
用遗传算法提取南疆红枣总糖的近红外光谱特征波长
2015-06-05 09:51彭云发彭海根罗华平
食品工业科技 2015年3期
彭云发,詹 映,彭海根,刘 飞,罗华平,2,*
(1.塔里木大学机械电气化工程学院,新疆阿拉尔 843300;2.新疆维吾尔自治区普通高等学校现代农业工程重点实验室,新疆阿拉尔 843300)
用遗传算法提取南疆红枣总糖的近红外光谱特征波长
彭云发1,詹 映1,彭海根1,刘 飞1,罗华平1,2,*
(1.塔里木大学机械电气化工程学院,新疆阿拉尔 843300;2.新疆维吾尔自治区普通高等学校现代农业工程重点实验室,新疆阿拉尔 843300)
本研究尝试利用近红外光谱技术测量红枣的总糖含量,针对采用偏最小二乘(PLS)法建立近红外光谱预测模型时波长筛选问题,提出用联合区间偏最小二乘法(siPLS)与遗传算法(GA)相结合的方法遗传联合区间偏最小二乘法(GA-siPLS)来提取近红外光谱特征区域和特征波长,提高模型预测精度的方法。结果表明:将全谱等分成20个子区间,用联合区间偏最小二乘法优选出4个特征子区间,在这4个子区间的基础上再用遗传偏最小二乘法继续筛选出12个特征波长。用12个特征波长建立的偏最小二成模型精度要好于全谱建立的模型,其主因子数减少了4个,预测集标准偏差(RMSECP)减少了25%,预测相关系数(RP)提高了5%。该方法选取的波长变量建立的校正模型,不仅使模型简洁、优化,而且增强了模型的预测能力。
近红外光谱,特征波长,联合区间偏最小二乘法,遗传算法,红枣
红枣营养十分丰富,是我国历来推崇的滋补食品。北方民间有“日食三个枣,人生不易老”,“五谷加红枣,胜过灵芝草”的谚语,高度赞扬了红枣的食补功效[1]。糖度是红枣内部品质的一个重要指标,而且按照目前国际市场惯例,标识出糖度的水果可以获得更高销售价格[2],所以对红枣糖度进行检测很有必要。对红枣糖度进行检测不仅可以增加我国的红枣出口数量,而且通过对红枣进行分级管理,也可以完善对红枣资源的综合利用,产生显著的经济效益及社会效益。
