
基于众包的社交网络数据采集模型设计与实现
2015-01-02 02:00高梦超胡庆宝程耀东李海波
计算机工程 2015年4期
高梦超,胡庆宝,程耀东,周 旭,李海波,杜 然
(1.四川大学计算机学院,成都610065;2.中国科学院高能物理研究所计算中心,北京100049;3.中国科学院声学研究所,北京100190)
1 概述
互联网的兴起打破了传统的社会交往方式,简单、快捷和无距离的社交体验推动社交网络快速发展,以Facebook、Twitter、微博等为代表的应用吸引了大量活跃网络用户,社交网络信息呈现爆发式的增长。社交网络信息反映了用户的网络行为特征,通过对这些信息的研究,可以实现社会舆论监控、网络营销、股市预测等。社交网络信息的重要价值在于实时性,如何快速、准确、有效地获取目标信息非常重要。但社交网络属于Deep Web的专有网络[1],信息量大、主题性强,传统搜索引擎无法索引这些Deep Web页面,只有通过网站提供的查询接口或登录网站才能访问其信息,这增加了获取社交网络信息的难度。
目前国外有关社交网络数据采集模型的研究较少,对社交网络的研究主要集中在社会网络分析领域。国内社交网络平台的数据采集技术研究有一定成果,如文献[2]提出并实现一种利用新浪微博应用程序接口(Application Programming Interface,API)和网络数据流相结合的方式采集数据,文献[3]利用人人网开发平台提供的API实现数据采集,并通过WebBrowser和HttpFox监测信息交互时的数据包,实现动态获取Ajax页面信息等。
本文采用模拟登录技术,利用社交平台账户获取平台访问权限,通过设置初始任务集对目标信息进行定向获取,避免请求不相关的信息页面,既保证了信息的实时性,又提高了信息获取效率。但是频繁地使用缺少维护的社交账户爬取数据,容易导致账户被平台封杀,为获取大量有效的社交账户并在服务器端避免繁重的账户维护工作,利用Hadoop平台的MapReduce计算模型处理结果数据[4],选择基于Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)的HBase数据库存储MapReduce处理结果,完成海量数据的有效存储。
2 数据采集模型设计
2.1 设计原理
大规模获取社交网络数据需要解决3个问题:(1)获取社交平台的数据采集权限;(2)数据的快速采集;(3)数据的有效存储。
一些社交平台如Twitter、新浪微博、人人网等,允许用户申请平台数据的采集权限,并提供了相应的API接口采集数据,通过注册社交平台、申请API授权、调用API方法等流程获取社交信息数据。但社交平台采集权限的申请比较严格,申请成功后对于数据的采集也有限制。因此,本文采用网络爬虫的方式,利用社交账户模拟登录社交平台,访问社交平台的网页信息,并在爬虫任务执行完毕后,及时返回任务执行结果。
为提高数据的采集速度,本文采用分布式采集方式,通过设置初始任务集,按照任务调度机制把数据采集任务下发到用户机器,由用户机器完成整个数据的获取工作。然而,为了保护数据,减轻服务器的负担,社交平台通常会采取一些反爬虫措施,如封杀账号、封锁登录IP等。随着社交账户的申请流程越来越严格,社交账户的获取和有效性维护也成为制约大规模采集社交网络数据的瓶颈之一。
为解决以上问题,本文引入众包思想。众包是一种分布式的问题解决和生产模式,由美国《连线》记者Jeff Howe于2006年6月提出,即指公司或机构把公司内部任务以公开的方式外包给非特定的大众网络的行为。本文参考其商业运作模式,将其运用到互联网的相互协作中,通过社交网络的数据共享吸引网络用户作为志愿者参与到该项目平台中,由志愿者提供计算资源和社交账户在本地完成信息的分布式采集,并由志愿者负责维护自己的社交账户,解决了计算资源和社交账户的获取以及维护大量社交账户的难题。
