
基于改进异步DBN模型的听视觉融合情感识别
2014-09-12 11:17张晓静蒋冬梅FANPingSAHLIHichem
计算机工程与应用 2014年21期
张晓静,蒋冬梅,FAN Ping,SAHLI Hichem
1.西北工业大学计算机学院,西安 710072
2.陕西省语音与图像信息处理重点实验室,西安 710072
3.布鲁塞尔自由大学电子与信息系,比利时布鲁塞尔 1050
基于改进异步DBN模型的听视觉融合情感识别
张晓静1,2,蒋冬梅1,2,FAN Ping3,SAHLI Hichem3
1.西北工业大学计算机学院,西安 710072
2.陕西省语音与图像信息处理重点实验室,西安 710072
3.布鲁塞尔自由大学电子与信息系,比利时布鲁塞尔 1050
提出了一个改进的三特征流听视觉融合异步动态贝叶斯网络情感模型(VVA_AsyDBN),采用面部几何特征(GF)和面部主动外观模型特征(AAM)作为两个视觉输入流,语音Mel倒谱特征(MFCC)作为听觉输入流,且视觉流的状态和听觉流的状态可以存在有约束的异步。在eNTERFACE’05听视觉情感数据库上进行了情感识别实验,并与传统的多流同步隐马尔可夫模型(MSHMM),以及具有两个听觉特征流(语音MFCC和局域韵律特征LP)和一个视觉特征流的听视觉异步DBN模型(T_AsyDBN)进行了比较。实验结果表明,VVA_AsyDBN获得了最高识别率75.61%,比视觉单流HMM提高了12.50%,比采用AAM、GF和MFCC特征的MSHMM提高了2.32%,比T_AsyDBN的最高识别率也提高了1.65%。
听视觉融合;动态贝叶斯网络;主动外观模型(AAM);异步约束
1 引言
如果计算机能够感知和响应人类的情感,人机交互将会变得更加自然,因而情感识别逐渐成为多个领域的热门研究课题,如心理学、认知学以及计算机科学等,而大多数研究只关注单特征流信息,如听觉上的语音韵律信息[1]或视觉上的面部表情信息[2]。近年来,出现了一些听视觉融合多模态情感识别方法,所采用的融合策略包括特征层融合、决策层融合和模型层的融合。其中,特征融合[3]可能由于特征空间的扩大,带来维数灾难而导致识别率下降,而决策层融合[3-4]则忽略了听觉和视觉信息之间的关联关系。为了更加合理地融合听觉和视觉的情感信息,文献[5]提出了多流融合隐马尔可夫模型(Multi-Fused HMM,MFHMM),其听觉特征采用基频、能量等韵律特征,面部表情特征采用人脸纹理特征,基于最大熵和最大互信息准则,将听觉情感和视觉情感的两个HMM模型关联起来。文献[6]提出了三元HMM(triple HMM,THMM),允许特征流之间存在无限制的状态异步,采用语音韵律特征、上半部人脸几何特征和下半部人脸几何特征作为三个输入流进行情感识别。
然而,由于HMM结构的局限性,以上基于HMM的听视觉融合不能合理地描述听觉和视觉情感特征流之间的异步关系。为了更灵活地描述两者之间可能存在的异步,在前期工作中[7],提出了异步可控的双流动态贝叶斯网络模型(Asy_DBN),采用语音感知线性预测系数(PLP)作为听觉输入流,视频人脸的面部几何特征为视觉输入流,通过设置合理的听视觉流状态异步约束,Asy_DBN模型得到了比听觉单流或视觉单流HMM以及状态同步的多流HMM(MSHMM)都要高的识别率。在文献[8]中,进一步提出了三特征流混合的DBN模型(T_AsyDBN),以语音Mel倒谱特征(MFCC)和局部韵律特征(LP)作为两个听觉输入流,面部几何特征(GF)作为视觉输入流,并且允许听觉流和视觉流的状态在一定范围内异步。实验结果表明,T_AsyDBN模型获得了比MSHMM以及Asy_DBN更高的识别率。然而,由于每种情感的训练数据量有限,当训练和测试数据集发生改变时,实验结论不是很稳定。
考虑到在人类对于情感的感知中,从面部表情上获得信息量占主要成分,为了进一步提高情感识别的识别率以及鲁棒性,本文除了采用面部几何(GF)特征外,还另外提取了包含人脸形状和纹理信息的主动外观模型(AAM)特征[9]作为视觉特征流,同时对T_AsyDBN模型进行了修正,构建了包含两个视觉特征流和一个语音特征流的情感识别模型(VVA_AsyDBN),使得GF特征和AAM特征这两个视觉特征流在状态层同步,而它们与语音MFCC特征流之间允许在状态层异步。在eNTERFACE’05情感数据库上进行了听视觉融合情感识别实验,每种情感选取60句语句进行模型训练,六种情感共135句作为测试数据,并采用了Jack-Knife方法,以消除训练和识别样本较少造成的影响。识别结果表明,VVA_ AsyDBN比Asy_DBN和T_AsyDBN模型的识别率有了进一步提升,达到75.61%。