红枣中的总糖含量存在形式已经不是简单的单糖和多糖,特征谱区也就不是某种单糖或多糖的特征谱区,所以在测定时确定红枣总糖的特征谱区是比较困难的。遗传算法(GA)最初是由Holland于1975年提出的,它借鉴生物界自然选择和遗传机制,利用选择、交换和突变等算法的操作,随着不断的遗传迭代,使目标函数值较优的变量被保留,较差的变量被淘汰,最终达到最优结果。1998年R.Leardi[3]提出一种遗传偏最小二乘法(GA-PLS)来进行光谱特征波长的筛选,并在短波近红外光谱中得到成功的应用,但参与该方法的光谱点数不能太多,否则算法很难收敛。2000年Lars N rgaard[4]提出一种联合区间偏最小二乘法(siPLS)来进行光谱区间的筛选,该方法只能筛选特征区间,不能筛选出单个特征波长。通过特定的方法筛选特征变量一方面可以简化模型,一方面剔除不相关或非线性变量,得到预测能力更强的校正模型。本研究目的是提取红枣红糖的近红外特征波长,先用联合区间偏最小二乘法在整个谱区中选择红枣的特征谱区,然后再对该特征谱区进行遗传偏最小二乘法筛选出红枣总糖的光谱特征波长,用该方法建立的偏最小二乘模型简洁、稳定性好并且预测能力强。
1 材料与方法
1.1 材料与仪器
2013年10月采集于新疆生产建设兵团阿拉尔市10团处于白熟期的灰枣,选出没有损伤、伤疤的120颗红枣。对其依次进行编号及去除灰尘等处理,沿着样品赤道部位(间隔约 120°)标记 3 点作为数据采集点,然后放入冷库(温度2~10℃)中保存。
采用美国赛默飞世尔科技生产的Antaris Ⅱ FT-NIR型光谱仪采集红枣近红外光谱,以仪器内部空气为背景,测量范围4000~10000cm-1,采样点数为1557点,每张光谱扫描次数32次,分辨率为8cm-1,仪器使用InGaAs检测器,化学计量学分析软件为仪器自带的TQ软件和MATLAB7.0(美国Mathworks)。
1.2 光谱采集
光谱采集条件:光谱采集前,先将红枣从冷库中取出放入室内12h,目的是使红枣温度与室内温度相同,室内温度在23~26℃之间,相对湿度25%~30%;测样方式:近红外光谱仪开机预热30min后,分别对红枣样本赤道部位每隔120℃标记的3点采集漫反射光谱,共采集三次,取平均光谱。共采集120张红枣近红外原始光谱图。
1.3 红枣样本总糖测定方法
1.3.1 样品处理 红枣总糖的测定方法采用直接滴定法,按国标GB/T5009.7-2008执行。取标记部位的红枣果肉去皮,准确称取2.5~5g研磨并置于100mL容量瓶中,加50mL水,摇匀,边摇边慢慢加入5mL乙酸锌溶液和5mL亚铁氰化钾溶液,加水至刻度,摇匀,静置30min,用干燥滤纸过滤,弃去初滤液,收集滤液备用。
