
时态信息的语义抽取与排序方法研究及系统实现*
2014-09-13 12:44舒忠梅左亚尧张祖传
计算机工程与科学 2014年8期
舒忠梅,左亚尧,张祖传
(1.中山大学教育学院,广东 广州 510275;2.广东工业大学计算机学院,广东 广州 510006)
时态信息的语义抽取与排序方法研究及系统实现*
舒忠梅1,左亚尧2,张祖传2
(1.中山大学教育学院,广东 广州 510275;2.广东工业大学计算机学院,广东 广州 510006)
针对通用搜索引擎缺乏对网页内容的时态表达式的准确抽取及语义查询支持,提出时态语义相关度算法(TSRR)。在通用搜索引擎基础上添加了时态信息抽取和时态信息排序功能,通过引入时态正则表达式规则,抽取查询关键词和网页文档中的时态点或时态区间等时态表达式,综合计算网页内容的文本相关度和时态语义相关度,从而得到网页的最终排序评分。实验表明,应用TSRR算法可以准确而有效地匹配与时态表达式相关的关键词查询。
时态语义;信息抽取;排序;搜索引擎
1 引言
在互联网技术迅猛发展的今天,网络信息成几何倍数递增,百度、Google、Bing等搜索引擎工具为人们在网上查找信息提供了便捷。时间是信息的重要属性之一,许多网页的内容与时态信息密切相关,如新闻报道、出版信息、网店商品折扣等。用户常常需要根据时态检索请求准确地找到相应的网页,因此时态信息是搜索引擎系统必须考虑的重要因素之一。
学者们逐渐开始关注时态给Web信息处理带来的问题,Alonso O等[1]从时态信息的意义出发,认为将抽取出的时态信息应用于当前的搜索引擎,将会大大提升搜索引擎产品的性能,肯定了时态信息在检索领域的研究意义。Whiting S、Choi J等学者[2,3]从Web页面的发布时间或最后更新时间进行研究,尝试将时态伪关联反馈应用到微博检索,分别基于提取出的前N个关联反馈的时态配置文件和用户行为,通过伪关联反馈改进初始检索,以提升检索的有效性,但是缺乏对网页内容的时态语义检索支持。因此,Strotgen J、Kuzey E、Dakka W等学者[4~6]从Web页面内容中抽取时态信息,Strotgen J、Kuzey E[4,5]分别通过函数计算和时态本体构建方式,探索了识别文档中高相关时态表达式和从维基百科中抽取时态信息的方法;Dakka W等人[6]提出了一个自动检索文本中用户感兴趣的时间点或时态区间的通用框架;而Kage T等[7]则探讨了时间粒度限制在小时级别的一个商用的时间搜索系统,但不支持如“圣诞节”、“国庆节”这类具体时间的查询。
另一方面,学者们希望搜索引擎不仅能够意识到嵌入在文档中的时态信息,也能根据时态上下文返回时态排序的搜索结果。Li F等[8]提出一种SEB-tree的简单索引结构支持时态排序检索,但并未充分考虑Web页面内容的时态语义相关度。为此,Campos R等学者[9]提出一种将查询与相关日期结合起来的时态相似性度量方法;Kanhabua N等学者[10]基于学习排名技术提出了时间感知的排名模型。
综上所述,现有的研究多限于从时态信息的某一个侧面进行探讨,缺乏较为系统的应用。本文则从两方面入手,研究时态信息的抽取与排序问题。现有的搜索引擎通常提供针对网页更新时间的查询,缺乏对网页内容的时态语义检索支持,往往基于链接进行网页分析并针对网页文本相关度进行排序,未充分考虑网页内容的时态语义相关度。另一方面,现有的搜索系统在处理时态相关查询时不能完全地抽取时态表达式,如将“上午9点”分解为“上午”、“9点”,将“5月9日至12日”分解为“5月9日”、“12日”等进行一般文本的搜索匹配,割裂并丢失了原有表达式的时态语义。
为解决上述问题,引入时态正则表达式规则,提出时态语义相关度算法TSRR(Temporal Semantic Relevancy Ranking),抽取查询关键词和网页文档中的时态点或时态区间等时态表达式,并在搜索排序阶段通过TSRR算法对搜索结果进行二次处理,计算网页的时态语义相关度,使返回结果按时态语义相关度与文本相关度的综合排序后再显示给用户。
2 时态语义相关度排序算法
搜索引擎为响应用户提交的检索需求,从互联网上搜集信息,并对所收集的信息进行处理,将用户检索的相关信息作为检索结果返回给用户。在进行网页内容时态信息的扩展检索时,TSRR算法采用两阶段设计方法:第一阶段抽取出网页中包含的所有时态信息;第二阶段为所有的网页计算最终排序分数。
2.1 网页内容时态信息的抽取
2.1.1 时态表达式及其模板规则
现实生活中的时态信息表达形式灵活多样,有时间、日期、时态区间和“今天”、“后天”、“前天”等时间词,以及通过时态定位词和介词等组合形成复杂的时间短语,如“昨天晚上11点30分”、“自2010年8月1日起至2011年8月1日止”等。将网页中的时态表达式分为时态点和时态区间两大类,为表述方便,这里将时间Time、日期Date、时间词TW(Temporal Word)和时间短语TP(Temporal Phrase)等表达的时态点和时态区间统称为时态表达式(Temporal Equation),如模板规则中的规则1所示。
