
基于多层grams的在线支持向量机的中文垃圾邮件过滤
2015-04-25 09:56沈元辅沈跃伍
中文信息学报 2015年1期
沈元辅,沈跃伍
(1. 哈尔滨理工大学 图书馆,黑龙江 哈尔滨 150080;2. 哈尔滨理工大学 计算机科学与技术学院,黑龙江 哈尔滨 150080)
基于多层grams的在线支持向量机的中文垃圾邮件过滤
沈元辅1,沈跃伍2
(1. 哈尔滨理工大学 图书馆,黑龙江 哈尔滨 150080;2. 哈尔滨理工大学 计算机科学与技术学院,黑龙江 哈尔滨 150080)
该文提出一种多层grams特征抽取方法来提升基于在线支持向量模型的垃圾邮件过滤器。基于在线支持向量机模型的垃圾邮件过滤器在大规模垃圾邮件数据集已取得了很好的过滤效果,但与逻辑回归模型相比,计算性能的耗时是巨大的,很难被工业界所运用。该文提出的多层grams特征抽取方法能够有效减少特征数,抽取更精准有效的特征,大幅降低模型的运行时间,同时提升过滤器的过滤效果。实验表明,该方法使得在线支持向量机模型的运行时间从10337s减少到3784s,同时模型(1-ROCA)%降低了一半。
特征抽取;支持向量机;垃圾邮件过滤。
1 引言
近年来,垃圾邮件给电子邮件行业带来了很多问题,给人们生活造成了影响,个人和公司由于接收垃圾邮件和区分垃圾邮件而占用大量网络资源和时间。同时垃圾邮件也是一个有利可图的商业模式,因为垃圾邮件发送者只需要付出很小的代价就能得到丰厚的回报。由于垃圾邮件导致了经济上的损失,有些国家制定相关法律来制裁垃圾邮件发送者。然而,由于技术上的限制,无法跟踪某些垃圾邮件的来源(如国家或某个地点),从而无法对垃圾邮件发送者进行法律制裁。
很多研究人员提出了多种解决垃圾邮件的方法。较早的技术是基于黑白名单的过滤技术[1]。该方法实现简单,运行速度快,但准确率较低。随着垃圾邮件发送技术的发展,垃圾邮件的特性大部分体现在邮件的内容上,所以垃圾邮件发送者发送的邮件很容易躲避基于黑白名单过滤技术的检测。为了解决此类问题,研究人员通过分析邮件的内容和附件来判别垃圾邮件。例如,建立一个垃圾邮件词库,将邮件内容与库中词进行匹配,若匹配成功,判断为垃圾邮件。我们将这种技术称为基于规则或匹配的垃圾邮件过滤技术。该技术针对性很强,词库也便于更改。但随着电子邮件的发展,垃圾邮件的数量非常庞大,规则库或词库也将变得非常庞大,从而导致系统匹配速度变慢[2]。
为了更好地解决基于内容的邮件过滤问题,基于机器学习理论的垃圾邮件过滤技术成为当前最常用的方法。该方法针对邮件内容进行过滤,从邮件的内容获取特征,并通过这些特征以及对应的标注来训练和优化过滤器。该方法准确率高、成本较低,已成为当前解决垃圾邮件过滤问题普遍采用的方法[3]。