1.3.2 测定 吸取处理后的样品溶液50mL于100mL容量瓶中,加入5mL 6mol/L盐酸溶液,在68~70℃水浴中加热15min,冷却后加入2滴甲基红指示剂,用20%氢氧化钠溶液中和至中性,加水至刻度,摇匀。吸取5mL费林试剂甲液和5mL费林试剂乙液,置于150mL锥形瓶中,加水10mL,加入玻璃珠2粒,控制在2min内加热至沸,趁沸以快速从滴定管中滴加比预测体积少1mL的样品溶液,然后趁沸以每两秒1滴的速度滴至终点。记录样品溶液消耗体积,同时平行测定三份,取其平均值。
1.3.3 计算 计算红枣样品中的总糖含量:
总糖含量(%)=m×100/W×(50/V1)×(V2/100)×1000
式中:m为10mL费林试液相当于葡萄糖量(mg);W为红枣样品质量(g);V1为红枣样品处理液的总体积(mL);V2为测定总糖含量取用水解液的体积(mL)。
1.4 算法简介
Nørgaard等提出在光谱数据中运用局部区域建立回归模型的方法,然后把它称为间隔偏最小二乘法(iPLS)[4]。iPLS的目的是把光谱分割成一些较小等距子区间,然后在每个子区间建立偏最小二乘模型。它表明选择最优的区间能带来精确的预测模型。然后,在某些情况下,如果仅选择一个光谱区间来建立校正模型,有些有用的信息可能被遗弃,并且也可能会降低模型的性能。所以,Nørgaard提出其他的方法来选择组合区间建立PLS模型,叫做联合区间偏最小二乘模型(siPLS),它将同一次区间划分中精度较高的几个局部模型所在的子区间联合起来,共同预测待测样本品质指标。虽然该方法相对于iPLS或多或少的有所改进,但是,它也存在缺点。正如我们所知,这些方法只用于选择有效的光谱区间;尽管在一些小区间里,也仍然有一些共线变量。因此,必需从这些最优子区间中选择有用的变量。
遗传算法[3]是一种新近发展起来的搜索最优解的方法。它模拟生命进化机制,也就是说,模拟了自然选择和遗传进化中发生的繁殖、交配和突变现象,从任意一个初始群体出发,通过随机选择、交叉和变异操作,产生一群新的更适应环境的个体,使群体进化到搜索空间中越来越好的区域。这样一代一代不断繁殖、进化,最后收敛到一群最适应环境的个体上求得问题的最优解。遗传算法的实现主要包括5个基本要素:参数编码;群体的初始化;使用度函数的设计;收敛判据和变量的选取等。具体的遗传算法实现流程框图参见图1。
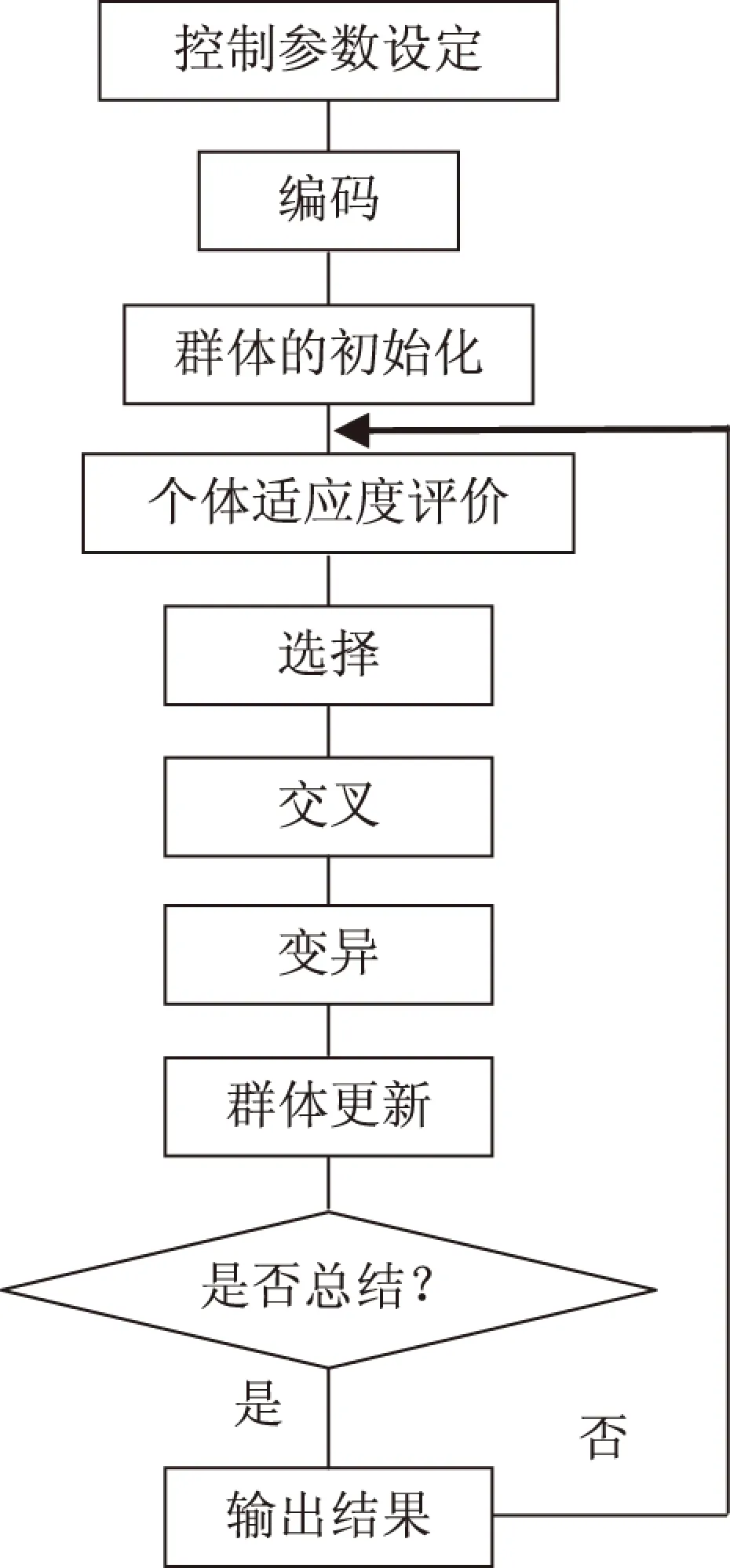
