
加权投票采样学习在用户信用评级中的应用
2014-09-12 11:17陈念唐振民
计算机工程与应用 2014年21期
陈念,唐振民
1.池州学院数学与计算机科学系,安徽池州 247000
2.南京理工大学计算机科学与工程学院,南京 210094
加权投票采样学习在用户信用评级中的应用
陈念1,2,唐振民2
1.池州学院数学与计算机科学系,安徽池州 247000
2.南京理工大学计算机科学与工程学院,南京 210094
以委员会投票查询算法为基础,提出在采样过程中动态修正分类器成员权值的加权投票方法。在对无标签样本标注价值评估中,该方法能够强化高精度分类器成员的查询贡献,降低高误差成员的投票影响,减少机器训练过程中的标注学习次数。通过在UCI的Statlog(Australian Credit Approval)数据集上对用户信用度级别进行识别,并比较于其他采样方法,证明该方法能够用较小的采样标注代价获取稳定的泛化精度。
主动学习;采样查询;加权投票;熵;标注门槛
金融用户信用评级是一种为金融组织或企业提供决策参考的社会服务,它揭示了受评对象按合同履行金融义务的能力、意愿及违约风险的大小。由于用户数量庞大,信用等级完全用人工方式评价较为困难,且在批量标注前提下精准度得不到保证,机器标注已成必然,如何有效利用无标签信息增强机器学习效果成为研究的要点。近年发展起来的主动学习(Active Learning)方法,在已标注样本数量不足,分类器得不到充分训练的条件下,通过选取一些无标签样本交由专家系统或人工进行标注,以此获得训练用数据。主动学习方式下,学习过程不再是被动接受由用户提供的数据[1],而是自主选择一些包含信息量大,针对性强的高价值样本经过标注后再进行学习。
主动学习的数据场景常见的有基于池的和基于流的两种,前者假设有两个信息池的存在:能提供前期训练的有标签样本池,和拥有大量可供选择样本的无标签池;后者中无标签样本则依照时间节点顺序到达。池场景机器学习的研究成果已在文本分类[2]、信息提取[3]、视频分类与检索[4]等诸多领域得到有效应用,基于流场景的研究也取得了较大进展,如在不良用户评论过滤[5]、网页广告点击预测[6]等网络问题的处理上。已有的无标签样本评价采集方法主要分三种[7]:一是基于不确定性的采样,即选择类别划分不确定性大的样本标注后加入训练集,如边界采样(Margin sampling)[8],最小-最大视图采样(QUIRE)[9]等。二是基于版本空间缩减的采样,委员会投票方法QBC[10]就是其中最具代表性的算法,如某个无标签样本在经过多个分类器投票后,熵值较大,那么它应标注后去训练分类器。在此基础上改进的Boosting_QBC[11]和Bagging_QBC[12]算法都能很好适应复杂的数据环境和分类模型。三是基于误差缩减的采样,它可以有效避免野值点对分类器的干扰,如Fisher信息法等。
本文的讨论是基于样本池场景和委员会投票QBC算法之上的。首先用Bagging算法生成多个投票弱分类器(委员会),再通过对各分类器加权的方法调整不同成员投票对样本熵值的影响。在采集标注到一个训练用样本后,进行类别预测投票,并依据各分类器的投票误差修正相应权值,运用到下一轮样本评价中。该方法可以更有效收集到高信息量无标签样本用于训练,减少机器学习过程中与外部的交互次数,节约标注成本,同时不会影响到分类器精度。通过在UCI的Statlog(Australian Credit Approval)集上对用户信用度等级进行仿真识别,证明了该方法的有效性。
1 委员会投票算法
1.1 投票委员会的产生
设样本空间X被分成有标签集L={<xi,yk>}和无标签集UL={<xj>},其中yk∈Y,Y为类标识空间。Bagging算法每轮用随机方式在L中抽取m个样本构成子集SL,用SL训练分类器f获得模型参数ω,其中若干样本可以重复出现在不同轮次的训练子集中,经过p轮训练后即可产生p个参数,如图1。

图1 用Bagging方法产生投票委员会
由这些参数对应的分类器组成的集合称为委员会committee,其间每位成员对UL中的样本都能预测其类别,即=f(ω,x),由于单个ω是部分样本训练产生的,因此它对应的分类器的判断能力是较弱的。投票算法的思路在于:对xj∈UL,统计所有成员对它的投票结果V(y,xj),样本最终划分到得票数最多的类,即

