
异构环境下MapRuduce任务调度算法优化
2015-04-21 02:38魏巍刘钊远
微型电脑应用 2015年6期
魏巍,刘钊远
异构环境下MapRuduce任务调度算法优化
魏巍,刘钊远
Hadoop作为世界领先的大数据平台,其性能更多地依赖于MapReduce任务调度机制。通过对MapReduce任务调度机制中推测算法的研究,提出一种高效、准确和基于优先级的改进Hadoop调度算法。通过测试发现,改进后的Hadoop调度算法在异构环境下能够对落后任务判定准确,更好地维持系统的负载平衡,减少系统对任务的响应时间,增加对高优先级任务的响应速度,提高MapReduce任务调度算法的性能。
异构环境;推测算法;负载均衡;优先级
0 引言
近些年来,在大数据背景下,ApacheHadoop已经逐渐成为研究的热点,业界对于开源Hadoop的应用也在不断的加深。Google、IBM、Microsoft、Amazon、Yahoo、Alibaba等IT互联网公司都推出了自己的云计算服务平台,并把云计算作为未来重要的战略目标[1-2]。大多数的开源云计算系统都是基于Hadoop应用平台,尤其在应用研究领域发展更为广泛。Hadoop应用框架最核心的设计是HDFS[3](分布式文件系统)和MapReduce,HDFS负责海量数据的存储,而MapReduce负责海量数据的计算。
MapReduce的优势之一在于容错机制对于用户透明化,并不需要用户去参与实现。当一个节点出现崩溃时,其上的任务被分配给其它的节点继续运行。类似情况,如果一个任务在一个节点上被执行的时间过长,则这个任务被称作掉队者任务或后备任务。把这个掉队者任务放在另外一个节点去执行,以便快速完成,这个过程称之为推测执行[4]。Hadoop现有的调度算法对于推测执行这一部分并不是很完善,主要体现在对后备任务的判定上。目前常用的调度算法有Hadoop默认的调度算法FIFO(先进先出),这种算法并不能体现出作业的优先级和推测任务的执行;Facebook提出的Fair Schedule(公平调度),对于权值高的任务多分配资源,并且支持抢占,如果作业数过多,可能会频繁的进行上下文切换,增加后备任务的执行时间;Yahoo公司提出的Capacity Schedule(计算能力调度),虽然不支持抢占,但是通过设定一些阈值来判定后备任务,这在异构集群中误差较大。针对以上Hadoop调度算法不足的基础上,提出一种基于优先级的改进Hadoop调度算法,并同其它的调度算法进行比较研究。
1 现有MapReduce任务调度算法
在Hadoop集群中,当一个空闲Slave节点请求分配任务时,有三种任务类别会被调度器所调度[5]。(1)处于等待状态还没有被执行的任务,若是本地任务,则会优先选择。(2)执行失败的任务,优先级高的先被执行。(3)需要推测执行的掉队者任务。为了挑选和执行掉队者任务,Hadoop平台上使用的是推测式执行算法。
Hadoop对于集群中作业的处理主要分为Map和Reduce两个过程,如图1所示:
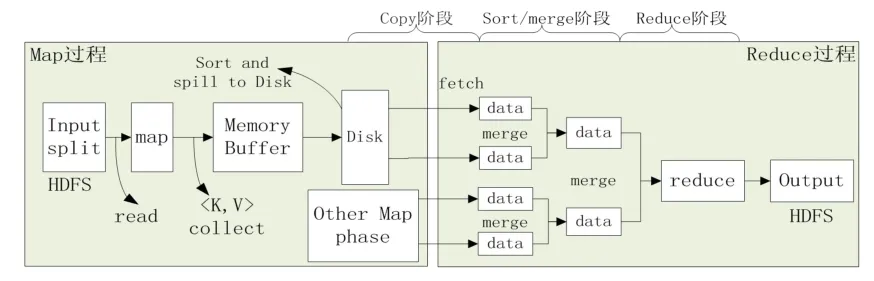
图1 Map/Reduce task运行过程
Map Task过程,存储在HDFS上的Input split经过用户自定义map函数处理,得到一个个键值对[6]。这些键值对被收集后存放在环形内存缓冲区中,当缓冲区满后,数据经过排序,由MapReduce将其写入本地磁盘,生成一个临时文件,并在必要时对数据进行合并和压缩操作。Reduce Task过程,数据的处理被分成3个阶段:复制、排序和归并。复制阶段,从磁盘中得到所有map的输出结果;排序阶段,将map的输出结果按某种规则进行排序;归并阶段,将排序后的数据按照用户自定义的reduce函数处理。