基于内容的垃圾邮件过滤是一个机器学习过程,机器学习技术通常分为生成模型(如朴素贝叶斯模型)和判别模型(如支持向量机模型、逻辑回归模型)。Goodman and Hulten[4]在PU-1数据集上测试发现,判别模型的效果要好于生成模型。通过TREC和CEAS会议的垃圾邮件评测竞赛发现,取得最好效果的模型都是采用判别模型[5-7]。在2007年TREC垃圾邮件评测中取得最好的成绩是采用在线支持向量模型(online SVM)[7]。然而,在线支持向量模型消耗时间与样本数量成平方关系,即时间复杂度为O(n2),逻辑回归模型和朴素贝叶斯模型时间复杂度仅为O(n)。在2007年Sculley and Watchman[8]提出了松弛在线向量机(Relaxed Online SVM,简称ROSVM)算法,大幅的降低了online SVM模型的运行时间。尽管ROSVM模型的运行时间被大幅降低,但与逻辑回归模型相比,消耗时间仍然是巨大的。例如,ROSVM运行完TREC06p数据需要18 541s,而逻辑回归模型仅需238s,运行效率是ROSVM的78倍。
本文我们提出多层grams特征抽取方法来提升在线支持向量模型。目前,常用的特征抽取方法是基于词和基于n-grams的特征抽取方法。实验发现基于n-grams的特征抽取方法效果更好,但该方法抽取特征数据较多,例如,一封邮件的字符串长度为3 000个字符,则抽取的特征接近3 000。大量特征数目是导致模型分类器高耗时的关键因素。因此本文提出了多层grams特征抽取方法提升在线支持向量机模型。实验结果表明,该方法不仅能大幅降低系统的运行时间,同时还大幅提升过滤器的过滤效果。
本文第2节介绍在线支持向量机;第3节介绍本文提出的多层grams特征抽取方法;第4节是本文实验和数据分析部分;第5节为结论。
2 在线支持向量机分类器
2.1 支持向量机

f(x)=w·x+b
(1)
其中w表示超平面向量,b是偏移项,x是邮件的特征向量。当f(x)=0时,w为超平面,距超平面最近两个不同样本符合f(x)=±1。因此距超平面最近的两个不同类型的样本的距离为1/‖w‖2。所以最大间隔的优化问题如式(2)所示。

subject_to:yi(w·xi+b)≥1-ξi,∀i,ξi≥0
(2)
其中,xi表示第i个训练样本,yi表示此样本的所属类型。
然而并不是所有的样本都是线性可分的,即不能找到线性超平面,当训练样本不是线性可分的情况,我们引入松弛变量ξi。当最大分类间隔变大时,最少错分样本个数会增加,当最小错分个数减少时,最大分类间隔变小。最大分类间隔和最少错分个数之间是矛盾的,所以引入平衡参数C,调节两者之间的个数。优化形式如式(3)所示。

subject_to:yi(w·xi+b)≥1-ξi,∀i,ξi≥0
(3)
其中,ξi是松弛变量,C是平衡因子。参数C的选择很重要,它决定了过滤器的分类性能和消耗的时间。
2.2 在线支持向量机
通常,SVM采用批量学习(batch learning)的方式进行训练,批量学习就是事先使用一部分训练数据对SVM进行训练,之后再采用另一部分数据作为测试集对训练好的模型进行测试。在测试的过程中模型不再进行学习。
由于垃圾邮件过滤通常采用在线的方式进行,训练数据随着时间源源不断的到来,当模型遇到新的训练邮件后,必须将该训练邮件加入训练数据集,重新对模型进行学习。
