
LS-SVM时间序列预测
——免疫文化基因算法进行LS-SVM参数选优
2014-09-12 11:17王波梅倩
计算机工程与应用 2014年21期
王波,梅倩
重庆大学计算机学院,重庆 400030
LS-SVM时间序列预测
——免疫文化基因算法进行LS-SVM参数选优
王波,梅倩
重庆大学计算机学院,重庆 400030
针对最小二乘支持向量机(LS-SVM)在时间序列预测中的参数不确定问题,在训练阶段,使用结合了全局搜索和局部搜索的免疫文化基因算法来进行参数寻优。实验中通过对Lorenz时间序列和建筑能耗的两组预测实验,对比了免疫文化基因算法、遗传算法和网格搜索算法对LS-SVM参数的优化效果,证明了免疫文化基因算法的优化效果最好,且LS-SVM的预测精度比支持向量机(SVM)和BP网络预测都要高。
时间序列预测;最小二乘支持向量机;文化基因算法;能耗预测
1 引言
时间序列指存在于自然科学或社会科学中的某一变量或指标的数值或观测值,按照其出现时间先后次序,以相同的间隔时间排列的一组数值[1]。自从20世纪60年代以来,来自天文、水文、气象等领域如太阳黑子、径流量、降雨量等时间序列都被发现含有混沌特性。时间序列预测技术在复杂系统建模、数据流技术和故障诊断等领域都具有较为广泛的应用,是当前理论研究的热点之一。
基于传统统计学的预测方法是利用时间序列之间的相关性来建立线性预测模型,如回归模型、移动平均模型、自动回归滑动模型[2]等方法虽然建模机理简单,建模和预测速度快,适用于对线性、平稳的时间序列建模,但实际应用中采集到的时间序列一般是非线性、非平稳的,所以这些方法建立的线性模型与非线性系统部匹配,导致预测精度下降。而基于上面的线性模型改进的ARIMA模型、自回归条件异方差模型、广义自回归条件异方差模型与小波分解等理论结合的局部建模[3]等方法虽然在一定程度上解决了非线性时间序列的预测问题,但是这些方法的针对性较强,对不同的时间序列未必适用,通用性较差。目前基于人工神经网络(ANN)的方法也广泛使用在时间序列预测中,如Elman网络、回声状态网络[4-5]等,ANN具有较强的非线性逼近能力、自学习能力和并行协同处理信息的能力,在时间序列的预测中精度较高,但其自身也存在参数选择困难、计算复杂度高、过学习和收敛于局部最小值的现象,当特征空间维数增大时,其运算量将急剧增加,导致ANN难以处理高维问题。
支持向量机(SVM)是Vapnik于1995年首先提出的一种新型的机器学习算法,它解决了以往机器学习方法中小样本、高维数、局部极小、非线性等问题[6]。SVM采用结构风险最小化准则,将泛化误差的上界最小化,而不是将训练误差最小化,因此泛化能力较强,并且它通过核函数实现了到高维空间的线性映射。SVM模型的这些优点使之成为了时间序列预测领域的研究热点。
2 LS-SVM简介
2.1 LS-SVM模型
LS-SVM是SVM的改进算法,用等式约束代替标准支持向量机中的不等式约束条件,极大减少了SVM由于求解二次规划问题带来的大量复杂计算。作为一种通用函数逼近器,LS-SVM可以以任意精度逼近非线性系统,它的预测原理介绍如下:

则x时刻输出模型如式(6)所示:

