
HEVC标准中整数变换的FPGA实现
2014-09-18 00:16普建龙吴景东
电视技术 2014年19期
普建龙,吴景东
(福州大学工业控制研究所,福建福州350108)
2010年,由ITU-T和ISO/IEC的专家联合成立的JCT-VC(Joint Collaborative Team-Video Coding)开始着手于下一代视频压缩标准HEVC的研发[1]。HEVC目标是在H.264/AVC扩展档次的基础上,提高50%的压缩率,然而其计算量和复杂度也大大增加[2],非常不利于其在硬件上的实施。
HEVC标准于2013年1月发布,有关HEVC中整数DCT在FPGA上实现的研究还比较少。Belghith和Park在文献[3-4]中设计的结构只能支持部分TU块,其MCM单元没有采用任何优化方法。这两种架构的时延也较大,不利于高清视频的实时处理。Shen在文献[5]中为IDCT(Inverse DCT)设计了能适应各种TU块的结构,但每个周期只能处理4个样本点。其复用了同一个1-D IDCT结构,时延变大。对大TU块,该结构直接使用乘法操作,功耗大。Meher在文献[6]中设计的结构将数据都进行了裁减,准确性下降,容易出现数据漂移现象。刘毅在文献[7]中的设计,支持非方形的TU块,而这已经被最新的标准去除了。
为了克服上述缺点,本文提出了一种能自适应各种TU块的硬件架构,去除了原MCM中的常规乘法,并最大限度地找出复用单元,节省硬件资源。同时,按照HEVC标准[8]要求,最大限度地保证数据的准确性。实验表明,该结构每个周期能处理32个样本,最大时延只有32个时钟周期,在184 MHz的时钟频率下,能实时处理60 f/s(帧/秒)、采样率为4∶2∶0的UHD视频序列。
1 硬件架构总体设计
整个算法采用6个模块,如图1所示。图中,粗箭头表示数据的流向,细箭头表示控制信号,复位和时钟信号在此省略。下面对各个模块进行简要介绍。

图1 硬件架构的总体设计
Control模块产生控制信号,控制整个流水线的进行。TU_size设置为0~3,分别标记本次运算时TU的大小(4×4~32×32)。同时用TU_size来设置enable1控制信号(包括 enable1_8,enable1_16,enable1_32),以选择DCT_1中用于当前TU块的运算单元。mode记录上一个参与运算的TU块的大小,并设置enable2控制信号(包括 enable2_8,enable2_16,enable2_32),选择 DCT_2中的运算单元。require表示当前TU块中的数据全部计算完毕,可以重新设置TU_size并输入一组新的数据。在Control单元中,还有两个标记信号:flag和flag_permission。flag由TU_size和mode中较大的数据决定,用于标记计算本TU块所需要的周期。flag_permission控制本TU计算过程中,有多少次数据是有效的,无效的数据用0填充。h_v信号控制转置模块是按照行还是按列存储。cnt则用来记录正在处理的数据将存放在第几行或者第几列。
