
基于三级索引和Trie的IPv6路由查找算法研究
2015-03-07 02:07刘阳
山东农业大学学报(自然科学版) 2015年4期
刘阳
滨州学院信息工程系,山东滨州256603
基于三级索引和Trie的IPv6路由查找算法研究
刘阳
滨州学院信息工程系,山东滨州256603
摘要:Internet的迅速发展使得骨干网核心路由器转发分组的数量呈指数级增长,快速的IP路由查找算法是实现高速分组转发的关键。IPv6的应用,使得路由查找算法要适应IPv6地址的特点。本文分析了典型的基于Trie的路由查找算法,总结各种算法的优缺点。结合IPv6地址特征和骨干路由器路由表地址前缀的分布规律,提出了一种基于三级索引表和多比特Trie的快速IPv6路由查找算法。与其他同类算法相比较,该算法易于实现,并且具有较快的查找和更新速度,较低的存储空间。
关键词:索引表;多比特Trie;路由查找; IPv6
Internet的迅猛发展,使其链路速度、带宽、流量等呈指数级增长[1],骨干网络核心路由器的接口速率也随之迅速提高。快速的IP地址路由查找算法是实现高速分组转发的关键[2],IP路由查找操作已经成为当前路由器转发性能的瓶颈之一[3]。互联网下一代IP协议使用地址长度为128位的IPv6地址,随着无分类域间路由(Classless Inter Domain Routing,CIDR)的引入,IP地址查找采用最长前缀匹配(Longest Prefix Match,LPM)算法,更加增加了IPv6路由查找的复杂性[4-6]。如果简单的套用原有的用于IPv4路由查找算法,将会导致读取存储器的次数和占用的存储空间急剧增加,性能急剧下降[7],因此,要得到较好的路由必须使算法更适用于IPv6的结构[8],寻找一种适用于IPv6的路由查找方法显得十分重要。
为了提高路由查找和更新的速度,路由表一般采用一定的数据结构进行存储,查找和更新算法不仅要有较快的速度,同时在所需存储空间方面有比较好的性能。基于Trie的算法是常用的路由查找算法,它不仅结构简单,而且在时间复杂度和空间复杂度等方面均能满足不断提高的路由器性能要求。因此,很多现代的路由算法都是在此基础上进行优化和改进。本文分析基于Trie的路由查找算法的优缺点,根据骨干网络核心路由表中地址前缀的分布规律,提出一种快速IPv6路由查找算法,该算法采用索引表和多比特Trie两种数据结构。从性能上来看,该算法易于实现,并且具有较快的查找和更新速度,较低的存储空间。
1 典型的Trie树路由查找算法
1.1二进制Trie树
Trie树是表示地址前缀的常用方法,是一种被广泛应用的数据结构[7]。二进制Trie树是一棵二叉树,树中每个节点(除叶子节点以外)只有两个分支,每个节点代表一个地址前缀,而Trie树中的部分节点保存着地址前缀信息。例如,某路由器的部分路由表如表1所示。表中*是通配符,下一跳地址为a、b、c、d、e的表项的地址前缀分别为00,0001,010111,01,1000。
根据表1的路由前缀信息,可以构造一棵二进制Trie树。其结构见图1。
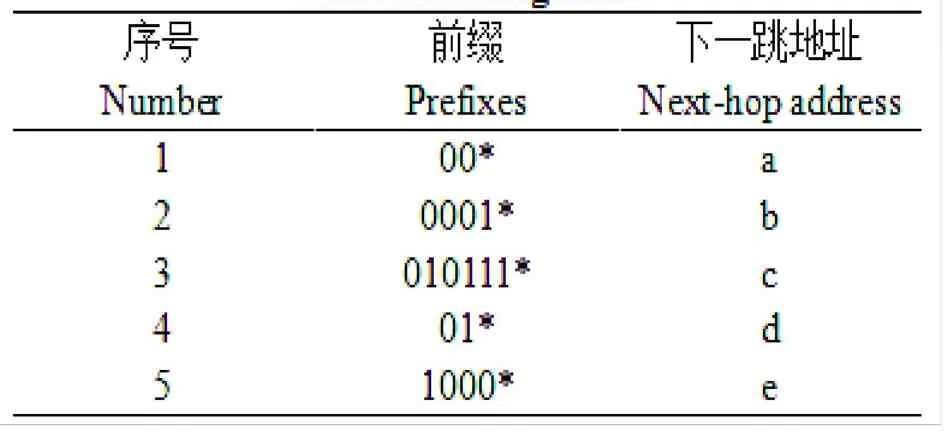
表1 路由表Table1 Routing table
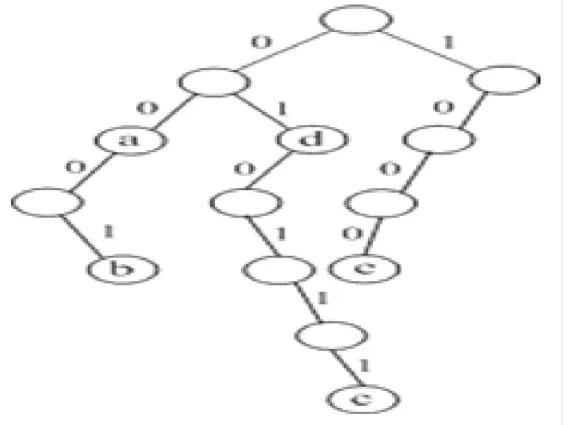
图1 二进制TrieFig.1Binary Trie tree
