
一种基于权重融合的JPEG隐写分析方法
2015-06-10 00:28孙寿健魏立线苏光伟
液晶与显示 2015年2期
孙寿健,魏立线,刘 佳,苏光伟
(武警工程大学 电子技术系 网络与信息安全武警部队重点实验室, 陕西 西安 710086)
一种基于权重融合的JPEG隐写分析方法
孙寿健*,魏立线,刘 佳,苏光伟
(武警工程大学 电子技术系 网络与信息安全武警部队重点实验室, 陕西 西安 710086)
针对JPEG图像通用隐写检测中检测效率低、训练时间长的问题,提出一种基于集成分类器的新检测方法。算法以CC-PEV为特征对图像进行描述并作为隐写分析特征;然后,随机构造若干个特征子空间,用bootstrap方法构造图像训练子集,分别进行训练得到数个基分类器;根据基分类器的分类结果赋予基分类器不同的权重,将基分类器的结果按照其权重进行融合得到最终的结果。本文对该算法进行了测试,对它的集成性、检测准确率和训练时间进行分析。实验结果表明,相对于传统的集成方法,本文方法用自举方法构造训练集、随机方法构造子特征空间、赋予基分类器不同权重进行融合能够显著地提高算法准确率。本文方法相对于SVM和传统的集成分类方法,具有更高的检测率,对于特征维数更大的图像检测,具有更好的拓展性和一般适用性。
隐写分析;集成;分类器; 权重
1 引 言
隐写分析[1-3](steganalysis)的目的是检测隐秘载体中秘密信息的存在性,进而估计出秘密信息的嵌入比率和嵌入位置,最终提取出秘密信息。其中,秘密信息检测是嵌入比率估计和秘密信息提取的前提,也是当前隐写分析技术研究的热点问题。它通常采用基于统计的方法,通过挖掘载体图像和隐写图像间的统计差异构造特征向量集,采用分类器进行隐写判别。因此,隐写分析实质上是多维特征空间的模式分类器,设计与特征空间相匹配的分类器对于提高算法的检测效果具有十分重要的意义。
隐写分析技术主要包括专用隐写分析和通用隐写分析两大类[1-3],一般来说,专用隐写分析只对特定的方法有效;通用隐写分析对几种隐写方法都有效,甚至对新的未知方法也有效。专用隐写方法主要有基于LSB的专用隐写分析和基于JPEG域的专用隐写分析。通用隐写分析主要包括基于图像质量、基于统计矩和基于相邻像素相关性的隐写分析。本文提出方法属于通用隐写分析。
在文献[4]中,Fridrich等人提出一种集成分类隐写分析方法,将模式识别领域的集成分类器运用到图像通用隐写分析中,实验证明,集成隐写分析可以在计算时间和精确度上有很大的提升。但存在以下几点可以改进的地方:(1)没有考虑基分类器之间的差异性,构造基分类器的方法比较简单,可以优化训练集的构造方法和子特征空间的构造方法;(2)集成分类策略很简单,赋予每个基分类器相同的权重。基于以上两点,本文设计了新的集成隐写分析算法,算法以CC-PEV为特征对图像进行描述并作为隐写分析特征;然后,随机构造若干个特征子空间,用bootstrap方法构造图像训练子集,分别进行训练得到数个基分类器;最后,根据基分类器的分类结果赋予基分类器不同的权重,最后将基分类器的结果按照其权重进行融合得到最终的结果。实验结果表明,赋予基分类器权重能够显著地提高算法准确率。
2 特征空间设计
校准是攻击F5隐写算法时提出来的一个新概念。随后,校准成了JPEG通用盲隐写分析中不可或缺的一个环节,实验证明,它可以有效提高隐写分析的检测率。Jan Kodovsky 等[5]对校准的原因及步骤进行研究。在本文算法中,采用PEV特征的校准特征CC-PEV[5],现有的实验结果表明,在特征空间中尽可能将不同类型的特征组合在一起可以有效提高检测率,PEV特征是由几种不同类型特征组合在一起的,PEV的特征类型和校准过程如表1和图1所示。