2.2 模型参数对预测效果影响分析
在训练LS-SVM模型阶段中关键问题就是参数的选取,即模型待确定参数C和核参数σ[8]。正则化参数C的主要作用是调节经验风险和正则化部分的平衡关系,决定对误差平方项的惩罚力度。C越小对误差的平方项的惩罚力度越小,对各个点的约束力变小,回归曲线趋于平坦,回归机可能出现欠学习现象,导致预测精度下降;C越大则对偏差的惩罚力度越大,LS-SVM构造的回归曲线会尽力使得各点距回归曲线的误差最小,过度要求极小化训练误差容易导致训练过程中产生过学习现象,使预测过程中模型的泛化能力下降。
RBF核函数的函数宽度系数σ控制最终解的复杂性。σ越小误差容限ξ-带越敏感,核映射更容易局部化,容易导致训练的回归机有过学习现象,导致模型的泛化能力下降;σ越大则误差容限ξ-带越不敏感,回归曲线趋于平坦,这样可能会导致回归机的欠学习现象。因此参数的选取会决定模型预测输出和系统实际输出之间的误差大小,直接影响到LS-SVM的泛化能力和预测精度。
文献[9]通过遗传算法来进行预测,具有一定的现实意义。但是算法在参数寻优过程中会出现因遗传优秀个体的破坏而导致优化过程不完全收敛,而且会陷入局部最优。因此本文利用能克服局部最优缺点的免疫文化基因算法进行LS-SVM参数的选优。
3 免疫文化基因算法选择最优C和σ
文化基因算法[10-13]是一种基于种群的全局搜索和基于个体的局部搜索的混合算法,它引入了局部搜索机制,结合了群体算法搜索范围大的优点和局部搜索算法的深度优势。该算法实质上是一种框架,在此框架下采用不同的搜索策略可以形成不同的文化基因算法。针对LS-SVM的参数优化问题,本文采用克隆算法进行全局搜索,用Baldwin学习作为局部搜索策略。
为了避免在优化过程中产生过拟合和欠学习的情况,将初始的含有N个样本的总训练样本集分成两个子样本集,用一个子样本集进行训练,另一部分子样本集进行验证,对于检验训练优化的效果,用验证样本的评价绝对误差(MAE)作为评价依据,因此对MAE取倒数作为个体评价标准:

3.1 危险信号提取
免疫克隆选择算法是通过种群初始化、克隆、变异、选择等操作对候选抗体进行进化的一种进化算法。免疫学基本原理认为,对于所有异己抗原,其最优匹配可通过免疫响应进行选择[14],基于免疫危险理论,将种群浓度的变动作为环境因素,以抗体与抗原的亲和力为依据计算各个抗体在该环境因素下的危险信号,最终通过危险信号自适应地引导免疫克隆、变异和选择等后续免疫应答过程。
定义一种危险信号函数gi如式(9)所示,模拟不同种群下各抗体所处危险信号状况。该函数以当前种群平均浓度和各抗体—抗原亲和力为输入,产生该抗体所处危险信号值向量[11]。

其中,fit(Ai)为抗体Ai的抗体—抗原亲和力的归一化表示,归一化可采用各种不同的方式[14];C为抗体种群平均浓度;α和β为调节参数,一方面控制种群浓度和抗体—抗原亲和力值对危险信号的影响程度,另一方面使危险信号值gi∈[α,α+β]。可以看出,种群平均浓度越小,抗体多样性越大,因而在此环境中各抗体所处危险信号相应较大,该危险信号值引导后面的克隆扩增、变异及免疫选择过程。
3.2 Baldwin效应
Baldwin效应是指如果父代学到某些有用的特性,那么它的后代也有很大的概率获得同样的特性[14]。这种免疫系统的增强学习机制,使得抗体亲和度进一步提高。使用这种免疫系统的Baldwin效应,通过对最优值阈值附近的个体进行鼓励来加快进化过程,这些解通过简单的调整(即学习)就有可能成为较优解。具体而言,把Baldwin效应引入到算法设计中,对亲和度值较大的抗体进行一定的鼓励,提高它的生存率,加快算法的收敛速度。具体方法如下:
假设抗体Ai原来的亲和度值为fit(Ai),则学习激励后的抗体亲和度为:

3.3 免疫文化基因算法设计
本文用免疫文化基因算法实现LS-SVM参数优化的流程图如图1所示,算法实现步骤如下:
(1)生成初始种群解(候选解集)P,种群大小取100,α和β分别取0.06、0.8,w(Ai)取1.3。使用二进制编码,每个抗体由参数C和σ的二进制编码组合而成。
(2)对种群解中的每个个体代入LS-SVM模型,用式(8)进行评价,即每个个体的亲和度。
(3)根据式(9)进行危险信号提取操作,获得各个抗体的危险信号值。
(4)根据每个抗体的亲和度值进行克隆扩增操作,克隆数量与抗体的危险信号值成比例,抗体的危险信号值越大,浓度越小,则克隆数量越大,即
(5)选取群体中性能最好的20%的抗体作为精英粒子,采用第3.2节的局部搜索策略对精英抗体进行优化,更新个体和全局极值点。
(6)对克隆种群进行高频变异,变异概率为Pm=0.5,获得一个变异后的抗体群C*。设计了一种自适应变异概率,保证算法在进化初期采用较大的变异尺度以保持种群的多样性,而在进化后期采用较少尺度的变异,以提高局部微调能力。其中,变异概率为,其中t为进化代数。
(7)对C*中所有抗体进行解码,得到各个优化参数的实际值,用训练样本训练LS-SVM,并根据式(8)对当前个体进行评价,重新选择亲和度高的改进个体产生下一代候选解P。
(8)令进化次数t=t+1,如果t<tmax,则转到步骤(2)。
(9)输出最优解,建立LS-SVM预测模型。

图1 算法流程图
4 仿真实验与分析
4.1 混沌时间序列预测
利用Lorenz混沌方程:

其中,a,b和r都是常数,当取a=10,b=8/3,r=28,x(0)=10,y(0)=1及z(0)=0时,系统产生混沌。利用四阶Runge-Kutta法迭代产生混沌时间序列,步长为0.02,延迟时间和嵌入维数分别取13和3。生成1 000个Lorenz时间序列数据,如图2所示,前500个数据用于训练LSSVM模型,后500个数据用于对训练好的LS-SVM进行测试。

图2 Lorenz时间序列
本文选用Matlab R2010a作为实验仿真平台,为了检验预测效果,用归一化均方根误差NRMSE(Normalized Root Mean Square Error)对学习效果和预测结果进行评价,NRMSE的计算如式(12)所示。其中xt为能耗时间序列实际值,为预测值,n为预测的数据个数。
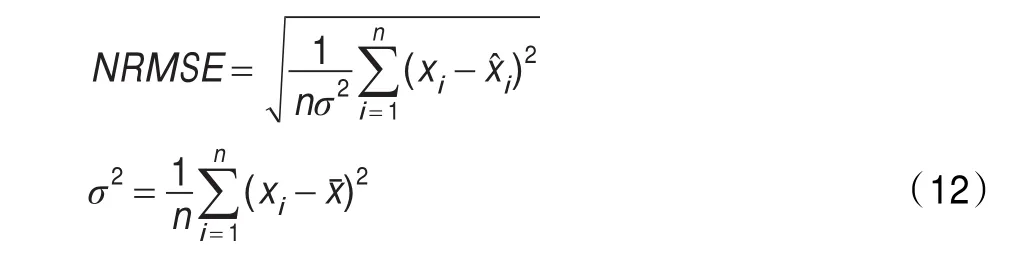
分别采用免疫文化基因、遗传算法、网格搜索优化的LS-SVM,SVM和BP神经网络,连续进行500步长单步预测。LS-SVM参数C和σ分别初始化为10和0.1,迭代次数为100。SVM模型的参数C=10,p1=75。BP神经网络模型的隐藏层节点数设为20,第一层传递函数为tansig,输出层传递函数为purelin,迭代1 000次。
从图2和图3中可以看出本文方法和传统LS-SVM分别对Lorenz时间序列的预测情况和误差对比,表1中对四种预测方法的对比可看出,本文方法由于采用了基于免疫算法全局搜索与基于Baldwin效应局部搜索结合的方法,相比遗传算法与网格搜索算法0.091 9和0.098 7的测试误差,能更快速地找到最优解,测试误差为0.086 5,相比SVM、BP分别为0.121 9、0.315 6的测试误差,免疫文化基因算法优化的LS-SVM误差为0.086 5,对时间序列预测更加准确,且没有因为学习误差较低而产生过拟合现象。

