
一种改进的Web社区结构挖掘系统
2014-07-13 06:45罗彩君
电子设计工程 2014年12期
罗彩君
(陕西职业技术学院 计算机科学系,陕西 西安 710100)
一种改进的Web社区结构挖掘系统
罗彩君
(陕西职业技术学院 计算机科学系,陕西 西安 710100)
针对HITS算法、传统最大流算法在挖掘Web社区时存在主题漂移、噪音页面等问题,采用基于传递概率的边容量分配最大流改进算法,开发了一个改进的Web社区结构挖掘系统,详细描述了该系统的设计和实现过程。实验表明,利用该系统进行Web社区挖掘能较好的解决传统算法中存在的问题,进一步提高了Web社区挖掘的准确性。
结构挖掘;Web社区;体系结构;种子节点
Web社区的结构挖掘是基于两种模型:一个是Hub和Authority模型,一个是拓扑图中最大流量/最小割集模型。基于Hub和Authority模型的HITS算法挖掘社区,存在主题漂移等问题,而用传统的最大流算法,则可能产生一些噪音页面,降低社区质量[1]。为解决上述存在的问题,本文开发了一个改进的Web社区结构挖掘系统。
1 系统算法分析
在本系统中,将网络中任意两个节点之间的紧密程度用它们之间产生的传递概率来度量,传递概率的计算可以综合考虑节点属性之间的连接度、节点之间的相关度、节点之间发生信息传递等多种因素,进行综合度量,为不同的边分配不同的边值。因此,本系统采用动态分配边容量的算法——基于传递概率的边容量分配最大流改进算法进行设计。其算法步骤如下:
Step1:构建种子节点集合:S={s1,s2,…,sk};
Step2:对种子节点集S中的每个节点以深度为2进行扩展;
Step3:计算链接所对应的两个端点的相关度;
Step4:计算链接所对应的两个端点的出度和入度值,并计算两端点的传递概率值;
Step5:构造邻接图 G(V,E);
Step6:根据 Puv给边(u,v)分配边容量 c(u,v);
Step7:执行最大流算法;
Step8:得到仍然同种子节点相连的节点集合C={c1,c2,…,cm};
Step9:将C中入度最高的两个非种子节点添加到S中,重复上述过程直到C中节点比较稳定,形成一个稳定的社区;
Step10:对最终结果进行处理,输出社区中的各节点。
此算法在页面集合基础上实现更精确的信息聚类、识别、匹配等操作[2],从而有助于实现根据用户的搜索请求,为用户提供更加精准的搜索结果。
2 系统体系结构
系统体系结构主要包括原始数据收集、数据预处理和在线处理等部分,其体系结构如图1所示。
由于客观条件的限制,不可能对所有网站数据甚至是所有特定类型的网络数据进行研究,因此,为了确保Web数据的获取不影响研究结果的可靠性,选择了代表性网站作为样本数据源,即在研究总体中进行抽样,利用现有搜索引擎对Web数据资源进行搜索,然后对Web的数据进行采集、组织和存储,建立Text或知识模型库,通过对样本的研究达到了解总体的目的。
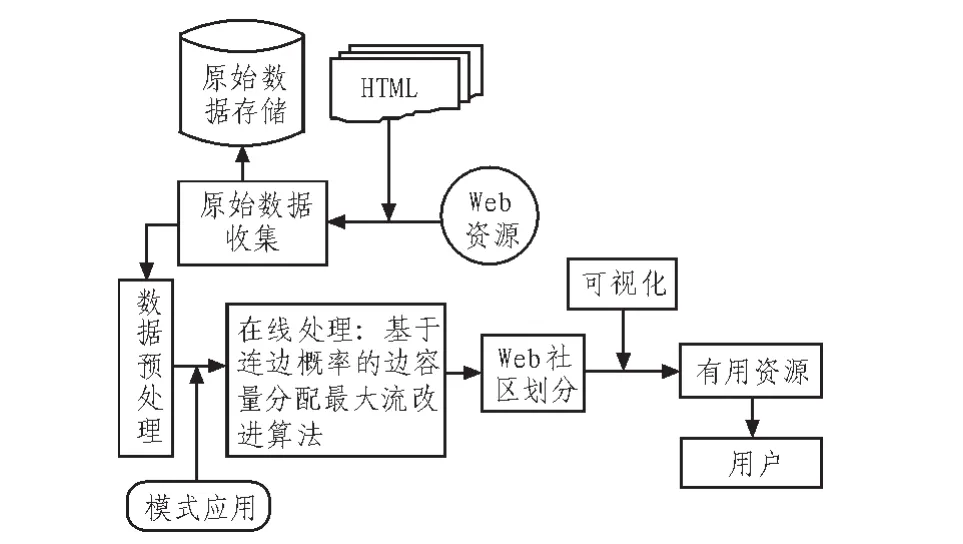
图1 Web社区结构挖掘系统体系结构Fig.1 The system structure of Web community structure mining system