这种将多个弱分类器集成的做法,可以有效克服单个分类器预测的不足,但它并未考虑委员会成员间的精度差异,没有合理利用分类器样本预测过程中的经验,导致在不确定性高的样本投票上缺乏参考性,需要更多依赖外部决策。
1.2 熵度量的引入
熵值是度量不确定性的有效指标,投票结果用熵值反映更利于理解和处理,熵值越大说明样本类别归属的不确定性越高,需要高一级的判别系统(专家系统或人工)介入。Argamon提出了投票熵的概念[13]。

其中,|Y|为类别数,V(y,xj)是s个委员会成员对无标签样本xj的投票结果,ε为微调量,当某类得票数为0时,防止lb0情况的出现。投票熵是根据“硬性”投票方式进行计算的,即对样本的类别投票只有属于(1)或不属于(0)两种可能。相对熵,又称KL散度,是另一种不确定性度量形式,样本的类别划分用概率的形式描述。

相对熵度量的是样本xj属于某一类yi的概率,与属于各类平均概率间的差异,体现了样本归类的概率相对性。
2 基于投票查询的采样
基于委员会投票的采样方法(Query By Committee)由Seung和Freund等人提出[14-15],是一种基于版本空间缩减的算法,通过在无标签样本池UL中采集样本,在委员会投票之后,计算其熵值,将熵值是否超过标注门槛作为标注学习与否的依据。图2给出了流程简图。

图2 投票采样方法流程简图
2.1 加权投票采样方法
在1.1节中提到,用Bagging方法产生的投票委员会,其成员对任一无标签样本的熵值影响是相同的。但实际情况是:对UL中的样本,委员会部分成员的预测准确率较高,而另外一些则相对较低,若这些前期经验没有得到合理利用,对后续一些分类难度偏高的样本,不能由投票方式直接决定其类别,需要更多次数的专家或人工标注,这无疑增加了学习的成本。本文通过对委员会成员的投票加权的方式,来调整不同精度的弱分类器对熵值的影响,并在后续的学习中动态修正权值,以达到降低主动学习中与外部交互次数的目标。
用委员会F={f(ω1),f(ω2),…,f(ωp)}对有标签测试集L中的n样本分别进行类别投票,计算预测误差:
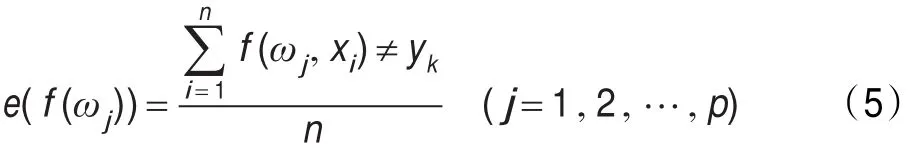
式中,yk为样本xi的真实标签。依据误差e给对应的分类器赋予权值wj:

微调常量ε的作用同样是为防止误差为0时,除0情况的出现。为使wj>0,则区别于一般委员会,加权分类器成员误差需满足据此,委员会对样本xi属于某类y的投票结果可表示为:
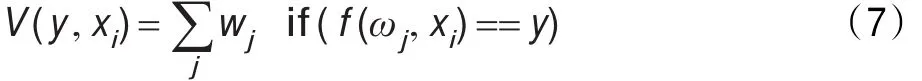
用式(7)的投票结果计算样本的熵值,更能发挥高精度分类器在无标签样本类别判定中的作用,使一部分样本的归类由机器自行解决,而不需要专家系统或人工的介入。若投票熵值仍然超过预先设定的阈值θ,则该样本需进行类别标注,作为学习样本加入训练集L。
2.2 投票权值的更新
在采集标注一个新样本后,委员会中所有的成员要对它进行学习,学习的方式仍然是对该新样本进行类别预测。预测结果同样会出现正确和错误两种情况,据此进一步调整委员会成员的权重,来获得泛化性能更强的分类器集合。本文提出一种权值调整方法,设分类器f(ωj)在时刻t的权值为,则对一个新样本xi的类标预测后,其权值调整为,令