对于一封新的邮件,过滤器首先对邮件进行分类,分类后等待用户给予的反馈,即用户会告诉过滤器这封邮件是垃圾邮件还是正常邮件,过滤器获得用户的反馈后,根据反馈结果调整模型的参数。由于不停地有新邮件添加到训练集中,一个加快训练速度的简单方法是,每次训练时候,都以前一次训练得到的参数作为本次训练的初始参数。
本文的在线支持向量机分类器使用Platt的SMO算法作为求解器[9],因为SMO方法对线性支持向量机来说是最快的方法。
在线学习算法的训练样本是源源不断的到来的,随着时间的推移,训练样本集合会达到很大的规模,当训练规模很大时,在线支持向量机模型的训练速度就会急剧下降,从而导致模型不可用。因此,应该采取相应的算法提升模型的训练速度,使用三个简化措施。
1) 减少训练集合大小
在线支持向量机训练时,将训练之前出现的所有邮件。邮件数量很大时,训练时间将是非常昂贵的。本文提出只训练最新的n封邮件,减少过滤器训练时间,同时,新的邮件训练时并不需要训练之前的数据。每次训练完之后保存当前的权重向量,下次训练时只需要在此向量进行训练。
2) 减少训练的次数
根据KKT(Karush-Kuhn-Tucker)条件,当yif(xi)>1时,xi被认为是一个很容易正确分类的样本。所以当样本xi满足yif(xi)≤1时,该样本需要重新训练。现在我们放宽条件来降低重复训练的更新数量,当样本满足yif(xi)≤M,(0≤M≤1)时,该样本进行重新训练。这样就降低了训练样本的次数。
3) 减少迭代次数
减少学习过程的迭代次数。SVM模型中最优分类面通过多次迭代获得,迭代次数的多少直接影响到模型的运行速度,如果次数过大,模型训练将很慢。然而在垃圾邮件过滤中,该模型并不需要过多的训练。所以,通过降低SVM模型的迭代次数能提升模型的运行速率,从而提升过滤器整体性能。
3 多层grams特征抽取方法
本节我们将介绍基于多层grams的特征抽取方法,在介绍该方法之前将介绍基于分词和基于n-grams的特征抽取方法,并分析存在的问题。
3.1 基于词和n-grams的特征抽取方法
基于词的特征提取方法是将一封邮件的内容以词的形式分开,每个词作为一个特征建立特征空间向量。即在建立特征空间之前,需要对邮件进行分词。中英文分词有所不同,不同的系统也有不同的分词形式。对邮件内容为英文的邮件,有多种分词形式,例如,一个连续且含非空白字符的字符串为一个特征,即以空格形式分词,也有的是一个连续且只含字母的字符串为一个特征,即以非字母形式分词等。中文邮件的分词,并不像英文分词那么简单,因为中文每个词与词之间是连续的,并没有用空格分开,需要根据一定的规范将中文句子拆分成每个词。所以中文分词要比英文分词复杂得多,困难得多。目前中文分词方法主要分为3类: 基于词典的方法、基于统计的方法和基于理解的方法[10]。这3类分词方法之间哪种方法准确率更高,目前尚无定论。对目前常用的分词系统来说,大部分都是混合使用这三类分词方法。例如,海量科技的分词算法就是采用基于词典和基于统计的分词方法。目前比较成熟的分词系统有: SCWS分词系统、FudanNLP分词系统、ICTCLAS分词系统、CC-CEDICT分词系统、IKAnalyzer分词系统、庖丁解牛(Paoding)分词系统和JE分词系统等。本文实验使用JE分词系统。
