
面向跨语言词云可视化的拓扑保持布局算法研究
2014-03-06 05:42马坤乐
图学学报 2014年2期
路 强, 唐 靓, 马坤乐,梁 翀
(1. 合肥工业大学可视化与协同计算研究室,安徽 合肥 230009;2. 合肥工业大学计算机与信息学院,安徽 合肥 230009)
面向跨语言词云可视化的拓扑保持布局算法研究
路 强1,2, 唐 靓1,2, 马坤乐2,梁 翀1,2
(1. 合肥工业大学可视化与协同计算研究室,安徽 合肥 230009;2. 合肥工业大学计算机与信息学院,安徽 合肥 230009)
针对大范围替换词云中单词后出现的词云拓扑结构不稳定的现象,提出一种词云可视化的拓扑保持布局算法。首先,该算法通过对替换后的词云中单词进行分散处理,使之前或重叠或远离的单词按原拓扑相应分离;再利用Delaunay三角剖分算法对分离词云网格化,形成控制网格;最后在控制网格的基础上采用紧凑布局的方法将分散词云紧凑为与替换前原词云拓扑一致的词云布局。针对替换的一种具体情况,即跨语言翻译词云的情况做详细介绍。该算法在提高词云布局稳定性,保持原词云拓扑结构方面是一个新的突破。
图拓扑保持;单词替换;翻译词云;单词分散;紧凑布局
词云也称为标签云,由Milgram[1]最先提出。其作为一种用于文本分析的可视化工具,显示了需分析文本中的关键性单词,用户只需一扫而过便能掌握文本的主要内容,提高了用户分析文本的效率。出于其高效性考虑,越来越多的研究工作日益展开。目前的词云工作已由当初只想在可视化界面中单纯显示出重要性单词[2]的初衷,发展到便于读者高效分析文本内容的前提下同时还能为读者带来美学享受。
目前的词云研究可以分为两大方面,分别侧重于词云的单词分布和词云语义一致性研究。我们的工作不同于前两种,却是在这二者的基础上的进一步深化探索。本文将针对于词云的研究概念,提出一种新的词云布局方法,即在保持词云本身的拓扑、颜色、布局不变的情况下,通过替换词云中的元素即单词,可能是替换某个,或者是替换全部,可能是将所有英文单词全替换为翻译后相应的中文词语、法文单词等其他语言,亦或是将词云中的各个单词分别替换为另一篇文本的其他关键词,从而形成一种与替换之前拓扑结构完全一致的紧凑词云分布。其中,本文将针对词云中单词跨语言翻译为其他语种单词的替换后的词云拓扑保持算法做一介绍。随着词云这一可视化工具在视觉方面和新闻发布方面越来越普遍的应用,这一工作的研究对于美学工作者及从事新闻领域的工作者有着极大的意义,相比于之前人为翻译后的手工布局,我们的研究将会因其在词云生成方面的一致性、高效性、紧凑性、美观性、便利性,获得越来越多的青睐。
1 词云研究现状
现阶段的词云工作可以分为着重于研究词云布局从而为用户带来美学影响和以提高词云可读性为目的调整单词自身特性或单词间特性这两方面。基于这两方面的研究在词云领域已经较为成熟。
