
基于损失量的G-O漏洞预测模型及其改进
2015-02-28 06:14彭轼郭昊王涛
电信科学 2015年1期
彭轼,郭昊,王涛
(全球能源互联网研究院,北京102209)
1 引言
软件漏洞是软件缺陷的一种,其定义众说纷纭。Schultz[1]定义软件漏洞为“一种缺陷,使得入侵者可以绕过安全机制”,Pfleeger[2]将漏洞定义为“安全系统中可被用来引起损失或危害的弱点”,Shin Y[3]认为“软件漏洞是软件规格、开发或配置中缺陷的一个实例,它的运行违反潜在或外在的安全策略”。软件缺陷是影响软件安全性的一个重要因素,软件安全性是软件可信性的一个重要属性,国家标准GB/T 11457中对软件安全性的定义为:通过对软件系统进行防护,阻止针对软件产品的恶意攻击,使软件系统免于受到恶意的或无意但有害的破坏。
软件漏洞对软件系统有着巨大的危害,例如,2011年12月,中国最大的开发者技术社区——中国软件开发者联盟(CSDN)的系统遭到黑客攻击,多达600万用户的登录名、口令、邮箱等敏感个人信息泄露。因此,包括政府、软件供应商、软件使用者以及软件评估机构等相关组织采取建立漏洞库、跟踪漏洞信息等方法,以求降低漏洞的危害。但是,这些都是事后措施,人们尝试使用多种数学模型来预测漏洞,比较有代表性的有热动力模型[4]、对数泊松模型[5]、二次模型[6]和指数模型[7]等,这些模型以时间为重要参数,试图预测软件漏洞的数量等属性,效果各有千秋。
随着软件理论领域的发展,人们提出了软件可信性这个概念,软件可信性有许多定义[8-12],它们的共同点在于软件可信性是一个复合的概念,包含了软件几个方面的属性,而这些属性之间如何统一起来反映软件可信性是一个大问题[13]。以漏洞和故障为例,漏洞有以上提到的几个属性,而故障的属性和漏洞不是一一对应的,因此二者不能直接合并。此外,软件可信性包含强可靠性和强安全性[12],它们的度量量纲也不一样,需要一个统一的度量量纲。
