
基于有监督学习的医古文叙述性术语语义标注
2015-04-21 09:44丁长林蔡东风
中文信息学报 2015年2期
丁长林,白 宇,蔡东风
(沈阳航空航天大学 知识工程研究中心 计算机学院,辽宁 沈阳 110136)
基于有监督学习的医古文叙述性术语语义标注
丁长林,白 宇,蔡东风
(沈阳航空航天大学 知识工程研究中心 计算机学院,辽宁 沈阳 110136)
对自由文本形式的中医古籍文献(医古文)进行标注,是对其进行深入分析的前提,语义标注技术是实现该目的的方法之一。该文将中医古籍文献中包含的术语分为名称性术语以及叙述性术语。在分析叙述性术语特点的基础上,将对其语义标注转化为基于有监督学习的短句序列标注或分类问题,并提出了名词性术语规约操作以及基于知网的替换操作两种预处理方法。最后该文通过实验对比了三种学习模型及四种特征选择算法,并证明了问题转化的可行性以及两种预处理方法的有效性。
语义标注;叙述性术语;有监督学习;中医古籍文献
1 引言
语义标注技术作为自然语言处理领域中的基础技术,其结果广泛应用于知识发现等各种深层研究与应用中。同时,中医古籍文献(下称医古文)作为我国中医文化精华的载体,针对其分析和处理也引起了越来越多学者的关注。如果缺少医古文中的类别信息,对其研究只能建立在大量的人为干预或仅停留在简单的统计层面,语义标注(Semantic Annotation,SA)正是获取自由文本类别信息的方法之一。
SA是一个特殊的元数据生成和使用的模型,这一模型的目标是能够吸收新的信息,并扩展原有信息[1]。根据SA所使用的方法,可将其分为人工标注、自动标注两种。而后者又可分为基于模板、有监督以及无监督的学习三种[2]。例如,KIM[1]是采用基于规则的方法,利用模板进行标注的;MnM[3]以标注完成的语料为基础,采用有监督的机器学习方法进行标注;而文献[4]介绍了一种面向特定领域的、基于Bootstrapping算法的无监督学习方法。基于规则的SA往往需要利用大规模的语料来弥补规则不足带来的低覆盖率;而无监督方法很难保证识别的准确率。虽然有监督的学习方法需要大规模的标注语料,但其更能保证标注结果的可用性。同时,目前的SA算法及平台多基于大规模语料(如Web)并面向通用领域。
目前针对医古文的研究主要集中在基于人工标注或简单统计基础上的关联规则挖掘[5]。为了提高关联规则挖掘等研究的效率和准确率,必须对医古文中包含的多种术语进行自动标注。这些术语中,一部分是描述特定事物名称,如中药名称、方剂名称等;另一部分是描述特定事物属性,如症状、病机、病因等。这些术语正是医古文语义标注的对象。本文将前者定义为名称性术语。对于名称性术语的识别[6]可借鉴于命名实体识别的方法[7]。而后者,本文将其定义为叙述性术语。
本文通过分析叙述性术语的特点,发现该类内容多以整句中的分句形式出现,也就是说,只要获取的短句与叙述性术语能够拟合,短句的标注结果就可以被视为叙述性术语的标注结果。因此本文提出将叙述性术语的标注问题转化为短句的分类或序列标注问题。针对古文缺乏特征的标注难点,以减少数据稀疏为主要目的,本文提出了两种预处理方法。最终利用实验对比了不同转化方法、参数设置对标注的影响,证明了两种预处理方法的有效性。