随着反垃圾邮件技术的发展,发送垃圾邮件技术也在提高,垃圾邮件发送者通过故意拼写错误、字符替换和插入空白等形式对垃圾邮件特征的单词进行变体,从而逃避检测系统的检测。图1给出了“Viagra”这个单词在TREC05p数据集上出现次数最多的25种变体。正常情况下,用户都能知道这些变体和“Viagra”单词是同一个含义。然而在基于词的特征提取方法下,每一个变体的出现都代表一个新的特征,不能识别出是“Viagra”这个单词,从而导致过滤器失效。基于字节的n-grams方法能够克服这些问题。

图1 “Viagra”这个单词在TREC05p-1数据集上出现次数最多的25中变体
基于n-grams的特征提取方法是将邮件按照字节流进行大小为n字节的切分(其中,n取值为1,2,3,4…),每次向后滑动一个字符,得到长度为n个字节的若干个串,每个串称为gram。例如,information,按照n=4时进行滑动窗口切分为: info、nfor、form、orma、rmat、mati、atio和tion这8个4-grams的特征。
基于字节级n-grams特征提取方法使用非常方便,对句子进行分词,不需要任何词典的支持;在使用之前也不需要语料库进行训练。在对邮件提取特征时,不需要对邮件进行预处理,也不用考虑邮件编码问题,直接将邮件作为无差别的字节流。同时该方法能够处理复杂的文档,例如,HTML格式的邮件、邮件中的图像文件以及附件等内容。该方法与基于词的特征提取方法相比,能够有效防止信息伪装等问题。如图1所示的文字变形。基于词的特征提取方法可能就识别不了这些特征,而n-grams方法能有效地识别出该特征。例如,Viagra使用4-grams方法提出的特征为: Viag、iagr、agra;当Viagra变形后变成Viiagra时提取的特征为: Viia、iiag、iagr、agra;两者共同特征是iagr和agra。过滤器能够识别这两个特征。
中文的一个字由两个字节或四个字节组成,每个字之间都是连续的。对于中文的n-grams特征提取方法如图2所示。图2中,“10月29日”在计算机中存储的形式转化为十六进制: 31 30 D4 C2 32 39 C8 D5。使用基于字节级的4-grams特征提取方法提取的特征如图2所示。

图2 使用n-grams方法提取特征实例
虽然基于n-grams的特征抽取方法已经在垃圾邮件过滤中取得了非常好的效果,但仍存在以下两个问题:
1) 基于n-grams的特征抽取方法抽取的特征数目较多,特征数接近邮件内容的字符数,对大规模系统来说,耗时非常久。
2) 基于n-grams的特征抽取方法抽取中文邮件特征时,会出现半个汉字情况,半个汉字和其他字符会组成新的汉字,改变特征原有的含义。
3.2 多层grams特征抽取方法
虽然基于n-grams的特征抽取方法已取得很好的效果,但由于该方法抽取的特征数目较多,导致Online SVM消耗的时间仍然过大,无法在工业界使用。本文提出了多层n-grams特征抽取方法。该方法处理流程如图2,处理过程如算法1。