2 损失量度量和预测漏洞
现有实际漏洞库给出的最基本的数据都是发现漏洞的个数、类型和严重程度等数据。在使用这些数据度量软件的安全性时,遇到了两个问题。
第一个问题是现有的漏洞分类方法难以准确描述漏洞对安全性的影响程度。例如,两个网上银行软件可能各有一个漏洞,使得用户的权限泄露,但是其中一个网上银行软件不会造成账户被黑客操作,只是泄露信息,用户必须重置账户信息,银行在此过程中只要支付一定的办公开支即可;而另一个软件系统则造成账户中的钱被取走或消费,银行可能需要赔付客户损失。这两个漏洞即使被认定为属于不同的种类,但是对严重程度的反映并不直观,而且在有些分类方法中,由于都属于权限的泄露,这两个漏洞可能被分为同一级。
第二个问题是为了度量不同软件的可信属性,有必要统一度量的量纲,而现有的漏洞分类方法,要么做不到这一点,要么勉强可以做到,但没有充分地反映软件的可信属性。为了使漏洞的度量能直观、有效地反映软件的可信属性,有必要重新选择度量的量纲。
那么,有没有一个影响因子,既能比较客观地反映出用户对软件系统安全性的信任,又能作为一个统一的量纲来度量软件安全性乃至可信性呢?漏洞所造成的经济损失量符合这个要求。首先,用损失量来描述问题的严重程度,有一目了然的优点。其次,损失量(即钱数)本身就是一个量化的值,而且是统一的。例如,两个不同的漏洞各造成了10 000美元的损失,尽管这两个漏洞可能有很大区别,但是10 000美元和10 000美元总是相等的。第三,使用损失量度量软件安全性乃至可信性可以让用户抛开细节,直接面对他们关心的方面,从而将软件可信问题的主观因素统一在度量中。
在已知的范围内,学术界和产业界还没有研究过使用损失量度量安全性。因此,为了使用损失量作为度量和预测漏洞发现的量纲,有必要审视一下损失出现的规律,以便选择合理的模型。