本文采集模型采用自主开发的C/S架构软件系统作为分布式采集的基础框架,利用Hadoop计算平台[5]作为采集模型的数据处理框架。爬虫应用获取到的初始数据是非结构化和半结构化的网页信息,对网页信息进行抽取后,得到指定格式的目标结果数据,经过MapReduce计算模型的处理后,保存在HBase数据库中。
MapReduce编程模型是Hadoop平台的核心技术之一,它掩盖了分布式计算底层实现的细节,并提供相关接口,使编程人员能够快速实现分布式并行编程。HBase是一个分布式存储模型,是Bigtable[6]的开源实现,把HDFS作为HBase的支撑系统,一方面可以提高数据的可靠性和系统的健壮性,另一方面也可以采用MapReduce模型处理HBase中的数据,便于充分发挥HBase的大数据处理能力。采集模型整体结构如图1所示。
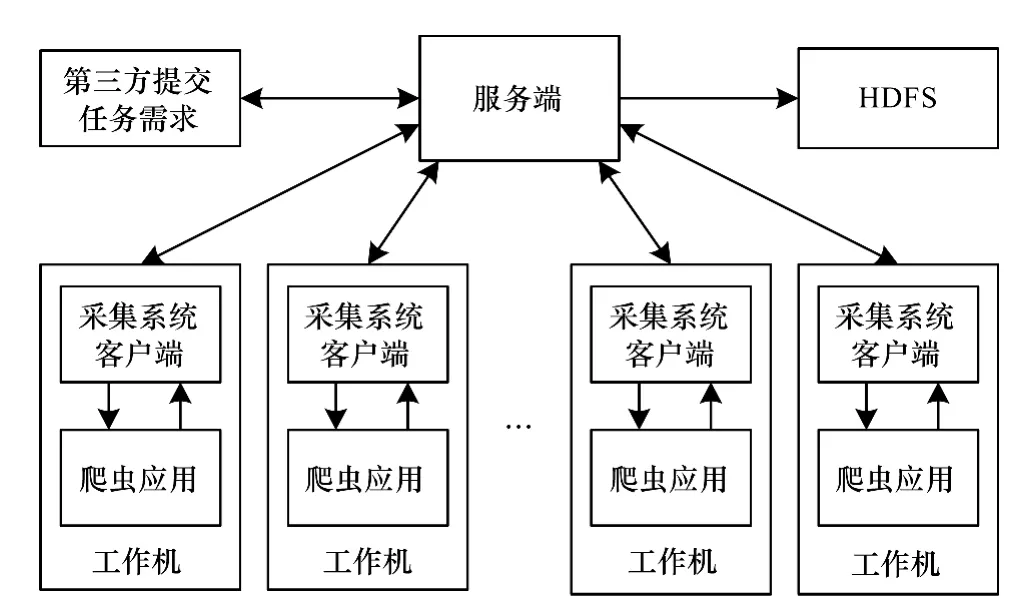
图1 采集模型整体结构
2.2 功能架构
采集模型基于众包模式,采用C/S架构,包含了服务端、客户端、存储系统与爬虫系统4个模块。服务端是系统控制核心,控制任务在下发前的一切操作以及结果校验等工作,且系统只有一个服务端。客户端置于分布式机器节点中,通过socket套接字与服务端通信,接收服务端命令、调用爬虫程序等。存储系统采用HDFS,具体的数据获取工作由爬虫程序使用HttpClient对象来模拟浏览器操作完成。
系统的主题爬虫应用程序通过HttpClient对象模拟浏览器操作实现。HttpClient[7]是 Apache Jakarta Common下的子项目,它是一个客户端的传输类,支持自动转向、HTTPS协议、代理服务器等。爬虫的模拟登录功能模块与数据获取功能是基于HttpClient提供的HTTP方式与Cookies管理功能实现。
HDFS是 Hadoop核心技术之一[8-10],可以运行在通用硬件上、具备高度容错性、支持超大文件的分布式文件系统以及以流的形式访问文件系统中的数据,适合大规模数据集上的应用。HDFS程序的文件操作模式大部分是一次写入、多次读取的简单数据一致性模型,这种设计简化了数据一致的问题并使高吞吐量的数据访问变得可能[11],非常适合网络爬虫程序。采集模型各组成部分在运行时的调用关系如图2所示。

图2 采集模型中各组成部分在运行时的调用关系
在客户端启动后,调用爬虫程序向服务器请求任务并执行数据获取任务。服务端的控制模块负责管理服务端与客户端的通信,并接收第三方提交的任务需求。Mysql数据库用来存储和任务有关的一切数据,并接收任务调度中心的命令生成任务。任务调度中心接收爬虫程序的任务请求,并返回任务文件,由爬虫程序完成具体的数据获取操作。数据获取结果返回给服务端的接收模块后,再由校验模块负责校验,并修改Mysql数据库中任务状态。校验成功后,如果任务是第三方提出的,将数据获取结果发送给第三方,否则传输给 HDFS,利用MapReduce完成数据结果的存储。
3 数据采集模型的功能实现
3.1 逻辑功能
众包模式的实现需要基于C/S架构的通信主体。服务端包含控制模块、任务调度模块、接收模块、校验模块和Mysql数据库。客户端主要功能是接收服务器命令、启动爬虫程序等。
控制模块向客户端下发命令并接收客户端的反馈信息,并接收第三方提交的任务需求参数,并根据配置文件将其转化为相应的任务类型,存储到Mysql数据库中,等待任务调度模块的调度。