(1)词云的布局方式对于用户分析文本有着举足轻重的作用,对于词云的整体美学感观影响更甚。最初的将单词单一的按一定顺序逐行排列的布局方式[3]已不能满足用户对于词云可读性的需求,文献[4]提出了用词云布局美国地图的方法,每个州分别用各自州名来布局,很好的将词云同地图结合起来,为用户更方便地了解美国提供了极大便利。同时,利用词云排列而形成的简单图形的词云布局算法[5],及一种新型的词云街道图[6]都打破了我们关于词云布局的原有观念。但这些算法的研究往往是只偏向于整体布局本身的美观性,忽略了词云中单个单词独立美观和各单词间连贯易读对于整体词云效果的影响。
(2)词云中的单个单词本身特性,包括单词的字体、颜色、大小等方面及词云中各单词间的关联性我们称为单词间的语义连贯性[7]对用户理解文本起到关键性作用。Shaw[8]为了将单词的关联性在可视化空间有所表示,提出将每个单词看做单个的点,将相互关联的单词用点与点之间连线的形式显式表达,从而得到一种语义相关的词云分布。2010年,文献[9]中提出了一种新型语义相关方式,这种方式将语义相关的单词聚簇到一起,且用不同的颜色分类,这一方法使得针对词云可读性的研究向前迈进了一大步。
诚然,上述两方面对于最终词云达到的效果都有着举足轻重的作用,能体现文本内容的分布方式,可以提高词云的美观性,而相邻单词具有语义连贯性的分布方式,有助于提高整体词云的可读性。我们的工作不同于这两方面,但却是在这两方面的进一步深化探索,针对已具备各单词语义连贯的美观词云,在保持其原有拓扑不变的情况下,将词云各单词全部替换或直接翻译为其他语言词云,就目前来说,是一种全新形式。与此同时,该算法的实现将会给从事新闻行业和视觉设计行业的工作者带来极大便利,相比于人为翻译后的手工布局,该方法更加高效便利。
2 跨语言词云可视化的拓扑保持布局算法
本算法相比于前人的工作,从保持词云的拓扑结构着手,介绍一种新的词云布局概念深化词云的布局形式,即在替换词云中各单词显示形式的情况下,着重介绍词云的跨语言替换,即翻译词云的这种情况下,通过对翻译过程中各个单词的调整,保证翻译后相对应各单词分布紧凑,使拓扑结构保持不变。
2.1 相关定义
与文本主体内容越贴近的单词在文本中出现的频率越高,当然,一些起连接作用和代词作用的词除外。以单词出现的频率为标准,定义了单词的重要性值,出现频率越高,该单词对于整个词云的重要性影响越大。将重要性值越大的单词通过显示不同的字体和颜色进行标注,突显在词云中,已成为词云工作者在布局词云时参考的一种基本原则。依照此原则布局的词云是有意义的,而用我们的算法对此词云保持原拓扑替换或翻译为其他语言的词云也是有意义的。
图1所示的词云是由百度百科中对于Wordnet[10]的文本描述为文本来源生成的,也较好体现了以上述原则分布词云对于词云主要内容表达的正确性,由图1可以得知Wordnet是用来描述词语的语义信息关系的大体概念。表1对文本中提取的前100个词语出现的频率划分频率区间,并对相应词语划分的不同优先级进行说明,其中高频率单词具有高优先级。我们定义词云中显示面积较大的单词具有较高优先级,显示同种大小的单词具有相同优先级,以此为依据对翻译词云中各单词重要性进行判断。为了对算法作用后的拓扑保持程度形象化说明,在此基础上,我们定义单词语义相关的概念,其具体表现为单词间的相对位置和相对距离的关系,其中相邻单词必定语义相关。

