
客户评论中用户体验信息自动提取研究
2015-06-27 08:26胡令传陶晓鹏
计算机工程 2015年1期
胡令传,陶晓鹏
(复旦大学计算机科学技术学院,上海201203)
客户评论中用户体验信息自动提取研究
胡令传,陶晓鹏
(复旦大学计算机科学技术学院,上海201203)
客户评论在人们的日常生活中越来越重要,人们希望从客户评论中获取商品的用户体验信息。客户评论数量的急剧增长使得用户快速、精准地获取有用的信息变得较为困难。为此,提出一种能够自动提取用户体验信息的方法。该方法通过语义片段过滤评论中的冗余信息,提取产品特征词及特征描述词,将其结合组成用户体验信息,自动获取信息能够迅速、准确地从客户评论中提取信息。实验结果证明了该方法的有效性,并且能够保证较高的准确率与查全率。
客户评论;特征挖掘;情感分析;语义片段提取;用户体验;语义相似度
1 概述
随着电子商务、微博的兴起,人们的衣食住行与互联网的关系越来越密切,互联网中的信息也随之飞速增长。电子商务中的客户评论数量急剧增长使得用户想要在评论中快速准确的获取到其他用户的体验信息变得困难。客户评论的特点有:数量大,在主流的电商网站上,一件商品的客户评论已经成千上万;内容单一,大部分的客户评论字数较少,所包含的信息量少;语法简单,比较口语化;表达方法简单。
本文提出一种在评论中获取用户体验信息的方法。该方法首先对评论进行分词、词性标注,然后进行产品特征与特征描述的提取,根据产品特征与特征描述来提取出用户体验信息。
2 问题分析及研究背景
2.1 问题分析
现在电商网站上出现了一些对评论进行分类、摘要的方法:(1)用户对商品的总体体验打分,电商网站根据分数进行分类,如一号店,这种方法的弊端是提供的信息量太少;(2)用户添加体验信息,其他用户可以重复使用,如京东商城,这种方法得到的信息与具体评论内容脱节;(3)人工总结词组,统计其数量,如百度微购,但人工总结效率低、不全面。在现有的研究方向中,与本文研究工作密切相关的主要有2个:产品特征挖掘和情感倾向分析。下面结合本文的方法对这2个方面分别进行介绍和分析。
2.2 产品特征挖掘
产品特征挖掘是指从大量的网络客户产品评论中获取产品特征,这项技术是产品特征情感倾向分析的前提。文献[1-2]使用了人工标记语料加上机器学习的方法提取汽车的产品特征,取得了不错的效果。但人工进行参与的产品特征提取方法可移植性差。文献[3]首先对句子进行句法分析,进行名词短语的获取,然后运用关联规则进行提取到产品特征。这种方法虽然不需要人工进行干预,但准确率与效率都比较低。
人工参与和句法分析的特征提取方法都不太适用于电商网站上的客户评论:对于前者,客户评论数量庞大,种类繁多,采用人工进行标注特征,可行性太差;对于后者,互联网上的评论表达自由,形式新颖,并不一定符合非常严谨的语法规则,导致句法分析结果不会太理想,进而准确率不会太高。本文则结合客户评论自身的特点,采用了语义片段提取与词频统计结合的方法实现了自动产品特征挖掘。