从图1可以看出,处于第L层的节点代表一类地址前缀L比特均相同的地址空间。例如,c节点代表地址前缀前4比特为1000的一类地址空间。在查找的过程中,有可能出现多个前缀同时匹配的情况。例如,若到来的分组的地址前缀为0001,根据图1,可以看出(a,b)均能够匹配,这时按照最长前缀匹配原则,b节点为最后查找结果。在查找过程中要记录当前最匹配的路由前缀,一直到叶子节点或者节点没有合适的分支为止。用二叉Trie树组织路由转发表,结构比较简单,易于实现[9]。但访存次数与地址前缀长度相同,若地址前缀长度为w,则此算法的时间复杂度为O(w)[10]。对于图1的二进制Trie树,此算法的时间复杂度为O(6)。若用于IPV6路由查找,在最坏的情况下,树的深度为128,需要访问128次存储器,时间复杂度为O(128)。
1.2多比特Trie树
在基本的二进制Trie树中,每次读取一个比特信息,步长为1。多比特Trie树选择一次读取多个比特,若树的深度为L,则多比特Trie树的时间复杂度为O(L)。因此,路由查找的时间复杂度大大降低。根据表1的前缀信息,可以构造一棵步长为2的多比特Trie树(见图2),此时,算法的时间复杂度为O(3)。IPv6路由查找时,在最坏的情况下,步长可以设置为128,只需要一次访问存储器的操作,其时间复杂度为O(1),但它却是以牺牲存储器空间为代价的,需要2128个表项的存储空间。步长选择是多比特Trie树进行路由查找必须解决的问题之一[10]。
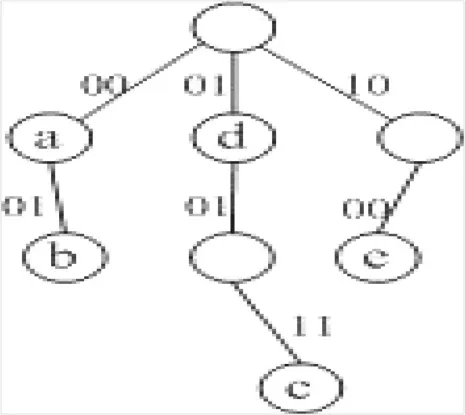
图2 多比特Trie树Fig.2 Multi-bit Trie tree
1.3其他基于Trie树的路由算法
文献[11]提出了层次压缩树(Level Compressed Trie,简称LC-trie)的概念,该算法首先对二进制Trie树的稀疏部分进行路径压缩,然后将压缩后Trie树的稠密部分转换为多比特Trie树。以此达到减少访存次数和节约存储空间的效果,但是对前缀的更新支持不是很好。文献[12]提出了以32 bits为查找路由前缀起点的分段哈希表和多比特Trie树相结合的IPv6路由查找算法,该算法与单纯多比特树查找算法相比,在一定程度上提高了查找效率,但需要构造一个完备哈希函数来解决冲突问题。本算法采用三级索引表和多比特Trie树,无论在查找效率和消耗存储空间上,都具有很好的性能。
2 算法设计
2.1IPv6路由前缀分布规律
128位的IPv6地址空间被划分为两大部分[13]。其中,高64 bits表示网络前缀,低64 bits表示后缀,即主机。根据RFC3587中规定的全球单播地址的标识长度为高64 bits,不用于子网间的路由。因此,IPv6单播地址的地址前缀长度不会小于64 bits,而是介于65~128 bits之间,并且只可能有长度为128 bits的前缀。而按照IPv6单播地址的分配策略,不存在长度小于16 bits的网络前缀。就单播IPv6而言,以6 Bone,6 Net等几个IPv6骨干实验网络的数据来看,其前缀长度主要介于19~64 bits,核心路由器关心的是目标地址的高64 bits[14]。从骨干自治域AS2、AS1221、AS6447等的路由表来看,路由前缀分布存在一定规律,不存在长度小于16 bits的前缀[12],而前缀长度为32 bits的最多,前缀长度为48 bits的位居其次,这两部分占全部路由表的4/5以上[15],不存在前缀长度介于64~128 bits之间的前缀,而长度为128 bits的前缀仅有几个,这也符合IPv6的地址分配策略。