在经过数据采集阶段后将进入数据预处理程序中。在网页文件中存在乱码、连接重复等问题,为了满足实验的要求,必须对所采集的原始数据进行预处理。数据处理是为了更好地进行数据挖掘以获得高质量的挖掘结果而做的准备工作。数据处理后就可以得到一个比较合理的邻接Web图[3]。在数据处理过程中主要做了以下几个工作:
1)去除死链接和无效链接,某些网页已经不存在,或改成新的地址,如果不存在,就删除这个网页的URL,如果地址已更改,则用新的URL代替旧的URL。
2)排除那些入链接或者出链接数超过了500以上的Web页面,因为这样的一些页面往往是非常出名的一些站点页面,像Yahoo,Google等,这些站点页面根本就不需要用户使用什么挖掘策略去获得。
3)统一URL的格式,去除那些URL里包含有关键词%,?,bbs,cgi-bin,di-ary,news等的页面,因为这样的一些页面往往和用户要找的主题无关,还会产生更多的主题漂移问题[4]。
4)去除镜像页面,所谓的镜像页面是指与主网站的内容相同的其它位置的网站页面,太多的镜像页面只会重复同一个页面内容,扰乱用户的视野,所以要尽可能事先去除。
在线处理模块主要目的是利用之前预处理好的数据与Web信息搜索技术相结合,提高传统搜索引擎的效率及搜索精度。主要包括页面处理、文档索引、链接分析及Web社区发现等模块组成,最终将发现的结果返回给用户,具体过程如图2所示。
页面处理:主要功能是将页面中的所有链接提取出来,并对链接进行必要的转换以获取真实的URL,因为页面链接中给出的URL格式可能是不一样的,既可能是完整的绝对路径,也可能是一个相对路径,为方便处理,需要先将其规格化为统一的绝对路径格式。根据一定计算模型可计算出链接的价值,并由此预测链接指向的页面对主题的相关性,将其认为主题相关的URL放入URL队列中以供选择出合适的URL提供给Crawler进行采集。
文档索引:为原始网页建立索引,实现索引网页库。针对索引网页库切分,将网页转化为词的集合。将网页到索引词的映射转化为索引词到网页的映射,同时将网页中包含的不重复的索引词汇聚成索引词表[5]。
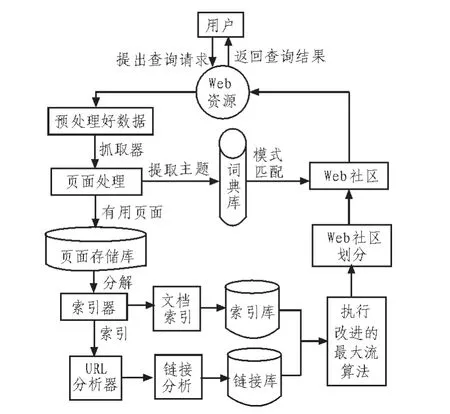
图2 在线处理模块体系结构图Fig.2 The system structure diagram of online processing module
链接分析:由一组种子URL开始,DNS解析器获得该URL对应的主机IP地址,然后通过机器人拒绝协议检测后由HTTP/HEEPS下载模块下载该网页。URL抽取器从下载的网页中抽取出新的URL。然后由URL过滤器逐个检测是否符合过滤规则的限制。最后,用哈希函数计算各个URL的哈希值,将符合下载规则的URL加入到链接数据库中。
Web社区发现:根据链接分析和文档分析的结果,关注那些关系较为紧密的节点,计算出节点的连接度和节点相关度[6],将节点的连接度与节点之间的相关度统一起来计算连边的传递概率,依据传递概率动态分配边的容量,然后执行改进的最大流算法,进行Web社区划分,对用户的请求进行分析并返回结果。
3 系统实现
3.1 开发环境
本系统开发环境为Windows操作系统,2.4 GHz处理器,1 GB内存,768 MB虚拟内存,开发工具为Visual Studio 2005。
3.2 用户界面
本文基于Web搜索引擎技术设计并实现了Web社区结构挖掘系统,其检索页面如图3,Web用户通过图3界面输入要查询的内容。

图3 搜索界面Fig.3 Search interface