任务调度模块的核心功能是保证客户端爬虫程序能有序地获取到有效任务。任务调度模块、接收模块、校验模块共同维护Mqsql数据库中的taskinfo表。taskinfo表设计了14个字段,包含索引值taskhash、任务类型type、任务状态state、任务创建时间createtime、任务下发时间requestindex、任务超时时间mactimelength等。taskinfo表包含了每一个任务的索引目录,但是没有任务内容,任务内容存放在次级任务表里,每种小任务对应一个次级任务表,每一个任务文件都由若干个小任务组成。任务调度模块创建任务时,使用taskhash来标识任务的唯一性,并按照 createtime设定任务的优先级,同时选择taskhash作为次级任务表的外键,并在次级任务表中添加与taskhash相应的任务内容。任务调度模块根据state的状态决定任务的下发。state有7种状态,分别 是 created,dealing,dealed,analysing,failed,success,stop。任务调度模块接收到爬虫程序的任务请求后,选择 taskinfo表中 state为 created或 failed状态的优先级最高的任务的taskhash,通过SQL语句查询次级任务表,生成最终任务文件,以json文件格式返回给爬虫程序。state状态之间的转换如图3所示。
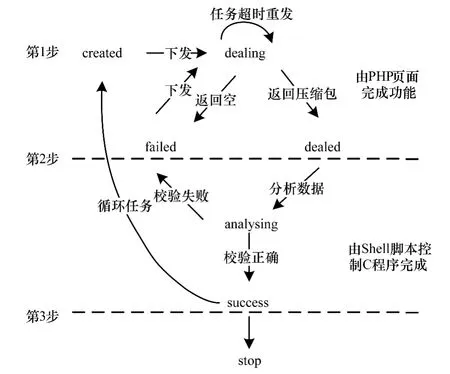
图3 任务状态转换
对于只需要执行一次的任务,在state转换成success后,任务结束。对于需要循环执行的任务,如定时爬取社交网络用户的注册信息来保证信息的动态更新等,state在转换到success一定时间内,如果没有被修改为stop状态,会转换到created状态,重新等待节点请求。
接收模块使用超文本预处理器(PHP)代码实现,调用PHP代码的标准函数move_uploaded_file,接收使用repost上传的文件,并存储到磁盘指定位置。如果压缩包为空,state被修改为failed,否则修改为dealed。如果压缩包非空,进入到校验模块,修改state状态为analysing。压缩包由包含json字符串的文件组成,校验模块根据C语言标准函数json_object_object_get,json_object_get_string,json_object_array_length对上传的json数据进行抽取分析,如果与定义的结果格式一致,校验成功,修改state状态为success,否则state被修改为failed。在该任务被重新下发后,state被修改为dealing。校验成功后的文件被发送到HDFS中进行进一步处理,最后完成数据存储。
客户端使用MFC框架实现,机器节点通过安装客户端即可选择加入系统中的某一项目,通过节点自身的运算能力为项目提供计算资源。
3.2 主题爬虫
主题爬虫应用程序是实现数据获取的核心模块。基于社交网络信息的特点,爬虫程序包含模拟登录、请求任务、执行任务、数据上传4个功能,与传统爬虫程序的区别是增加模拟登录功能,通过构建目标数据所在页面的URL实现信息的定向获取。本文以新浪微博为例,介绍爬虫的工作原理。
针对新浪微博的主题爬虫应用程序,基于J2SE平台进行实现。模拟登录功能的实现方式是读取包含账号信息的配置文件,模拟网页登录新浪微博的过程,获取访问新浪微博页面时所需要的有效认证信息,即需要保存在本地的Cookie信息。程序向新浪服务器发送经过加密的用户名(username)和密码(password),服务器从传递的URL参数中提取字符串并解密得到原用户名和密码,其中对username和password的加密是模拟登录过程中的关键步骤。对username进行Base64编码得到用户名的加密结果。