图3 Lorenz时间序列预测结果
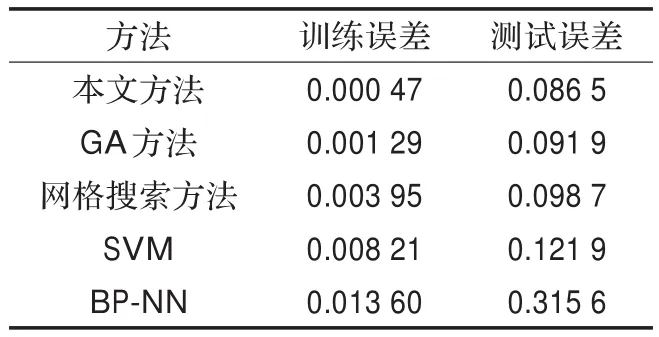
表1 Lorenz预测对比结果
4.2 建筑能耗预测
为了进一步验证方法的有效性和实用价值,结合建筑能耗值进行预测,文献[15-16]中已有将SVM、BP神经网络用于建筑能耗预测的研究,下面实验中将这几种算法进行对比。建筑能耗数据如图4所示。

图4 建筑能耗数据

图5 建筑能耗预测结果
对重庆某综合大楼实行能耗采样计量,本文选取夏季8月份的能耗数据(见图5所示),以耗电量作为主要研究对象,每隔1 h对能耗数据采样一次,预测步长为24,即用前后两天同一时刻数据作为输入输出对。若要预测第di天24 h的能耗数据,则输入序列为{di-1(1),di-1(2),…,di-1(24)},对应的输出为{di(1),di(2),…,di(24)}。
预测月末最后一天的能耗情况如图5所示,可以看出免疫文化基因算法优化的LS-SVM逼近真实值。各种预测方法应用在建筑能耗预测中的对比结果如表2所示。四种方法的测试误差分别为0.194 3、0.275 1、0.327 1和0.573 6,本文方法比遗传算法优化LS-SVM、SVM和BP网络无论在学习精度还是预测精度上都有所提高,更适用于建筑的能耗预测。通过预测得到较精确的能耗值,与实际值的比较,可以实时地监测建筑能耗是否正常,将预测方法嵌入到建筑能耗管理系统中,可以为建筑节能管理提供一种手段。不失一般性,水、燃气等用量的实时预测也可使用该方法。