图1 遗传算法实现流程框图Fig.1 Flow diagram of the genetic algorithm
2 结果与分析
2.1 校正模型
在采集原始光谱时为了消除系统、环境和样品背景等对近红外漫反射的影响,经过多次测试与比较,对原始光谱进行标准化预处理,图2为120粒红枣近红外光谱图和标准化后的光谱。
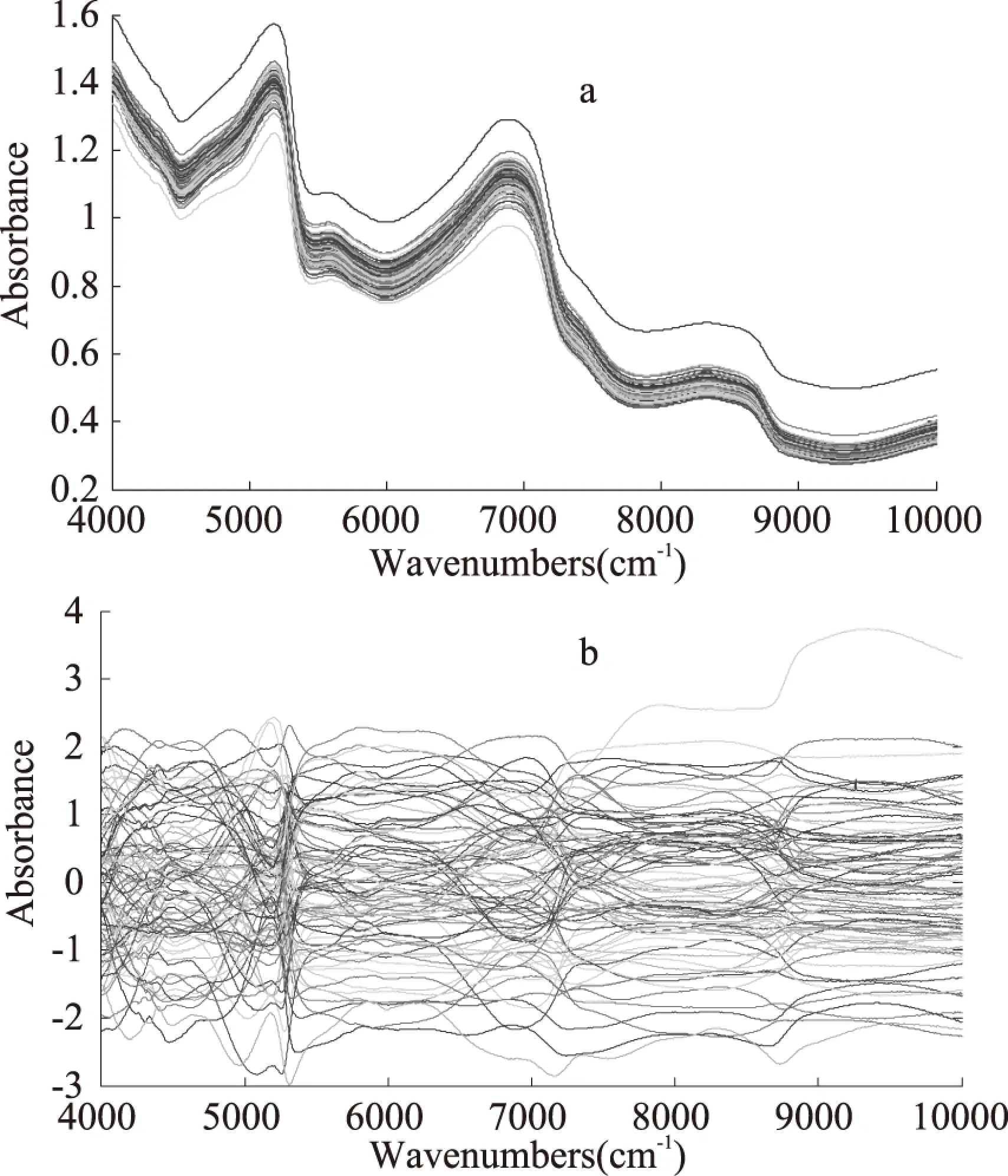
图2 120颗红枣近红外光谱(a)和 标准化后处理的光谱(b)Fig. 2 NIR original spectra of one hundred(a)and twenty jujubes NIR spectra after standardization(b)
将120颗红枣样本随机分成两组,一组是校正集用来建立校正模型,另一组是验证集用来测试模型的稳健性。为了避免两个子集划分出现偏差,按照如下方式划分:所有样品是通过他们各自的Y值(总糖)而排列的。为了划分校正集与验证集光谱,每4个样品中有一个光谱被选人验证集。因此,校正集有90个光谱;验证集有30个光谱。如表1中所示,校正集y值范围大于验证集的范围。因此,样品分布在校正集和验证集是适当的。图3所示的是校正集样品总糖含量分布图,该图呈高斯分布说明校正集样品选择合理。

表1 红枣总糖含量实测值统计表Table 1 Statistics of sugar content of jujubes measured by the standard methods
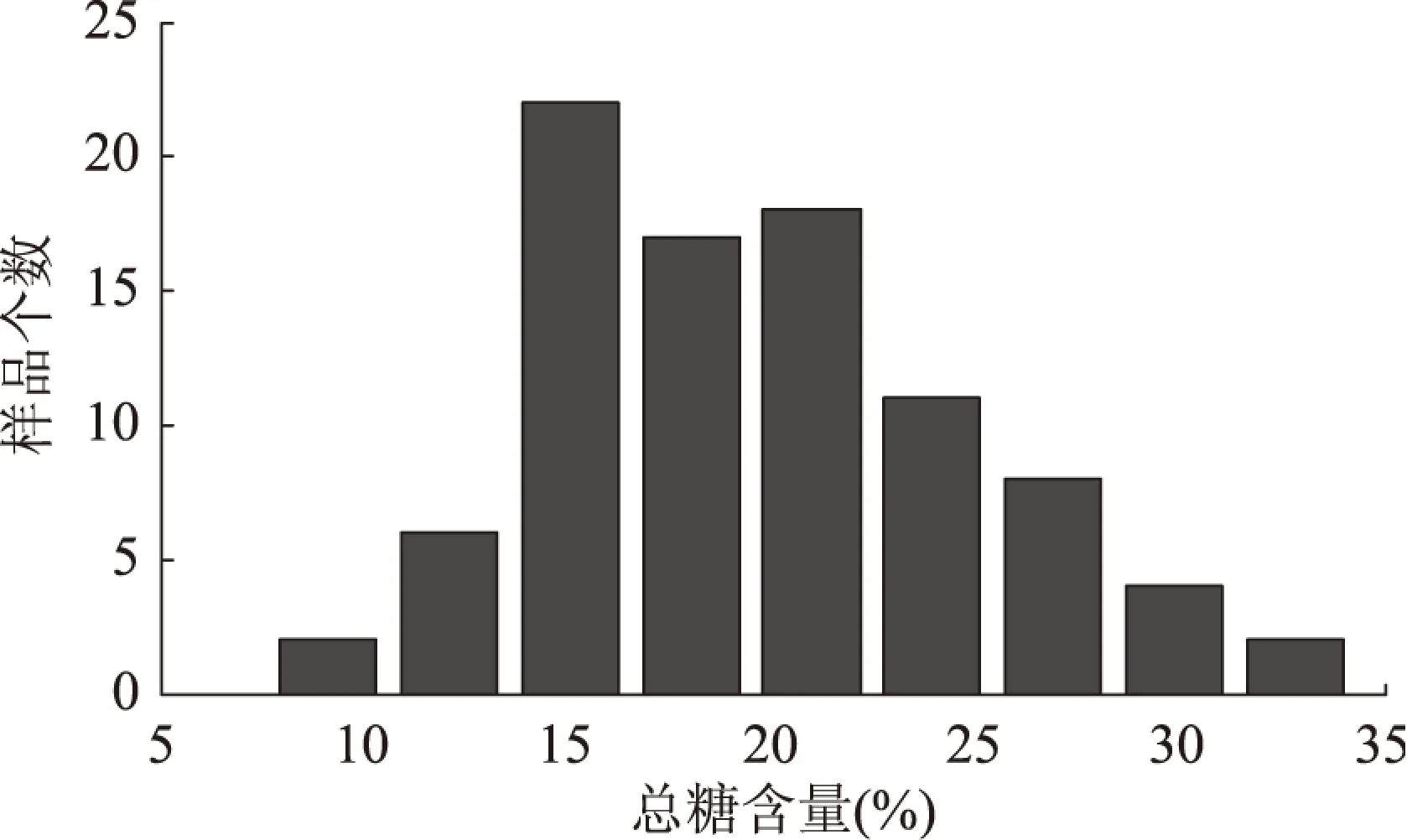
图3 校正集样品总糖含量分布图Fig.3 Total sugar content distribution of Calibration set
在校正模型中,采用留一交互验证法(leave-one-sample-out cross-validation)来建立校正模型。留一交互验证法就是:每次从样本集中取出一个样本,用余下的样本来建立模型,用建好的模型来预测之前取出在这个样本,直到样本集中每个样本都被取出过一次。
2.2 iPLS模型结果
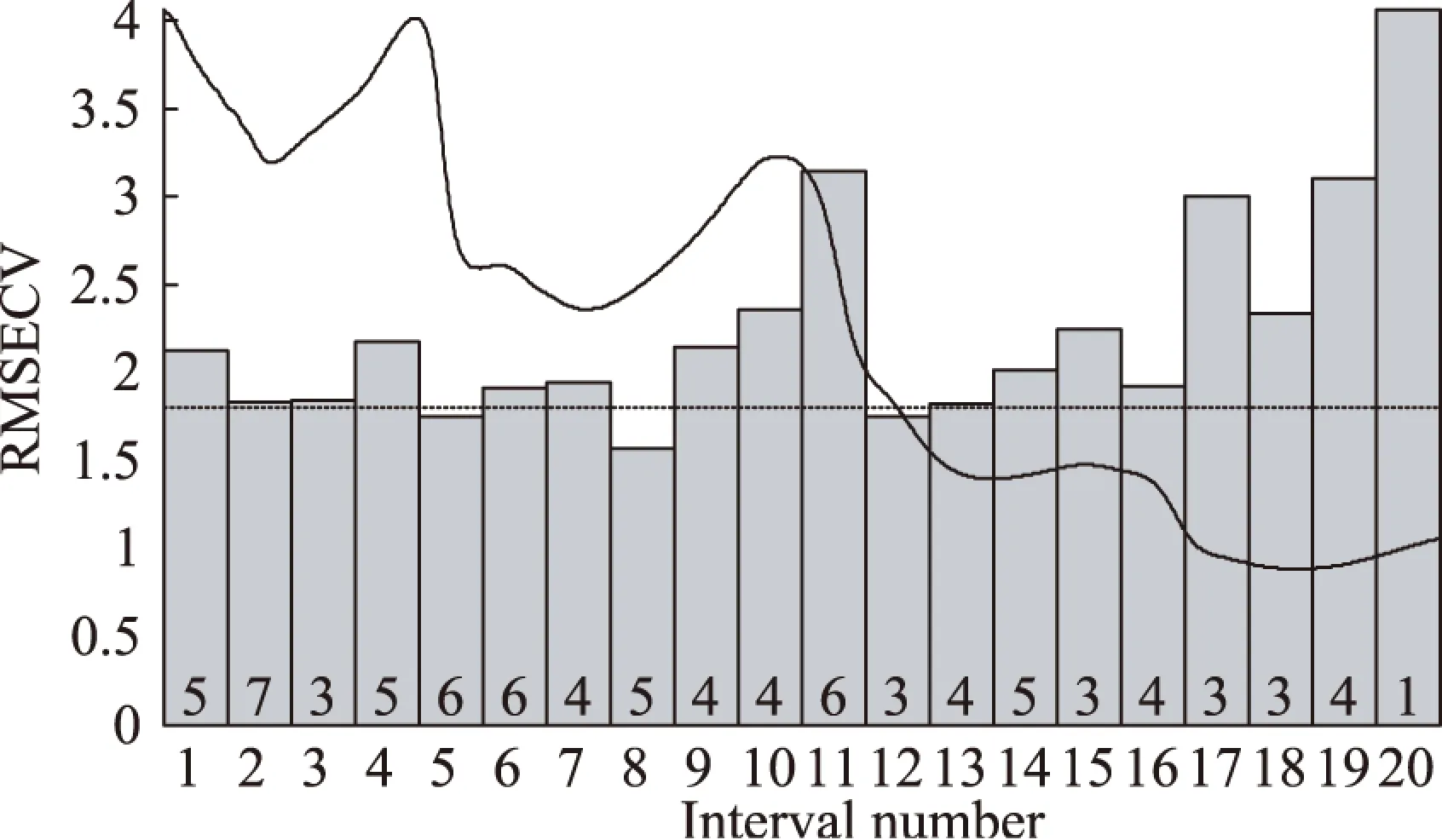