3 实验与结果分析
实验用随机标注(Random Choice)、委员会投票标注(Query By Committee)及加权委员会投票标注(weighted QBC)三种采样算法采集到的样本进行分类器训练,对比采样标注数量与训练精度,证明加权投票方法的高效性。用Matlab的SVM工具在UCI的Statlog(Australian Credit Approval)数据集上进行仿真。该数据集收集了用户信用卡的相关使用情况数据,并依此对持卡用户做出信用评级以作为信贷审批的依据,用户被分成两类:+(信誉度较好)和-(信誉度较差)。对多级信用评定的多类分类问题,可将其分解成若干个二分类问题加以解决。
实验将数据集按9∶1的比例随机分离出训练样本和测试样本,做10重交叉验证。在训练集中有标签池和无标签池的样本比例按1∶5进行设置。表1列出了实验数据组成及配置情况。
3.1 不同采样方法效率比较

图3中反应出三种方法的共同点在于:随着新采集样本的加入,分类器的训练效果都在不断增强,精度呈现上升趋势。随机方法在无标签池中的采样具有盲目性,获取样本的训练效果在三种算法中是最差的。QBC只选择投票熵值超过设定门槛θ的样本加入训练集,同等采集规模下其泛化精度是优于随机采样的,如图3在num=60时,两者精度差值接近5%。Weighted QBC方法在采样过程中,区分了不同精度分类器对样本熵值的影响,让更高信息量的样本通过标注方式进入训练集,因而能用相同的训练代价获得更高的识别准确率。

表1 实验数据组成及配置情况

表2 三种采样算法效率比较(%)

表3 不同委员会成员数对应的投票熵

图3 不同采样方法对应的精度比较
表2给出了三种算法在不同采样规模下的效率对比,其中Δnum=20。
表2中数据反映出训练样本采集的后期效率要明显低于前阶段,识别率提升幅度呈现出明显的放缓。三种方法中随机采样不加选择地采集标注样本,部分样本采集对分类器精度的提升贡献不大,因此在各种规模下效率都是相对较低的。Weighted QBC在QBC采样的基础上不断分化不同精度分类器对新样本评价的影响,有效减少了需要标注学习的样本数量,因而能体现出更高的工作效率。
3.2 参数设置对算法的影响
初始的参数设置会对Weighted QBC算法的性能产生影响,它们包括投票成员的数量(Bagging训练的轮次),初始预测能力(Bagging每轮训练所用的样本数),标注门槛值θ。投票成员需满足一定的数量才能为样本的标注与否提供有价值的参考,表3列出了二分类模型下,四种不同的委员会成员数对应的可能熵值。
可以看出,在投票成员数目偏小时,熵的可能取值也会相应较少,为样本提供标注参考的能力就会相对较弱。如在只有3个成员进行投票的情形下,熵的取值只有0和0.918 3两种可能性,导致会有大量的样本不能通过分类器直接决定其类别,而需要通过专家或人工标注获取其标签。同样,Bagging初始训练所使用的样本数多少决定了投票成员的预测能力强弱,强分类器在一般样本的类别预测上,会体现出较高的一致性,降低熵值,减少标注学习的次数,而初始训练能采用的样本数取决于有标签集的规模|L|。
阈值θ也是影响标注次数的重要因素,采样次数会随着该参数值的增加而递减,当θ=0时,QBC采样就退化成随机采样,θ过小的取值会导致信息量近似的样本被冗余标注,增大机器学习负担;而过大的值则会让采样过程中一些学习价值较高的样本被遗漏,分类器得不到有效的训练。表4给出了不同的标注门槛下,Weighted QBC在无标签池中的采样次数。