2 叙述性术语标注的任务转化
根据领域专家提供的术语类别,本文将医古文中的叙述性术语定义为描述特定事物属性或具体过程的内容,具体包括症状、病因、病机、针灸、体质、治则、治法、调护等八类。由于现有语料的限制,本文利用症状(ZZ)、病因(BY)、病机(BJ)三类作为叙述性术语识别的范例。而以上三类中医术语均是表述疾病的某方面属性。分析可知,同一疾病的同一属性未必相同,例如,不同人在伤风时的症状不同。同时,同一属性也有可能对应多种疾病,例如,咳嗽的症状可出现在多种疾病中。而在描述属性时,即使某些用词是固定的,由于写作习惯的不同,具体的表述形式也因人而异。因此疾病与其属性形成了多对多的关系,并且叙述性术语的表达方式较为灵活,可见对其识别的难度。同时将不属于以上三类的内容标注为其他类(OT),如下例所示,其中粗体为症状、斜体为病因、下划线部分为病机、无变化的内容属于其他类。
一男子年近五十,久病痰嗽,忽一日感风寒,食酒肉,遂厥气走喉,病暴喑。与灸足阳明别丰隆二穴各三壮,足少阴照海穴各一壮,其声立出。
2.1 叙述性术语的特点
分析现有语料中的叙述性术语后发现,该类术语具有以下特点。
(1) 内容无明显边界。在叙述性术语中,除了部分中医用语外,相当大部分的内容与口语相近,其表达方式也较为灵活。例如,症状: “脓水淋漓,发热吐痰”。这种接近口语的表达方式致使叙述性术语的前后并没有明显的边界,其内容已经融入了整个无结构的文本中,因此利用标记边界的方法对其进行标注是不可行的。
(2) 内容不连续出现。在理想情况下,一个独立单元中,属于同一类的叙述性术语应该连续出现,例如在一篇医案中,描述症状的句子为1~3句,描述病机的为第5句,描述病因的为8~9句。但是如上例所示,在真实文本中,由于其写作的口语化和随意性,几类术语经常交叉出现,并无特定规律。因此利用文本分割方法标注叙述性术语也是不可行的。
(3) 内容相对独立。叙述性术语所描述的是一个完整的事件,比如某疾病的症状。如果在将篇章划分为待标注单元时,保证了切分的合理性,使待标注单元与具有独立意义的叙述性术语重合,就可以利用对人工切分单元的标注获得对应单元的标注。
(4) 内容上下文相关。虽然叙述性术语在表述过程中没有明显的顺序性,但是篇章或整句作为一个整体,每个分割后形成短句的标注是上下文相关的。
2.2 样本粒度
利用标点对自由文本进行切分是最可行、最有效的方法。现有语料中共包含句子(以句号、感叹号以及问号结束)3 878个,字数为93 858,那么平均每句包含24字。古文中一般单字成词,每个字都表示丰富的含义。所以在将叙述性术语的标注转化为短句标注时,以24字的长句作为单位显然不合理。经分析,除上述三个表示句子结束的标点符号外,本文还选择了逗号、冒号以及分号作为切分标点以获得短句,原因如下。
逗号(,): 逗号在整句中频繁出现,其在数量上非常适合做分割标点,并能很好地避免不同的标记内容出现在同一短句中。