现有的分词系统不能完全地抽取时态表达式,如将“上午9点”分解为“上午”、“9点”,将“5月9日至12日”分解为“5月9日”、“12日”,割裂并丢失了原有的时态语义。为准确而完整地识别较为复杂的时态表达式,基于规则匹配方法,采用正则表达式形式,预先定义好符合汉语时间表达习惯的模板规则,如下所示:
时间正则表达式的模板规则:
(1)TE→t|I;
(2)t→Time|Date|TW|TP;
(3)I→[t,t]TP+TPr+TP;
(4)Time→(Digits+时){Digits+时}*+{Digits+分}*+{Digits+秒}*|{Digits+时}*+{Digits+分}{Digits+分}*+{Digits+秒}*|{Digits+时}*+{Digits+分}*+{Digits+秒}{Digits+秒}*;
(5)Date→{Digits+年}{Digits+年}*+{Digits+月}*+{Digits+日}*|{Digits+年}*+{Digits+月}{Digits+月}*+{Digits+日}*|{Digits+年}*+{Digits+月}*+{Digits+日}{Digits+日}*;
(6)Digits→(1|2|3|4|5|6|7|8|9)+(1|2|3|4|5|6|7|8|9)*;
(7)TW→去年|今年|夏天|劳动节|昨晚|…;
(8)TP→Date+(TW|Time)|(Date|Time|TW|Dur)+TL|TW+(Date|Time|TW|Dur)+TL|TPr+(Date|Time|TW|Dur)+TL|TPr+Date+TW|TPr+{TW}++Time|TPr+TW+Date+TL;
(9)Dur→{Digits+年}*+{Digits+月}*+{Digits+天}*{Digits+小时}*+{Digits+分钟}*+{Digits+秒}*;
(10)TL→前|之前|以前|后|之后|以后|期间|…;
(11)TPr→到|于|在|自|从|…。
正则表达式表述的规则中,符号“|”表示“或”关系,标号“{}*”表示括号中的内容可以出现零次或多次,“{}+”表示括号中的内容至少出现一次或多次;Dur表示时态跨度,TPr表示时态介词;TL表示时态定位词,据统计在汉语中总共有105个位置名词,其中六个可以引入时间表示:末、末期、以来、之际、前夕和期间,此外还有21个具有时间和地点的双重含义:前、后、之前、之后等,为此建立相应的时态表达式词典。
2.1.2 时态表达式的识别
要找到网页中所包含的时态信息,使用时态正则表达式和中文分词相结合的方式将网页的时态表达式识别出来。段落是由句子组成的,确定时间描述的具体内容,分词和词性标注是时态表达式识别的基础。首先基于开源软件IKAnalyzer分词系统[11],对网页正文文本进行词性标注;同时,采用时态正则表达式识别并修正,尽可能准确而完整地发现页面文本中所包含的时态信息。
通常,一个网页包含多个TE,需要从中选择一个准确的参考时间,其他参照该参考时间进行推理计算。可以根据网页内容的发布时间来确定网页参考时间,进而对网页内容的“昨天”、“去年”等隐性或非规范的时态点和时态区间推理规范为标准化格式时间,其形式为:“×年×月×日”、“×时×分×秒”。为方便时态语义相关度计算和排序,将从网页中抽取的时态表达式分为时态点集合{t1,t2,…,tn}和时态区间集合{I1,I2,…,Im},其中Ij=[Ij,s,Ij,e],Ij,s、Ij,e分别表示时态区间Ij的起点和终点,Ij的长度表示为|Ij|=Ij,e-Ij,s+1。
2.2 时态语义相关度的确定
基于网页内容的时态语义相关度TSRR算法根据查询关键字返回的查询结果,综合考虑网页内容的文本相关度和时态语义相关度计算网页的最终排序得分。网页的文本相关度指用户的查询关键字和网页关键字的相关度。网页的时态语义相关度根据用户查询中的时态信息和网页内容中的时态信息计算得到。
TSRR算法和其他现有的排序算法的不同之处在于结合了网页内容的时态语义和发布时间进行排序,其关键是计算网页内容的时态语义相关度,记为TSR(q,D),计算步骤如下所示:
Step1计算查询时态点tq与网页文档D的时态语义相关度R(tq,D)。
对于一个输入的查询时态点tq和根据文本相关度搜索返回的一个网页内容D,tq与D的时态语义相关度表示为R(tq,D):
(1)
其中,num(tq)是查询时态点tq在D中出现的次数;[Ij,s,Ij,e]是D中包含查询时态点tq的时态区间Ij,tq∈[Ij,s,Ij,e]当且仅当Ij,s≤tq≤Ij,e;|Ij|=Ij,e-Ij,s+1;{I1,I2,…,Im}是D中所有包含查询时态点tq的时态区间集合。
Step2计算查询时态区间Iq与网页文档D的时态语义相关度R(Iq,D)。
令Iq为用户输入的查询时态区间,Iq=[Iq,s,Iq,e],Id为返回结果集中D所包含的时态区间,Id=[Id,s,Id,e]。Iq与D的时态语义相关度表示为R(Iq,D):