2.2算法的数据结构
依据IPv6路由前缀分布规律,本算法采用三张索引表和三棵多比特Trie树来实现。算法将128 bits的IPv6地址空间划分成五段,分别为16 bits,32 bits、48 bits,64 bits和128 bits,地址前缀长度为16 bits和32 bits、48 bits和64 bits、128 bits信息分别存放在三张索引表中:H_Tab1、H_Tab2、H_Tab3;而前缀长度介于16~32 bits、32~48 bits、48~64 bits的信息存放在3棵多比特Trie树Trie_1、Trie_2、Trie_3中。为了有效利用和节约存储空间,三张索引表采用不同的数据结构。
2.2.1索引表的数据结构索引表H_Tab1与H_Tab2采用相同的数据结构,包含五个字段:IP_Pre字段、2个标志位MP_1和MP_2字段,Fill_Len字段和NHP_Add字段。IP_Pre字段用于存放0~31 bits 或32~63 bits地址前缀,当路由表中前缀长度不足32 bits时,需要用连续的1进行填充,使其填充后满足32 bits;MP_1用来标志是否存在比32 bits或64 bits更长的前缀,占1 bit,当MP_1=1时,表示存在比32 bits或64 bits更长的前缀,反之则表示没有;MP_2用来标志是否存在比16 bits或48 bits更长前缀,占1 bit,当MP_2=1时,表示存在比16 bits或48 bits更长的前缀,反之则表示没有;Fill_Len表示当前缀长度大于16 bits但小于32 bits或者当前缀长度大于32 bits但小于48 bits时,需要进行填充的比特数,占3个比特,取值范围为000-111;NHP_Add存放转发接口或下一跳地址、Trie树或者下一级索引表的地址。索引表H_Tab1和H_Tab2的数据结构见图3。

图3 H_Tab1和H_Tab2的数据结构Fig.3 Data structure of H_Tab1 and H_Tab2
H_Tab1和H_Tab2中MP_1、MP_2标志位和Fill_Len有几种有效的组合,每种不同的组合,NHP_Add的表示含义也有所不同。在数据存储完毕之后,需要对该表按照Fill_Len进行升序排序,以提高查找效率。以索引表H_Tab1为例说明几种组合的含义。其中:
①MP_1=0,MP_2=1,Fill_Len=000时,说明不存在比32 bits更长的前缀,前缀长度正好是32 bits,NHP_Add用来表示转发接口地址或者下一跳地址;
②MP_1=1,MP_2=1,Fill_Len=000时,说明存在比32 bits更长的前缀,NHP_Add用来表示H_Tab2索引表的地址;
③MP_1=0,MP_2=0,Fill_Len=000时,说明前缀长度正好为16 bits,NHP_Add用来表示转发接口地址或者下一跳地址;
④MP_1=0,MP_2=1,Fill_Len=m(8>m>0)时,说明在原有前缀后填充了mbits,即前缀长度介于16~32 bits之间,NHP_Add用来表示多比特树Trie 1的地址;
⑤其他情况为无效情况。