图1 描述Wordnet的词云

表1 根据频率区间定义单词优先级
2.2 基本框架
对于给定的输入词云即待翻译词云V,用跨语言词云可视化的拓扑保持布局算法,将其翻译为具有相同拓扑结构的相应语种词云,具体实现主要分以下3个部分,首先我们需将其翻译为指定语言,翻译后的词云与原词云相比肯定存在差异,之前无重叠的单词相互覆盖,又或者是原本紧凑的词云分布翻译后存在大量空白,依照本文的算法第二步的工作是将词云中的单词依照其优先级的相反顺序移动单词,保证单词相互分散的同时各语义相关单词间依旧保持相关关系。在对分散后的单词进行 Delaunay三角剖分[11]形成控制网格后,最后紧凑布局网格化词云得到最终词云分布。该算法的核心部分以伪代码形式描述如下:
1 start
2 translate(V) //翻译所有单词节点的标签

其中,N表示V中的单词个数,ks为翻译后词云覆盖部分面积占总面积的比例,d1, d2为本算法自定义的阈值,distance_n为单词n为消除重叠所需移动距离,ln为单词分散时单词n需移动的位移,Fn为单词n所受合力,dn为在紧凑词云这一步骤时单词n需移动的向量。
2.3 词云翻译
将中文词云中的单词翻译为相应英文为例,翻译后的英文单词与之前相比普遍更为扁平,在确定了翻译后英文单词的字体和大小后,根据单词所占像素确定字体所在矩形框的大小,将词云中的单词放置在与之大小匹配的矩形框中,通过调整矩形框的位置实现对相应单词实际位置的调整,进而通过调整各个矩形框之间的距离实现实际单词间无重叠的初步放置。
2.4 单词分散
不同语种的同一单词有着不同的显示结果。我们仍然以中文单词翻译为对应的英文单词为例说明。翻译后的单词在长度和高度上明显存在差异,其长度一般较为拉长,高度在原有基础上更为压缩,这必然使得翻译后的词云存在大面积的单词重叠,为了达到消除单词重叠的目的,我们提出一种单词分散算法,实现可能存在大面积空白的无重叠词云放置。
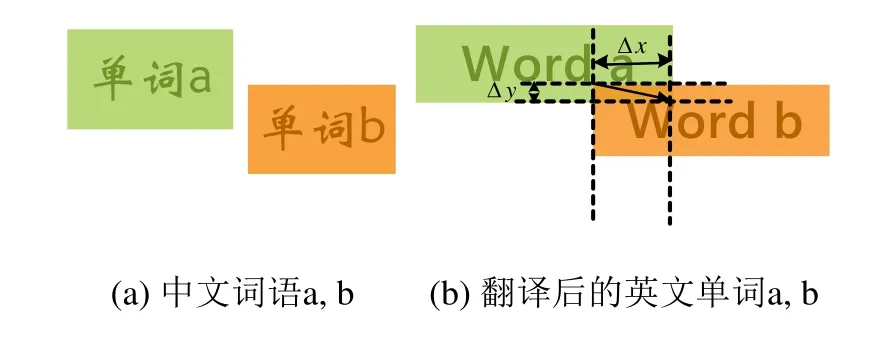
图2 翻译后的单词重叠
对于给定词云V,根据单词在词云中的显示大小确定各单词的优先级,我们规定从优先级最低的单词开始,同种优先级的单词按单词序号进行,依次对词云中各单词进行遍历。如图2所示,以词云中的两个中文单词a, b为例,单词a的优先级高于单词b,原本相对紧凑的布局由于翻译为相应的英文单词(图2(b)所示)其原有长度被拉长,高度被压缩,使得单词间必定存在重叠。对于Word b,为了消除与Word a之间的单词重叠,其需要在图中所示的x方向移动距离Δx ,y方向移动距离Δy ,分别表示为dx和dy。为了保证词云中各单词的语义相关性得到保持,在此基础上,我们采用循环迭代的方法将Word b每次按系数α, β移动,假定有n个单词与Word b重叠,则Word b第j次需移动的位移lbJ定义如下:
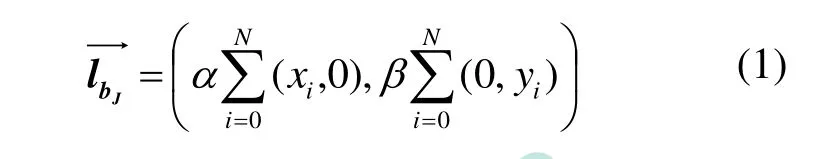
其中α, β可由相应两种字体的长宽自行确定,对于中英文跨语言的词云,经过大量实验得出α, β分别取值为1/16,1/8时可取得较好效果。当位移lbJ在某次迭代后的值小于规定阈值e时,迭代终止,即lbJ<e。由此得到翻译后的英文单词分散分布的词云。
2.5 紧凑布局
通过上述算法得到的词云存在大量空白(如图3(a)所示),为了在保持词云原有拓扑结构的基础上得到紧凑的词云分布,我们将各单词用其矩形框的中心点表示,对其三角剖分得到网格化的最初图G(如图3(b)所示)。假定Delaunay边连接Word a和Word b,在此基础上我们定义两种力:引力和斥力,保证Word a,Word b在不重叠的情况下最大限度的靠近,紧凑布局(如图3(c)所示)。引力的使用有助于消除单词间的大量空白,使得词云中的单词分布紧密(如图3(d)所示),对于Word a和Word b,如图4所示,它们之间的引力定义如下:
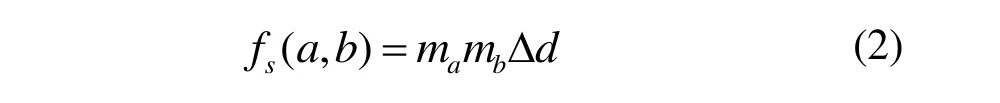
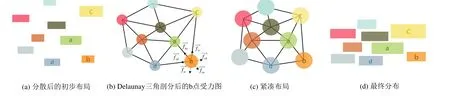
图3 紧凑布局过程示意图
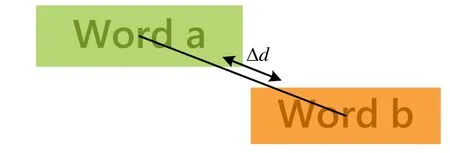
图4 有引力作用情况示意图
只有当Word a和Word b重叠时,它们之间的斥力才会产生作用,以图2(b)为例,此时的斥力可以被定义为:
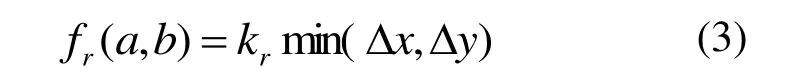
其中,kr是一个给定的值,Δx 和Δy分别为Word a和Word b重叠部分的x,y方向的长度。
单词间无重叠无覆盖是紧凑布局的前提,因此我们定义斥力的优先级高于引力,量化的表示为
与单词分散的遍历一致,依照单词的优先级顺序从最低优先级的单词进行遍历,同等优先级的单词按序号从大到小进行,依次计算每个单词受到的合力,以图3(b)中的word b为例,它在第q次遍历时所受到的合力可以被定义为:
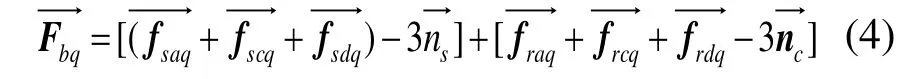
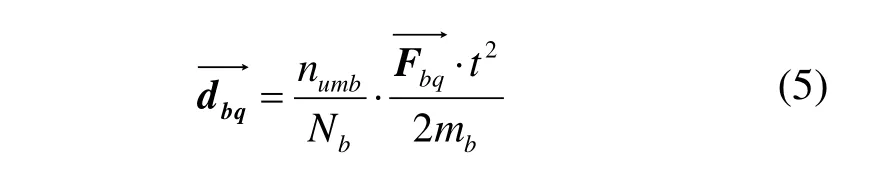
其中,num为以单词出现频率为依据的单词编号,单词出现频率越高其值越小,N为所分析词云包含单词的总个数,t为给定值的单位时间。
3 实验结果分析
以百度百科中定义Wordnet的文本描述为文本来源生成的两种布局形式的词云图,分别为螺旋状排布单词的紧凑布局(如图5(a))和完全依照单词重要性程度按层次依次从大到小发散性布局(如图5(b)),为输入词云。