多层grams特征抽取方法相比n-grams方法有两大优点: 1)能够大幅降低特征的数据,从而大幅降低online SVM模型的运行时间。2)能够抽取更为精准、更为有效的特征,减少无用和具有噪声的特征,从而提升模型过滤效果。
算法1: 多层n-grams特征抽取方法处理过程
Input: 一封邮件内容
Step1: 将邮件内容按照中英文字符分隔成若干个字符串,每个字符串为全部中文字符或全部非中文字符,并将其分成全部中文字符串集合和全部非中文字符串集合。例如,邮件内容为: “12月12日 10个人在Hilton Hotel花费1234567元人民币”,被分成若干个字符串,其中,中文字符串集合为: “月,日, 个人在,花费,元人民币”,非中文字符串集合为: “12,12,10, Hilton Hotel,1234567”。
Step2: 对中文字符串集合中每个字符串使用n-grams特征抽取方法抽取特征,但滑动窗口每次往后移动两个字符。例如,字符串“元人民币”一共为8个字符,通过n-grams方法抽取的特征为: “元人,人民,民币”。
Step3: 对非中文字符串集合中每个字符串也使用n-grams方法抽取特征,但滑动窗口每次往后移动1个字符。
Step4: 将两个集合中抽取的特征组成特征空间向量。
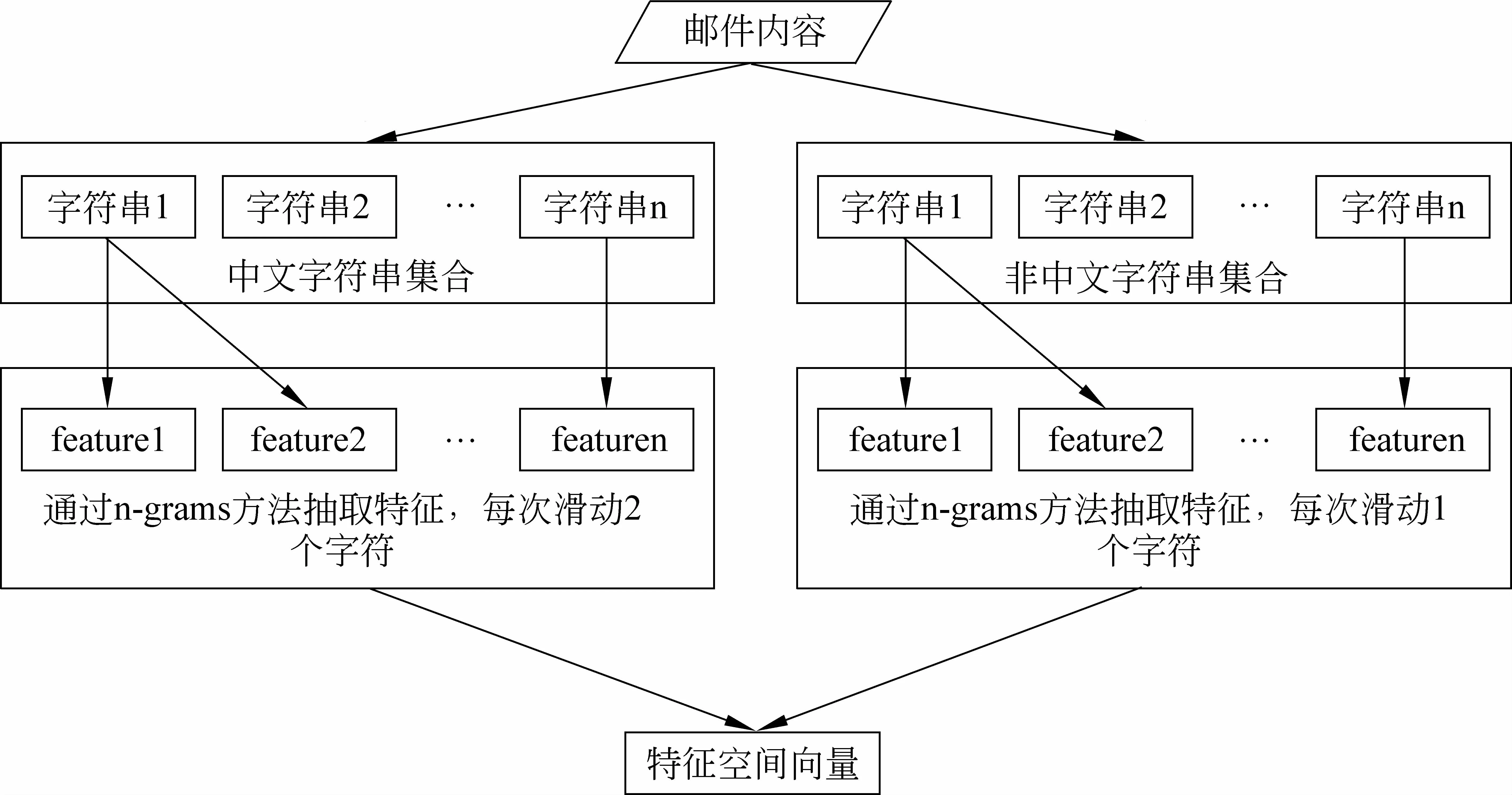
图3 基于多层grams特征抽取框架
4 实验
本节我们将在大规模数据集上测试本文所提出的多层grams特征抽取方法,本节的实验结果表明,该方法大幅降低了基于在线支持向量机的中文垃圾邮件过滤器的运行时间,显著提升了过滤器的过滤性能。
4.1 实验数据集及评价指标
本文中所用的数据集TREC06c是TREC会议于2006年举行的中文垃圾邮件评测数据,其数据集由清华大学提供。TREC06c数据集的邮件数为64 620封,其中垃圾邮件为21 766封,正常邮件为42 854封。
本文使用(1-ROCA)%和lam%作为过滤器的评估指标[5]。hm%为正常邮件的误判率,sm%为垃圾邮件的误判率。由于hm%值很小时,并不能保证sm%的值也很小,所以本文使用(1-ROCA)%和lam%做过滤器评价指标。
lam%为逻辑平均误判率,其定义为式(4)。
以hm%为横坐标,以sm%为纵坐标,组成ROC曲线,(1-ROCA)%的值为取不同阈值时的ROC曲线上方面积。该值的范围为0到1之间。(1-ROCA)%和lam%的值越小表示过滤器性能越好。
4.2 实验设置
本节所有实验所测试邮件都只提取每封邮件的前3 000个字符,涉及的n-grams特征抽取方法的n均为4。在线支持向量机模型中,正则化参数C=100,回看样本的参数n=10 000,即只训练最新出现的10 000封邮件,KKT条件中,M的参数为0.8,优化迭代次数设为1。
4.3 基于词和n-grams特征抽取方法比较
我们分别测试基于词和基于n-grams的特征抽取方法在online SVM模型上的效果,实验结果为表1,实验结果表明基于n-grams方法的过滤效果要远好于基于分词的方法,(1-ROCA)%由0.007提升到0.004,降低近一半。