2.3 情感倾向分析
情感倾向分析的目的是判断用户对产品的态度,包括正面、负面和中性[4]。目前情感倾向分析的技术主要分为2种:机器学习方法和语义方法。文献[5]提出了半监督的机器学习方法进行情感倾向挖掘。这种方法虽然能够达到非常高的准确度,但人工标记语料效率低。基于语义理解的情感分析方法[6-7]是利用词语相似度计算词语与褒义词和贬义词的距离,从而得到的词语的情感值。在文献[8]中,用基于语义理解的情感倾向分析方法对文本的情感倾向进行分析,取得了非常好的效果。
目前的情感倾向分析方法只是考虑了一些比较有情感色彩的词,比如“不错”、“好看”这样的词。而客户评论特别是一些电商网站的评论中会出现很多新词,比如“接地气”、“正能量”这种词,则不能很好地判断其褒贬。更有像“荷兰进口”这种词,不能仅仅用褒贬来表达。因此,定义了表达范围更广泛的概念,称为特征描述词。用特征描述词的提取来代替情感倾向分析,使得评论阅读者能够获取到更加丰富的信息。
3 用户体验信息提取
本文提出的自动获取用户体验信息方法主要有3个步骤:(1)通过产品特征挖掘获取到产品的特征信息,即产品特征词;(2)获取描述产品特征的词语,即特征描述词;(3)合并特征词和特征描述词,形成用户体验信息。
3.1 产品特征挖掘
产品特征挖掘基于语法规则及上下文相似度计算,分3个步骤:复合名词合并,语义片段提取,语境相似度计算。
(1)复合名词合并。这里的复合名词包括普通意义的复合名词、“的”字结构等。用复合名词作为产品特征词能够保证所提取信息的完整性和精确性。合并规则如下:
名词+名词(直至后面不是名词)
名词+“的”+名词
(2)语义片段提取。客户评论中存在字数很多,但没有或者很少用户体验信息的句子,通过名词短语和介词短语形式的语义片段的提取有用信息提取出来。基于如下的语法规则来定义语义片段:
名词+副词+名词修饰语 (东西/NN很/AD不错/JJ)
名词+副词+动词(宝宝/NN很/AD喜欢/VV)
名词+副词+表语形容词 (味道/NN很/AD浓/VA)
动词+副词+表语形容词 (买的/VV很/AD便宜/VA)
介词+名词+表语形容词 (比/P超市/NN便宜/VA)
语义片段提取用正则表达式来实现。实验表明,利用这些语法规则能够提取出基本完整的语义片段集合,达到了91.9%。
(3)语境相似度计算[9]。在客户评论中,产品特征词的语境有许多相似之处:句中位置相似,上下文的词相似、上下文的词性相似。根据这些特点,本文设计了特征词扩展算法,其中,用W1表示已知的产品特征词;W2表示候选特征词。W1和W2各自取前后2个词语及其词性分别作为它们的上下文,用PW表示上下文中的词,PT表示对应的词性。整个上下文如下所示:

算法中的权重值由人为设定,分值大小确定的原则为:上下文中距离特征词越近的词和词性的权重越高;在距离相同的情况下,上下文中的词比词性的权重高。所有的候选特征词依据得分从高至低排序,如果其得分大于预先设定的阈值,则确定为新的产品特征词。这里的阈值是根据实验过程中得到的结果,取其最小值所得。
特征扩展算法如下:
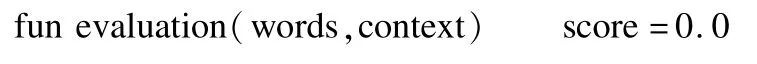

3.2 特征描述词的提取
PMI算法[10]利用词之间同时出现的概率判断情感倾向,PMI算法可以用下式表示:
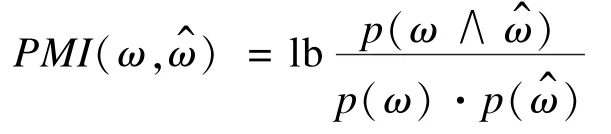
本文发现客户评论中都有多个特征描述词同时出现。因此借用PMI算法,利用已知的特征描述词发现新的特征描述词,即式(1)中ω表示已知的特征描述词,ω^表示待确定的特征描述词。根据PMI算法给所有的ω^打分排序之后,然后去掉其中的副词(AD)、动词(VV),最后根据预先设定的阈值进行筛选。这里的阈值是根据实验结果,取每次正确结果的最小值所得。
3.3 种子词的获取
前面介绍的产品特征词和特征描述词的获取,都需要一些初始的已知词,分别称为产品特征种子词和特征描述种子词。采用如下步骤获取种子词:
(1)对语义片段提取的结果进行词频统计。
(2)设置一个停用词表[11],包含经常出现,但是没有参考价值的词语。
(3)选取出现频率最高,且不包含停用词的N个名词作为产品特征种子词,频率最高且不包含停用词的N个形容词作为特征描述种子词。N的值太小会影响拓展词的准确度,N的值太大会影响种子词的准确度。
3.4 特征词和特征描述词的合并
用户体验信息是特征词与特征描述词的结合。本文利用上下文相关性,将特征词与特征描述词联系起来。依次处理每个特征词,然后合并它们的结果。单个特征词的处理方法如下:
(1)获取特征词的上下文,这里的上下文取的是特征词的前面2个词与后面2个词。
(2)记录上下文中含有的特征描述词,并统计在所有评论中出现的次数。
(3)在含有特征描述词的上下文中,查看是否含有否定词,若含有否定词,需在特征描述词前加入否定词,并重新统计其数量。
4 实验结果与分析
图1给出了本文的实验流程,包括每个步骤的简要实现方法。

图1 本文方法实验流程
4.1 实验数据及预处理
在京东商城选取10个不同种类的商品进行对比实验,如表1所示。在信息提取之前,对评论进行预处理:
(1)重复其他用户的评论,即有些用户直接复制的其他用户的评论。
(2)存在大量重复文字的评论,如:“好好好好好!!!”。
(3)存在大量特殊字符的评论,如:“A∗(¿]%好”。
(4)存在大量空白的评论,如:“东西很好 很给力”。
(5)重复自身的评论,如:“东西很好 东西很好东西很好 东西很好东西很好”。
对于(1)、(5)中的评论,采取去重的方法;对于(2)、(3)中的评论,直接将评论丢弃;对于4中的评论,除去空白。