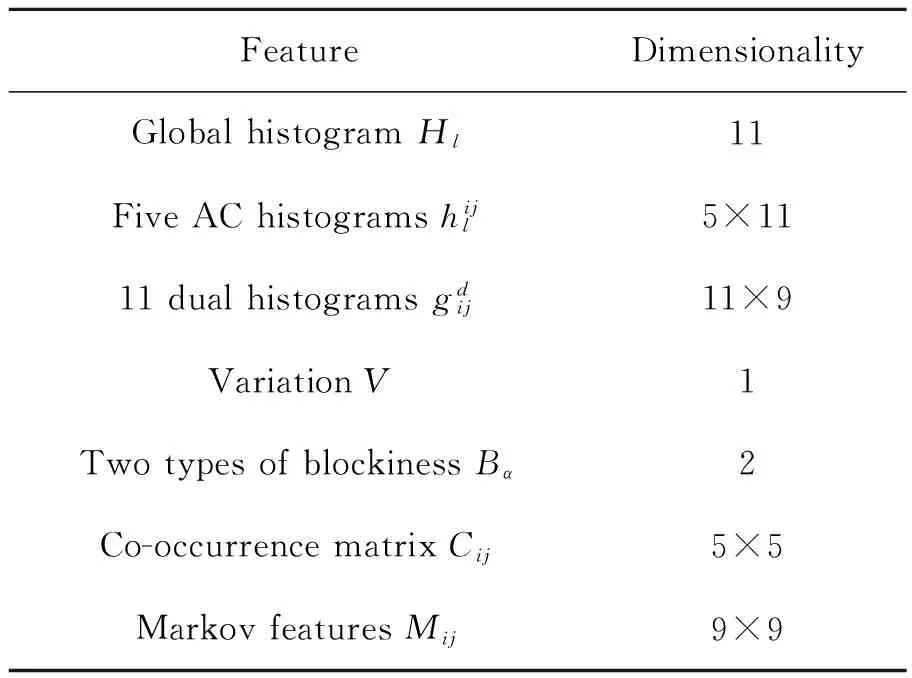
表1 PEV特征类型
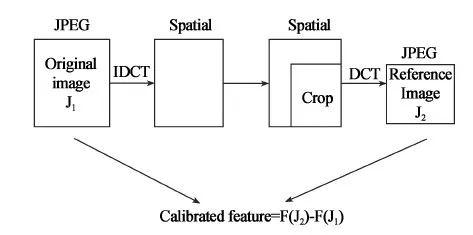
图1 PEV特征校准过程示意图Fig. 1 PEV characteristics of the calibration process schematic
3 集成分类器
3.1 基分类器
SVM分类器训练的复杂性,使得训练过程变得更长,训练复杂性更高,同时,复杂的训练过程也限制了训练特征的维数。为了提高计算效率,减小特征维数限制,本方法采用Fisher线性分类器作为基分类器,FLD分类器可以不考虑特征维数限制,同时使得每轮的训练时间减少,使得训练时间大大减少。同时,随着训练轮数的增加,最终的集成分类器的分类准确度会越来越高。
3.2 基分类器权重计算方法
考虑到基分类器样本和特征子空间的差异性,不同基分类器的对最终预测结果的影响比重也不同,所以本算法使用权重计算方法来平衡基分类器间的差异性[6]。例如,把N个样本集对同一组特征重要性的判断看作是N个裁判的判断一样,一般情况下可以采取多数投票法来决定最后的结果。然而基于不同裁判自身的差异性,他们对最终结果影响的比重各不相同,不是简单的等权重。所以,应赋予不同基分类器不同的权重,与最终判定结果具有高度统一的基分类器应赋予更高的权重,反之,应赋予更低的权重。假设存在一个实例数为N的样本集,有数据集产生的L棵决策树,根据决策树的预测结果可获得一个N(L+2)的矩阵,矩阵的行代表要预测的实例,矩阵的前L列分别代表L棵决策树,第L+1 列代表集成投票的结果,在前L列中超过半数的判定,确定为第L列的最终结果,第L+2 列代表样本数据集的实例类标号。则第i棵决策树的判定可信度可通过式(1)计算:
AccEnsemble,
(1)
其中:TreeConfidencei表示第i棵树的可信度,Treeij表示第i棵树对第j个实例的预测结果,Ensemblej表示对第j个实例的集成预测结果。AccEnsemble表示的是集成预测准确率,即Ensemble与Original的一致性程度,I(Treeij=Ensemblej)是示性函数,用来表示单棵树预测结果与集成结果是否相同。由于每棵树的AccEnsemble都是相同的,TreeConfidencei与AccEnsemble相乘后所获得排序结果是一样的。之所以仍然需要加入这一影响因素,是为了缩小权重间的绝对差距,同时展现集成整体效果对于特征重要性度量的影响。
然后,根据计算出来的决策树的可信度计算出决策树的权重值,即基分类器的权重值。决策树的权重值可以计算如下:
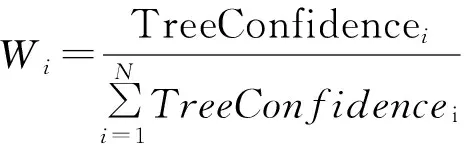
(2)
3.3 集成分类器
为了进一步提高分类器分类精度,设计集成分类器来进行隐写判别。集成分类器主要包括集成分类器主要包括特征子空间构造、基分类器训练和集成策略3个部分[7],其基本思想是首先构造原始特征空间的随机特征子空间,然后构造具有良好差异性的训练子集,并分别进行训练得到基分类器,最后将基分类器的结果按照一定的集成策略进行融合作为最终的分类结果。
结合CC-PEV特征的特点,本文按如下思路设计集成分类器:随机产生L个具有较低维数的特征子空间[8],L为基分类器个数,为原始特征空间的维数且,利用bootstrap方法构造图像的训练样本子集,分别按FLD线性分类器进行训练得到基分类器,再将所有基分类器的分类结果按权重计算法进行融合作为集成分类器的分类结果。具体步骤如算法1所示,其中,Ntrn为图像训练集,Ntst为测试图像集。