图4 各区间模型的RMSECV值与全谱模型的 RMSECV值比较图Fig.4 Comparison of interval model’s and full spectrum’s RMSECV注:虚线表示全谱模型的RMSECV值, 曲线是一个红枣光谱图,斜体字为各区间模型的主成分数。
将图1中光谱数据(范围4000~10000cm-1)共1557个波数点等分为20个区间,第1~17为78个波数点,第18~20为77个波数点。用间隔偏最小二乘法(iPLS)进行处理,处理结果如图4所示。从图4中可以看第5、8和12个区间上的偏最小二乘法模型的RMSECV值比全谱模型的RMSECV值小,这是因为全谱1557个变量用来建立校正模型,这1557个变量有很多是与红枣总糖不相关的,它们叫做“无信息变量”。另外,近红外光谱区域的共线变量,它们称为“冗余变量”。如果模型中含有“无信息变量”和“冗余变量”,会降低模型的预测能力,因此并不是用于建模的光谱数据越多越好。
2.3 联合区间偏最小二乘法选取特征光谱区间
利用siPLS从20个区间中选取特征光谱区域组合,在数据处理过程中,尝试分别联合2、3和4个子区间建立红枣总糖校正模型,处理结果如表2所示,从表中可以看出选择第5、7、9和10区间组合的联合区间建立的红枣总糖的偏最小二乘模型,得到最小的RMSECV值1.554,该4个子区间所对应的波数分别为5203~5499.99,5804.69~6101.67,6406.37~6703.35,6707.21~7004.19cm-1,如图5所示。
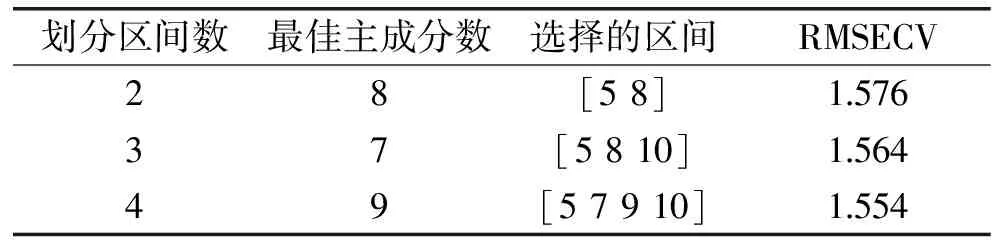
表2 选择不同子区间数的 联合区间偏最小二乘分析模型结果Table 2 Choose the number of different subinterval joint interval partial least squares analysis model results
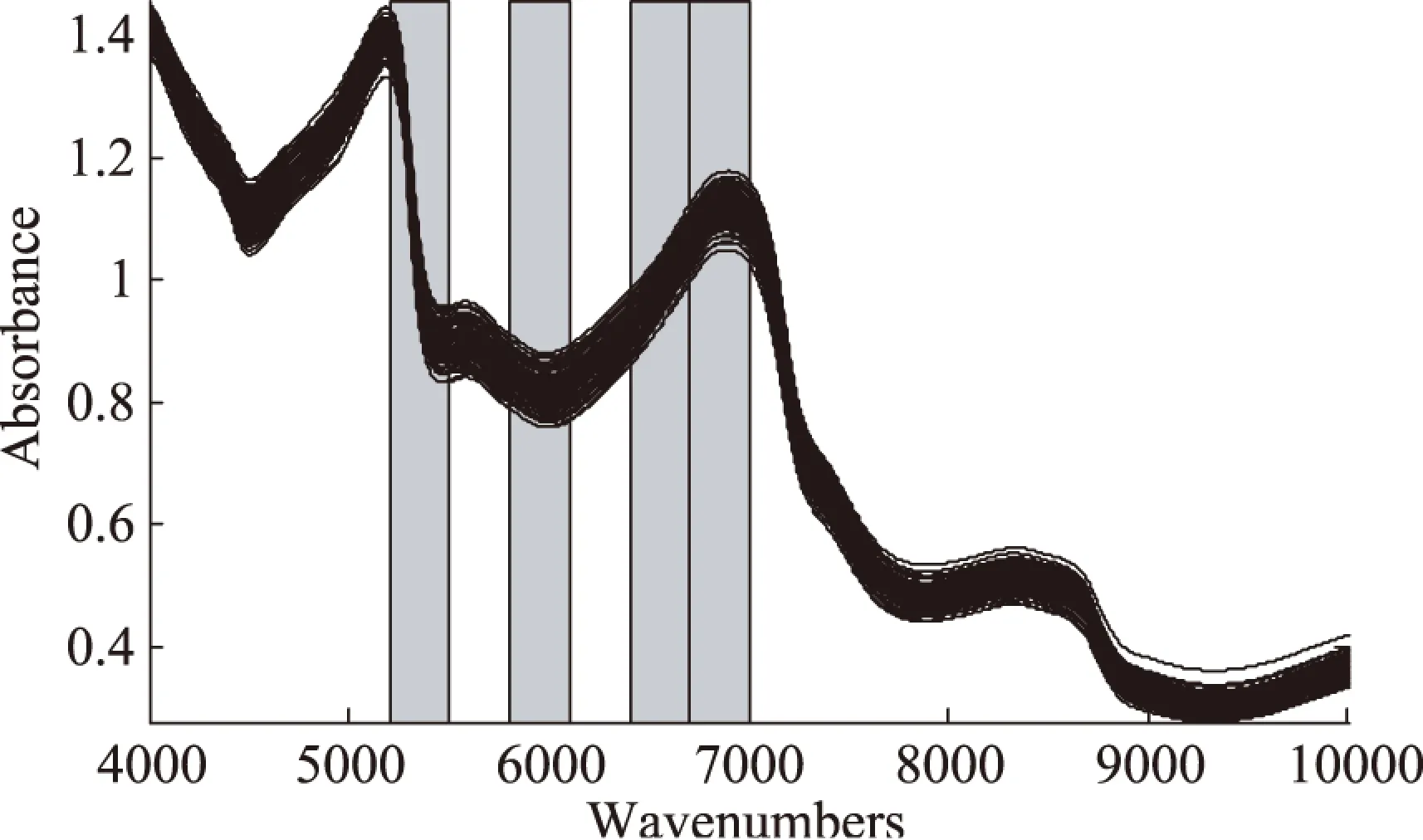
图5 si-PLS选择的最佳子区间Fig.5 Spectral region selection accomplished by si-PLS
2.4 遗传偏最小二乘法选择特征波长