(2)
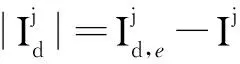
Step2.1比较Iq和Id的起始端点Iq,s和Id,s判断Iq和Id相交:(Iq,s≥Id,s)∧(Iq,e≥Id,s)∨(Iq,s≤Id,s)∧(Id,e≤Iq,s)⟺Iq∩Id≠∅;否则,Iq和Id不相交,|Iq∩d|=0。
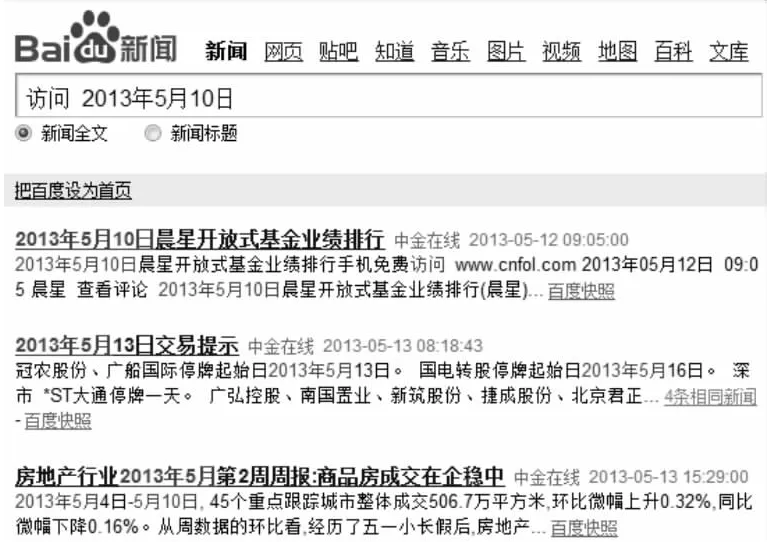
Step2.2根据Iq和Id的相交关系计算Iq∩d的长度:(Iq,s≥Id,s)∧(Iq,e≥Id,s)∧(Iq,e Step2.3根据Iq和Id的包含关系计算Iq∩d的长度:(Iq,s≥Id,s)∧(Iq,e≥Id,s)∧(Iq,e≥Id,e)⟹|Iq∩d|=Id,e-Id,s+1;(Iq,s≤Id,s)∧(Id,e≥Iq,s)∧(Id,e Step3计算查询q与网页文档D的时态语义相关度TSR(q,D)。 一个查询q与网页文档D的时态语义相关度TSR(q,D)为该查询q中时态点tq和时态区间Iq在返回结果集中与D的时态语义相关度之和,计算公式为: (3) 2.3 基于文本相关度和时态语义相关度的网页排序 当用户提交查询后,搜索引擎动态计算网页最终排序分数后进行网页排序。网页文本相关度排序分数采用公式(4)所表示的Lucene评分机制,该公式组合使用了信息检索的向量空间模型和布尔模型计算[12]。 Score(q,D)=coord(q,D)*queryNorm(q)* d.getBoost()*norm(d,D) (4) 其中,coord(q,D)为评分因子,是文档D中出现查询q的个数;queryNorm(q)为q的标准查询形式;freq(dinD)为项频率,d∈q,指项d在文档D中出现的次数;docFreq为文档频率,指出现项d的文档数;d.getBoost()为查询时为项d指定的权值;norm(d,D)返回建索引时的参数计算值,封装了一些索引权值和长度数值。 根据公式(3)和公式(4),给定查询〈q,tq,Iq〉,网页D的最终排序得分计算方式为: TSRR(q,D)=Score(q,D)*TSR(q,D)= (5) 3.1 系统架构 基于文本相关度和时态语义相关度的搜索引擎系统TTSRR(TextsandTemporalSemanticsRelevancyRanking)架构如图1所示。实现了信息采集、信息抽取、信息索引和信息检索等基本功能,并添加了时态信息抽取模块和时态信息排序模块。TTSRR系统基于网络爬虫工具Nutch和搜索应用服务器Solr,采用Java语言设计开发。其中,爬虫模块和预处理模块由Nutch提供,索引模块和检索模块由Solr提供,系统重点实现时态信息抽取模块和时态信息排序模块。 Figure 1 Architecture of TTSRR system图1 基于时态语义的搜索引擎系统架构图 时态信息抽取模块针对预处理后的网页发布时间和内容时间进行分析,提取其中的时态信息,抽取时态点集合{t1,t2,…,tn}和时态区间集合{I2,I2,…,Im}。此外,时态信息抽取模块还对用户的查询请求进行分析,提取其中的查询时态点tq和时态区间Iq,供时态信息排序模块使用。 时态信息排序模块按照TSRR算法计算、返回结果网页内容D和查询q的时态语义相关度TSR(q,D),对搜索结果按文本相关度和时态语义相关度计算网页的最终排序得分TSRR(q,tq,Iq),按新的分数排序后返回给用户,实现基于时态语义排序的搜索功能。 3.2 搜索结果示例 TTSRR系统搜索界面和通用搜索引擎类似,分为三个部分:查询输入框和搜索按钮、搜索结果数目显示及搜索结果列表,下面列举了分别在TTSRR系统和百度输入查询关键词搜索的实验示例。 (1)q=“访问5月10日”,查询时态点tq=“5月10日”,搜索结果表明TTSRR系统能够进行tq与网页文档D中时态区间Id的匹配,如图2和图3所示。 Figure 2 Results of searching “Visiting Tenth, May” in TTSRR图2 TTSRR系统搜索“访问5月10日”结果 Figure 3 Results of searching “Visiting Tenth, May” in Baidu图3 百度搜索“访问5月10日”结果 从图2可以看到TTSRR系统返回一个结果,“5月9日至12日”被标红,说明与输入的时态点tq=“5月10日”匹配成功,在时态信息抽取时“5月9日至12日”被转换成时态区间Id=“[2013年5月9日,2013年5月12日]”;而查询时态点tq=“5月10日”被转换成规范形式“2013年5月10日”,正好落在时态区间,因此该网页被作为搜索结果返回。而图3搜索结果表明,百度只是简单匹配“5月10日”,而没有出现“5月9日至12日”这种时态区间的匹配。 (2)q=“地震 2009年到2013年”,搜索结果表明TTSRR系统能够进行查询时态区间Iq与网页文档D中时态点td及时态区间Id的匹配,如图4和图5所示。 