表1 基于词和基于n-grams的特征抽取方法在Online SVM模型上指标对比
在时间消耗方面,虽然基于分词的方法抽取特征数目明显小于n-grams,但消耗的时间基本接近,主要原因是中文分词花费时间较大,导致整体消耗的时间过大。
因此,基于n-grams特征抽取方法在online SVM模型处理中文垃圾邮件过滤时要明显优于基于分词的特征抽取方法。
4.4 多层grams和n-grams特征抽取方法比较
我们将基于多层grams的特征抽取方法和最优的n-grams方法进行比较,实验结果如表2,通过表2可以发现,多层grams特征抽取方法相比n-grams方法,邮件的平均特征特征由1 625减少到835,减少一半,同时系统运行时间由10 337减少到3 784,仅为原来的1/3。且模型的(1-ROCA)%由原来的0.004降低到了0.002,效果显著。

表2 基于多层grams和n-grams的特征抽取方法在Online SVM模型上指标对比
4.5 与目前最新的垃圾邮件过滤比较
目前研究中比较常用的是基于逻辑回归的垃圾过滤器(LR Model)[11],该方法不仅过滤效果好,而且运行速度快,普遍被工业界运用。同时,在2013年孙广路、齐浩亮等提出了基于在线排序逻辑回归的垃圾邮件过滤器(Ranking LR Model)[12],该方法极大提升了过滤器过滤效果。本文将这两种方法与本文提出的方法进行比较,实验结果如表3。从实验结果可以看出,本文提出的方法的过滤效果是LR Model的5倍,是Ranking LR Model的3倍,效果非常显著。上述数据再次证明了本文提出的方法能被广泛使用。

表3 与目前最新模型的比较
4.6 讨论
从表3可以看出,文本提出的基于多层grams特征抽取方法,不仅降低了模型的特征数目,同时抽取特征能够更精准、更有效地反映垃圾邮件和正常邮件的特性,减少噪声特征,从而提升模型过滤性能。
5 结论
在线支持向量机模型过滤器在TREC 2007垃圾邮件评测竞赛中取得非常好的效果,但与逻辑回归模型过滤器相比,消耗的计算代价是巨大的。目前,很多研究人员更倾向于通过改变在线支持向量机模型的训练方法来减少模型的耗时,很少有研究者从特征抽取的角度来提升模型的效率。然而,事实上特征的优化对模型的影响也是至关重要的,影响机器学习模型的计算速度不仅仅是样本的数量,还有特征维度,通过抽取能够反映数据特性的特征,可以提升过滤器的性能。因此,我们提出了基于多层grams的特征抽取方法来提升基于在线支持向量模型的中文垃圾邮件过滤器。实验表明,该方法不仅能大幅减少系统的运行时间,而且还能大幅提升系统的过滤效果。
[1] G Hulten, J Goodman. Tutorial on Junk Mail Filtering[C]//Proceedings of the Twenty-First International Conference on Machine Learning Tutorial, 2004.