Step1分类器参数优化。设置适合的基分类器个数L和特征子空间维数dsub;
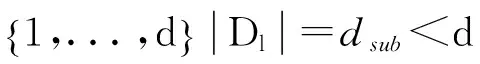
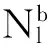
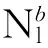
(d)∀y∈ytst,预测第l次结果:
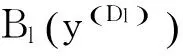
(3)
Step3基分类器权值的训练。利用训练好的基分类器对新的训练集进行训练,将多数投票的方法确定集成结果,按照公式(1)(2)对每个基分类器进行权值的计算。
Step4 基分类器集成。利用权重计算法将L个基分类器的分类结果进行融合,作为集成分类器最终的分类结果:
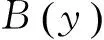
(4)
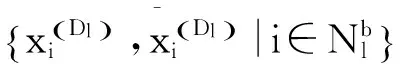
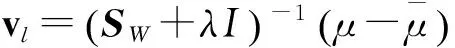
(5)
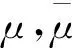
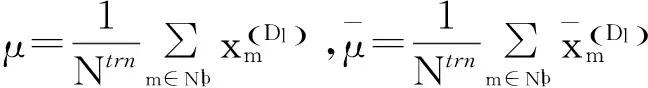
(6)
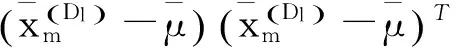
(7)
其中:SW是无类别分散矩阵,λ是使矩阵SW+λI为正数的稳定参数,来避免SW有可能出现异常数值的问题。
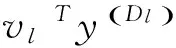
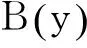
3.4 分类器参数优化
由于基分类器的泛化性很弱,分类效果不明显,构造检测准确度高、差异性大的集成分类器成为关键。而集成分类器的最重要的两个参数L和dsub的设定成为关键。对此,本人利用1 000幅载体图像ci(i=1,…,N)及其对应的隐写图像si(i=1,…,N)作为测试样本对参数L和dsub进行优化。在训练集的每个基分类器最终调整为使最终检测错误率PE最小[9]:
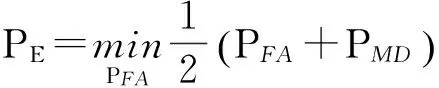
(8)
其中:PFA和PMD分别代表虚警率和误报率。
在本算法中,由于前面基分类器使用的训练集是boostrap自举方法得到的训练集,每个训练样本都会收集大约0.37N的预测来检测训练样本的错误率。把这些用于检测的来源于训练集之外(outofbag)的样本集得到的错误预测称为OOB错误[4]。
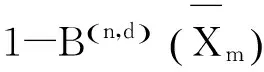
(9)
由图2可以看出:(1)随着基分类器个数L的增加,错误检测率PE逐渐减小并趋于一个稳定值,超过一定的个数后,错误检测率PE几乎不再变化。这是因为一开始随着基分类器的个数增加,集成结果越来越准确,错误检测率就随之降低。当基分类器到达一定数量时,基分类器之间差异的重复程度比较大,集成结果准确率趋于稳定。(2)当dsub较小时,随着子空间维数dsub的增大,错误检测率PE随之显著降低,dsub到达一定值后继续增加,错误检测率PE反而随之升高。这是因为dsub较小时,特征间差异性不大,dsub变大可以有效提高特征差异性从而降低错误检测率,dsub到达一定数量继续增加后,特征间的差异性有很多重复部分,反而降低了特征差异性,从而使错误检测率升高。