由于中文和韩文相比于英文来说都属于方块型字体,相应的中文翻译成韩文后遮挡的面积较小,如图5(c)所示,可以直接使用紧凑布局算法对其进行调整;而中文翻译成英文词云出现的遮挡面积过大,如图5(d),所以先将词云用单词分散算法进行分散处理,分散后的词云分布如图6所示,再进行紧凑布局,形成最终词云分布。图5(e)和图5(f)为两种词云布局形式分别翻译为韩文和英文后的最终词云分布图。
词云的拓扑变化主要由单词间相对位置变化和单词本身大小变化引起的。为了对我们的算法在替换原词云单词后的拓扑保持程度量化说明,受文献[12]启发,我们提出一种方法评估翻译后词云拓扑保持程度。

图5 两种中文分布的不同翻译结果

图6 分散算法处理后的英文词云分布
其中,由于翻译后的单词间相对位置变化,因此各单词相对于最高优先级单词的相对位置也会发生变化,我们定义参数距离和,即Δ p,则:
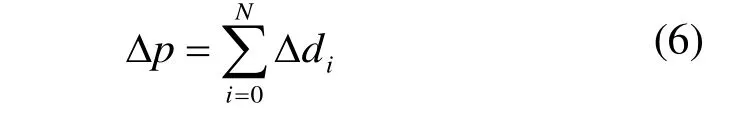
与此同时,单词本身大小的改变也会对单词间的语义相关性和词云的拓扑保持产生影响。由此,我们定义参数s表示词云中所有单词的矩形框的面积和。

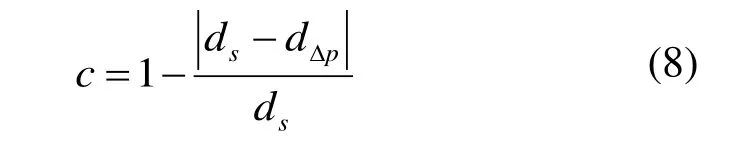
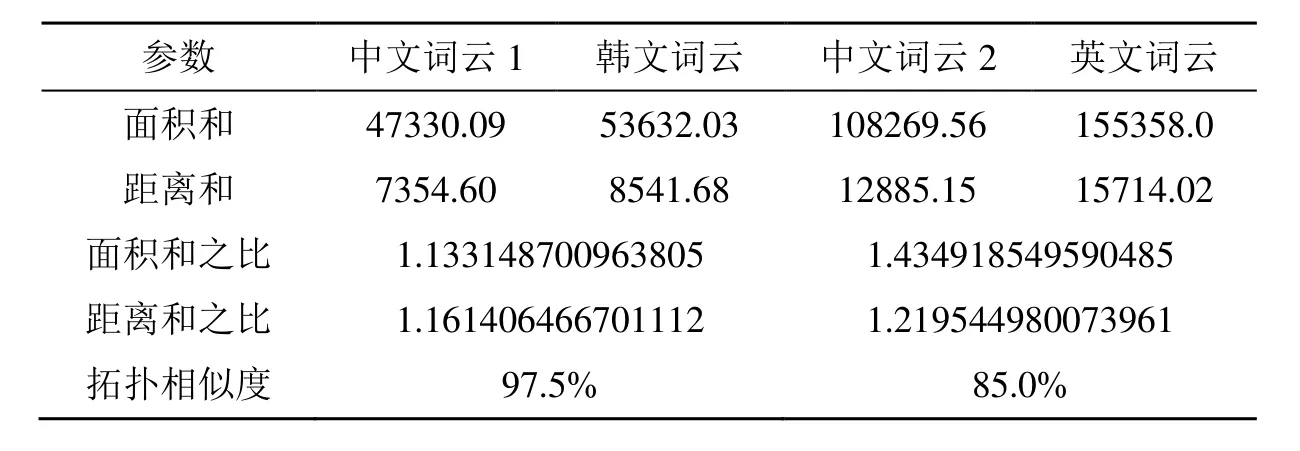
表2 翻译前后词云拓扑保持程度的量化衡量
从实验结果可知,相比于翻译为韩文后词云的拓扑结构得到了程度较大保持来讲,翻译后的英文词云单词间的语义相关性较小,拓扑保持效果相对较差,与图5所示的实验结果相符。这主要是由于在紧凑布局算法中使用了按优先级由低到高依次进行力导向布局的缘故,此方法在拓扑调节时极力地保持了优先级较高单词的相对位置不变,并且使空白的区域尽量的减少,因此优先级较低的词便有可能产生相对位置较大的变化。如图5(b)中“计算机”一词与图5(f)中相应翻译后单词“computer”位置差距较大,产生此现象的原因主要是:①单词“Computer”的优先级相对较低,移动的距离相对较大;②使用紧凑布局调节时,由于单词“Computer”紧凑时需要的空白区域较大,无法将其塞入原相对位置,而字体比“Computer”小的词(如单词“Overall”)大小合适,为了不出现词云大面积空白的现象,由其代替入空白区域。正由于此,致使词“Computer”因为程序的多次循环而逐渐的偏离。针对于翻译为英文后优先级较低单词相对位置不变但存在偏离的情况有待进一步改善,我们的深入工作将进一步在其上开展。
4 总 结
本文分析了一种适用于不同布局的词云可视化拓扑保持布局算法,面向翻译中文词云为英文词云和韩文词云的具体情况做了详细描述。针对翻译后存在大面积重叠的词云分布,在进行单词分散的基础上,对分散后的词云进行三角剖分,用控制网格确保紧凑布局的过程中保持词云的原有拓扑。结果表明,该算法对于替换单词后的词云拓扑具有较好的保持效果,也为词云研究工作开辟了一种全新模式。
[1] Proshansky H M. Environmental psychology: People and their physical settings[M]. Holt, 1976: 632-633.