Figure 4 Results of searching “Earthquake from Year 2009 to Year 2013” in TTSRR图54 TTSRR系统搜索“地震2009年到2013年” Figure 5 Results of searching “Earthquake from Year 2009 to Year 2013”in Baidu图5 百度搜索“地震2009年到2013年” 从图4可以看到,TTSRR系统搜索返回五个结果,“2013年4月20日”、“ 2013年4月20日到2013年4月21日”、“2011年10月23日”、“1月12日”被标红,说明与输入的时态区间Iq=“2009年到2013年”匹配成功。“2013年4月20日”、“2011年10月23日”和“1月12日”等时态点td都落在时态区间Id中。特别地,“1月12日”之所以落在时态区间Iq中,是因为第五个网页的网页发布时间是“2010-01-15”,该时间是在时态信息抽取模块从网页源代码中得到的网页发布时间,并以此做为该网页的参考时间,进而对网页内容D的时态点td=“1月12日”进行时态推理得到规范时间“2013年1月12日”。“ 2013年4月20日到2013年4月21日”时态区间Id也落在时态区间Iq中。根据TSRR算法,第一个网页的时态语义相关度为4,第二个网页的时态语义相关度为3.5,第三个网页的时态语义相关度为3,分别乘上各自的文本相关度分数,按从大到小顺序显示。而从图5中可以看出,百度只是把“2009年到2013年”当成普通文本进行搜索,返回结果也只是与2009年或2013匹配成功,没有出现和“2010年”、“2011年”或“2012年”等匹配成功的情形。 3.3 系统性能 TTSRR系统对Nutch搜索引擎的返回结果进行二次开发,查全率、查准率都与Nutch一致,TTSRR系统暂未对其进行具体测试,Nutch的索引文档数量在100万以下时,查询响应快速,不超过0.5秒,因而适合专业的垂直搜索引擎应用领域。以网易新闻(http:∥news.163.com/)网站数据进行了测试,分别用不同关键词和相同时态信息进行检索,统计结果如表1所示。从表1可以看出,返回结果并没有影响查询时间,查询响应的平均时间为320ms。 Table 1 Statistics of response time for searching表1 检索响应时间统计 时态属性,作为刻画事物的一个重要维度,对时态信息检索、时态数据库、时态知识推理、时态数据挖掘等研究领域均有深远的影响[13~15]。针对通用搜索引擎缺乏对网页内容中时态表达式的准确抽取及语义查询支持,在通用搜索引擎架构基础上添加了时态信息抽取和时态信息排序功能,引入时态正则表达式规则结合分词系统准确而完全地抽取网页中的时态表达式;并提出时态语义相关度算法,综合计算网页内容的文本相关度和时态语义相关度,按网页的最终排序得分对搜索结果进行二次处理。实验表明,应用TSRR算法可以准确而有效地匹配与时态表达式相关的关键词查询。 [1] Alonso O, Gertz M, Baeza-Yates R. On the value of temporal information in information retrieval[J]. ACM SIGIR Forum, 2007, 41(2):35-41. [2] Whiting S, Klampanos I A, Jose J M. Temporal pseudo-relevance feedback in microblog retrieval [C]∥Proc of the 34th European Conference on Advances in Information Retrieval,2012:522-526. [3] Choi J, Croft W B. Temporal models for microblogs[C] ∥Proc of the 21st ACM International Conference on Information and Knowledge Management, 2012:2491-2494. [4] Strotgen J, Alonso O, Gertz M. Identification of top relevant temporal expressions in documents [C]∥Proc of the 2nd ACM Temporal Web Analytics Workshop, 2012:33-40. [5] Kuzey E, Weikum G. Extraction of temporal facts and events from Wikipedia [C]∥Proc of the 2nd ACM Temporal Web Analytics Workshop, 2012:25-32. [6] Dakka