冒号(:): 冒号多起引出下文的作用,如在古文中“因悟曰: 诸脉皆属于目”。其中冒号后属于病机类。利用冒号分隔后,冒号之前(包含冒号)的内容明显属于其他类(OT)。
分号(;): 分号一般表示两部分内容的并列,但是并列的内容未必同属一类,因此也将分号作为分隔标点。
以上三种标点的总数为10 374个,则每个短句的平均字数约为6~7个字。在长度上较为合理,下面将证明人工切分单元与叙述性术语的契合性。
经分析发现,叙述性术语多以短句的形式出现,本文将此类短句称为规则化叙述性短句实例(简称规则化短句),除此之外,其他包含叙述性术语的短句同时包含以下几类内容。
(1) 古文虚词: 如病机“此肾经虚火”。 虚词多在叙述性术语与其他内容承接或叙述性术语相互承接时出现。由于虚词多无实际意义,所以将该类短句同称为规则化短句。
(2) 人物代词: 如症状“一老妇两臂不遂”。该类情况多出现在叙述性术语的开始,用来明确该段内容的指向者。
(3) 包含其他内容: 如病因“时冬忽有风气暴至”,该类情况多在叙述性与其他内容承接或一段叙述性短句相互承接时出现,以起到连接或补充说明的作用。
统计现有语料得出表1,该表显示了包含人物代词与包含其他内容的两种非规则短句在所有短句中所占比重。
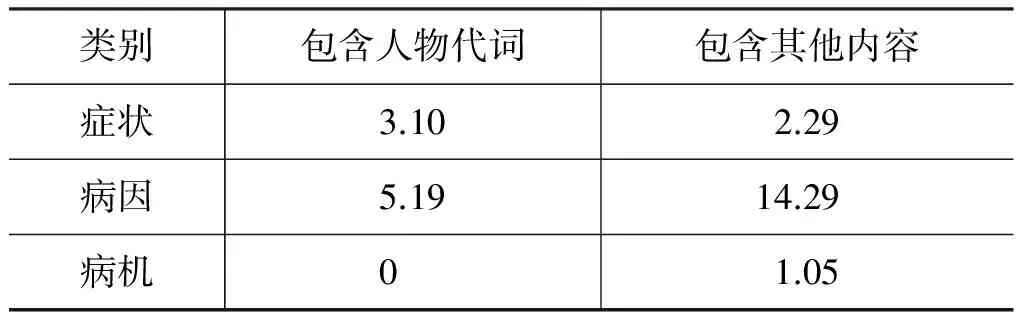
表1 不规则短句在各标注类别中所占比例/%
由表1可知,以上两种非规则短句只占很小的一部分,这使将叙述性术语的标注问题转化为短句的分类或序列标注问题成为可能。而在切分过程中,由于病因类的不规则性最强,致使病因类对问题转化的适应性相对较差。
2.3 语料偏置
利用2.2节的分割粒度对现有语料进行分割后发现语料中存在严重的偏置,如表2所示。
由表2可知,所要标注的三类的总量与其他类数量持平,同时病因类实例过少。严重的语料偏置会使学习器在训练过程中,为了提高拟合率而偏向于实例较多的类别。这一点在实验中也得到了验证。
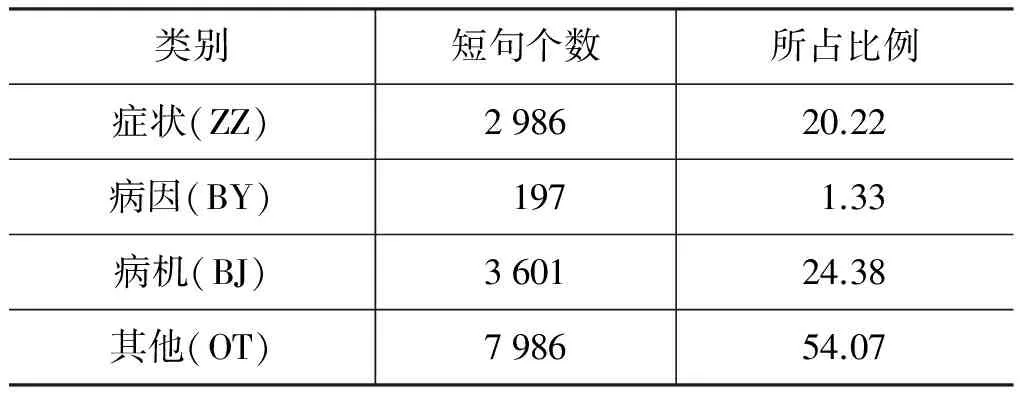
表2 各类短句在语料中的所占比例/%
3 叙述性术语标注特征的分析
3.1 短句切词的粒度 据统计,除专有名词外,古文中80%以上为单音词。所谓单音词是指一个字就是一个事物概念,可以单独作为一个语义单元,如古文中“妻子”表示现代文“妻子”和“子女”的意思。因此,在古文中,可以直接利用字作为切分单位。也就是说,对于古文的处理,在学习器的训练过程中,以短句中的字作为特征是有效、可行的。
3.2 学习算法的选择
如2.1节所述,短句是上下文相关的,能够利用动态标注结果的模型即序列标注模型更适合于解决该问题。在自然语言处理的多数领域中,条件随机场(Conditional Random Fields,CRF)的效果要优于其他的序列标注模型[8]。同时,也可将短句的标注问题转化为短句的分类问题,在分类模型中最大熵(Maximum Entropy,ME)、支持向量机(Support Vector Machine,SVM)较为常用。以上提到算法为代表的两种转换方法的对比如表3所示。