当输入主题 “java“时,得到如图4所示搜索结果。
在搜索结果中,前10个被搜索出的URL都是与主题“java“相关的。
3.3 实验及性能评价
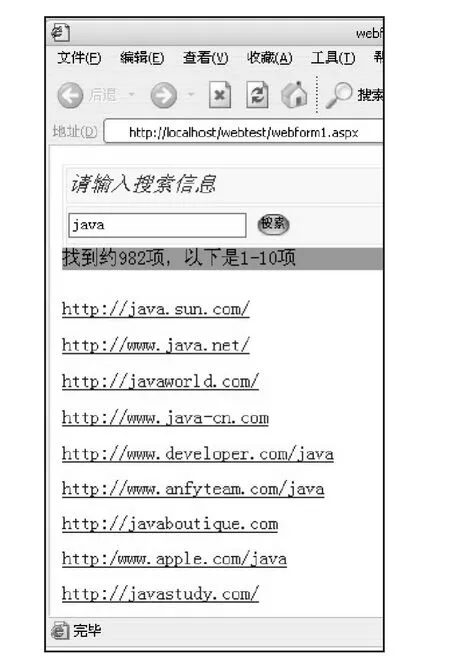
图4 搜索结果Fig.4 Search results
Web挖掘需要的数据集往往非常庞大,Web社区的挖掘需要更大数据资源才能体现算法的性能和优越性,为了测试算法的效果和验证它的有效性,本系统分别选择10个互不相同的主题页面作为种子节点,前5个选择了以中文为关键字的查询主题,后5个选择了英文为关键字的查询主题,每一个主题都具有明确的意义。表1中列出了利用本系统的算法和利用原系统算法发现社区的情况比较。
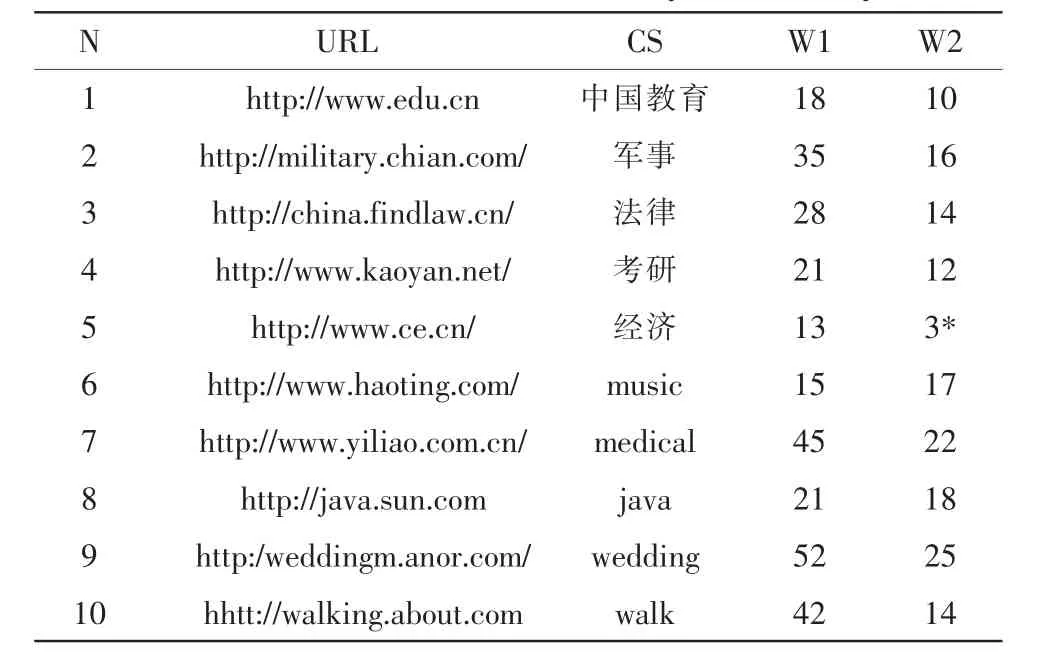
表1 两种系统发现社区情况比较Tab.1 The contrast found in community of the two systems
其中 N、URL、CS、W1、W2 分别表示节点、种子节点、社区主题、本系统算法获得的社区成员数及原系统算法获得社区成员数。W2竖排的第5主题上面标有一个“*”,表示在这种情况下所获得的社区体积都是不合理的失败情况。
如表1所示,本系统算法所获得的社区W1在总体上要明显好于原来系统算法的结果,原来的系统虽然在某些情况下确实获得了比较好的结果,但在另外一些情况下却产生了非常坏的结果,比如在主题5情况下,所获得的结果就不理想。
4 结束语
Web在发展过程中存在大量的社区,社区可以为用户提供有价值的、可靠的、及时的信息。本文在深入研究了Web社区[7]结构挖掘算法的基础上开发了一个改进的Web社区结构挖掘系统。实验证明,利用该系统进行Web社区挖掘,能很好的解决主题漂移、噪音页面等问题,从而发现更多有价值的社区。
[1]杨杰,姚莉秀.数据挖掘技术及其应用[M].上海:上海交通大学出版社,2011.
[2]李星,钟志农,景宁,等.社区挖掘技术研究[J].计算机工程与科学,2012,34(9):157-158.
LI Xing,ZHONG Zhi-nong,JING Ning,et al.Research on community detection methon[J].Computer Enginteering and Science, 2012,34(9):157-158.
[3]陈丽萍.基于Web链接结构的挖掘算法研究与应用[J].巢湖学院学,2011,13(6):39-40.
CHEN Li-ping.Research and application of mining algorithm basedonWebhyperlinkstructure[J].JournalofChaohu College,2011,13(6):39-40.
[4]刘兵.Web数据挖掘[M].北京:清华大学出版社,2009.
[5]Takaffoli M,Sangi F,Fagnan J,et al.Community evolution mining in dynamic social networks[J].Procedia-Social and Behavioral Sciences,2011,7(55):49-58.
[6]李莹,吴晓军.基于最大流及页面相似度的Web结构挖掘[J].计算机技术与发展,2011,21(10):112-113.