W, Gravano L, lpeirotis P G. Answering general time sensitive queries[C]∥Proc of the 17th ACM Conference on Information and Knowledge Management, 2008:1437-1438. [7] Kage T, Sumiya K. A Web search method based on the temporal relation of query keywords[C]∥Proc of the 7th International Conference on Web Information Systems Engineering, 2006:5-15. [8] Li F, Yi K, Le W. Top-kqueries on temporal data [J]. The VLDB Journal, 2010, 19(5):715-733. [9] Campos R, Dias G, Jorge A, et al. Enriching temporal query understanding through date identification:How to tag implicit temporal queries?[C] ∥Proc of the 2nd ACM Temporal Web Analytics Workshop, 2012:41-48. [11] Zhang Qi-yu,Zhu Ling,Zhang Ya-ping.Summing-up of studies on Chinese segmentation arithmetic[J].Information Resea- rch,2008(11):53-56.(in Chinese) [12] McCandless M, Hatcher E, Gospodnetic O. Lucene in action[M].2nd ed. USA:Manning Publications Co.,2010. [13] Zuo Ya-yao, Tang Yong, Shu Zhong-mei. Method of the subtraction operation between temporal points with granularities based on granularity hierarchy mapping[J]. Journal of Computer Research and Development, 2012,49(11):2320-2327.(in Chinese) [14] Zuo Ya-yao, Shu Zhong-mei, Tang Yong. Exploration into granularity constraints and standardization of temporal primitives[J]. Journal of Chinese Computer Systems,2013,34(5):1070-1075.(in Chinese) [15] Zuo Ya-yao,Shu Zhong-mei,Tang Yong.Research on qualitative relationship among temporal elements with temporal granularities constraint[J]. Computer Engineering and Science,2013,35(2):34-40.(in Chinese) 附中文参考文献: [11] 张启宇,朱玲,张雅萍.中文分词算法研究综述[J].情报探索,2008(11):53-56. [13] 左亚尧,汤庸,舒忠梅.基于粒度层次映射转换的时态粒点差运算方法[J].计算机研究与发展,2012,49(11):2320-2327. [14] 左亚尧,舒忠梅,汤庸.时态原语的粒度约束与规范化问题探讨[J].小型微型计算机系统,2013,34(5):1070-1075. [15] 左亚尧,舒忠梅,汤庸.时态粒度约束下的时态元素定性关系探讨[J].计算机工程与科学,2013,35(2):34-40. SHUZhong-mei,born in 1974,PhD,lecturer,her research interests include data warehouse, business intelligence, and institutional intelligence. 左亚尧(1974-),男,湖北荆州人,博士,副教授,CCF会员(E200011215M),研究方向为数据仓库与数据挖掘,Web信息处理。