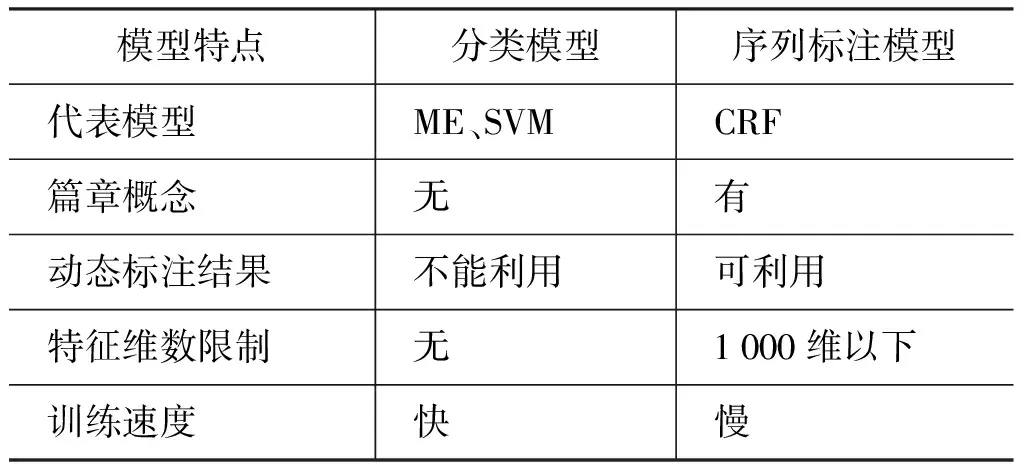
表3 两种短句标注任务转换方法对比
其中,是否有篇章概念是指,在学习器的训练过程中,能否在段落或篇章内考虑待标注单元的标注结果。在本文中体现为在医案的篇章范围内考虑每个短句的标注结果。
3.3 名称性术语的处理
在进行短句分类时,名词性术语既可以被视为一个整体,又可以将其视为字的序列。为了降低语料的稀疏程度,可将同类名词性术语用同一符号代替。本文将对名词性术语的该类操作称为名词性术语的规约(规约操作)。具体如下例所示(例中对方剂、中药类术语进行了规约,并分别用“F”、“Z”替换了语料中出现的方、药名称)。
规约操作前: OT 朝用补中益气加黄柏、知母、麦门、五味,
规约操作后: OT 朝用F加Z、Z、Z、Z,
规约操作的主要作用如下:
(1) 排除名词性术语对短句标注的影响,降低语料的稀疏度。如下例所示。

规约操作前规约操作后再用加味归脾汤加麦冬、五味,再用F加Z、Z,遂用六君加炮姜、肉果,遂用F加Z、Z,
(2) 通过规约操作突出名词性术语对叙述性术语标注的区分性,具体数据见表4。
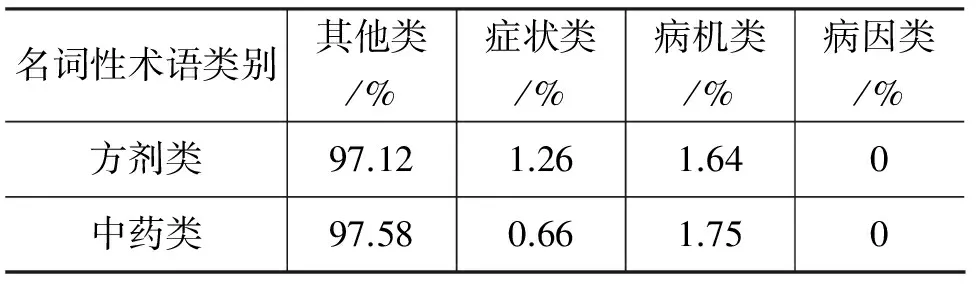
表4 两类名词性术语在各类待标注短句中的出现比例
但是在该操作的具体过程中,难免会存在以下影响:
(1) 规约不彻底带来的混乱
对于每类名词性术语,其对应的术语词典都不能穷尽语料中所有属于该类的术语。这就造成了同类术语的类内部分规约,该现象必将导致对未规约短句识别能力的减弱。其次,在中医语料中还包含了多类通用领域术语,如人名、地名等。要获得全部的类别的术语词典显然很困难。本文把该种情况称为类间部分规约。
(2) 规约操作中的歧义
该情况多出现在较短(1~2字)的术语中。如下例所示。
久服知(中药知母)、柏之类, ||殊不知(清楚、晓得)肾脏风,
若要屏蔽掉对该类词语的规约会造成类内部分规约,如果在规约时进行消歧,不只会增加处理时间,同时消歧结果有待修正。因此本文仅规约了人为挑选出的无歧义术语。
3.4 基于知网的特征扩充
古文中句子短小,同时也缺乏现代文处理中的词法、句法特征。扩展短句特征的可行方法之一就是利用领域词典中对切分单元的解释代替该单元。但是,目前尚无可直接使用、计算的数字化古文词典,而针对中医领域的上述词典更是难以获得。同时,在查词典时,必然要涉及到词义消歧的相关工作,而在缺乏特征情况下的消歧,结果很难保证。
因此,对于词典的缺乏问题,本文利用现代文的面向通用领域的知网[9]来代替本文需要的中医领域古文词典。在知网中,对词的解释以DEF的形式出现,如下例所示。
痈 DEF={disease|疾病}
口DEF={Age|年龄:host={livestock|牲畜}}
DEF={NounUnit|名量:host={physical|物质}}……
本文提出以下假设: DEF越多的切分单元,歧义越严重,该单元词义消歧越困难,而在不计语义的情况下,该单元在语料中出现次数较多,则该单元的数据稀疏程度也较轻。