首先考察漏洞的出现趋势。通常来讲,一个软件系统发布并投入使用后,漏洞从零开始增长,由于具体情况不同,可能在不同时期有不同的增长速度;随着已发现漏洞被修补,新漏洞的发现速度最终会下降;由于漏洞本质上是软件开发部署过程中系统内部固有的缺陷,所以其数量是有限的,不会无限增长,但也很可能不会全部被发现,而且软件最终会因为更新而下降,所以在一个时间点以后,漏洞数趋近于一个固定值。大概的趋势如图1所示。
图1 漏洞数量随时间的变化趋势
漏洞的发现是一个离散的过程,而损失是一个连续的量。损失是由漏洞造成的,但事实上不能得到很精确的记录,而且也不要求预测模型有很精确的结果,只要精确到某个数量级就可以了。所以可以将损失量离散化,比如以1万元或10万元为单位。虽然损失随着离散的漏洞而出现,但是当考虑损失总量的时候,通过离散化方法,也可以得到类似于图1的趋势,如图2所示。
图2 漏洞造成的损失量随时间的变化趋势
因此,损失量也可以使用那些用于预测软件缺陷的模型来进行预测。由于这些模型中很多是基于概率的模型,所以还要确定漏洞的发现是不是概率问题。
很显然,从不同的角度出发,漏洞的发现规律也不同。由于需要建立的是通用的预测模型,而不是专用的模型,必须选择一个有通用性的,在软件漏洞生命周期内人们所扮演的所有角色中,三方软件质量评测机构最符合要求。首先,第三方软件质量评测机构通常建立并维护漏洞的数据库,因此,不缺乏模型需要的基础漏洞数据。其次,第三方软件质量评测机构不参与软件的开发,也不会把自己的工作量作为唯一参数,因为他们明白有许多人同样在挖掘漏洞。第三,尽管第三方软件质量评测机构收集的信息不能精确到函数数量或者工作时间这样的精度,也会有一些时延,但是漏洞预测本身也不可能做到非常精确,一定范围内的误差是不可避免的,所以尽管原始数据越翔实越好,但是如果实在难以获得,也没有必要强求。