因为不存在长度介于64~128 bits之间的前缀,只存在长度为128 bits的前缀,为了节约存储空间,H_Tab3表的结构与H_Tab1相比减少了三个字段,只有IP_Pre和NHP_Add两个字段,其含义与H_Tab1表相同。
2.2.2多比特Trie树的数据结构多比特树用来查找长度介于16~32 bits之间、32~48 bits之间和48~64 bits之间的地址前缀。为了降低算法的复杂性,本算法采用步长为3的固定步长多比特多比特树,由于基于Trie树的查找最多只涉及15 bits,因此,最多就只需要5次访问内存。例如,若a、b、c代表三个地址前缀,长度在32~48 bits之间,其地址前缀的前32 bits已经存储在H_Tab1表中,而其后的比特串分别为100*,101001*,10100101*,由它们构成的多比特Trie树见图4,其数据结构见图5。
其中,Next_Node指针指向该节点的下一层节点,当w=3时,下一层节点总数为23个,共需要23个指针;Next_Add指针指向转发接口或者下一跳地址。存储多比特树需要占用较多的存储空间,但由于本算法采用固定步长的比特树,因此结构相对简单,易于实现。目前存储器价格低廉,所消耗的存储空间也是可以接受的。
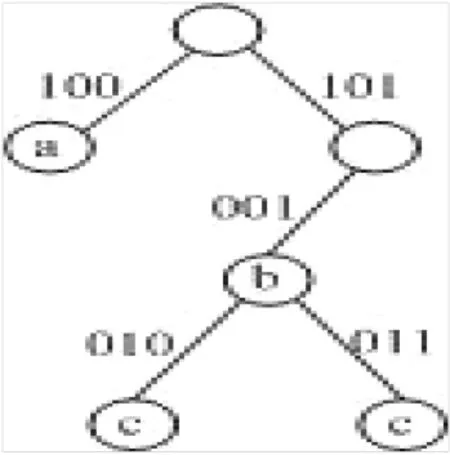
图4 多比特Trie树Fig.4 Multi-bit Trie tree
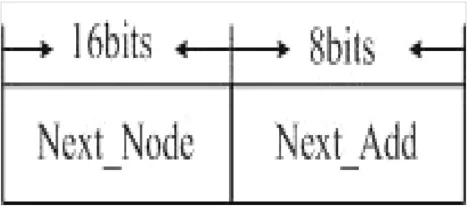
图5 多比特Trie树数据结构Fig.5 Data structure of multi-bit Trie tree
2.2.3整体数据架构在三张索引表中,IP_Pre用来记录地址前缀信息,NHP_Add用来存储下一跳或转发接口的地址。当目标IP地址的前缀为16 bits或32 bits时,只需要查找H_Tab1表;当前缀为48 bits或64 bits时,在查找H_Tab1表之后,按照NHP_Add中指向的地址继续查找H_Tab2表;如果前缀为128 bits时,在查找H_Tab1、H_Tab2后,要继续查找H_Tab3。而当前缀长度介于16~32 bits之间时,在查找H_Tab1表之后,要按照NHP_Add中指向的地址继续查找Trie_1;当前缀长度介于32~48 bits之间时,在查找H_Tab2表之后,要按照NHP_Add中指向的地址继续查找Trie_2;当前缀长度介于48~64 bits之间时,在查找H_Tab2表之后,要按照NHP_Add中指向的地址继续查找Trie_3。根据如上描述,算法的整体的数据架构见图6。
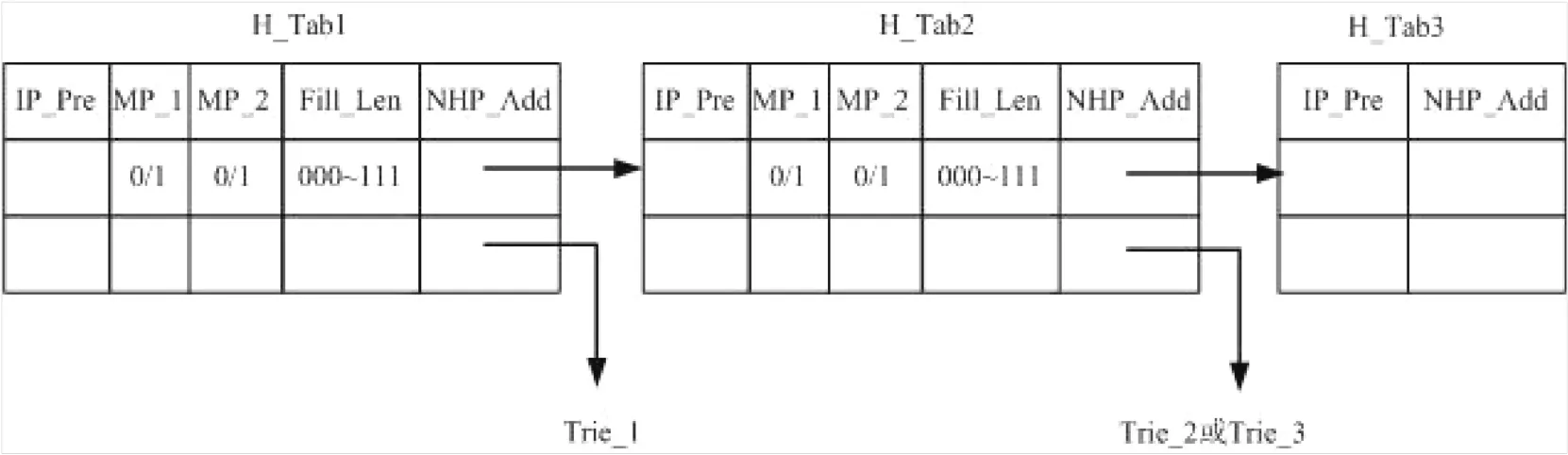
图6 算法整体数据架构Fig.6 Data workup of the algorithm
3 算法流程与性能分析
3.1算法流程
H_Tab1和H_Tab2表在存储时,以Fill_Len字段为主关键字、MP_1字段为次关键字进行升序排序。这样排序后,可以保证表中的表项是按照地址前缀长度为32 bits或64 bits、大于32 bits或64bits、等于16 bits或48 bits、介于16~32 bits或者介于48 bits和64 bits的顺序进行排序。以表H_Tab1为例来说明这样做的目的:前面分析过,IPv6路由表中,前缀长度为32 bits和48 bits的表项占总路由表的4/5,因此,这样做可以保证绝大多数的地址前缀长度为32 bits的IP地址可以一次命中,从而尽最大可能减少访存次数。以查找H_Tab1为例,说明路由查找的过程,其查找详细流程见图7。