根据如上假设,本文利用知网替换了语料中DEF唯一的切分单元,即利用切分单元对应的DEF中的词语替换该单元。本文将该操作称为替换操作。而除了DEF唯一的切分单元外,语料中还存在DEF不唯一或知网没有收录的切分单元。具体比例如表5所示。
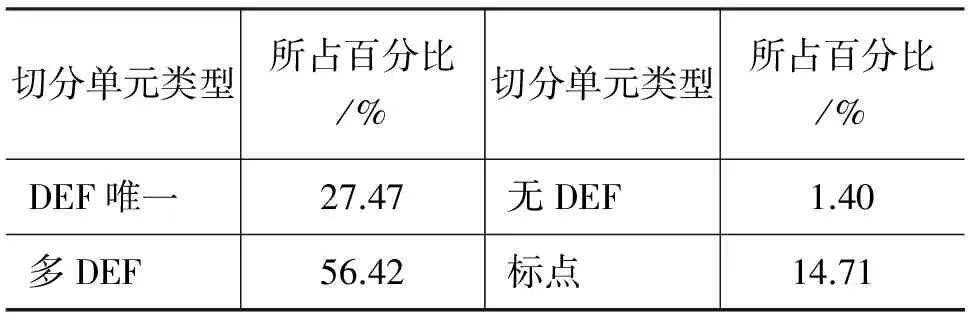
表5 根据对应DEF数量对字切分单元的分类结果
由于标点会对短句标注起重要作用,因此并未对其进行规约。可见利用知网,在语料中可替换的有将近30%的字切分单元。具体过程如下(以字切词为例)。

替换操作的主要作用在于以下几点。
(1) 丰富短句特征。一个切分单元对应的DEF中通常包含多个词语,如此就起到了扩充特征的作用。
(2) 降低稀疏程度。首先,有多个词语对应同一DEF的情况,对该类词语的替换与前文介绍的名词性术语替换的作用相似。同时经过特征选择操作后,可屏蔽掉不同切分单元对应DEF中的某些词语,而使剩下的词语一致,同样可以降低稀疏程度。
由于在替换的过程中,没有词义消歧的相关操作,必然会导致该过程中的如下弊端。
(1) 替换不彻底。如表5所示,除少部分知网未收录的词语外,有尽60%的切分单元有多个DEF,也就不能进行替换操作。
(2) 替换错误。即使仅仅替换DEF唯一的切分单元,也会出现替换错误。该类错误对于单个词是没有影响的,因为一词若被替换则在整个语料范围内都会被替换。但是会引起特征错误的泛化,经过特征选择后,这种错误泛化还将扩大。导致替换错误的主要原因如下。
• 作为面向现代文的针对通用领域的知网,并不包含古文的中医领域解释;
• 对中医术语外的通用领域术语替换不当,如通用术语中的人名、地名等。
4 实验与分析
本文实验中所用的语料出自《名医类案》以及《续名医类案》,共包含519篇医案。本文共设置了三组实验,并利用十则交叉验证的准确率、召回率以及F值来评价实验结果。
实验一: 选择合适的任务转化方法、学习算法以及短句切词方法。
实验二: 选择标注效果最优的特征选择算法。
实验三: 分析规约操作以及替换操作的效果。
4.1 实验一
如上文所述,对于短句的标注任务有两种转化方法。一是将其转换为短句分类问题;二是将其转换为短句序列标注问题。实验一中利用ME、 SVM和CRF分别作为两种转化方式的学习器。同时,如上文所述古文多单字成词,为证明以字为切词单元更符合对古文的处理,本实验对比了二元切词与字切词的实验效果。由于二元切词会导致特征急速上升,因此在字切词的实验中,特征维数由200到 2 000阶梯增长,但是在二元切词时,特征维数由500到5 000阶梯增长。同样由于二元切词后特征数的激增,而CRF对特征维数有严格限制,因此本实验利用SVM、ME对比了两种切词方法,实验结果如图1所示。
分析图1可知,CRF分类器的效果要明显好于其他两种分类器,其主要原因是在短句标注过程中上下文信息起到了重要作用。ME比SVM的效果更优,主要原因是,SVM较擅长于解决二分类问题。结果说明将短句标注问题转化为短句分类或短句序列标注问题都是可行的,不过序列标注模型更适合于短句标注任务。同时图1表明,无论使用SVM还是ME二元切词的标注效果劣于字切词的效果,这也证明了以字为单位处理古文是合理的。