E-mail:13808815212@139.com ZUOYa-yao,born in 1974,PhD,associate professor,CCF member(E200011215M),his research interests include data warehouse and data mining,web information processing. Studyonextractionandrankingoftemporalsemanticsandsystemimplementation SHU Zhong-mei1,ZUO Ya-yao2,ZHANG Zu-chuan2 (1.School of Education,Sun Yat-Sen University,Guangzhou 510275;2.Faculty of Computer,Guangdong University of Technology,Guangzhou 510006,China) General search engine lacks of extraction and retrieval of temporal semantic from the text content of the Web pages. To address the temporal query problem, the Temporal Semantic Relevancy Ranking (TSRR) algorithm is proposed by integrating the temporal information extraction and ranking functions. Firstly, the rule of the temporal regular expression is introduced to extract the temporal points or temporal intervals from the query keywords and the text content of the web pages. Secondly, the scores of web pages are re-evaluated and the returned results are ranked according to the text relevancy and the temporal semantic relevancy. Experiments show that the TSRR algorithm precisely and effectively matches the keywords queries related to the temporal expression. temporal semantic;information extraction;ranking;search engine 1007-130X(2014)08-1609-06 2013-05-28; :2013-09-29 国家自然科学基金资助项目(60970044);广东省自然科学基金资助项目(S2011040004281) TP391.3 :A 10.3969/j.issn.1007-130X.2014.08.033 舒忠梅(1974-),女,湖北荆门人,博士,讲师,研究方向为数据仓库、商业智能和院校智能。E-mail:issszm@mail.sysu.edu.cn 通信地址:510275 广东省广州市中山大学大钟楼312 Address:Room 312,Dazhong Building,Sun Yat-Sen University,Guangzhou 510275,Guangdong,P.R.China3 基于TSRR的搜索引擎系统实现





4 结束语


 猜你喜欢
家庭影院技术(2021年2期)2021-03-29数学物理学报(2020年2期)2020-06-02安顺学院学报(2020年1期)2020-04-05疯狂英语·新策略(2019年12期)2020-01-04现代计算机(2019年6期)2019-04-08中国卫生(2015年12期)2015-11-10新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06海外英语(2013年4期)2013-08-27科学导报·学术论坛(2013年5期)2013-06-26商(2012年11期)2012-07-09
猜你喜欢
家庭影院技术(2021年2期)2021-03-29数学物理学报(2020年2期)2020-06-02安顺学院学报(2020年1期)2020-04-05疯狂英语·新策略(2019年12期)2020-01-04现代计算机(2019年6期)2019-04-08中国卫生(2015年12期)2015-11-10新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06海外英语(2013年4期)2013-08-27科学导报·学术论坛(2013年5期)2013-06-26商(2012年11期)2012-07-09