LI Ying,WU Xiao-jun.Web structure mining based on maximum flow and page similar value[J].Computer Technology and Development,2011,21(10):112-113.
[7]李刚.基于SOA的Web GIS系统框架设计分析[J].陕西电力,2011(2):38-41.
LI Gang.Web GIS system frame design analysis based on SOA[J].Shaanxi Electric Power,2011(2):38-41.
An improved Web community structure mining system
LUO Cai-jun
(Department of Computer Science, Shaanxi Vocational and Technical College, Xi’an 710100, China)
For the topic drift,noise pages and other problems of the HITS algorithm and the traditional maximum flow algorithm in mining Web community,maximum flow improvement algorithm based on transmission probability's side capacity assignment is used, an improvement Web community structure mining system is developed,and described this system design and the realization process in detail.It is proved with numbers of experiment that the system of the community structure mining can well solve problems of traditional algorithm,the accuracy of the Web community mining is more improved.
structure mining; Web community; system structure; seed node
TP391
A
1674-6236(2014)12-0034-03
2013-12-26稿件编号201312218
陕西省教育厅科学研究计划项目(2013JK0433);陕西职业技术学院国家骨干高职院校建设项目课题(GJ1314)
罗彩君(1979—),女,湖南桂东人,硕士,副教授。研究方向:计算机应用技术、数据处理。
猜你喜欢
保健医苑(2022年1期)2022-08-30
机械工业标准化与质量(2022年6期)2022-08-12
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
电子测试(2015年18期)2016-01-14
中国卫生(2015年12期)2015-11-10
通信技术(2012年4期)2012-02-15