用遗传偏最小二乘法GA-PLS对联合区间偏最小二乘法所选出来的4个区间内的波数变量进一步筛选,遗传算法的控制参数设定为:初始种群100,交叉概率Pc=0.8,变异概率Pm=0.01,遗传迭代次数为100,迭代终止后将被选用频次最多的波数点按频次高低顺序逐一加入PLS模型中,以最小的交互验证均方根误差(RMSECV)值确定出最佳的建模变量。为了防止算法运行过程中随即性对结果的影响,研究共进行5次运算,最后挑选出其中性能最好的模型所选用的频率变量作为最佳变量,表3为5次运算GA-PLS所选用的波长变量的数目及RMSECV值,可以看出12个波长点数被使用的时,可获得最低的RMSECV值1.4609。图6(a)显示了第3次运算过程中各频率被选用的频次,从该图中可以看出,被选用的频次较多的变量主要集中在siPLS变量区间的中间区域,即在100~200(对应的波数为5885.68~6572.21cm-1)之间,特别是变量数在168(波数6448.79cm-1)左右的几个变量被选用的频次最高,这说明这几个变量与红枣总糖信息之间有较高的相关性,(b)图为选用的变量数对用的RMSECV值,从图中可以看出选用12个变量建立的RMSECV值最小。

表3 5次GA-PLS运算选用的变量和最低RMSECV值Table 3 The statistical result of 5 calculations by GAPLS
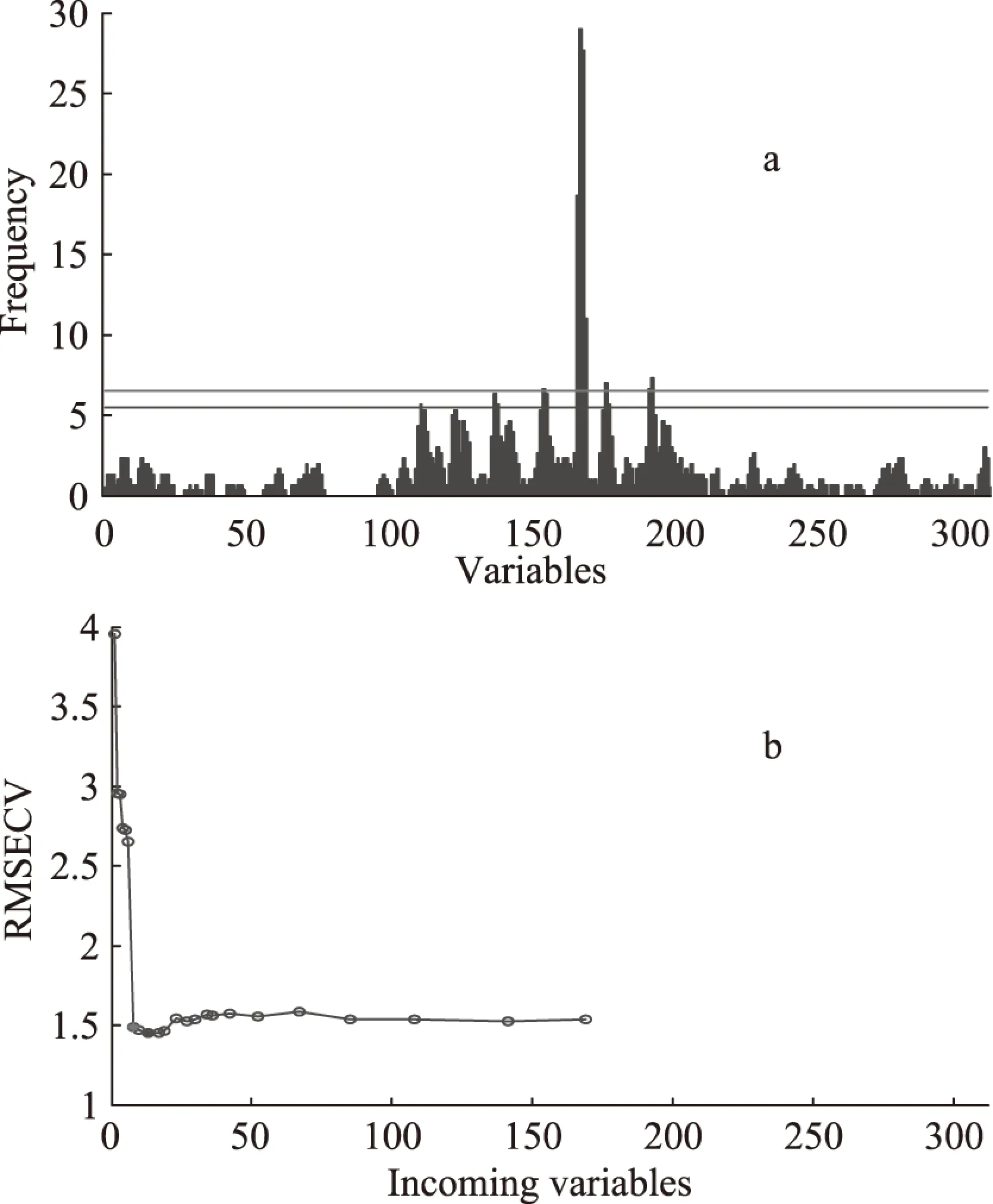
图6 各变量被选用的频次图(a)和 选用的变量数对应的RMSECV值(b)Fig.6 The frequency of selections original wavelengths after dynamic GA-PLS(3 runs)(a)and RMSECV corresponds selections variables(b)
2.5 建模比较
为了比较联合区间偏最小二乘法和遗传偏最小二乘法的处理效果,采用TQ软件来建立校正模型。将所建的模型与全谱建的模型进行比较,结果如表4所示。比较其他的PLS模型,GA-siPLS模型展现最优的结果。这种现象可以用化学计量学和光谱学解释。
关于PLS模型,全谱1557个变量用来建立校正模型。这1557个变量有很多是与红枣总糖不相关的,它们叫做“无信息变量”。另外,近红外光谱区域的共线变量,它们称为“冗余变量”。如果模型中含有“无信息变量”和“冗余变量”,会增加PLS主因子数。例如,PLS模型中的9个主因子数,它多余其他的模型主因子数。如此多的主因子数能够解释校正集与验证集不同的结果。太多的PLS主因子数会导致模型过拟合。当通过独立的样品来测试时,过拟合模型会给出不好的预测结果。