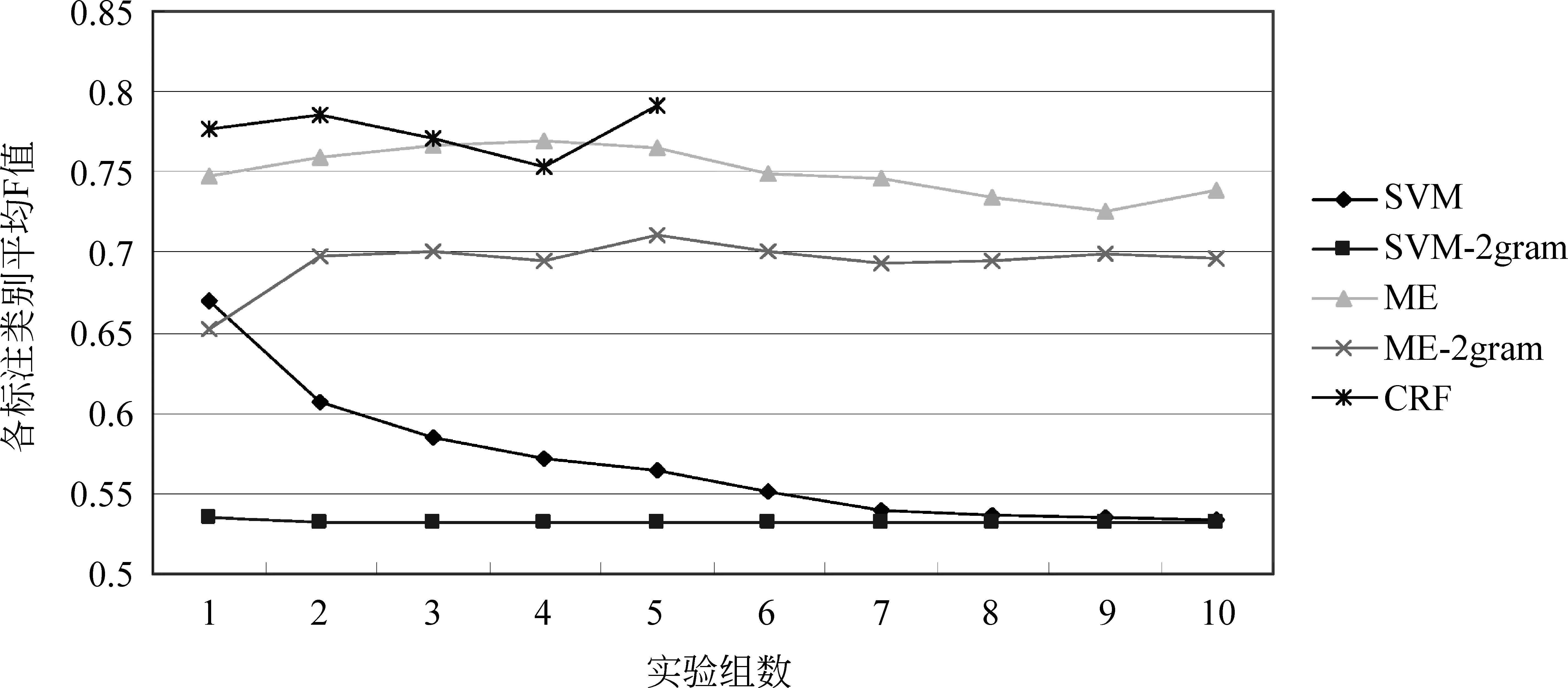
图1 三种模型标注短句的平均F值
4.2 实验二
常用的特征选择算法有DF、IG、MI、CHI、WLLR、BNS[10]。DF易于实现,但权值难以设定,而BNS计算过于复杂。因此本文实现了其余四种方法,采用CRF、字切词方法以及100到1 000的特征维数增长,以对比四种特征选择算法优劣。实验结果如图2所示。
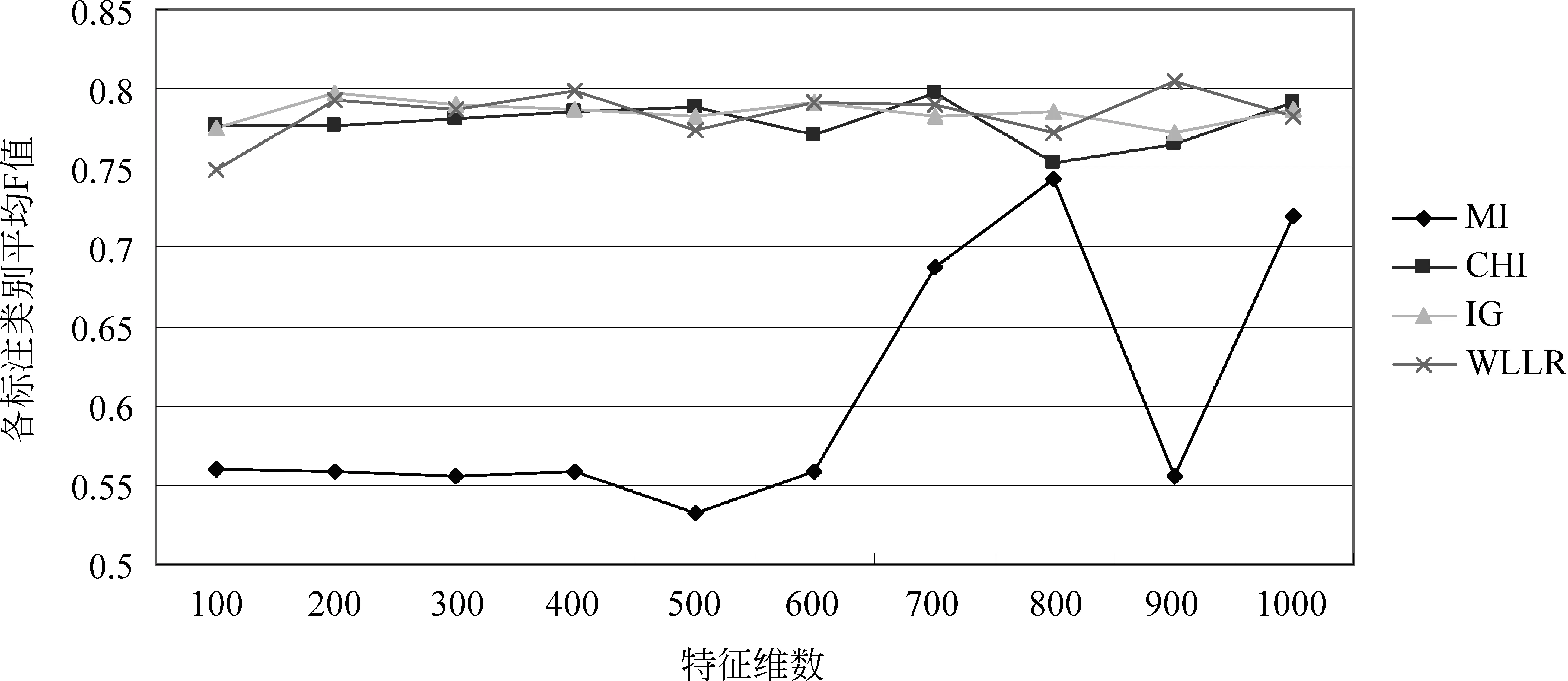
图2 四种特征选择算法标注短句的平均F值
分析图2可知,MI方法的效果较差,其他三种方法的效果非常接近。本文选择了特征为900维时F值达到最高值(80.48%)的WLLR作为实验三的特征选择方法。
4.3 实验三
利用之前实验中得到的最优参数组合,即以字切词方式切分短句,WLLR的特征选择方法,并利用CRF完成本实验。同时为了避免替换操作时,对名词性术语的错误替换,替换操作是建立在规约操作基础上的,实验结果如图3~7所示。
图3说明在特征为600维时,三种方法均取得较好识别效果,表6中为三种方法在该维数对于各类的识别效果。
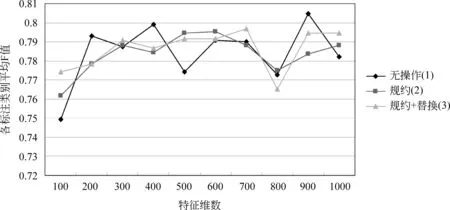
图3 三种标注方法标注各类的平均F值
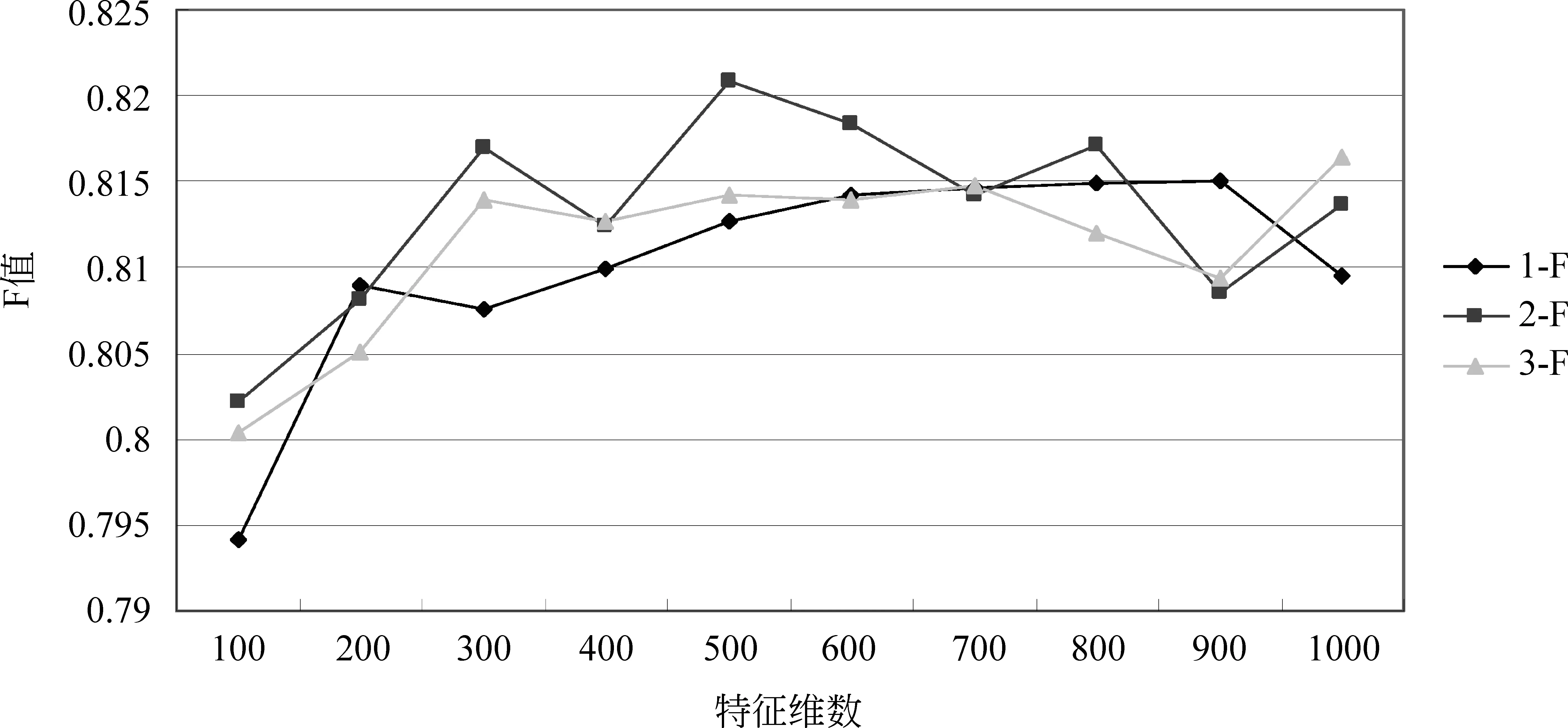
图4 三种标注方法对标注OT类的F值
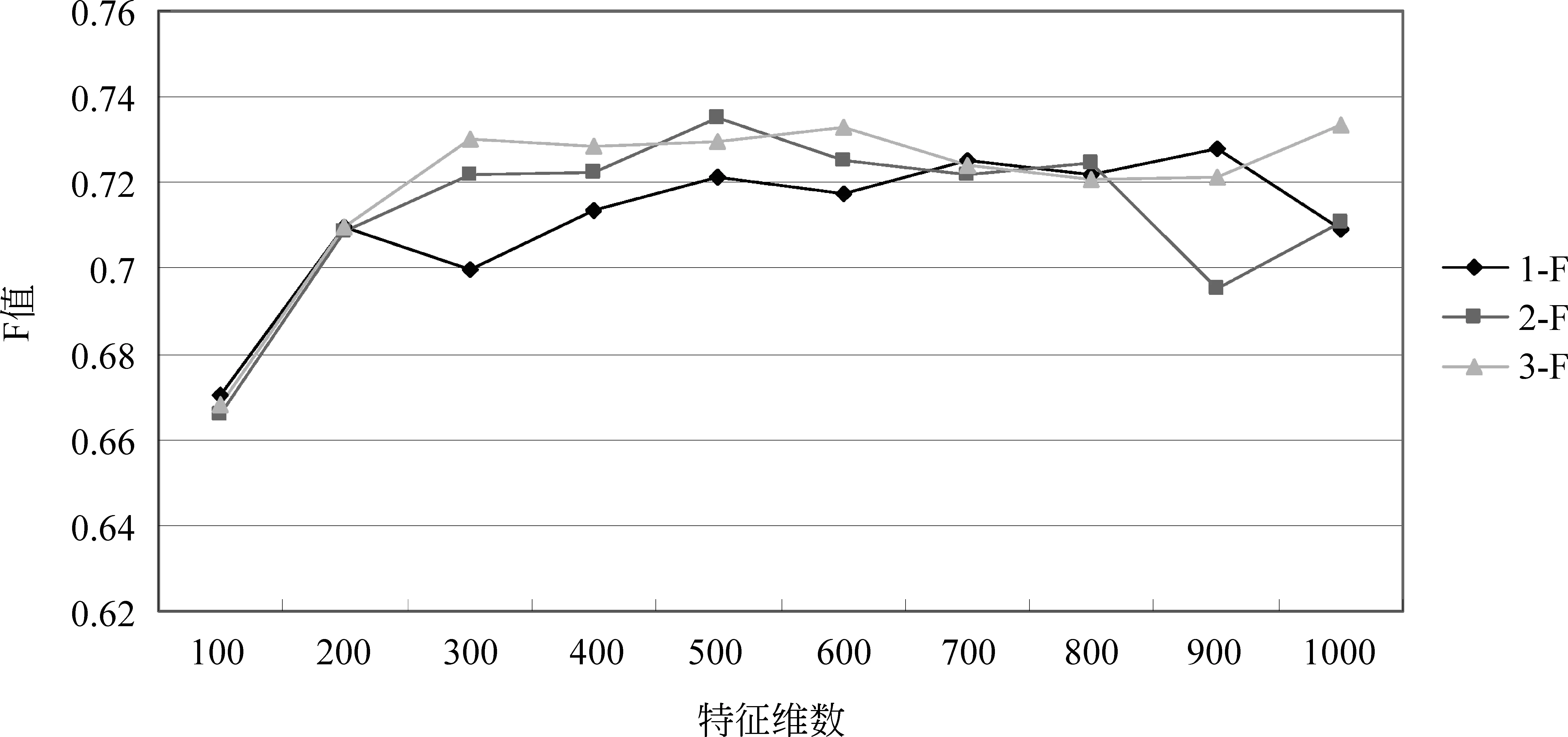
图5 三种标注方法对标注ZZ类的F值
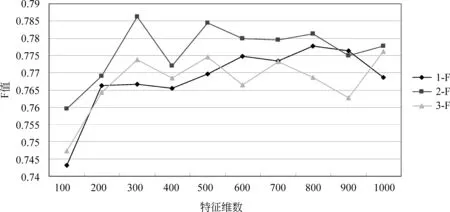
图6 三种标注方法对标注BJ类的F值
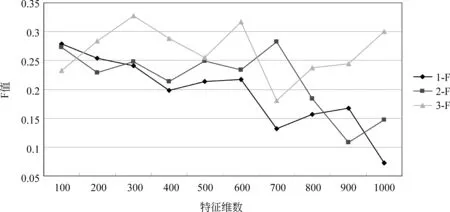
图7 三种标注方法对标注BY类的F值
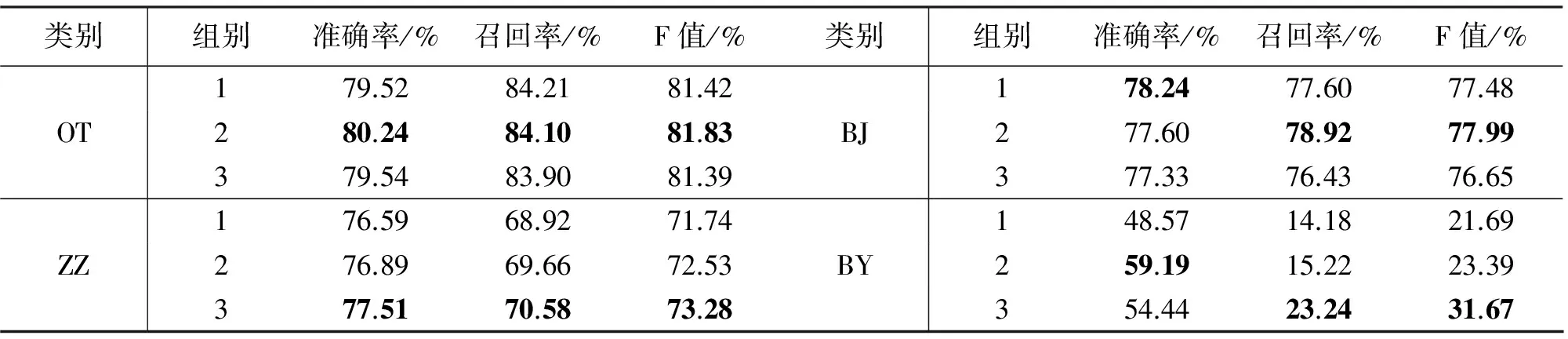
类别组别准确率/%召回率/%F值/%类别组别准确率/%召回率/%F值/%179.5284.2181.42178.2477.6077.48OT280.2484.1081.83BJ277.6078.9277.99379.5483.9081.39377.3376.4376.65176.5968.9271.74148.5714.1821.69ZZ276.8969.6672.53BY259.1915.2223.39377.5170.5873.28354.4423.2431.67
分析实验结果可知,虽然识别的最优效果依然由无预处理操作的第一组获得,但是该组较不稳定。这说明规约操作以及替换操作增强了识别的稳定性。而BY类的识别结果最不理想,该状况主要由于语料偏置,以及上文指出的,BY类较其他类别短句对问题转化的不适应性。
对比规约操作前后(第1、2组)的实验结果可知,除个别特征维数外,规约后四类的F值均有提高。取得该结果的原因是前文介绍的名词性术语在各个待标注类别中的分布差异。可见,规约操作对于短句的识别是有效的。若想进一步提高,必须深入解决上文中规约操作的类内部分规约以及类间部分规约问题。