PN_1和PN_2分别对DCT_1和DCT_2模块输出的数据进行整理。当计算的TU块为4×4时,PN_1和PN_2的输出数据p_out0~3分别等于DCT_1和DCT_2输出数据中的y0,y8,y16,y24,其他输出数据都设为0。当 TU 块为8×8时,p_out0~7 对应y0,y4,y8,y12,y16,y20,y24,y28,其他的也都是0。对于16×16和32×32的TU块,PN_1和PN_2的输入输出方法也符合类似规律。
DCT_1,DCT_2和Transpose是本文的主要研究工作,将在下文详细介绍。
2 DCT模块设计
类似于H.264/AVC,HEVC采用了整数DCT,在简化运算的同时,避免了视频图像的漂移现象。HEVC具有灵活的块结构,能准确适应各种分辨率的视频序列。TU块是变换的基本单元,目前支持4×4,8×8,16×16和32×32四种大小[8]。较大的块能更有效地处理高清视频中相对平滑的区域。
HEVC中2-D(1-Dimensional)DCT也可以转换为两个1-D DCT来计算。1-D DCT模块对应图1中DCT_1和DCT_2。其区别在于输入数据的位数。DCT_1的输入数据为9位,即预测图像与原图像的残差数据,DCT_2的输入数据为16位,是经过了1-D DCT之后的数据。数据在1-D DCT运算的过程中需要裁减,以保证输出的数据是16位。16位的数据既保持了数据的准确度,又能保证Transpose模块大小适中[1]。
2.1 DCT总体结构
图2详细描述了1-D DCT模块的设计。“<<”和“>>”分别表示算术左移和算术右移。B4,B8,B16,B32分别表示输入 Transform4×4,Transform8×8,Transform16×16,Transform32×32单元的数据的位数,不包括符号位。这些参数的使用,不仅简化了设计过程(DCT_1模块通过简单的参数配置就能用于DCT_2模块),而且能保证被处理数据的准确性。图中有3个enable信号(包括enable8,enable16和enable32),由TU块的大小决定其取值,分别控制 Transform8×8,Transform16×16和Transform32×32三个单元的输入数据。如果enable信号为1,则对应单元选择蝶形加法器,否则使用移位器。由于任何大小的TU块在变换时都会调用Transform4×4单元,故该单元无需enable信号。该结构利用了HEVC标准中变换核[8]的特性,使较大的TU块在做变换时,能复用较小TU块的变换单元。

图2 DCT模块的详细设计
经过综合后,DCT_1和DCT_2模块中各单元所占资源如表1所示。各单元寄存器使用量为0,未在表中列出。表1中同时列举了文献[7]中的资源使用情况,其在Altera CycloneII上进行了综合。可以看到,本文的资源使用量明显减少。
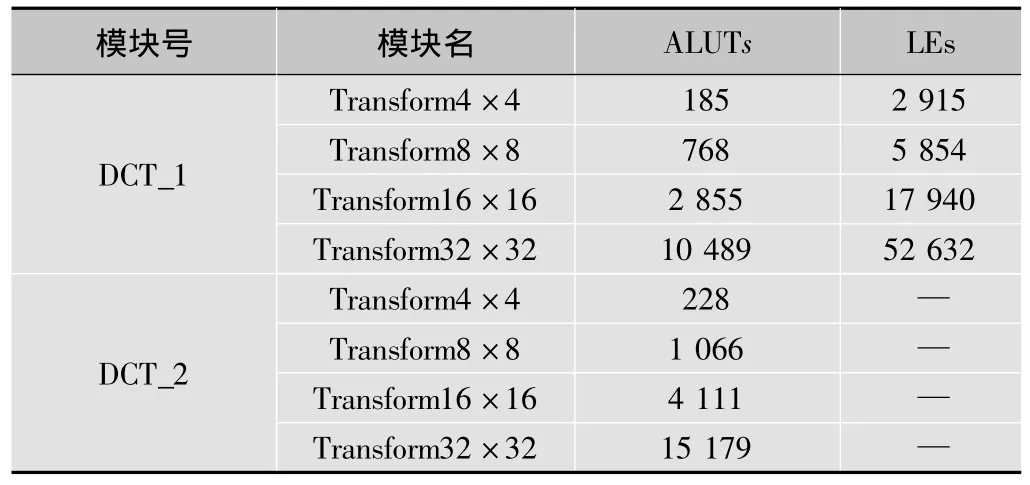