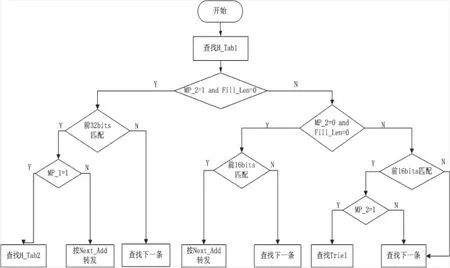
图7 查找H_Tab1流程图Fig.7 Flow chart of looking for H_Tab1
3.2算法的性能分析
从时间复杂度和所用的存储空间两个方面来分析算法的性能。3.2.1时间复杂度当一个IP数据包到来时,提取目的IP地址,然后查找路由表来转发分组。如果的路由前缀长度为16 bits、32 bits、48 bits、64 bits和128 bits,只需查找各级索引表,则分别需要1次、1次、2次、2次、3次访问存储器。除了以上几种情况,每次查找除了要访问索引表之外,还需要加上访问多比特树的访存次数。考虑最坏的情况,各种情况的访存次数如表2所示。
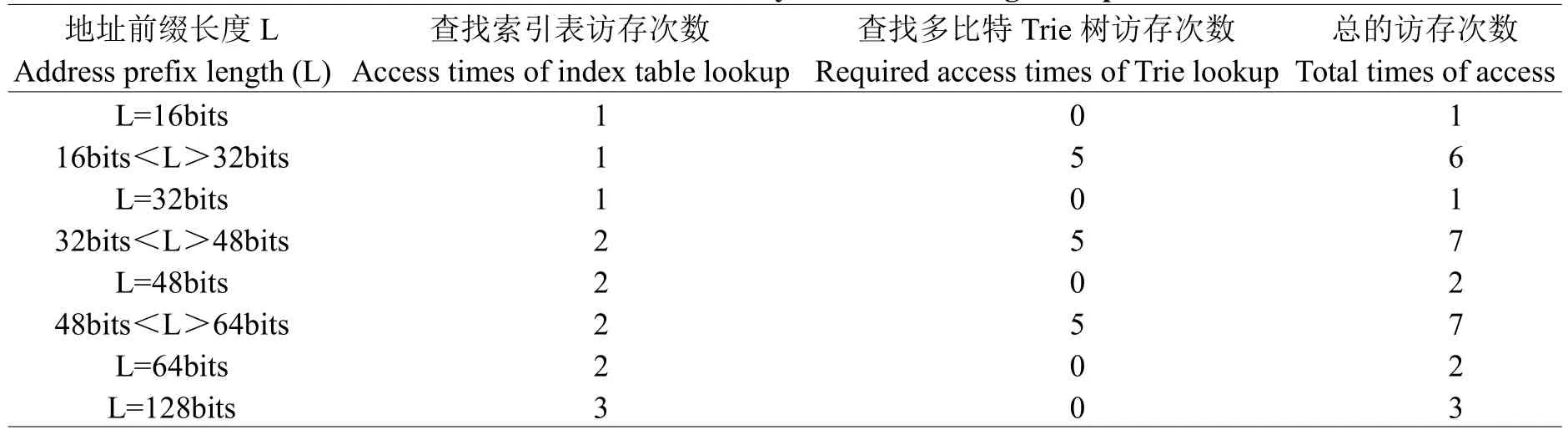
表2 路由查找访存次数Table 2 Times of memory access of routing lookup
从表2可以看出,最坏情况下,当前缀长度介于48~64 bits之间时,在查找H_Tab1、H_Tab2两张索引表后,还要访问一棵多比特树,访存次数共计7次,总的时间复杂度为O(7)。由于IPv6路由表中32 bits和48 bits的前缀占总路由表的4/5以上,如果分组按照这个比例到达路由器,那么大多数情况下的查找复杂度为O(1)或O(2),即只需一次或两次内存访问就可查到路由信息。路由更新过程类似于路由查找过程,算法复杂度也为O(7)。
3.2.2所需存储空间算法所需要的存储空间主要用来存放索引表、多比特Trie树。三张索引表所需的存储空间分别为:H_Tab1表有5个字段,长度共53 bits;H_Tab2表有5个字段,长度共53 bits;H_Tab3表有2个字段,长度共80 bits。最坏情况下,一个地址前缀长度为128的路由表项,则需要186bits的存储空间,而相同情况下,文献[12]算法则需要270 bits的存储空间。多比特树步长为3,深度为5,每个多比特分支共有23个指针,,一颗满8分支树最多存在86-2个节点,每个节点需要存储24个指针和其他字段信息,多比特树所需要的存储空间约4 MB,与文献[12]算法相当。而实际上,由于多比特树存储的路由属于稀疏分布,多比特树可以采用可变步长,也可以采用层次压缩技术,也可以采用文献[16]所提到的多比特树优化算法,以节约存储空间。

表3 不同算法时间复杂度的比较Table 3 Comparison of time complexity of the different algorithms
4 结论
(1)采用三级索引表,将128 bits的IPv6地址空间分成了3部分。当路由前缀长度为16 bits、32 bits、48 bits、64 bits和128 bits时,通过查找各级索引表,分别需要1次、1次、2次、2次、3次访问存储器。前缀长度为32 bits和48 bits的路由表项占路由表的4/5,因此,绝大多数情况下,只需要1次或2次即可完成查找。