Hadoop使用0到1之间进度分数来表示任务的完成情况。在Map阶段,进度分数等于已经完成的任务量与输入的总任务量的比值。在Reduce阶段,复制、排序和归并3个小阶段各占整个Reduce任务执行时间的1/3,在每个小阶段,进度分数表示已经处理的数据量与输入的总的数据量的比值。例如,设完成Reduce阶段总的任务进度1,当一个任务完成了复制阶段的一半,则任务的进度分数为,当一个任务完成了排序阶段的一半,则任务的进度分数为。
在MapReduce任务调度算法中,用任务的运行时间、任务的平均进度和当前进度来预测掉队者任务,即当活跃任务的数量大于1,任务的平均进度分数减去当前进度分数的值大于或等于0.2,且任务的运行时间超过一分钟时,则该任务被视为掉队者。这种推测算法是基于以下假设:(1)每一个节点都是按照同样的速度处理任务;(2)在整个运行过程中,每个任务按照同样的速率运行;(3)运行后备任务不消耗系统额外资源;(4)Map阶段,用任务的进度分数表示任务的完成情况,Reduce阶段,任务的排序、复制、归并3个小阶段分别占总任务量的1/3。集群的异构性使得以上的假设失效。
集群中的节点由于配置不同,处理性能不同,总是存在着差异,这些差异影响了Hadoop调度器的性能。在MapReduce任务调度算法中,推测任务的判定和执行都是通过任务的进度值确定的,但是在异构环境中由于节点的差异性,用任务的平均进度分数减去0.2来判断推测任务显的不足。很多任务的进度都低于这个阈值。例如:假设异构集群中有A、B、C3个节点,A节点硬件配置最高,性能很好,B节点硬件配置中等,性能一般,C节点硬件配置最差,性能最低。当给这个集群中每个节点分配相同任务,一段时间后,A节点的进度为0.9,B节点的进度为0.5,任务的平均进度为(0.9+0.5)/2=0.7。此时,Hadoop默认B节点为慢节点,则会调度空闲节点C启动推测任务,由于节点C性能较低,这个后备任务完成时间肯定不会在节点B完成任务之前完成,因此,这个后备任务就没有什么意义。
综上所述,执行后备任务的推测算法可能在同构环境下比较适用,但是在异构环境下,调度程序常可能选择不到正确的后备任务,造成了过多的后备任务执行,占用了系统大量的资源,影响了系统对任务的响应时间。
2 同构环境下的任务推测算法
Hadoop默认的推测执行调度策略中设置一些阈值来判定一个任务是否是后备任务。比如,设置SPECULATIVE_LAP=60*1000,表示后备任务的运行时间阈值;SPECULATIVE_GAP=0.2,表示后备任务的进度分数阈值等等。这些阈值的设置在异构环境下并不准确。当一个任务请求执行时,JobTracker会根据空闲节点的心跳请求分配TaskTracker执行任务。如果这些任务在被处理过程中满足以上阈值,则会被视为掉队者任务,其后备任务将被执行。后备任务如果被分配到到性能较差的节点上执行,会再次满足以上阈值,产生第二个后备任务,造成了系统资源的浪费。由于调度算法不能根据系统的负载量动态的调整提交的task数量,这样就产生了任务间相互竞争系统资源现象,又由于节点的处理能力不同,产生的后备任也加入了与已经提交的新任务产生竞争。最终,导致系统负载量过大,不足以快速地完成任务。为了使后备任务的推测执行更加准确。可以从两个方面加以改进,第一是正确判定后备任务;第二是选取性能较好的节点执行后备任务。
2.1 任务执行剩余时间预测算法
对于Hadoop默认调度策略对后备任务判定不足的基础上,提出一种新的判定方法,即把运行时间最久的task作为后备任务[7]。因此,要判定后备任务,就必须知道任务完成的剩余时间。设Pa表示任务执行的平均速率,T_left表示任务运行的剩余时间。Pr表示任务的进度分数,t表示已运行的时间,则Pa=Pr/t,任务执行的剩余进度为1–Pr。用平均速率计算任务完成的剩余时间[8],如公式(1):
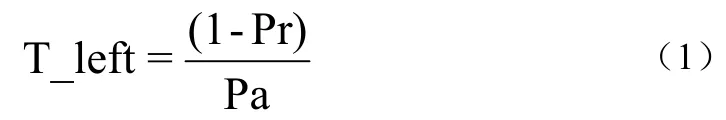
用任务运行开始到当前时间的平均值来预测任务的剩余完成时间,充分考虑到集群的异构性,任务提交的顺序不同运行时间也不同,不会产生后提交的任务产生新的后备任务情况。