从第三方软件质量评测机构的角度来看,漏洞的出现有着随机性,而且可以用一个数字来表示这种随机性的大小,因此漏洞的出现可以看作概率问题。
国内外学者提出了许多模型,比较有代表性的有热动力(AT)模型、对数泊松模型、二次模型、指数模型、逻辑模型、线性模型、多周期模型等。在这些模型中,MUSA[14,15]等人提出的模型考虑了累计的故障数、故障出现率的衰减等因素,因此有十分重要的参考意义。本文将从损失和时间的联系出发,推导出预测模型,并根据实际问题进行改进。
3 漏洞损失量模型
3.1 基本定义及模型
设{M(τ),τ≥0}为一个计数过程,表示到时间τ为止由漏洞造成的累计损失量。显然:

用m(τ)表示到时间τ为止由漏洞造成的累计损失量的期望,为τ的有界不递减函数,m(τ)=E[M(τ)]满足以下关系:

其中,α是最终软件中所有漏洞造成损失量的和的期望。
假设在时间(τ,τ+Δτ)内漏洞造成损失的期望正比于所有未发现漏洞造成损失的和的期望,则:
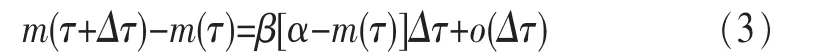
其中,β是常数,且当Δτ→0时,o(Δτ)/Δτ→0。
在式(3)中令Δτ→0,则:

解此微分方程,可得:

m(τ)即M(τ)的均值函数,其密度函数为:
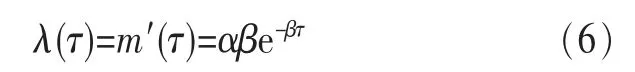
{M(τ),τ≥0}是均值函数为m(τ)、密度函数为λ(τ)的泊松过程,y是自然数,并且满足:
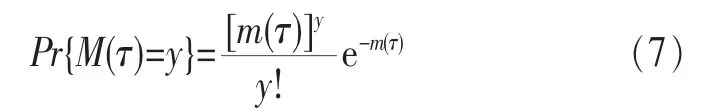
为了区别于传统的安全度,定义基于损失量的安全度为强安全度,其具体定义为在上一个损失时间一定的条件下,下一段时间内不发生漏洞引起的损失的条件概率。