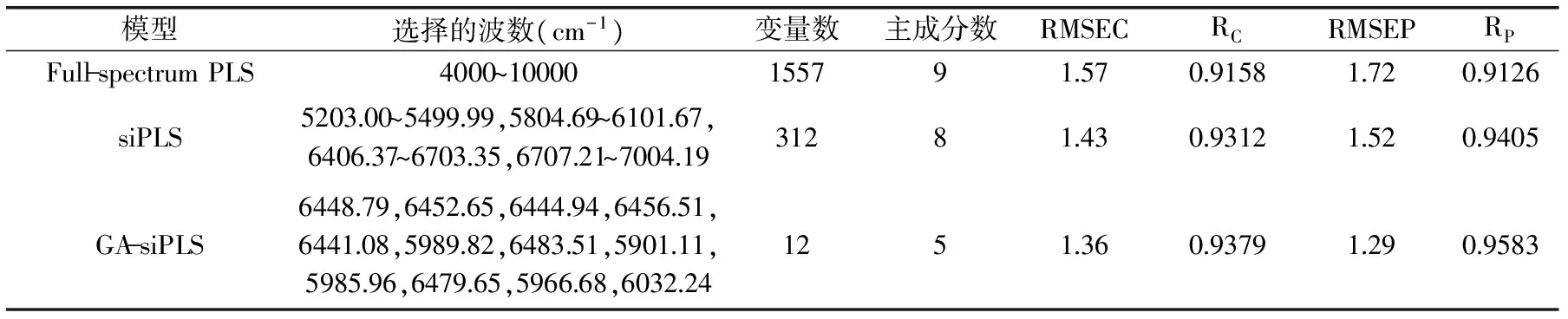
表4 选用不同处理方法后的偏最小二乘模型结果Table 4 Results of PLS by different methods
siPLS模型,是通过Norgaard的目的联合几个光谱区间建立的PLS模型。siPLS模型要好于PLS模型,因为校正模型中的一些“无信息变量”和“冗余变量”被剔除了。本研究中siPLS模型包含312个变量,在变量数目上siPLS远少于PLS模型的变量数(1557个变量)。siPLS(主因子8)模型比PLS模型(主因子9)简洁。
siPLS模型有较好的性能相对于PLS模型,但是与GA-siPLS相比模型性能要稍微低点。在两个相邻波段或者一个小的区间仍有共线变量。这些共线变量会降低模型的预测能力。本研究中,GA-siPLS模型先后分两步建立:首先,从20个光谱区间中选择4个子区间,并且选择的变量为312个;第二,从312个变量中选择12个变量。GA-siPLS模型相比于siPLS获得更好的性能,因为它可以避免两个相邻波段的共线变量。
3 结论与讨论
用联合区间偏最小二乘法和遗传算法对南疆红枣总糖特征区域和特征波长的提取,结果表明,用其方法建立的偏最小二乘法模型与全谱模型相比,不仅提高了模型的预测精度,而且还大大减少了建模所用的波长点数,使模型得到简化,减少建模运算时间,稳定性好,所选取的变量点数能有效的反应红枣总糖的信息,建立的模型鲁棒性强。该结果可为设计滤光片式或激光式红枣糖度快速检测仪提供一种客观的特征波长的选择方法。
在光谱结合多元校正的方法中,传统观点认为多元校正方法(如PLS)具有较强的抗干扰能力,可全波长参加多元校正模型的建立。随着对PLS等方法的深入研究的应用,通过特定方法筛选特征波长或波长区间有可能得到更好的定量校正模型。波长选择一方面可以简化模型,更主要的是由于不相关或非线性变量的剔除,可以得到预测能力强、稳健性好的校正模型。本文结果表明通过遗传算法选择的波长建立的PLS模型比全谱建立的模型预测能力强、稳健性好,选择的12个波长点与红枣总糖密切相关。遗传算法具有全局最优、易实现等特点,成为目前较为常用且非常有效的一种波长选择方法。
[1]郭裕新,单公华.中国枣[M].上海:上海科学技术出版社,2010.1-3.