对比替换操作前后(第2、3组)的实验结果可知,替换操作对ZZ和BY类的短句是有效的,特别对于BY类来说,适当缓解了语料偏置问题。而对于OT和BJ类来说,替换操作后,一些如“肾、肾水”等BJ类的特征词被泛化了,削弱了BJ类的自身特点。造成BJ类和OT类的混淆,从而导致两类的识别效果均有下降。不可否认的是,本文使用的替换操作中的部分替换问题以及替换错误较为严重,但是替换操作带来的特征扩充,对于实例较少的类别是有利的。替换操作完善后,必将进一步提高标注效果。
4.4 错误实例分析
除上文分析的规约、替换操作带来的错误,在整个识别过程中共性错误包括以下几类。
(1) 短句本身特征不明显,或包含过多虚词,致使学习器将其分入实例较多的OT类。例如,“而所患自若也”。
(2) 两个类别间部分内容相近,造成其用词与表达方式较为相近。类似的情况就会造成学习器的错误标注。如描述服药之后状况的句子(OT)与描述疾病症状的句子(ZZ)。
(3) 短句本身缺乏特征,根据上下文信息得出错误标注。此种情况多导致连续的错误。
上述多数错误均与短句本身特征不足有关。统计三组实验均取得较好效果的以600为特征维数的实验结果发现,短句长度与其在语料中所占比例及识别正确比例的关系如表7所示。
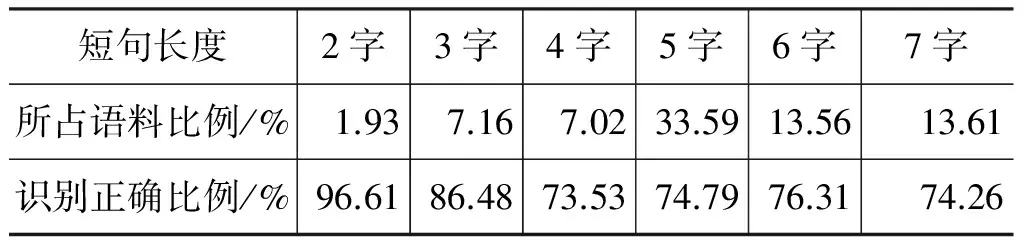
表7 识别正确与错误百分比与短句长度的关系
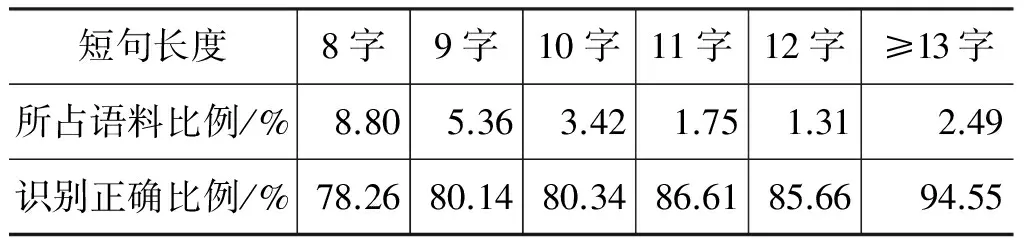
续表
其中,短句长度为2的句子主要包括“曰: ”,以及每篇医案的第一句,特征明显,方便识别。除短句字数为2时,正确识别的短句约占97%,其他其他均在80%左右,甚至更低,并且该类短句在语料中占很大比例。
由短句长度问题带来的识别错误可有两种解决方案: 一是对切分粒度进行改进,使其能够避免标点切分产生的句子碎片;二是寻找更多的特征以支持标注过程。
5 结语
本文通过对中医古籍文献中叙述性术语特点的深入分析,将叙述性术语的标注问题转化为了利用有监督学习方法对短句进行序列标注或分类的问题,并解决了转化过程中出现的问题,同时提出了针对名词性术语的规约操作以及基于知网的替换操作两种预处理方法。通过实验首先证明了上述的问题转化方法的可行性,选择了效果最好的CRF序列标注模型以及适用于古文的字切词方法;其次选择了合适的特征选择方法;最终证明了两种预处理操作的可用性。进一步的研究将集中于该方法在其他叙述类别上的应用,以及规约操作、替换操作的完善,并寻找其他可扩充短句特征,降低稀疏程度的方法。
[1] Popov b, Kiryakov a, Kirilov a, et al. KIM-Semantic Annotation Platform[C]//Proceedings of the 2nd International Semantic Web Conference (ISWC2003). Berlin: Springer, 2003: 484-499.