Ti′(i=1,2,…)表示第i-1个损失mi-1到第i个损失mi的时间间隔的随机变量,Ti(i=1,2,…)表示到第i个损失mi的时间的随机变量,则:
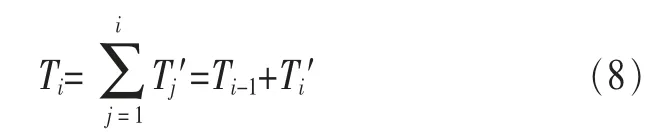
其中,T0=0。
给定时间序列τ1,τ2,…,τn,则T1,T2,…,Tn的联合密度函数为:
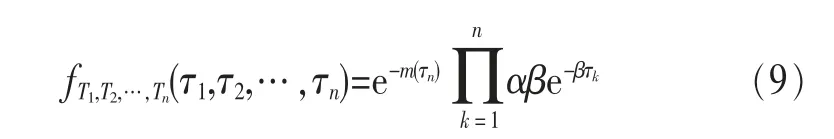
对数似然函数为:
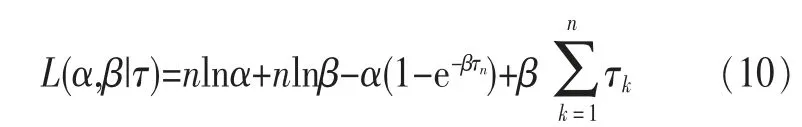
分别对α、β求导,并对导数赋0,建立方程组:
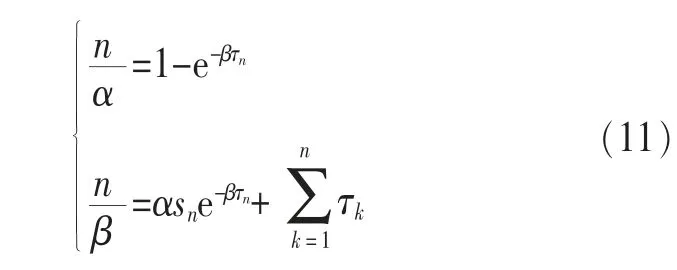
由此用数值方法可求解,解出α、β。
3.2 实际数据检验
从中国国家信息安全漏洞库中选取了Windows XP操作系统,Adobe Flash Player和Mozilla Firefox从发布起,累计200个漏洞的数据。这些漏洞按严重程度被分为4类,其中等级4最危险。假定严重等级越高损失越大,一个等级对应一个损失量级,在本文的例子中规定严重程度为1的漏洞造成1万元损失,严重程度为2的漏洞造成2万元损失,以此类推。将漏洞按发现日期排列,计算出发现日期距软件发布日期相差的天数。同时,假设一天只发现一次损失,因此将同一天内的损失量合并取平均值。
使用前50个数据来估算剩下的数据并与实际数据比较,误差在±0.5之间的结果记为预测成功,计算结果见表1(α=257.0,β=0.003 6,准确率约为20%)、表2(α=288.0,β=0.002 1,准确率约为35%)、表3(α=211.0,β=0.006 1,准确率约为30%)。
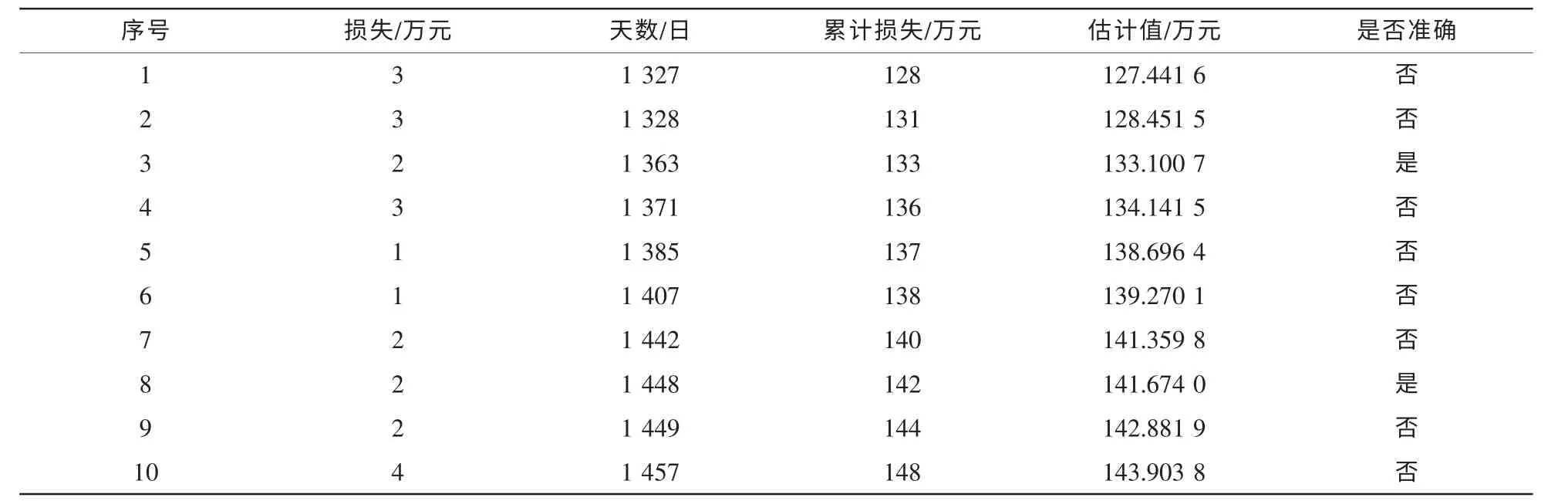