但password的加密过程比较复杂。首先利用HttpClient对象访问新浪服务器获取服务器时间(servertime)、一个随机生成的字符串(nonce)2个参数。然后利用新浪服务器给出的pubkey和rsakv值创建RSA算法公钥(key)。将servertime,nonce和password按序拼接成新的字符串message,使用key对message进行RSA加密并将加密结果转化为十六进制,得到password的加密结果。将加密后的用户名和密码一起作为请求通行证的URL请求的报头信息传递给新浪服务器,新浪服务器经过验证无误后,返回登录成功信息,HttpClient保存有效的Cookies值。模拟登录成功后,程序会向服务端请求数据获取任务,否则结束本次任务。
任务请求模块向服务端的调度中心请求数据获取任务。爬虫程序通过httpClient的HttpGet方法,对指定 PHP页面进行请求,获取任务对应的taskhash。然后把 taskhash和机器 mac地址作为URL参数对另一PHP页面进行请求,服务端PHP页面接收到请求后,服务端程序对taskhash和mac地址进行验证,检测无误后,通过SQL语句查询次级任务表,并把查询结果组合成任务文件,以json字符串的形式返回给爬虫程序。
任务执行模块解析任务文件,完成具体的数据获取操作。在爬虫程序中,不同数据类型的获取功能被封装成了不同类对象,以便程序调用。在执行数据获取任务时,根据目标数据的类型调用相应的类对象,然后执行相应的成员函数来获取数据。
对定向获取的微博信息的网页源码使用正则表达式进行正则匹配,将结果转化为json数据并存储到指定文件中,直到获取微博内容的任务全部完成。将结果数据压缩后,上传给服务端的接收模块,本次任务结束。主题爬虫系统流程如图4所示。
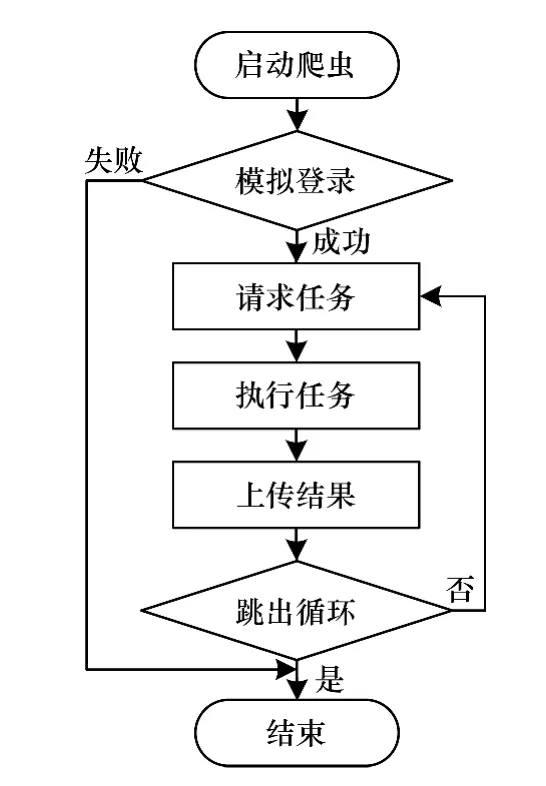
图4 主题爬虫系统流程
3.3 数据处理
MapReduce计算模型[12]在执行计算任务时,需要HDFS集群的支持。HDFS采用主从(Master/Slave)体系结构,包含名字节点NameNode、数据节点DataNode和客户端Client 3个重要部分。一个HDFS集群是由一个NameNode和若干个DataNode组成。
在写入HBase数据库前,需要使用MapReduce计算模型对原始数据进行清洗、筛选、统计等。MapReduce计算模型划分为Map和Reduce 2个阶段,分别采用Map()函数和Reduce()函数进行处理。其中,Map()函数主要对爬虫获取的结果数据进行格式清理,生成<key,list<value>>形式的中间结果,交由Reduce函数进行处理。Reduce函数对中间结果中相同键的所有值进行规约,可以去除结果中相同的记录,利用Java API与HBase数据库进行交互,通过创建 Put对象,实现数据批量导入HBase数据库中。
为便于程序执行,采集模型将MapReduce程序封装成Jar包,利用Shell脚本进行控制执行,在简化数据处理步骤的同时,也通过对数据的集中处理,提高了MapReduce程序的工作效率。
4 实验结果与分析
本文数据获取系统目前处于测试阶段,拥有146个志愿机器节点,分布在北京、海口和大庆3个地区。在普通网络环境下,经过一个月的试运行,系统数据获取结果如表1所示。

表1 系统试运行的数据获取结果
从结果可以看出,数据获取系统的任务成功率约为92%,数据获取效率很高,完成了预期结果。对抓取数据进行统计分析,可以观察微博数据走势。凤凰卫视2013年6月的微博转发统计如图5所示。

图5 凤凰卫视2013年6月中旬微博评论转发数量统计
5 结束语