(2)采用固定步长为3 bits的多比特Trie树,用来查找长度介于16~32 bits之间、32~48 bits之间和48~64 bits之间的地址前缀。多比特Trie树最多只涉及15 bits,树的深度为5,时间复杂度为O(5)。而更新过程与查找过程相同,因此,更新速度与查找速度相同。
(3)从路由查找速度和更新速度来看,该算法访问存储器的次数远低于二进制Trie树和单纯采用多比特Trie树的路由查找算法,优于文献12中所提到的基于哈希表和多比特Trie的算法;从算法所使用的存储空间来看,该算法所使用的存储空间也低于文献12算法所需的存储空间。
(4)提出的基于三级索引表和Trie的IPv6查找算法在保持低存储空间的基础上,提高了查找和更新路由表的效率,但由于路由表存储时要对路由表进行排序处理,在一定程度上增加了算法的时间复杂度。今后的研究将开展为该算法选择或设计一个适合的排序算法,与本研究的查找算法相结合,提供更完善的IPv6路由查找方案。
参考文献
[1] Roberts LG. Beyond Moore’s Law: Internet growth trends[J]. IEEE Computer-Internet Watch, 2000,33(1):1172-119
[2]郭文文.基于Trie的软转发路由查找模块的设计实现[D].南京:南京邮电学院,2011:1-2
[3]谭明锋,高蕾,龚正虎.IP路由查找算法研究概述[J].计算机工程与科学,2006,28(6):87-91
[4]杨玉梅,黎仁国.基于二分查找和Trie的IPv6路由查找算法[J].兰州理工大学学报,2012,38(4):98-102
[5]高莹,王贺明.陈强.采用分段哈希方法的IPv6路由查找算法研究[J].计算机工程与设计,2010,31(22):4790-4791
[6]王亚刚,杜慧敏,杨康平.使用Hash表和树位图的两级IPv6地址查找算法[J].计算机科学,2010,37(9):36-37
[7]白晓庆.基于分层分段和索引表的前缀区间IPv6路由查找算法[D].沈阳:东北大学,2010:9-10
[8]刘伟,刘伟科,闫春.IPV6下的路由技术[J].电脑知识与技术,2006,28(20):74-75
[9]王东菊.基于Bloom滤波器的快速路由查找算法研究[D].大连:大连理工大学,2013:10-13
[10]崔尚森,冯博琴.最长前缀匹配查找的索引分离Trie树结构及其算法[J].计算机工程与应用,2005,41(20):131-135
[11] Nilsson S, Karlsson G. IP address lookup using LC-Tries[J]. IEEE Journal on Selected Areasin Communications, 1999,17(6):1083-1092
[12]高莹.哈希表和多比特Trie树相结合的IPv6路由查找算法研究[D].郑州:郑州大学,2010:9-20
[13]谢希仁.计算机网络.第六版.[M].北京:电子工业出版社,2013:189
[14]崔尚森,冯博琴,张白一.一种前缀长度二分查找的改进算法[J].计算机工程,2007,33(15):71-74
[15] Li Z, Deng X, Ma H, et al. Divide-and-Conquer: A scheme for IPv6 Address longest prefixmatching[C]//Proceedings of IEEE Workshop on High Performance Switching and Routing. Poznan, Poland: IEEE Press, 2006:37-42