2.2 快慢节点判定算法
产生的后备任务如果运行的速度比原任务慢,则后备任务失去了意义。需要选择一个性能良好的节点来运行后备任务。选择节点的基本策略是给请求执行任务的节点按照某一个阈值分为快节点和慢节点。阈值设定为节点平均进度的25%[8]。考虑到集群的异构性,节点的平均进度是由整个系统所有节点上的所有任务的进度分数决定,这样就能较为准确的判定节点的处理能力和计算性能,达到了准确地判断快慢节点的目的。设节点的数量为n,每个节点处理的任务量(已完成和正在完成的task)为m,判断快慢节点的阈值为SNT。则有公式(2):
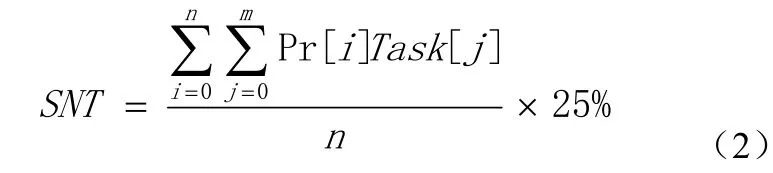
其中Task[j]表示节点上的第j个任务。Hadoop集群可用的系统资源有限,处理后备任务的能力受到制约。因此,需要计算系统当前能够承载后备任务的最大值[9](spectask)。考虑到集群的异构性,可以用在开始到某时刻系统处理Map和Reduce任务个数总和减去系统处理任务个数的平均值来计算spectask。其计算过程为:设某时刻T,系统正在处理的Map和Reduce任务总数为S1,则有公式(3):
S1=NmapTask[T]+NreduceTask[T](3)设系统从开始时刻到当前时刻(T)所处理任务的平均值为S2,则有公式(4):
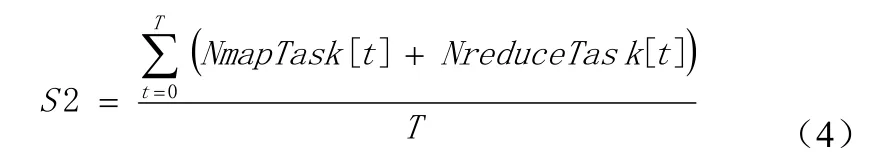
有公式(3)和公式(4)得到公式(5):
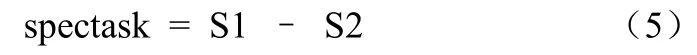
其中NmapTask[T],NreduceTask[T]分别表示T时刻Map和Reduce阶段所执行的任务的数量。
3 后备任务推测算法改进
在改进的后备任务调度算法中需要定义两个队列,一个是存放快节点信息的队列(QueueForNode),另一个是存放按剩余完成时间排序的task队列(QueueForTask)。提交给Hadoop集群的任务运行一分钟后,开始选择后备任务的运行。改进推测算法中后备任务的选择如图2所示:
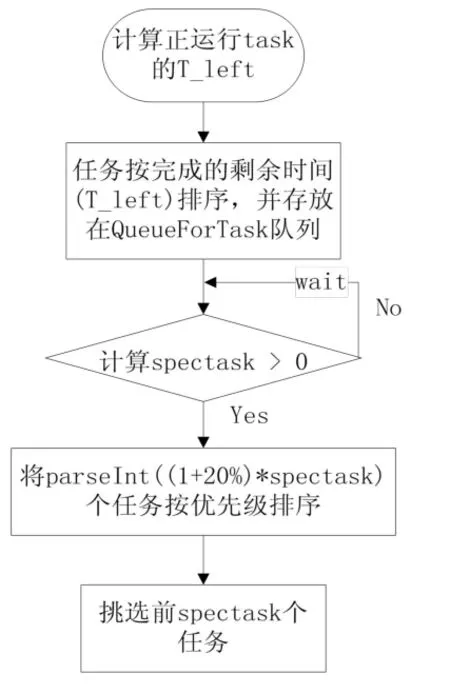
图2 后备任务的选择流程图
后备任务选择开始时,由式1计算系统所有正在运行任务的剩余时间,按照剩余完成时间的大小进行排序并把task存放在QueueForTask队列中。按照式5计算集群中能够处理的最大备份任务数量,若spectask大于0,将前parseInt((1+20%)*spectask)个任务按所属Job的优先级排序。parseInt(变量)函数表示不大于变量的最大整数,按优先级排序是为了使优先级高的后备任务可以先得到执行。排完序后,取前spectask个任务等待执行。
为了使备份任务得到较快执行,选取性能良好的快节点很关键。选取快节点执行流程如图3所示:
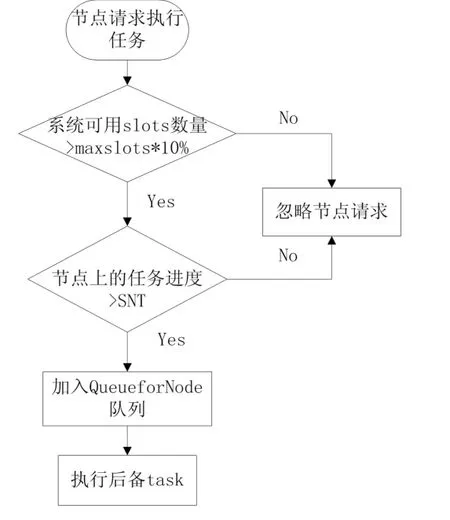
图3 快节点选择执行流程图
当JobTracker收到TaskTracker心跳请求时,为了确保系统预留足够可用资源,检查系统中可用的slots(槽)数量是否大于slots总数的百分之十。若不满足条件,忽略节点请求,否则判断节点的任务进度是否大于阈值(SNT),若不大于,忽略节点请求,否则将节点信息加入到快节点请求队列(QueueForNode)。将QueueForTask队列中前Min(QueueForTask.size,spectask)个 任 务 分 配 给QueueForNode前面的节点执行,QueueForTask.size表示队列中任务的数量,并更新QueueForTask队列和QueueForNode队列的信息。
4 实验设计及结果分析