2 听视觉情感特征提取
本文在eNTERFACE’05数据库上进行听视觉情感识别实验。数据库包含六种基本情感:生气、高兴、悲伤、厌恶、害怕和惊奇。
2.1 听觉情感特征提取
(1)MFCC特征
对语音信号施加窗长为30 ms,帧移为10 ms的海明窗之后,用HTK工具包[10]提取14维MFCC及其一阶差分和二阶差分,得到42维的MFCC特征序列。
(2)基于基频和短时能量的局域韵律特征(LP)
在对语音信号施加窗长为30 ms,帧移为10 ms的海明窗后,分别提取每帧语音的基频和短时能量,然后以130 ms作为一个局部区域,计算该局域内基于基频和短时能量的韵律特征,包括其最大值、最小值、中值、均值、上升段斜率的最大值、下降段斜率的最小值,并以10 ms作为局部区域的位移,计算韵律特征的一阶差分,得到28维局域韵律统计特征。为了降低数据的冗余度,对特征进行了PCA降维,在本文实验中,最终得到了19维局部韵律特征。
2.2 视觉情感特征提取
(1)面部几何特征(GF)
在本文前期工作中[8],采用有约束的贝叶斯切形状模型(CSM)方法[11],检测和跟踪得到人脸图像序列的83个特征点。如图1(a)所示,83个特征点的标识位置如图1(b)所示。

图1 面部特征点跟踪结果及特征点标识
在此基础上,文献[8]定义了将眉毛,眼睛和嘴巴考虑在内的整个脸部的18维面部几何特征,与其一阶差分相结合形成了36维视觉特征[8]。经过PCA降维之后,得到21维面部几何特征。
为了进一步提高对头部运动(旋转、缩放和平移)的鲁棒性,本文对文献[8]提取的GF特征进行了改进:(1)对每帧面部图像应用仿射变换,针对中性表情面部图像进行了归一化操作。(2)考虑到特征点距离的动态变化,将每帧图像与中性图像的特征向量的差值作为新的面部几何特征。
(2)主动外观模型(AAM)特征
为了获得更加丰富的面部表情信息,本文使用AAM工具包(http://bagpuss.smb.man.ac.uk/~bim/software/)提取包含面部形状和纹理信息的AAM特征。在训练时从eNTERFACE’05数据库中选取12个人的720幅面部图像及其面部特征点来训练AAM参数,设置特征向量的贡献率为95%时,对每帧图像提取了26维AAM特征。考虑到动态特性,采用AAM特征与中性图像AAM特征的差值作为一帧图像的特征向量。
最后,为了与听觉特征的帧率100 frame/s相匹配,分别对帧率为25 frame/s的面部几何特征和AAM特征进行线性插值,将其内插为帧率为100 frame/s的特征向量序列。
因此,当一句音视频语音结束之后,分别离线提取其听觉情感特征和视觉情感特征,形成了同步的两个(或三个)动态特征流,作为情感识别模型的输入。
3 改进的三特征流听视觉情感识别模型
3.1 VVA_AsyDBN模型及参数
借用DBN灵活的结构和强大的描述功能,考虑到情感识别中面部信息的优越性,本文设计了异步可控的听视觉三特征流DBN情感识别模型,以面部几何特征和AAM特征作为两个视觉输入流,MFCC特征作为听觉输入流,而且两个视觉流在状态层同步,它们与听觉特征流可以在状态层异步。VVA_AsyDBN模型的结构如图2所示,包括三个部分:Prologue部分对模型进行初始化,Chunk块可以随着时间序列进行扩展,Epilogue部分描述了模型的结束帧,连线表示结点之间的条件概率。VVA_AsyDBN模型结点含义描述如表1所示。
在这个模型中,听觉状态和视觉状态能够在各自状态流内进行独立转移,但其异步程度由结点CA的值控制。CA表示听觉流和视觉流状态之间的距离,其条件概率分布为:

设音频流和视频流的最大状态数分别为AN和VN,听视觉流状态之间的最大异步约束为M,则AS和VS的条件概率分布分别定义为:


图2 VVA_AsyDBN模型结构

表1 VVA_AsyDBN模型结点含义描述
上式表明,当AS/VS没有达到最大状态数AN/VN,并且允许状态转移,同时异步程度在M的约束范围之内时,AS/VS可以发生状态转移,否则不允许转移。
t时刻产生听觉观测向量和视觉观测向量的联合概率为:
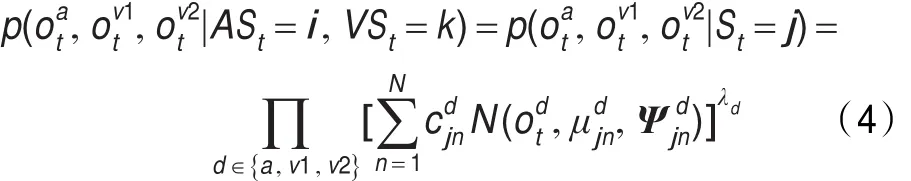