[2] Evans T. Money makes the world go round [J]. Capital & Class, 1985, 8(3): 99-123.
[3] Kaser O, Lemire D. Tag-cloud drawing: algorithms for cloud visualization [C]//www workshop on Tagging and Metadata for Social Information Organization, 2007: 1087-1088.
[4] Paulovich F V, Toledo F, Telles G P, Minghim R, Nonato L G. Semantic Wordification of Document Collections[C]//Computer Graphics Forum. Blackwell Publishing Ltd, 2012: 1145-1153.
[5] Park M, Joshi D, Loui A. Tag Cloud++-scalable tag clouds for arbitrary layouts[C]//IEEE International Symposium on Multimedia(ISM), 2012: 318-325.
[6] Afzal S, Maciejewski R, Jang Y, Elmqvist N, Ebert D S. Spatial text visualization using automatic typographic maps [J]. IEEE Transactions on Visualization and Computer Graphics, 2012, 18(12): 2556-2564.
[7] Wang C, Yu H, Ma K L. Importance-driven timevarying data visualization [J]. IEEE Transactions on Visualization and Computer Graphics, 2008, 14(6): 1547-1554.
[8] Shaw B. Utilizing folksonomy: similarity metadata from the del. icio. us system [EB/OL]. http://www.metablake. com/webfolk/web-project.pdf, 2008.
[9] Cui Weiwei, Wu Yingcai, Liu Shixia, Wei Furu, Zhou M X, Qu Huamin. Context preserving dynamic word cloud visualization[C]// IEEE Pacific Visualization Symposium (PacificVis), 2010: 121-128.
[10] 姚天顺, 张 俐, 高 竹. WordNet综述[J]. 语言文字应用, 2001, 1: 27-32.
[11] Berg M D, Cheong O, Kreveld M V, Overmars M. Computational geometry: algorithms and applications [M]. Springer, 2000: 1-17.
[12] 刘文印, 唐 龙, 唐泽圣. 一种在矢量基础上进行图形识别的通用方法[J]. 软件学报, 1997, 8(5): 376-383.
Topology Preserving Word Cloud Visualization Algorithm for Cross-Language Replacing
Lu Qiang1,2, Tang Liang1,2, Ma Kunle2, Liang Chong1,2
(1.Visualization & Cooperative Computing, Hefei University of Technology, Hefei Anhui 230009, China; 2. School of Computer and Information, Hefei University of Technology, Hefei Anhui 230009, China)
The word cloud may be unstable when replacing some words or even all words from it. This paper presents a visualization algorithm to solve the problem and ensure that the final topology of the cloud will be totally consistent with the original one. The algorithm can be concluded as follows. Firstly, all the words are scattered in the cloud to avoid overlapping. Secondly, the Delaunay Triangulation may be used on the words to obtain the mesh which can make sure the topology not be destructed after the last step being executed. Finally, the words are compacted on the basis of the control mesh to reduce the empty space. Then the final layouts of the word cloud may be formed. This paper may take the situation that all the words may be translated in other language for example to introduce the method in detail. The algorithm is a new breakthrough in keeping the stability and topology of the word clouds.
topology preserve; words replace; cross-language; scatter words; words compaction
TP 391.72
A
2095-302X (2014)02-0307-06
2013-06-08;定稿日期:2013-07-21
国家自然科学基金资助项目(61070124);高等学校博士学科点专项科研基金资助项目(20120111110003)
路 强(1978-),男,安徽合肥人,副教授,博士。主要研究方向为信息可视化与可视分析学习环境。E-mail:luqiang@hfut.edu.cn
猜你喜欢
阿来研究(2021年2期)2022-01-18
开放教育研究(2020年2期)2020-03-31
阿来研究(2020年2期)2020-02-01
当代陕西(2019年11期)2019-06-24
读友·少年文学(清雅版)(2018年8期)2018-12-06
能源(2017年5期)2017-07-06
中国修辞(2017年0期)2017-01-31
中国科技信息(2016年15期)2016-11-04
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