表1 Windows XP预测结果
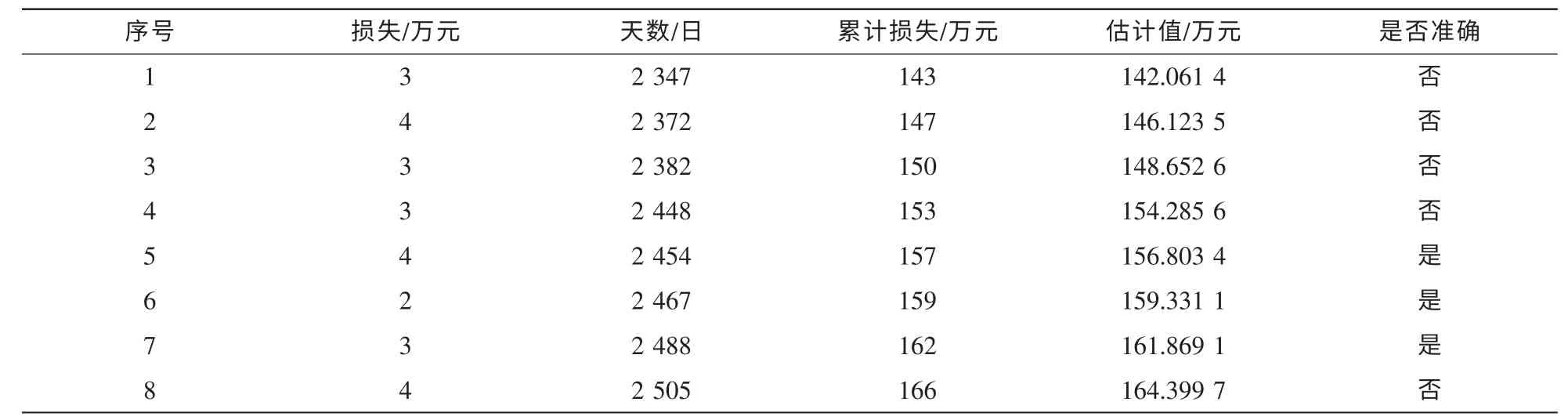
表2 Flash Player预测结果
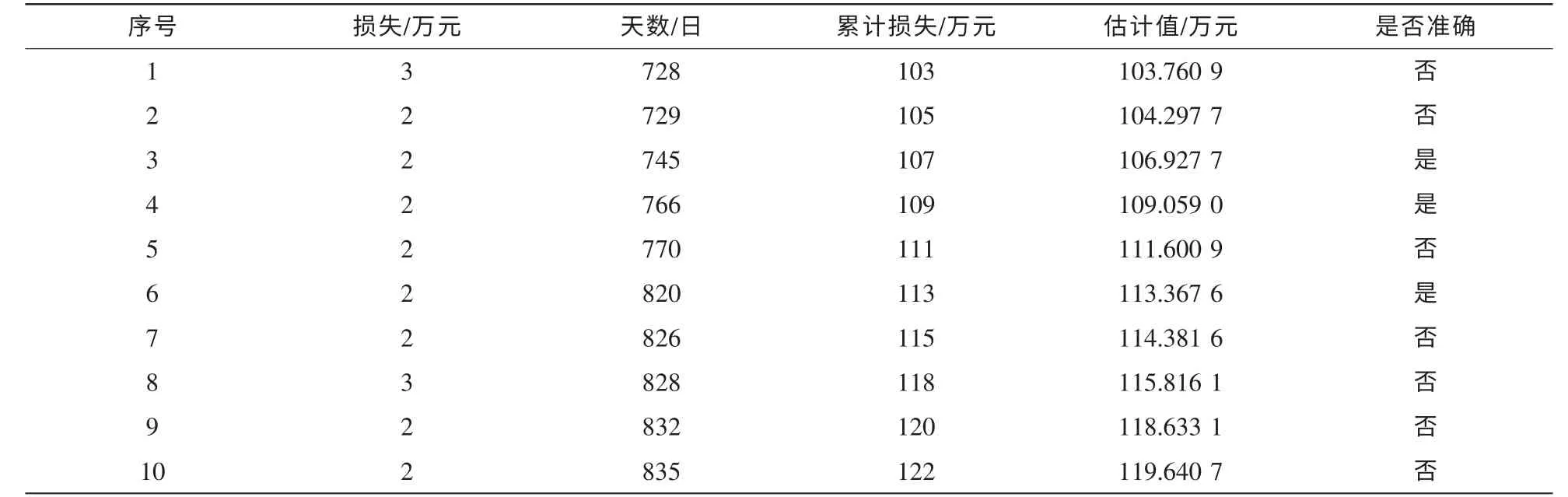
表3 Firefox预测结果
4 改进模型
从以上分析可以看到,预测结果并不理想,下面将对预测结果进行分析,改进预测模型,以得到更好的效果。
设τi为发生第i次损失的时间,τi′为此次损失与上一次 损 失 之 间 的 时 间 间 隔,即τi′=τi-τi-1,则 在 时 间(τi-1,τi]中产生损失与τi′相关,ω为相关系数。
设t=f(τ)=τ+ωτ′,为了表示方便,没有给t、τ和τ′加下标,在实际数据中它们是一一对应的。
为了保证损失量不变,设随机过程N(t),规定:N(t)=N[f(τ)]=M(τ),Pr{N(t)=m}=Pr{M(τ)=m}。
设N(t)的均值函数为μt(t),密度函数为λt(t),则:

这相当于从 坐标系{τ,μ(τ)}转换 到坐标系{t,μt(t)},由于t是τ变换后的结果,而μt(t)=μ(t),那么拉长后的损失量曲线应该比原曲线更平缓,如图3所示。
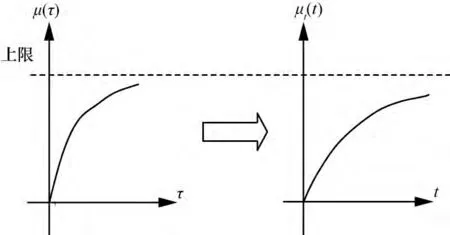
图3 坐标系的变换
可以得出:

损失密度函数为:

同理,可以得到似然函数:
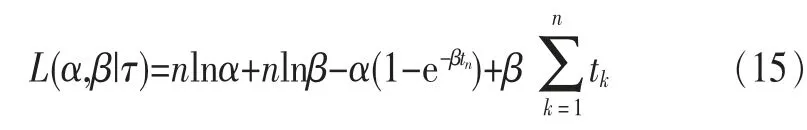
分别对α、β、ω求导,并对导数赋0建立方程组:
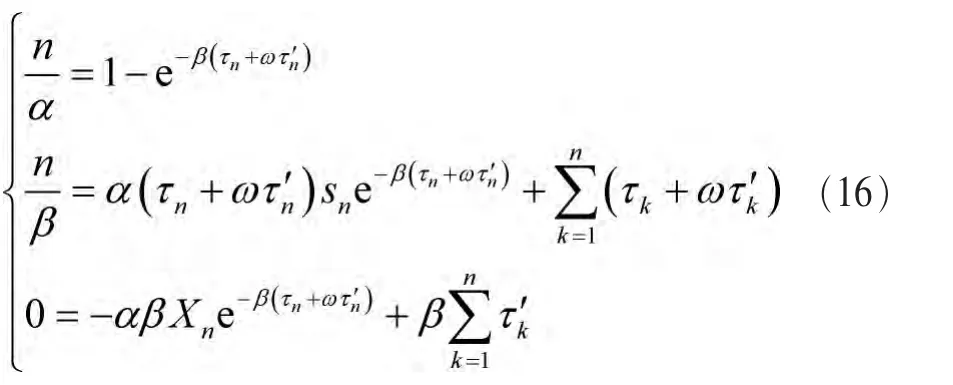
用数值方法可求解出α、β、ω。
5 实际数据检验