为了实验方便和计算简单,采用Hadoop源码包中自带的单词统计实例来测试改进MapReduce任务调度算法的性能。实验原理为:用户上传到HDFS的文档,经过map和reduce过程,统计输出结果,计算任务的完成时间,并和原有的任务调度算法进行对比。
(1)实验一由于实验条件限制,Hadoop集群由三台异构普通PC组成,其组成如表1所示:
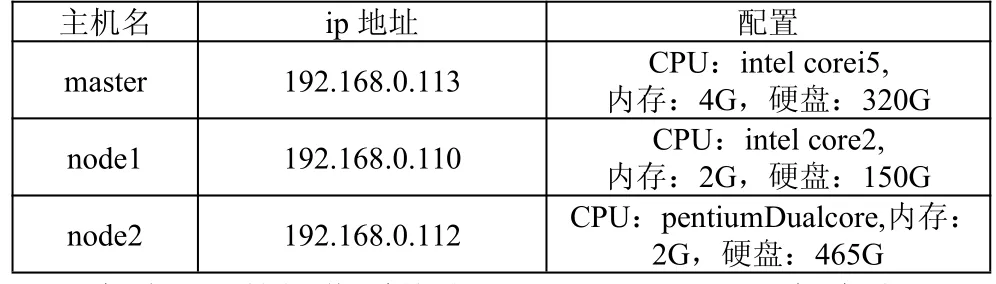
表1 集群配置
每台PC的操作系统为ubuntu14.04,java版本为JDK 1.7.0_65,Hadoop平台为Hadoop 1.0.0。在此次实验中,用户同时提交三个job,每个job的大小为300M,集群中设定的物理块(block)块大小为64M,因此每个job被分成5个Map子任务。三个job分别在无推测执行,Hadoop自带的推测算法(以Capacity Schedule为例)和改进Hadoop推测算法三种情况下处理,结果如图4所示:
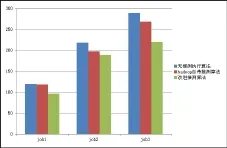
图4 异构环境下推测算法性能比较
由图4分析,异构环境中,在处理相同任务量的情况下,无推测算法相比推测算法,作业的完成的时间长;改进的推测算法比Hadoop自带的推测算法完成时间短,且随着job数量的增加变的明显。这是因为当任务量过多时,后提交的任务执行的时间较长,产生推测任务,改进的推测算法通过预测推测任务的剩余完成时间,动态的分配系统资源,使推测任务得到快速的执行,提高了系统处理作业的性能。
(2)实验二先后向Hadoop集群中提交4个job,每个job的大小是300M。同时设置第三次提交的作业(job3)的优先级为HIGH,其余job的优先级是NORMAL,在改进的推测算法下,处理任务的情况,如图5所示:
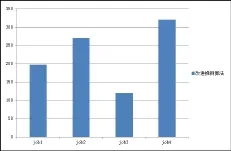
图5 不同优先级job完成时间比较
由图5分析,job3作业的完成时间最短,job1、job2、job4作业完成时间依次增加。因为job3的优先级大于其它job的优先级,在改进推测算法中,优先级高的任务优先获得系统资源,优先被执行;优先级低的job按提交的先后顺序依次被执行。综上所述,改进的推测算法能够较好地处理优先级较高的作业。
5 总结
针对Hadoop自带的推测算法对于后备任务判定的不足,提出了更具公平性的改进Hadoop推测算法。算法通过预测提交给集群中所有任务的剩余完成时间,结合作业的优先级,找到优先级较高,可能运行时间较长的任务,并视为推测任务。同时,对于异构集群中所有节点处理能力的不同,把节点分为快慢节点,并调用快节点处理推测任务,保证了推测任务得到较快的处理。实验表明,改进Hadoop推测算法相比原有的推测算法,缩短了任务完成时间,更好地维持系统的负载平衡,提高了系统处理作业的能力。
[1]VAQUEROLM,RODEO Merinol,CACERES J,et al.A break in the cloud:Toward a Cloud Definition[J].ACM SIGCOMM Computer Commutitication Review,2009,39(1):50-55.
[2]GUNARAYHNE T and WUTL,QIU,etal.MapReduce in the clouds for sicence:2th IEEE Internation conference on cloud computing Technology and science[C].New York:IEEE Scocienty,2010:565-572.
[3]Tom White.Hadoop权威指南[M].北京:清华大学出版社,2011:75-84.
[4]董西成.Hadoop技术内幕[M].北京:机械工业出版社,2013.5:152-156.
[5]梁建武,周扬.一种异构环境下的Hadoop调度算法[J].中国科技论文.2012,7(7):495-500.