j为听视觉流的状态组合,对每个特征流d,,和分别是状态j的第n个高斯的权值、均值和方差阵,λd为三个特征流对应的权重,在本文实验中均设置为1。
3.2 基于VVA_AsyDBN模型的情感识别
本文采用图模型工具包GMTK[12]进行DBN模型的训练和识别。在训练时,对每一种情感训练一组DBN参数。在本文实验中,听觉最大状态数,视觉最大状态数和混合高斯数分别设置为3、3和8。在识别阶段,将一段视频的MFCC特征、面部几何特征和AAM特征输入到模型中,将最大似然概率对应的情感模型作为识别结果。
4 听视觉情感识别实验及分析
4.1 听视觉情感数据库
实验采用eNTERFACE’05听视觉情感数据库[13],该数据库由来自14个不同国家的42个说话人,在纯净语音环境下用英语进行录制,包括生气、高兴、悲伤、厌恶、恐惧、惊讶6种基本情感。对每种情感随机挑选60句作为训练数据,其他各种情感共135句作为测试数据。由于实验数据量较少,为了保证实验结果的稳定性,本文采用了Jack-Knife方法[14],对于每种情感,每次在训练集和测试集中分别选取10句进行交换,循环3次,最终的情感识别结果是3次识别率的平均值。

表2 听视觉单流和多流情感识别结果(%)
4.2 实验结果分析
听觉/视觉单流HMM和听视觉多流模型的情感识别结果如表2所示,AHMM,VHMM分别代表听觉单流和视觉单流HMM,(n)表示听视觉状态之间的异步约束为n。
实验结果表明:
(1)视觉单流的情感识别率高于听觉单流,这一结果符合人类对情感的感知。在视觉单流识别中,以AAM为特征的VHMM(AAM)模型的识别率最高达到63.11%,也说明了AAM特征对情感识别的有效性。
(2)跟单流HMM相比,状态同步的双流HMM(MSHMM_AAM_MFCC)的识别率达到72.08%,而异步约束为1时的Asy_DBN_AAM_MFCC(1)模型的识别率又进一步提高到73.61%。
(3)对于三特征流模型,状态同步的MSHMM_AAM_ GF_MFCC识别率为73.29%,有两个音频流(MFCC和LP)和一个视频流(AAM)且异步约束为2的T_AsyDBN_ AAM_MFCC_LP(2)的情感识别率为73.94%,而本文提出的VVA_AsyDBN_AAM_GF_MFCC(2)模型在异步约束为2时,在所有模型中得到了最优的识别结果,达到75.61%。
5 结论及工作展望
本文提出了一个改进的听视觉融合三特征流DBN情感识别模型(VVA_AsyDBN),以面部几何特征和面部AAM特征作为视觉输入流,语音MFCC特征作为听觉输入流,而且两个视觉特征流在状态级同步,听觉特征流的状态与视觉特征流的状态之间可以存在有约束的异步。在eNTERFACE’05听视觉情感数据库上的情感识别实验结果表明,本文提出的VVA_AsyDBN模型,效果不仅优于传统的状态同步的听视觉双流和听视觉三流HMM,而且识别率比听视觉双流异步的Asy_DBN模型以及T_AsyDBN模型又有了进一步提升,达到了75.61%。本文的不足之处在于:由于CSM算法不能实时跟踪面部特征点,导致视觉特征的提取不能实时,因此不能做到实时的听视觉情感识别。在进一步工作中,将尝试应用AAM进行面部特征点跟踪,以提高视觉情感特征提取的实时性。同时,还将扩展在其他听视觉情感数据库中的情感识别实验,以进一步验证VVA_AsyDBN模型的有效性。
[1]Metze F,Polzehl T,Wagner M.Fusion of acoustic and linguistic features for emotion detection[C]//IEEE Int Conf on Semantic Computing(ICSC’09),2009:153-160.
[2]Yang Peng,Liu Qingshan,Metax D N.Boosting encoded dynamic features for facial expression recognition[J].Pattern Recognition Letters,2009,30(2):132-139.
[3]Busso C,Deng Z,Yildirim S,et al.Analysis of emotion recognition using facial expressions,speech and multimodal information[C]//ACM Int Conf on Multimodal Interfaces,2004:205-211.