使用与上文相同的数据和判断预测是否成功的标准,运用提出的改进模型,计算结果见表4(α=190,β=0.003 4,ω=76.677 8,准确率约为50%)、表5(α=181,β=0.003 1,ω=49.950 1,准确率约为62%)、表6(α=155,β=0.003 8,ω=51.475 6,准确率约为50%)。
6 结束语
以上判断准确率的标准是可以变动的,实际应用中未必选择±0.5作为标准。由于本文把损失分为4个等级,严格来讲即使是猜测,也有25%的准确率,所以本文提出的基本模型依然比猜测可靠。
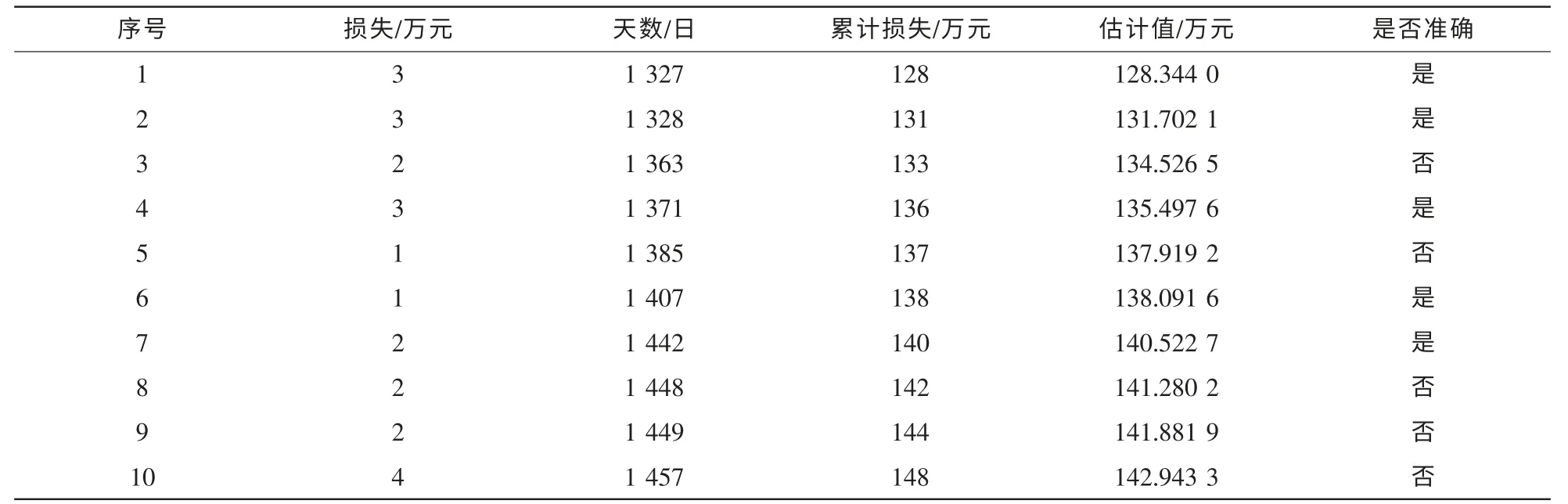
表4 Windows XP改进模型预测结果

表5 Flash Player改进模型预测结果
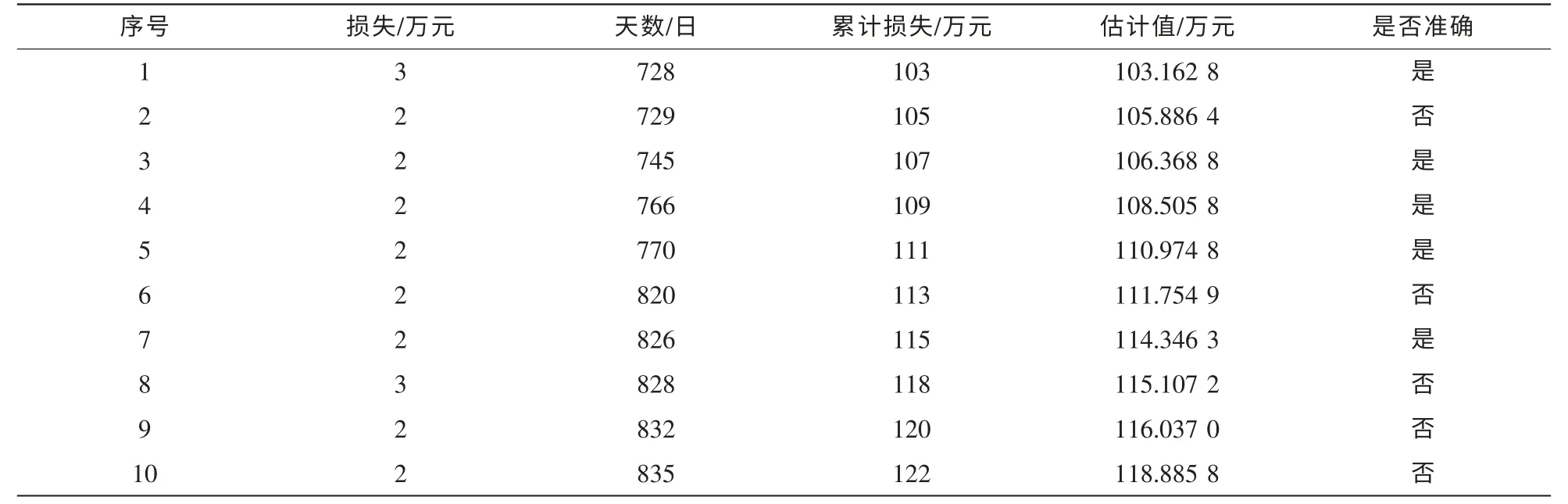
表6 Firefox改进模型预测结果
从另一方面来讲,本文提出的改进模型把时间进行一个变换,即拉长时间的目的是为了使预测结果更接近真实数据,这包含两个方面的意义:第一,预测损失量的趋势应该与实际数据相同;第二,预测损失量的曲线应该与实际数据吻合得比较好。那么,就画出两个模型的结果和实际数据的曲线,如图4所示。
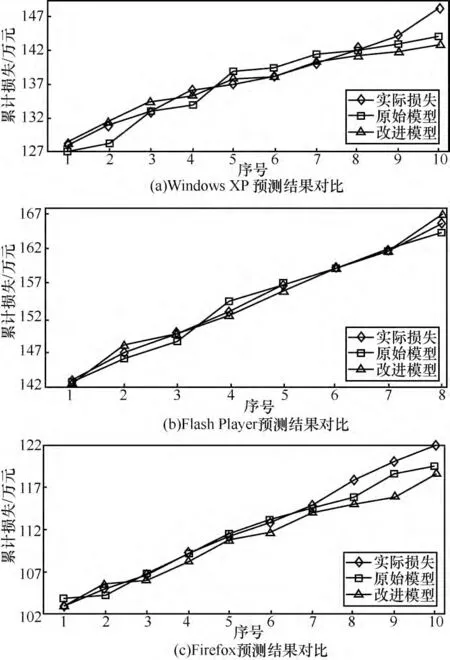
图4 原始模型和改进模型曲线比较
可见,预测曲线的趋势与实际是一致的,3组数据中,改进模型的曲线明显比原始模型的曲线更贴近实际曲线,这也和表格中的数据吻合。通过拉长时间轴,得到了更好的预测结果。
[1]SCHULTZ J E,BROWN D S,LONGSTAFF T A.Responding to computer security incidents[EB/OL].(1990-07-23)[2015-09-20].ftp://ftp.cert.dfn.de/pub/docs/csir/ihg.ps.gz.