[6]刘鹏.实 战Hadoop[M].北京:电 子 工业出 版社,2011:60-62.
[7]MateiZaharia,Andy Konwinski,Anthony D Joseph. Improving MapReduce Performancein Heterogeneous Environments[C].8thUSENIX Symposium on Operating System Design and Implementation,2009:29-42.
[8]余影,吴斌.基于Hadoop的大规模数据交换的研究[D].北京:北京邮电大学,2011.
[9]何文峰,王多强.基于任务特征和公平策略的Hadoop作业调度算法研究[D].武汉:华中科技大学,2013:40-50.
AMapRuducetask Scheduling Mechanism in Heterogeneous Environment
Wei Wei,Liu Zhaoyuan
(School of Computer Science and Technology,Xi’an University of Posts and Telecommunications,Xi’an710061,China)
As the world's leading data platform,Hadoop’s performance deeply depends on the MapReduce scheduling mechanism. In this paper,through a speculative algorithm research on MapReduce scheduling mechanism,an efficient,accurate and priority-based advanced Hadoop scheduling mechanism algorithm is proposed.This algorithm can make exactly judgment to backward task in heterogeneous environment by testing.It maintains the balance of the system load better and reduces the system response time to the tasks.The algorithm also improves the response speed to the tasks of high priority and the performance of MapReduce scheduling mechanism.
Heterogeneous Environment;Speculative Algorithm;Load Balancing;Priority
TP338
A
1007-757X(2015)06-0055-04
2014.12.31)
魏 巍(1988-),男,汉族,河南信阳,西安邮电大学,硕士研究生,研究方向:计算机应用技术,西安,710061
刘钊远(1963-),男,汉族,陕西铜川,西安邮电大学,教授,研究方向:嵌入式系统应用研究,西安,710061
猜你喜欢
小学教学研究(2022年5期)2022-04-28
汽车工程师(2021年12期)2022-01-17
现代畜牧科技(2021年4期)2021-07-21
冰雪运动(2020年2期)2020-08-24
制造技术与机床(2019年4期)2019-04-04
冰雪运动(2018年6期)2018-05-23
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
现代防御技术(2016年1期)2016-06-01
通信电源技术(2016年6期)2016-04-20