本文设计并实现一个基于众包模式的社交网络数据采集模型,把数据获取任务下发到不同的机器节点,通过主题爬虫执行任务,实现对网页信息的定向获取,提高数据获取速度。利用Hadoop分布式文件系统存储结果数据,在实现对数据进行有效存储的同时,提高信息检索效率,为进一步分析社交网络数据提供功能支持。今后将对采集模型的任务调度系统进行优化,并开放用户管理平台,提高用户参与度。
[1] 高 原.面向领域的 Deep Web信息抽取技术研究[D].南京:南京信息工程大学,2013.
[2] 黄延炜,刘嘉勇.新浪微博数据获取技术研究[J].信息安全与通信保密,2013,(6):71-73.
[3] 邓夏玮.基于社交网络的用户行为研究[D].北京:北京交通大学,2012.
[4] Prabhakar C.CloudComputingwithAmazonWeb Services,Part5:Dataset Processing in the Cloud with SimpleDB[EB/OL].(2009-05-11).http://www.ibm.com/developerworks/library/ar-cloudaws5/.
[5] Hadoop[EB/OL].[2013-05-28].http://hadoop.apache.org/.
[6] Chang F,Dean J,Ghemawat S,et al.Bigtable:A Distributed Storage System for Structured Data[J].ACM Transactions on Computer Systems,2008,26(2):4-12.
[7] HttpClient Tutorial[EB/OL].[2013-05-28].http://hc.apache.org/httpcomponents-client-ga/tutorial/pdf/httpclient-tutorial.pdf.
[8] Hayes B.Cloud Computing[J].Communications of the ACM,2008,51(7):9-11.
[9] Konstantin S,Hairong K,Sanjay R,et al.The Hadoop Distributed File System[C]//Proceedings of the 26th Symposium on Mass Storage Systems and Technologies.Washington D.C.,USA:IEEE Computer Society,2010:1-10.
[10] 陈 康,郑纬民.云计算:系统实现与研究现状[J].软件学报,2009,20(5):1337-1348.
[11] 崔 杰,李陶深,兰红星.基于Hadoop的海量数据存储平台设计与开发[J].计算机研究与发展,2012,49(Sl):12-18.
[12] 董西成.Hadoop技术内幕:深入解析MapReduce架构设计与实现原理[M].北京:机械工业出版社,2013.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
制造技术与机床(2019年4期)2019-04-04
测控技术(2018年7期)2018-12-09
东华大学学报(自然科学版)(2018年1期)2018-06-29
消费导刊(2018年8期)2018-05-25
电子测试(2018年1期)2018-04-18
网络安全和信息化(2017年9期)2017-11-07
电子制作(2017年9期)2017-04-17
信息通信技术(2015年6期)2015-12-26