[4]Zeng Z,Tu J,Liu M,et al.Audio-visual affect recognition[J].IEEE Trans on Multimedia,2007,9(2):424-428.
[5]Zeng Z,Tu J,Pianfetti,et al.Audio-visual affective expression recognition through multi-stream fused HMM[J].IEEE Transactions on Multimedia,2008,10(4):570-577.
[6]Song M,You M,Li N,et al.A robust multimodal approach for emotion recognition[J].Neurocomputing,2008,71(10/12):1913-1920.
[7]Chen D,Jiang D,Ravyse,et al.Audio-visual emotion recognition based on a DBN model with constrained asynchrony[C]//Proc Int Conf Image and Graphics(ICIG),2009:912-916.
[8]Jiang Dongmei,Cui Yulu,Zhang Xiaojing,et al.Audio visual emotion recognition based on triple-stream dynamic Bayesian network models[C]//LNCS 6974:Affective Computing and Intelligent Interaction,2011:609-618.
[9]Cootes T F,Edwards G J,Taylor C J,et al.Active appearance models[C]//LNCS 1407:Computer Vision,1998:484-498.
[10]Young S,Kershaw O D,Ollason J,et al.The HTK book[M]. Cambridge:Entropic Ltd,1999.
[11]Hou Y,Sahli H,Ravyse I,et al.Robust shape based head tracking[C]//LNCS 4678:Proc the Advanced Concepts for Intelligent Vision Systems,2007:340-351.
[12]Bilmes J,Zweig G.The graphical models toolkit:an open source software system for speech and time series processing[C]//Proc ICASSP,2002:3916-3919.
[13]Martin O,Kotsia I,Macq B,et al.The eNTERFACE’05 audio-visual emotion database[C]//Proc 22nd Int Conf on Data Engineering Workshops,2006.
[14]Wu C F J.Jackknife,Bootstrap and other resampling methods in regression analysis[J].The Annals of Statistics,1986,14(4):1261-1295.
ZHANG Xiaojing1,2,JIANG Dongmei1,2,FAN Ping3,SAHLI Hichem3
1.School of Computer Science,Northwestern Polytechnical University,Xi’an 710072,China
2.Shaanxi Provincial Key Laboratory on Speech and Image Information Processing,Xi’an 710072,China
3.Department of Electronics and Informatics,Vrije Universiteit Brussel,Brussel 1050,Belgium
This paper proposes a modified triple stream asynchronous DBN model(VVA_AsyDBN)for audio visual emotion recognition,with the two visual feature streams,facial geometric features(GF)and facial active appearance model features(AAM),synchronous at the state level,while they are asynchronous with the audio feature stream(Mel Filterbank Cepstrum Coefficients,MFCC)within controllable constraints.Emotion recognition experiments are carried out on the eNTERFACE’05 database,and results are compared with the traditional state synchronous Multi-Stream Hidden Markov Model(MSHMM),as well as the asynchronous DBN model(T_AsyDBN)with two audio feature streams(MFCC and local prosodic features LP)and one visual feature stream.Results show that VVA_AsyDBN obtains the highest performance up to 75.61%,which is 12.50%higher than the visual only HMM,2.32%higher than the MSHMM with MFCC,AAM and GF features,and 1.65%higher than the T_AsyDBN model with MFCC and LP features as well as AAM features.
audio visual fusion;Dynamic Bayesian Network(DBN);Active Appearance Model(AAM);asynchrony constraint
A
TP391.4
10.3778/j.issn.1002-8331.1211-0289
ZHANG Xiaojing,JIANG Dongmei,FAN Ping,et al.Audio visual emotion recognition based on modified asynchronous DBN models.Computer Engineering and Applications,2014,50(21):162-165.
国家自然科学基金(No.61273265);陕西省国际科技合作重点项目(No.2011KW-04)。
张晓静(1988—),女,硕士研究生,主要研究方向:听视觉融合的语音情感分析;蒋冬梅,女,教授,主要研究方向:语音处理、听视觉融合的语音情感识别和面部动画合成;FAN Ping,女,博士生;SAHLI Hichem,男,教授,主要研究方向:视频与图像处理。E-mail:jiangdm@nwpu.edu.cn
2012-11-23
2013-01-24
1002-8331(2014)21-0162-04
CNKI出版日期:2013-03-13,http://www.cnki.net/kcms/detail/11.2127.TP.20130313.0946.009.html
猜你喜欢
计算机工程(2020年3期)2020-03-19
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
小学生作文(低年级适用)(2019年5期)2019-07-26
中国听力语言康复科学杂志(2019年3期)2019-06-24
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
中国交通信息化(2018年3期)2018-06-13
读友·少年文学(清雅版)(2018年12期)2018-04-04
中国交通信息化(2016年2期)2016-06-06