表2 能耗预测对比结果
5 结束语
本文在LS-SVM的训练阶段使用了免疫文化基因算法对参数进行了优化,该算法结合了全局搜索与局部搜索,收敛速度快,克服了一般优化算法容易陷入局部最优的缺点,相比遗传算法和网格搜索算法,本文的算法寻优效率更高。结合建筑能耗预测的实际应用,说明了本文方法具有实用价值,但本文方法训练预测过程是离线的,下一步的研究就是在本文方法的基础上设计在线预测方法。
[1]Farmer J D,Sidorowich J J.Predicting chaotic time series[J]. Physical Review Letters,1987,59(8):845-848.
[2]Contreras J,Espinola R,Nogales F J.ARIMA models to predict next-day electricity prices[J].Power Systems,2003,18(3):1014-1020.
[3]谢品杰,谭忠富,尚金成,等.基于小波分析与广义自回归条件异方差模型的短期电价预测[J].电网技术,2008,32(16):96-100.
[4]Chandra R,Zhang M.Cooperative coevolution of Elman recurrent neural networks for chaotic time series prediction[J].Neurocomputing,2012,86(1):116-123.
[5]Deihimi A,Showkati H.Application of echo state networks in short-term electric load forecasting[J].Energy,2012,39(1):327-340.
[6]Cortes C,Vapnik V.Support-vector networks[J].Machine Learning,1995,20(3):273-297.
[7]Ito K,Kunisch K.Karush-Kuhn-Tucker conditions for nonsmooth mathematical programming problems in function spaces[J].SIMA Journal on Control and Optimization,2011,49(5):2133-2154.
[8]Rubio G,Pomares H,Rojas I,et al.A heuristic method for parameter selection in LS-SVM:application to time series prediction[J].International Journal of Forecasting,2011,27(3):725-739.
[9]周辉仁,郑丕谔,赵春秀.基于遗传算法的LS-SVM参数选优及其在经济预测中的应用[J].计算机应用,2007,27(6).
[10]Gong Maoguo,Jiao Licheng,Zhang Lining,et al.Immune secondary response and clonal selection inspired optimizers[J].Progress in Natural Science,2009,19(2):237-253.
[11]刘合安,张群慧.免疫文化基因算法求解多模态函数优化问题[J].计算机应用研究,2012,19(12):4515-4517.
[12]Gong Maoguo,Jiao Licheng,Liu Fang,et al.Memetic computation based on regulation between neural and immune systems:the framework and a case study[J].Science China:Information Sciences,2010,45(11):2131-2138.
[13]张明明,赵曙光,王旭.基于Baldwin效应的自适应有性繁殖遗传算法及其仿真研究[J].系统仿真学报,2010,22(10):2229-2332.
[14]Matzinger P.The danger model:a renewed sense of self[J]. Science,2002,296(5566):301-305.
[15]DongB,CaoC,LeeSE.Applyingsupportvector machines to predict building energy consumption in tropical region[J].Energy and Buildings,2005,37(5):545-553.
[16]Kalogirou S A,Bojic M.Artificial neural networks for the prediction of the energy consumption of a passive solar building[J].Energy,2000,25(5):479-491.
WANG Bo,MEI Qian
College of Computer Science,Chongqing University,Chongqing 400030,China
Aiming at the problem that the parameters of Least Squares Support Vector Machines(LS-SVM)are uncertain in time series prediction,this paper utilizes immune clonal memetic algorithm which adopts the advantage of global search and local search to optimize the parameters of LS-SVM.Simulation results of Lorenz time sequence prediction and building energy consumption prediction show that the prediction accuracy of this optimization method is higher than genetic algorithm and grid search algorithm,and the comparison shows that the optimized LS-SVM produces better results than Support Vector Machines(SVM)and BP neural network.
time series prediction;Least Squares Support Vector Machines(LS-SVM);memetic algorithm;energy prediction
A
TP391
10.3778/j.issn.1002-8331.1212-0031
WANG Bo,MEI Qian.Time series prediction based on LS-SVM optimized by immune clonal memetic algorithm. Computer Engineering and Applications,2014,50(21):254-258.
王波(1960—),男,副教授,硕导,主要研究方向为建筑与城市智能化、物联网与网络安全、信息集成与系统集成;梅倩(1988—),女,硕士研究生,主要研究方向为时间序列预测、支持向量机、神经网络。E-mail:wangbo@cqu.edu.cn
2012-12-04
2013-01-19
1002-8331(2014)21-0254-05
CNKI出版日期:2013-03-26,http://www.cnki.net/kcms/detail/11.2127.TP.20130326.1042.016.html
猜你喜欢
今日农业(2022年15期)2022-09-20
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年23期)2021-03-08
华人时刊(2018年15期)2018-11-10
红土地(2018年7期)2018-09-26
兽医导刊(2016年12期)2016-05-17
肝博士(2015年2期)2015-02-27
现代检验医学杂志(2015年4期)2015-02-06
当代畜禽养殖业(2014年10期)2014-02-27