[2] T Nathan, S Timothy, C Brad, et al. Deterministic Memory-efficient String Matching Algorithms for Intrusion Detection[C]//Proceedings of IEEE INFOCOM, 2004: 2628-2639.
[3] Hongyu Gao, Yan Chen, Kathy Lee. Towards Online Spam Filtering in Social Network[C]//Proceedings of the 19th Annual Network & Distributed System Security Symposium.2012.
[4] G Hulten, J Goodman. Tutorial on junk e-mail filtering. In ICML 2004, 2004.
[5] G V Cormack, T R Lynam. TREC 2005 spam track overview[C]//Proceedings of The Fourteenth Text REtrieval Conference (TREC 2005), 2005.
[6] G V Cormack. TREC 2006 spam track overview[C]//Proceedings of The Fifteenth Text REtrieval Conference, 2006.
[7] G V Cormack. TREC 2007 spam track overview[C]//Proceedings of The Sixteenth Text REtrieval Conference, 2007.
[8] D Sculley, G Wachman. Relaxed online SVMs for spam filtering[C]//Proceedings of The Thirtieth Annual ACM SIGIR Conference Proceedings, 2007.
[9] J Platt. Sequential minimal optimization: A fast algorithm for training support vector machines[M]. In B Scholkopf, C Burges, A Smola, editors, Advancesin Kernel Methods—Support Vector Learning. MIT Press, 1998: 158-208.
[10] 孙铁利, 刘延吉. 中文分词技术的研究现状与困难[J]. 信息技术,2009, 7: 187-192.
[11] 沈跃伍. 基于在线学习的垃圾邮件过滤技术研究[D]. 哈尔滨理工大学, 2012.
[12] 孙广路, 齐浩亮. 基于在线排序逻辑回归的垃圾邮件过滤[J]. 清华大学学报: 自然科学版, 2013, 5: 734-740.
Typed N-gram for Online SVM Based Chinese Spam Filtering
SHEN Yuanfu1, SHEN Yuewu2
(1. Library, Harbin University of Science and Technology, Harbin, Heilongjiang 150080, China; 2. School of Computer Science and Technology, Harbin University of Science and Technology, Harbin, Heilongjiang 150080, China)
In this paper, we propose Mix-grams method to improve online SVM filter for spam filtering. Though online SVM classifier brings high performance on online spam filtering, its computational cost is remarkable compared to other methods such as Logistic Regression. In this paper, we propose a type based n-gram extraction method to reduce the feature dimension of online SVM filter. Experimental results demonstrate that the method improves the filter performance and reduces the computational cost of online SVM filter.
Feature Extraction; Support Vector Machine (SVM); Spam filtering

沈元辅(1960—),副教授,主要研究领域为信息检索、信息过滤。E⁃mail:yuanfu.shen@gmail.com沈跃伍(1986—),硕士研究生,主要研究领域为机器学习、数据挖掘、特征抽取。E⁃mail:yuewu.shen@qq.com
1003-0077(2015)01-0126-07
2014-06-15 定稿日期: 2014-07-27
TP391
A
猜你喜欢
英语文摘(2021年10期)2021-11-22
校园英语·月末(2021年13期)2021-03-15
潍坊学院学报(2020年2期)2021-01-18
农机质量与监督(2020年8期)2020-09-29
计算机与网络(2020年4期)2020-04-20
科技与创新(2019年13期)2019-08-12
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
趣味(语文)(2018年2期)2018-05-26
现代计算机(2016年11期)2016-02-28