[2]PFLEEGER C P.Security in computing[M].Upper Saddle River:Prentice-Hall,1997:46-48.
[3]SHIN Y,WILLIAMS L.Is complexity really the enemy of software security[C]//The 4th ACM Workshop on Quality of Protection,October 27-31,Alexandria,VA,USA.New York:ACM Press,2008:47-50.
[4]ANDERSON R.Security in open VeTSUS closed systems-the dance of boltzmann,coase and moore[C]//The Conference on Open Source Software Economics,Jul 9,2002,London,UK.Cambridge:MIT Press,2002:1-15.
[5]MUSA J D,IANNINO A,OKUMOTO K.Software reliability engineering[M].New York:McGraw-Hill,1999:193-223.
[6]MUSA J D,OKUMOTO K.A logarithmic Poisson execution time model for software reliability measurement[C]//The 7th Int’l Conference on Software Engineering.Orlando:IEEE Press,1984:230-238.
[7]RESCORLA E.Is fining security holes a good idea[J].IEEE Security&Privacy,2005,3(1):14-19.
[8]BECKER S,HASSELBRING W,PAUL A,et al.Trustworthy software systems:a discussion of basic concept and terminology[J].ACM Sigsoft Software Engineering Notes,2006,31(6):1-18.
[9]杨光宇,曾东方,罗平.考虑短板效应的一种度量模型及其在软件可信性中的应用[J].计算机应用研究,2012(1):165-167.YANG G Y,ZENG D F,LUO P.Metric model considering effect of short board and its application in software trustworthiness[J].Application Research of Computers,2012(1):165-167.
[10]王怀民,刘旭东,郎波,等.软件可信分级规范v2.0[R/OL].[2009-05-30].http://www.doc88.com/p-3008711993507.html.WANG H M,LIU X D,LANG B,et al.Software trustworthiness classification specification v2.0[R/OL].[2009-05-30].http://www.doc88.com/p-3008711993507.html.
[11]王怀民,唐扬斌,尹刚,等.互联网软件的可信机理[J].中国科学E辑,2006,36(10):1156-1169.WANG H M,TANG Y B,YIN G,et al.The trusted mechanism of Internet software[J].Science in China(E),2006,36(10):1156-1169.
[12]LIU Y Z,ZHANG L,LUO P,et al.Research of trustworthy software system in the network[C]//The 5th International Symposium on Parallel Architectures,Algorithms and Programming,Dec 17-20,2012,Taipei,China.New Jersey:IEEE Press,2012:287-294.
[13]VOAS J.Why is it so hard to predict software system trustworthiness from software component trustworthiness[C]//The 20th IEEE Symposium on Reliable Distributed Systems,October 28-31,2001,New Orleans,Louisiana,USA.New Jersey:IEEE Press,2001:179.
[14]MUSA J D.A theory of software reliability and its application[J].IEEE Transactions on Software Engineering,Los Alamitos,1975,1(3):312-372.
[15]MUSA J D,OKUMOTO K.A logarithmic Possion excution time model for software reliability measurement[C]//The 7th International Conference on Software Engineering.[S.l.]:Whippany Bell Laboratories,1984:230-238.
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
中国特种设备安全(2022年1期)2022-04-26
数学年刊A辑(中文版)(2022年4期)2022-02-16
科技创新与应用(2021年36期)2021-12-11
中国煤层气(2020年2期)2020-06-28
廊坊师范学院学报(自然科学版)(2020年1期)2020-04-17
数学年刊A辑(中文版)(2019年3期)2019-10-08
疯狂英语·新读写(2018年3期)2018-09-07
质量技术监督研究(2017年4期)2017-05-07
现代食品(2016年14期)2016-04-28