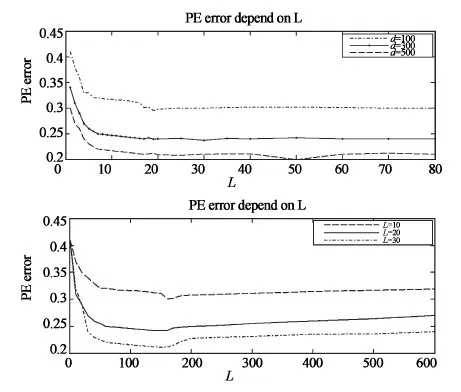
图2 PE和基分类器个数L和子特征空间维数d的关系Fig.2 Relationship PE and the number of base classifiers L and sub d is the dimension of the feature space
(1)L的优化
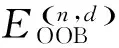

(10)
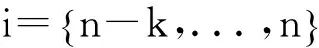
(2)dsub的优化
根据上式可以求得优化的L,然后根据得到的L和上面的关系式来求最佳的dsub。
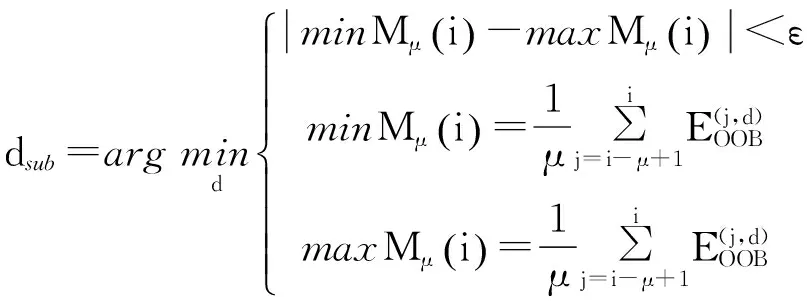
(11)
本文取得到μ=5,ε=0.05得到最优化的基分类器个数L=20,子特征空间维数dsub=210。
4 实验结果与分析
4.1 实验准备
为了验证本文算法的有效性和实验效果,从BossRank图像库选取1 000幅载体图像、6 000幅隐写图像和幅混杂图像进行实验。其中,图像大小均为512×384,质量因子为80,隐写图像采用nsf5[10]、mb2[11]、Outguess[12]等3种隐写算法进行嵌入且每种算法为2 000幅(嵌入率分别为10%和50%);混杂图像包含500幅载体图像和上述3种隐写算法图像各200幅(嵌入率分别为10%和50%)。为了衡量算法的性能和效率,本算法分别从集成性能、准确率和训练时间3个方面来衡量算法。
4.2 集成分类器对检测性能的影响
本方法中,使用多个基分类器集成作为最终的预测结果,其中所使用的基分类器为FLD线性分类器,下面来比较在这几种隐写图像下的单个分类器和集成分类器下的检测率。从表2中可以看出,集成分类器相对于单个分类器的检测结果都有不同程度的提高,不同嵌入率的隐写图像,其检测结果准确率都能提高,这说明,集成分类器能有效提高算法的性能。原因如下,相对于单个分类器,集成分类器通过构造更多的差异性使预测结果更加准确,同时使用权重赋值方法使得最终的融合结果体现不同基分类器对最终结果影响的大小不同,更具有准确性。同时通过比较发现,相对于低嵌入率的隐写图像,高嵌入率的隐写图像的检测率具有更大的提升幅度,这是由于高嵌入率的隐写图像和原始载体图像的差异性更大,其所对应的特征差异性更大,更容易被基分类器检测出来,从而使集成分类器精度更高。
表2 单个分类器和集成分类器的检测结果
Tab.2Detectionresultsofsingleclassifierandensembleclassifier
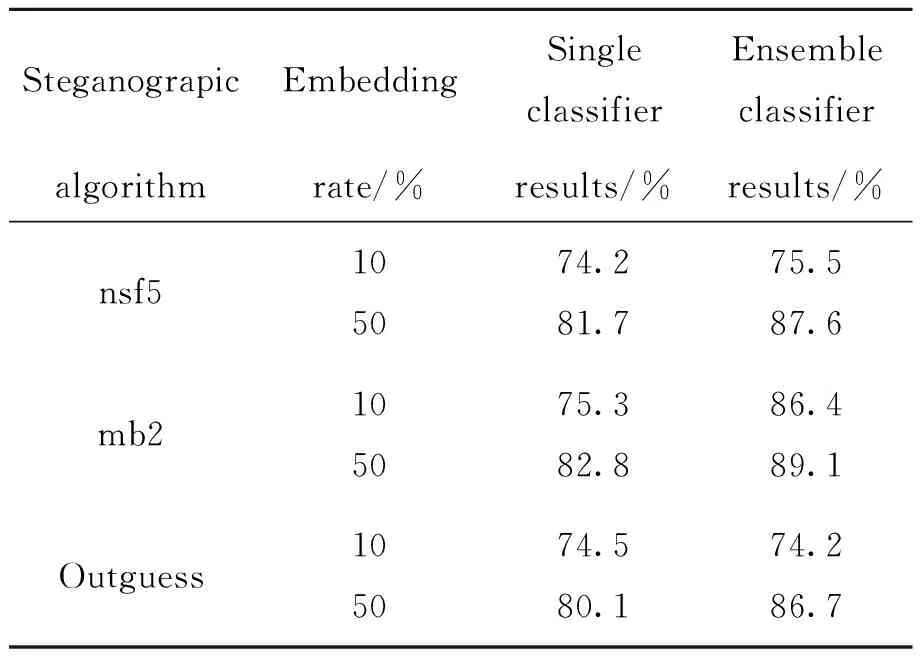
SteganograpicEmbeddingSingleclassifierEnsembleclassifieralgorithmrate/%results/%results/%nsf5105074.281.775.587.6mb2105075.382.886.489.1Outguess105074.580.174.286.7
4.3 不同方法检测准确率比较
为了进一步评价本算法的性能,将本文方法同支持向量机SVM[10]和文献[4]所用方法相比较:SVM先将训练集中的图像特征进行训练找出最优分类面,然后对待检测图像进行隐写类别判定;文献[4]所用方法为集成分类方法,训练多个基分类器,最后用简单的多数投票法来判定图像类别。3种方法的检测结果如表3所示。

表3 三种分类方法的检测结果