[16]秦晓分.IPv6路由查找算法研究[D].南京:南京邮电大学,2009:37-40
The Study on IPv6 Routing Lookup Algorithm Based on Three-level Index and Multi-bit Trie
LIU Yang
Department of Information Engineering/Binzhou University, Binzhou 256603, China
Abstract:The rapid development of Internet facilitates the exponential growth in the number of forwarded packets of core router for backbone network and the rapid IP routing lookup algorithm is a key for achieving the high-speed packet forwarding. The application of IPv6 requires the routing lookup algorithm to adapt to the characteristics of IPv6 address. This paper analyzed the typical routing lookup algorithm based on Trie and summarized the advantages and disadvantages of various algorithms. Combining the characteristics of IPv6 address and the distribution laws of address prefixes in the routing table of backbone router, this paper proposed a rapid IPv6 routing lookup algorithm based on the three-level index table and the multi-bit Trie. It was easier to be achieved a faster speed in lookup and updating and required a smaller storage space comparing with other similar algorithms.
Keywords:Index table; multi-bit Trie; routing lookup; IPv6
作者简介:刘阳(1979-),女,硕士,主要从事计算机网络相关工作. E-mail:bzjsjly@126.com
基金项目:滨州学院“青年人才创新工程”科研基金(BZXYQNLG200903);滨州市软科学研究计划项目(2014RKX18)
收稿日期:2015-01-04修回日期: 2015-05-08
中图法分类号:TP393文献标示码: A
文章编号:1000-2324(2015)04-0607-06