表4 不同的阈值θ对应的样本采集次数
4 结束语
本文在分析委员会投票采样QBC算法的基础上,针对投票过程中各分类器对无标签样本熵值的贡献相同,前期学习经验没有得到合理利用的情况,提出了加权投票采样方法Weighted QBC。统计委员会中成员对有标签样本的预测精度,并据此为不同的分类器赋予相应的权重;在每次采集标注到一个新样本后,根据现有成员对该样本类别预测的对错,调高或降低其权值,并运用到下一次的学习中去。该方法能够更好地发挥委员会中高精度成员的判别作用,减少机器学习过程中需要专家或人工标注的样本数量,压缩训练成本。通过在UCI的Statlog(Australian Credit Approval)数据集进行仿真,并与其他采样方法进行效率对比,证明了该方法的有效性。
[1]陈荣,曹永锋,孙洪.基于主动学习和半监督学习的多类图像分类[J].自动化学报,2011,37(8):954-962.
[2]Hoi S C H,Jin R,Lyu M R.Large-scale text categorization by batch mode active learning[C]//Proceedings of the International Conference on World Wide Web.[S.l.]:ACM Press,2006:633-642.
[3]Settles B,Craven M.An analysis of active learning strategies for sequence labeling tasks[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing.[S.l.]:ACL Press,2008:1069-1078.
[4]Hauptmann,Lin W,Yan R,et al.Extreme video retrieval:joint maximization of human and computer performance[C]// Proceedings of ACM Workshop on Multimedia Image Retrieval.[S.l.]:ACM Press,2006:385-394.
[5]Chu W,Zinkevich M,Li L,et al.Unbiased online active learning in data streams[C]//Proceedings of the 17th ACM SIGKDDInternational Conference on Knowledge Discovery and Data Mining.[S.l.]:ACM Press,2011:195-203.
[6]Graepel T,Candela J Q,Borchert T,et al.Web-scale Bayesian click-through rate prediction for sponsored search advertising in Microsoft’s Bing search engine[C]//Proceedings of the 27th International Conference on Machine Learning,2010:13-20.
[7]吴伟宁,刘扬,郭茂祖,等.基于采样策略的主动学习算法研究进展[J].计算机研究与发展,2012,49(6):1162-1173.
[8]Tong S,Koller D.Support vector machine active learning with applications to text classification[J].The Journal of Machine Learning Research,2001(2):45-66.
[9]Huang Shengjun,Jin Rong,Zhou Zhihua.Active learning by querying informative and representative examples[C]// Proc of NIPS 2010.Cambridge,MA:MIT Press,2010:892-900.
[10]Dagan I,Engelson S P.Committee based sampling for training probabilistic classifiers[C]//Proceedings of the 12th International Conference on Machine Learning,1995:150-157.
[11]Freund Y,Schapire R E.A decision-theoretic generalization of on-line learning and an application to boosting[J]. Journal of Computer and System Sciences,1997,55(1):119-139.
[12]Breiman L.Bagging predictors[J].Machine Learning,1996,24(2):123-140.
[13]Argamon E S,Dagan I.Committee-based sample selection for probabilistic classifiers[J].Journal of Artificial Intelligence Research,1999(11):335-360.
[14]Seung H S,Opper M,Sompolinsky H.Query by committee[C]//Proceedings of the 15th Annual ACM Workshop on Computational Learning Theory,California,1992:287-294.
[15]Freund Y,Seung H S,Samir E,et al.Selective sampling usingthequerybycommitteealgorithm[J].Machine Learning,1997,28(23):133-168.
CHEN Nian1,2,TANG Zhenmin2
1.Department of Mathematics and Computer Science,Chizhou University,Chizhou,Anhui 247000,China
2.Computer Science and Engineering College,Nanjing University of Science and Technology,Nanjing 210094,China
In this paper,a method of weighted voting is proposed which can adjust weights of classifiers in committee during the sampling process and it is based on query by committee algorithm.In process of unlabeled sample’s quality evaluation,the method can strengthen the contribution of high precision members,reduce the influence of high error members and decrease the times of learning which is needed in machine training.By experiment on dataset of Statlog(Australian Credit Approval)and compared results with other methods,the effectiveness has been proved that the algorithm can gain stable generalization accuracy with smaller costs of samples labeling.
active learning;sampling query;weighted voting;entropy;labeling threshold
A
TP391
10.3778/j.issn.1002-8331.1212-0281
CHEN Nian,TANG Zhenmin.Application of user credit rating based on weighted voting sampling algorithm.Computer Engineering and Applications,2014,50(21):259-263.
安徽省教育厅高等学校自然科学研究重点项目(No.KJ2012A211)。
陈念(1978—),男,副教授,主研方向:机器学习与人工智能;唐振民,教授,博导。E-mail:njustchennian@gmail.com
2012-12-24
2013-02-22
1002-8331(2014)21-0259-05
CNKI出版日期:2013-03-13,http://www.cnki.net/kcms/detail/11.2127.TP.20130313.0955.023.html
猜你喜欢
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
公民与法治(2016年10期)2016-05-17
新校长(2016年8期)2016-01-10
少儿科学周刊·少年版(2015年2期)2015-07-07
商事法论集(2014年1期)2014-06-27
电测与仪表(2014年15期)2014-04-04
中国中医药现代远程教育(2014年16期)2014-03-01
