执行效率。 关联分析是数据挖掘技术的一个重要的应用。基于经典的关联规则发现算法Apriori算法的研究,提出了改进的基于支持度矩阵的关联规则发现算法:该算法仅扫描数据库一次,把结果存储到矩阵中,节省了大量的内存空间,并通过矩阵运算来计算项的支持度计数,并生产支持度矩阵来产生频繁项集。将该算法应用到公安情报分析领域的规则发现中,通过对案件信息的一些强关联规则的挖掘,为公安侦破工作提供依据,提高了决策的质量和效率。 [1] 赵伟.数据挖掘技术在公安预测预警中的应用[J].警察技术,2009,9:56-58. [2] Chen H,Chung W,Jie J,et al.Crime Data Mining:A General Framework and Some Examples[J].The IEEE Computer Society,2004. [3] Patel Nimisha R,Sheetal Mehta.A Survey on Mining Algorithms[J].International Journal of Soft Computering and Engineering(IJSCE),2013. [4] Jiawei Han, Micheline Kamber. 数据挖掘概念与技术[M].机械工业出版社,2001. [5] 倪坚.对Apriori算法的一个改进[J].大连交通大学学 公安理论及软科学研究计划(编号:20125000000000871)
三、实验结果分析
(一)与Apriori算法的比较
(二)实验结果分析

四、结束语
猜你喜欢
核科学与工程(2021年4期)2022-01-12
公民与法治(2020年17期)2020-10-27
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
领导决策信息(2017年16期)2017-06-21
新闻传播(2016年20期)2016-07-10
轴承(2015年2期)2015-07-25
江苏年鉴(2014年0期)2014-03-11
电讯技术(2011年11期)2011-04-02
网络安全与数据管理(2010年1期)2010-05-18