[2]褚小立.化学计量学方法与分子光谱分析技术[M].北京:化学工业出版社,2011.293-295.
[3]Leardi R,Lupiáez A,González. Genetic algorithms applied to feature selection in PLS regression:how and when to use them[J]. Chemometrics and Intelligent Laboratory Systems,1998,41(2):195-207.
[4]Norgaard L,Saudland A,Wagner J,etal.Interval Partial Least-Squares Regress-ion(iPLS);a Comparative Chemometric Study with an Example form near-infrared Spectroscopy[J].Applied Spectroscope,2000,54(3):413-419.
[5]彭云发,黄磊,罗华平. 南疆红枣静态图像采集分级方法研究[J]. 农机化研究,2014(3):28-31.
[6]王加华,潘璐,孙谦,等. 遗传算法结合偏最小二乘法无损评价西洋梨糖度[J]. 光谱学与光谱分析,2009(3):678-681.
[7]褚小立,袁洪福,王艳斌,等. 遗传算法用于偏最小二乘方法建模中的变量筛选[J]. 分析化学,2001(4):437-442.
[8]邹小波,赵杰文. 用遗传算法快速提取近红外光谱特征区域和特征波长[J]. 光学学报,2007(7):1316-1321.
[9]朱向荣,李娜,史新元,等. 近红外光谱与组合的间隔偏最小二乘法测定清开灵四混液中总氮和栀子苷的含量[J]. 高等学校化学学报,2008(5):906-911.
[10]罗华平,卢启鹏. 近红外拓扑方法在南疆红枣品质分析中的应用[J]. 光谱学与光谱分析,2012(3):655-659.
[11]罗华平,卢启鹏,丁海泉,等. 南疆红枣品质近红外光谱在线模型参数的实验研究[J]. 光谱学与光谱分析,2012(5):1225-1229.
[12]陈斌,王豪,林松,等. 基于相关系数法与遗传算法的啤酒酒精度近红外光谱分析[J]. 农业工程学报,2005(7):99-102.
[13]彭云发,彭海根,詹映,等.近红外光谱对南疆红枣水分无损检测的研究[J]. 食品科技,2013(11):260-263.
[14]张楠,程玉来,李东华,等. 近红外透射光谱测定水晶梨糖度的初步研究[J]. 食品工业科技,2007(3):215-216+228.
Analysis of near infrared spectroscopy ofjujube sugar content by genetic algorithms
PENG Yun-fa1,ZHAN Ying1,PENG Hai-gen1,LIU Fei1,LUO Hua-ping1,2,*
(1.School of Mechanical and Electrical Engineering,Tarim University,Alar 843300,China;2.The Key Laboratory of Colleges & Universities under the Department ofEducation of Xinjiang Uygur Autonomous Region,Alar 843300,China)
This study was conducted to attempt to measure the total sugar content of jujube(Ziziphusjujubacv. Huizao)using near-infrared spectroscopy,the information can be abstracted by partial least-square regression(PLS). In order to select wavelengths of near infrared spectroscopy in the prediction model of partial least squares regression of jujube sugar content detection,correlation coefficients and genetic algorithms and interval partial least squares(GA-siPLS)were used to select wavelength from near infrared spectroscopy in partial least squares regression model. The spectra were divided into twenty intervals,among which four subsets were selected by GA-siPLS to characterize the net signals of jujubes’ saccharinity. Then twelve absorbance values(A)at their characteristic wavelengths were screened out. It showed that the model developed by selecting twelve wavelengths was better than that of full spectrum.the principal factor number reduced by 4 and the root mean square error of prediction of prediction set reduced by 25%,while correlation coefficient of prediction improved 5%. The results showed that this wavelengths selection method for PLS modeling not only simplified and optimized calibration model but also increased the prediction ability of calibration model. Therefore,genetic algorithms are effective and feasible methods applied in developing mutlivariate calibration model based on partial least squares regression.
Near Infrared Spectroscopy(NIR);characteristic wavelength;interval partial least squares;Genetic Algorithms;Jujube
2014-03-04
彭云发(1984-),男,硕士生,研究方向:农产品品质近红外光谱检测技术研究。
*通讯作者:罗华平(1973-),男,硕士,教授,研究方向:农产品品质无损检测技术的研究。
国家自然基金项目资助(10964009和11164023)。
TS255.7
A
1002-0306(2015)03-0303-05
10.13386/j.issn1002-0306.2015.03.055
猜你喜欢
小学生学习指导(低年级)(2022年10期)2022-11-05
数学小灵通(1-2年级)(2021年10期)2021-11-05
趣味(作文与阅读)(2021年12期)2021-04-19
语数外学习·初中版(2020年11期)2020-09-10
小学生学习指导(低年级)(2019年9期)2019-09-25
学生天地(2019年35期)2019-08-25
今日农业(2019年10期)2019-06-26
科技与创新(2016年22期)2017-03-30
科技视界(2016年20期)2016-09-29
小猕猴学习画刊(2016年6期)2016-05-14