[2] Uren v s, Cimiano p, Iria j, et al. Semantic Annotation for Knowledge Management: Requirements and a Survey of the State of the Art [J]. Journal of Web Semantics, 2006,4:14-28.
[3] Vargas-vera m, Motta e, Domingue j, et al. MnM: A Tool for Automatic Support on Semantic Markup, KMI Technical Report, TR Number133, 2003.
[4] Huang rh, Riloff e. Inducing Domain-specific Semantic Class Taggers from (Almost) Nothing[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL 2010), USA: Association for Computational Linguistics, 2010: 275-285.
[5] 麦乔智.数据挖掘模型的创建及其在中医药文献中的应用研究[D]南京:南京中医药大学,2009.
[6] 范岩.基于条件随机场模型的中医文献知识发现方法研究[D]北京:北京交通大学,2009.
[7] Nadeau d, Sekine s. A Survey of Name Entity Recognition and Classification [J]. Lingvisticae Investigationes, 2003, 30: 1-20.
[8] Zhao j, Liu k, Wang g. Adding Redundant Features for CRFs-based Sentence Sentiment Classification[C]//Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. Honolulu, USA: Association for Computational Linguistics, 2008: 117-126.
[9] 董振东, 董强, 郝长伶. 知网的理论发现[J]. 中文信息学报, 2007,21(4): 4-9.
[10] Li s, Xia r, Zong cq, et al. A Framework of Feature Selection Methods for Text Categorization[C]//Proceedings of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP. Singapore: ACL and AFNLP, 2009: 692-700.

丁长林(1987—),硕士研究生,主要研究领域为信息检索。E⁃mail:dcl19871208@126.com白宇(1982—),博士研究生,讲师,主要研究领域为信息检索。E⁃mail:baiyu@sau.edu.cn蔡东风(1958—),博士,教授,主要研究领域为自然语言处理,人工智能。E⁃mail:caidf@vip.163.com
第四届全国社会媒体处理大会(SMP2015)
第四届全国社会媒体处理大会(SMP2015)由中国中文信息学会社会媒体处理专委会主办,华南理工大学软件学院和华南理工大学南校区大学城管委会承办。该系列会议每年举办一次,现已成为社会媒体处理的重要学术活动。社会媒体处理大会专注于以社会媒体处理为主题的科学研究与工程开发,为传播社会媒体处理最新的学术研究与技术展示提供广泛的交流平台,旨在构建社会媒体处理领域的产学研生态圈,成为中国乃至世界社会媒体处理的风向标,会议将以社交网络的形式颠覆传统的学术会议交流体验。
SMP 2015征集各类与社会媒体相关方面的原创研究和应用论文。论文包括但不限于以下内容:
• 面向社会媒体的自然语言处理
• 社会网络分析与复杂系统
• 社会媒体处理与社会科学
• 社会媒体挖掘、预测与推荐
• 社会多媒体分析与可视化
• 社会媒体舆情分析与精准营销
• 社会媒体安全、隐私保护与计算支撑平台
• 社会化媒体营销与整合品牌传播
• 大数据营销与品牌的网络形象研究
重要日期:
投稿截止日期:2015年6月30日
录用通知日期:2015年8月10日
会议召开日期:2015年11月16-17日
投稿要求:
1. SMP 2015同时接受中文和英文投稿。
2. 论文必须没有公开发表过,字数要求在8页内,内容充实的论文要求最多不超过12页。
3. 论文盲审,提交的时候不用带作者信息,录用后再补充。
4. 英文格式要求参照Springer的论文模板;中文格式要求参照《中文信息学报》:
http://www.cipsc.org.cn/jsip/tougao.php。
5. 投稿系统将在4月20日开通。
论文出版:
录用的稿件分为两类:口头报告(Oral)和海报张贴(Poster)。被录用的英文文章拟由Springer结集出版(EI检索),被录用的中文稿件将被推荐至《中国科学》和《中文信息学报》,经《中国科学》和《中文信息学报》编辑部再审通过后发表。优秀英文文章将被推荐至IEEE Transactions on Big Data,经该期刊编辑部再审通过后发表。
Supervised Learning Based Semantic Annotation of Descriptive Terms in Chinese Medical Literatures
DING Changlin, BAI Yu, CAI Dongfeng
(Research Center for Knowledge Engineering, Shenyang Aerospace University, Shenyang, Liaoning 110136, China)
The semantic annotation is a promising solution to process the free texts of Ancient Chinese Medical Literature (ACML). Terms in such textx are further divided into Named Terms (NTs) and Descriptive Terms (DTs) in this paper. By analyzing the DT, this paper treat the annotating DTs as the problem of sequence labeling or classifying short sentences based on supervised learning. Two pre-processing methods named NT reduction and Hownet-based substitution are proposed. The experiments compare three learning models and four feature selecting methods, demonstrating the feasibility the proposed method.
semantic annotation; descriptive terms; supervised learning; ancient Chinese medical literatures
1003-0077(2015)02-0049-09
2012-09-27 定稿日期: 2013-01-15
国家基础科研973计划(2010CB530401)
TP391
A
猜你喜欢
十几岁(2022年34期)2022-12-06
国学(2021年0期)2022-01-18
北方民族大学学报(2021年5期)2021-11-27
装备制造技术(2020年4期)2020-12-25
学生天地(2020年6期)2020-08-25
娃娃画报(2019年8期)2019-08-05
娃娃画报(2019年8期)2019-08-05
北京航空航天大学学报(2018年10期)2018-10-30
汉字汉语研究(2018年1期)2018-05-26
中国惯性技术学报(2017年5期)2017-12-02