表1 本结构和文献[7]中DCT模块中各单元资源占用量
2.2 MCM单元和加法树
乘法运算在FPGA中资源占用量和能耗非常大,所以要将所有的矩阵乘法运算换成移位和加法操作,以减少硬件资源,缩小设计面积。
MCM算法在其他有关整数DCT的文献中也有较多的应用,下文以最复杂的单元来详细介绍MCM单元的优化过程。假设输入MCM32单元的数据为M,表2中xM表示x与M的乘积。为了书写方便,假设移位操作的优先级比加法操作高。
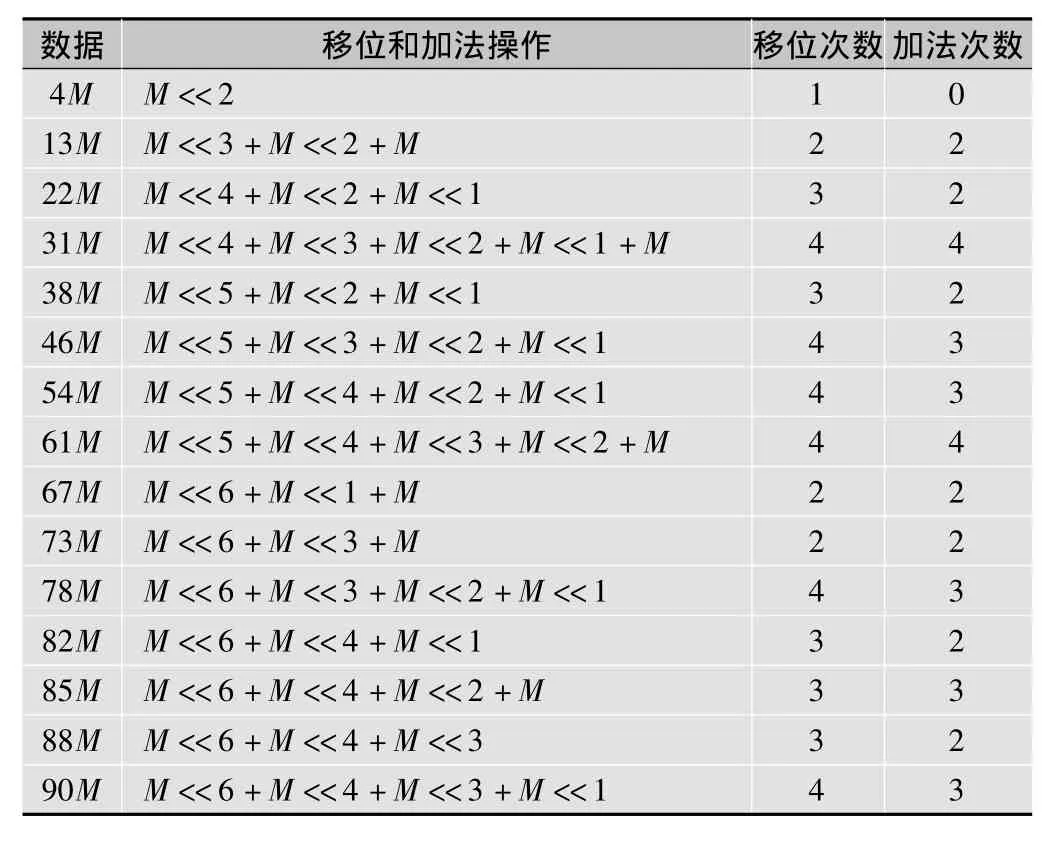
表2 常规方法MCM32单元运算量
由表中数据可知,若无单元复用,该MCM32单元需要移位操作46次,加法操作37次。通过仔细分析移位和加法操作,可以发现,该运算中许多单元都是可以复用的。下面对该结构进行一些改进,用一些临时变量保留复用单元的值,并在之后的运算中直接使用,如表3所示,正体部分表示临时变量。
统计结果表明,经过优化后,MCM32单元只需进行10次移位和14次加法操作,分别节省了78.3%和62.2%的运算量。
MCM单元计算出的结果,还要经过加法树AddTree的处理。由于两个位数较少的数相加,综合后得到的加法器资源消耗更少,故对上述15个数采用不同的位数来存储,每次计算时选择位数较少的两个数进行加法操作。
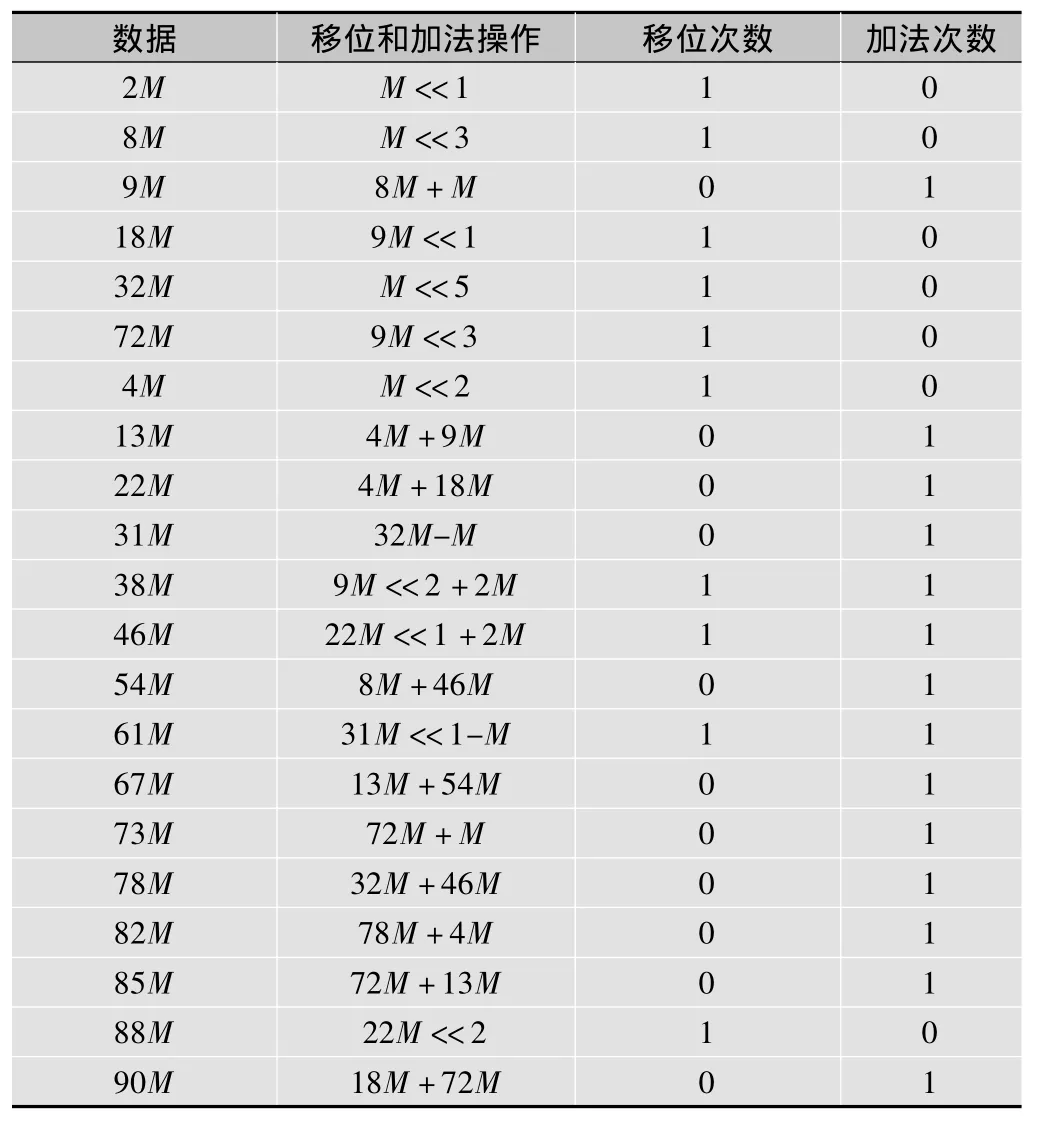
表3 改进后MCM32单元运算量
3 Transpose模块
Transpose模块在整个设计中至关重要,它使得DCT_1和DCT_2模块能够同时进行运算。具体实现时,采用标准测试程序HM12.1[9]中的方法,先按列计算一维(1-D)的DCT,其结果再按行进行第二维的DCT运算。具体流程如图3所示。

图3 Transform模块数据处理流程
Transpose模块中寄存器初始化为0,并假设当前处理的是32×32大小的TU块。首先输入一列数据,经过DCT_1模块之后,将数据按列存放于Transpose模块中,如图3中1所示。32个时钟周期之后,数据填满Transpose模块中的寄存器,如图3中2所示。该阶段表明当前TU块经过DCT_1模块运算完毕,Transpose模块中存放着用于DCT_2模块运算的数据,并且Control模块可以接收一组新的数据用于DCT_1模块计算。如图3中3所示,按行取出用于DCT_2模块的数据,新接收的数据依然按列在DCT_1中运算,但结果按行来存储。运用脉冲触发的特性,每次存取操作都可在一个周期内完成。当Transpose模块中原来的数据被取完之后,新的TU块经过DCT_1模块运算的结果也就保存在Transpose模块之中了,如图3中4所示。之后重复上述操作就可以实现两个DCT模块的流水线操作。