从表3可以看出,本文算法比其他两种方法的检测准确率都要高。具体来讲,相对于SVM分类器[13],本文方法明显优于前者,这是因为本文分类器充分考虑到特征子空间的差异性和基分类器间的差异性,随机构造特征子空间,使用自举方法选取训练样本,保证了样本和特征的一般性,采用集成方法更精确的预测待测样本的类别;相对于文献[4]所用方法,本文方法的准确率有小幅度的提升,主要是由于在基分类器融合过程中,文献[4]只是用很简单的多数投票法,没有考虑到不同基分类器对最终结果影响的不同,而本文所用方法为权重赋值法,即给不同的基分类器赋予不同的权值,从而得到更准确的分类结果。
4.4 不同方法训练时间比较
训练时间是衡量算法性能的又一指标,一个好的算法在兼顾准确率的同时,能够使训练时间尽量减到最小,统计不同方法在不同大小训练集下的训练时间,对比结果如表4所示。

表4 三种方法的训练时间
由表4可以看出,相对于SVM分类器,本文所用方法能够大大缩减训练时间,训练效率得到明显提升。这是因为本文所用方法的基分类器相对简单,训练单个基分类器时间较短,从而使所用时间大大减少。相对于文献[4]所用方法,本文所用方法的集成策略相对要复杂,所以训练时间会比文献[4]略微增加,但通过表3可知,在几乎同样的训练时间里,本文检测正确率要高一些。
5 结 论
图像通用隐写分析往往存在特征空间维数高、训练检测复杂的问题,通过分析隐写分析算法训练中基分类器之间的差异性,提出采用权重融合的集成策略用于集成隐写分析中,结果表明,用自举方法构造训练集、随机方法构造子特征空间、赋予基分类器不同权重进行融合能够显著地提高算法准确率,实验验证了本文算法的有效性,比之前的方法具有更高的检测准确率。本文中的基分类器可以换成分类性能更好的分类器,这样集合的结果会更准确些,也是下一步的研究方向。
[1] 张军, 熊枫, 张丹. 图像隐写分析技术综述 [J]. 计算机工程, 2013, 39(4): 165-168, 172. Zhang J, Xiong F, Zhang D. Overview on image steganalysis technology [J].ComputerEngineering, 2013, 39(4): 165-168, 172. (in Chinese)
[2] 王朔中, 张新鹏, 张卫明. 以数字图像为载体的隐写分析研究进展 [J]. 计算机学报, 2009, 32(7): 1247-1263. Wang S Z, Zhang X P, Zhang W M. Recent advances in image-based steganalysis research [J].ChineseJournalofComputers, 2009, 32(7): 1247-1263. (in Chinese)
[3] 韩晓东. JPEG 图像隐写分析技术研究 [D]. 郑州: 解放军信息工程大学, 2009. Han X D. Research on steganlysis for JPEG images [D]. Zhengzhou: PLA Information Engineering University, 2009. (in Chinese)
[4] Kodovsky J,Fridrich J, Holub V. Ensemble classifiers for steganalysis of digital media [J].IEEETransactionsonInformationForensicsandSecurity, 2012, 7(2): 432-444.