此处需要解决一个问题:上述示例中,如果第2次输入的TU块大小为4×4,理应只需4个时钟周期就能完成1-D DCT运算(在DCT_1模块中),但是Transpose模块中存放的32×32的矩阵,需要32个周期取出,若此时更新了TU块,并输入新的数据,则Transpose中剩余的数据就会因被覆盖而丢失。为了防止该现象发生,在Control模块中设置了一个mode值,如第1节所述,该值用来记录上次参与DCT运算的TU块的大小。通过比较TU_size和mode的值来设计flag标记信号,控制本次变换所需的周期。所以上述示例中,第2次输入的4×4的TU块实际需要经过32个时钟周期才算完成了1-D DCT的运算过程。
Transpose模块由1 024个16位的寄存器组构成,用有限状态机(Finite-State Machine,FSM)控制数据的行列转换。经过综合后,ALUT使用量为11 800,寄存器使用量为16 384。
4 实验结果
实验所用代码通过Verilog HDL编写,并在Altera Arria GX EP1AGX90EF1152C上进行综合。
本结构综合后的数据如表4所示,其他相关文献给出的数据也在表中列出,以便对比。因相关文献中没有具体说明或者未使用相应资源,表中有些数据未给出。DCT和IDCT的区别在标准[8]中有详细阐述,此处将IDCT的文献也列出,作为参考。
从表4可以发现,相对于Belghith,Park,Shen设计的结构,本结构具有明显的优势,不仅能支持各种TU块,而且具有较高的吞吐率。Meher的结构综合后的数据同样比较优越,但其在计算过程中,直接忽略数据的低比特位,导致数据的准确性下降。
实验表明,在不明显增加资源占用量的情况下,本结构的时延更小,数据处理能力更强。在184 MHz的时钟下,即使是最坏的情况,本结构也能实时处理60 f/s的UHD视频序列。

表4 资源占用量对比
5 结论
本文针对FPGA的特性,通过充分优化MCM和AddTree单元以减少资源使用量。两个DCT模块采用参数配置的方法,配合enable信号来选择移位和加减法操作,能最大限度地保持数据的准确性。文中设计了一种新的Transpose模块,使得两个1-D DCT模块能同时运算,并能适应各种TU块的变换。该结构将数据处理时延控制在32个时钟周期内,处理能力和实用性更强。
:
[1] HAN G J,OHM J R,HAN W J,et al.Overview of the high efficiency video coding(HEVC)standard[J].IEEE Trans.Circuits and Systems for Video Technology,2012(22):1649-1668.
[2]蔡晓霞,崔岩松,邓中亮,等.下一代视频编码标准关键技术[J].电视技术,2012,36(2):80-84.
[3] BELGHITH F,LOUKIL H,MASMOUDI N.Efficient hardware architecture of a modified 2-D transform for the HEVC standard[J].International Journal of Computer Science and Application,2013,2(4):1308-1312.
[4] PARK J S,NAM W J,HAN S M,et al.2-D large inverse transform(16x16,32x32)for HEVC(High Efficiency Video Coding)[J].Journal of Semiconductor Technology and Science,2012,12(2):203-211.
[5] SHEN S,SHEN W,FAN Y,et al.A Unified 4/8/16/32-point integer IDCT architecture for multiple video coding standards[C]//Proc.International Conference on Multimedia and Expo(ICME).Melbourne:IEEE Press,2012:788-793.
[6] MEHER P K,PARK S Y,MOHANTY B K,et al.Efficient integer DCT architectures for HEVC[J].IEEE Trans.Circuits and Systems for Video Technology,2013,24(1):1-11.
[7]刘毅,罗军,黄启俊,等.HEVC整数DCT变换与量化的FPGA实现[J].电视技术,2013,37(11):12-14.
[8] International Telecommunication Union.Recommendation ITU -T H.265[EB/OL].[2014-02-10].http://www.itu.int/rec/T-RECH.265-201304-I,.
[9] Joint Collaborative Team on Video Coding(JCT-TV).HEVC Test Model HM-12.1 [EB/OL].[2014-02-20].https://hevc.hhi.fraunhofer.de/svn/svn_HEVCSoftware/tags/HM-12.1.
猜你喜欢
昆明医科大学学报(2022年4期)2022-05-23
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
数学小灵通·3-4年级(2021年9期)2021-10-12
小学生学习指导(低年级)(2020年10期)2020-11-09
数学小灵通(1-2年级)(2020年6期)2020-06-24
数学物理学报(2020年2期)2020-06-02
船舶标准化工程师(2019年4期)2019-07-24
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
临床骨科杂志(2017年4期)2017-03-06
数学大王·中高年级(2017年2期)2017-02-08