[6] 尹华. 面向高位和不平衡数据分类的集成学习研究 [D]. 武汉:武汉大学, 2012. Yin H. Research of ensemble learning for high-dimensional and imbalanced data classification [D]. Wuhan:Wuhan University, 2012. (in Chinese)
[9] 李开达. 隐藏信息检测综合评估及融合技术研究 [D]. 郑州: 解放军信息工程大学, 2012. Li K D.Research on comprehensive evaluation and fusion of steganalysis techniques [D]. Zhengzhou: PLA Information Engineering University, 2012. (in Chinese)
[10] Westfeld A.F5—a steganographic algorithm [M]. Springer Berlin Heidelberg, 2001: 289-302.
[11] Ullerich C, Westfeld A.Weaknesses of MB2 [M]. Springer Berlin Heidelberg, 2008: 127-142.
[12] Fridrich J, Goljan M, Hogea D. Attacking the outguess [C].ProceedingsoftheACMWorkshoponMultimediaandSecurity, 2002.
[13] 徐茂. 基于SVM的JPEG图像隐写分析研究[D].长沙: 湖南大学, 2012. Xu M.Steganalysis for JPEG Image Based on SVM [D].Changsha: Hunan University, 2012. (in Chinese)
A rights-based re-integration method for JPEG steganalysis
SUN Shou-jian*, WEI Li-xian, LIU Jia,SU Guang-wei
(KeyLaboratoryofNetworkandInformationSecurityUndertheChineseArmedPoliceForce,ElectronicDepartment,EngineeringCollegeofArmedPoliceForce,Xi'an710086,China)
Aiming at the problem of the high dimension features and complicated training in image universal steganalysis technology, this paper proposes a steganalysis method based on ensemble classifier. The method designs a ensemble classifier which combines the difference of base classifier and weighted fusion. Specifically, the algorithm uses CC-PEV as steganalysis features. Then, the method randomly structures several feature subspace, uses the bootstrap method to construct image training subsets, and train them to get a number of base classifiers. Finally, every base classifier is given weight that different from each other according to the classification result and then the final forecast is got after the combination of classification results with their respective weight. The experimental results show that using ensemble classifier for training and giving base classifiers with different weights fusion could effectively improve the accuracy of the algorithm.
steganalysis; integration; classifier; weights
2014-04-02;
2014-05-22.
国家自然基金(No.61379152)
1007-2780(2015)02-0326-07
TP309
A
10.3788/YJYXS20153002.0326
孙寿健(1990-),男,山东德州人,硕士研究生,主要从事图像信息隐藏方面的研究。E-mail:ssj1990220@163.com 魏立线(1966-),男,陕西户县人,硕士研究生,教授,主要从事信息安全的研究。 刘佳(1982-),男,河南汝州人,博士,讲师,主要从事信息安全的研究。 苏光伟(1984-),男,山东淄博人,硕士研究生,主要从事信息安全的研究。
*通信联系人,E-mail:ssj1990220@163.com
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
心理学报(2022年5期)2022-05-16
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
当代陕西(2020年17期)2020-10-28
当代陕西(2019年10期)2019-06-03
人大建设(2018年5期)2018-08-16
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
航天返回与遥感(2014年5期)2014-07-31
中原工学院学报(2014年4期)2014-04-01