表1 京东商城选取的10个商品
4.2 修正的召回率和F-Measure值
本文的任务是从海量评论数据中提出取对客户有用的信息,通常用准确率(precision)和召回率(recall)来评估提取的质量。并用F-Measure[12]值综合准确率和召回率2个数值,其中常用的是F1,它的定义如下:
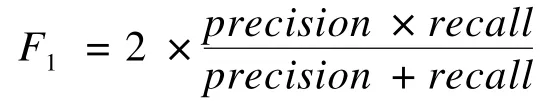
由于本文的实验数据规模太大,无法对所有评论进行人工标注,导致无法统计所有正确信息的数量,进而无法计算召回率。因此,设计了新的召回率计算公式,称为修正的召回率,即用2个进行比较的结果的正确部分的合并作为正确信息的全集,具体公式如表2所示。

表2 修正的查全率计算
本文把用新的召回率计算得到的F-measure值称为修正的 F-measure值,记为Fw,传统的 FMeasure值记为Ft。证明略,当满足条件C1≥C2时,下式成立:
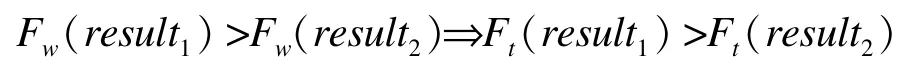
在下面实验的比较中,把本文方法提出的结果视为提取结果1,已有方法(比如京东商城的方法)提取的结果视为提取结果2。上面的结论说明,只要本文方法提取出足够多的正确信息,就能够保证修正的F-measure值的比较结果与传统的比较结果一致。
4.3 结果分析
本文对语义片段提取、种子词获取以及用户体验信息进行了实验结果的统计与分析。
4.3.1 语义片段提取实验
从Iphone4的评论中随机选取100条,经过人工挑选,从中找出62个语义片段,作为实验的“黄金标准”(Gold Stan-dard)。本文方法的提取结果如表3所示。

表3 本文方法的提取结果
表3结果表明,本文方法虽然不能保证较高的精确率,但能够保证非常高的召回率。这样的结果就能保证本文的语义片段提取损失尽可能少的信息量,也保证了本文最后提取出来的用户体验信息的全面性、完整性。
4.3.2 种子词获取实验
实验数据来自10种商品的全部评论,N的值设为5,实验结果如表4所示。其中,每个商品的评论中产生10个种子词,包括5个特征种子词和5个特征描述种子词,它们的正确性由人工评定。实验结果表明,本文方法准确率达到98%,基本可以替代人工提供的数据。
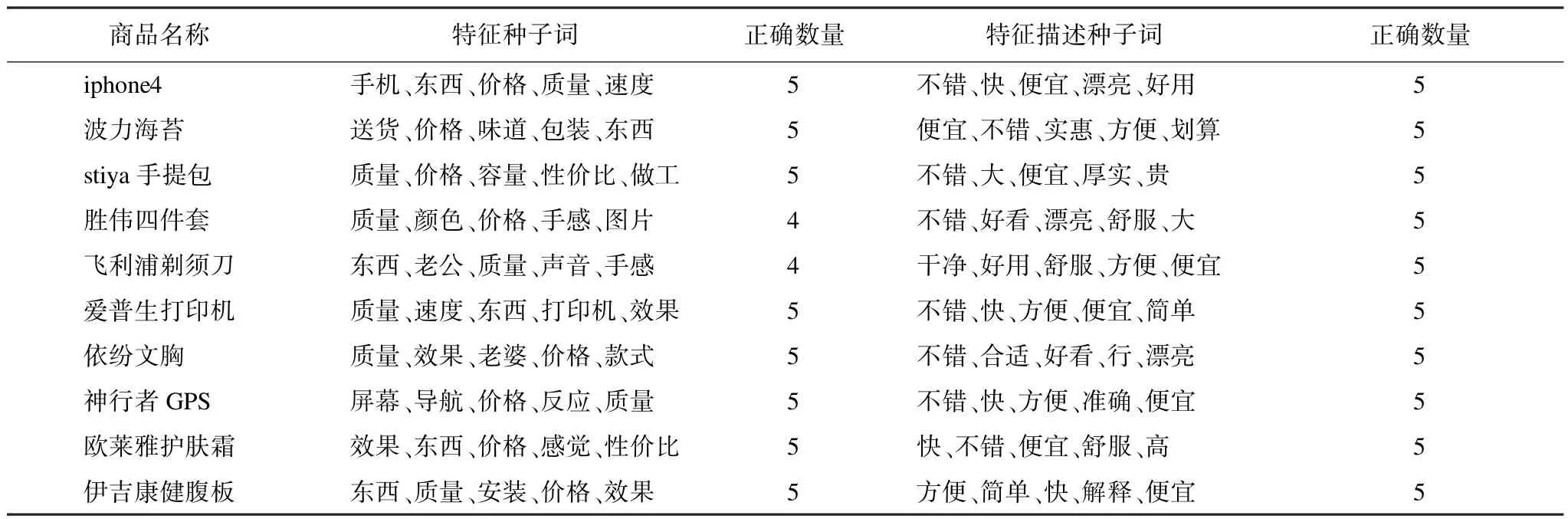
表4 种子词提取实验结果
4.3.3 用户体验信息提取实验
本文对10种商品的评论进行用户体验信息提取,结果与京东商城进行比较。京东商城的结果通过爬虫程序从评论接口获取,每个商品都获得一条体验信息。本文方法和京东商城的结果都由人工判断是否正确。实验结果如表5、表6所示。实验结果表明,在准确率上,本文方法与京东商城相差不大,但是在召回率上,本文方法远远优于京东商城。在最终F-Measure值评估上,本文方法无论是宏平均还是微平均都远远优于京东商城。
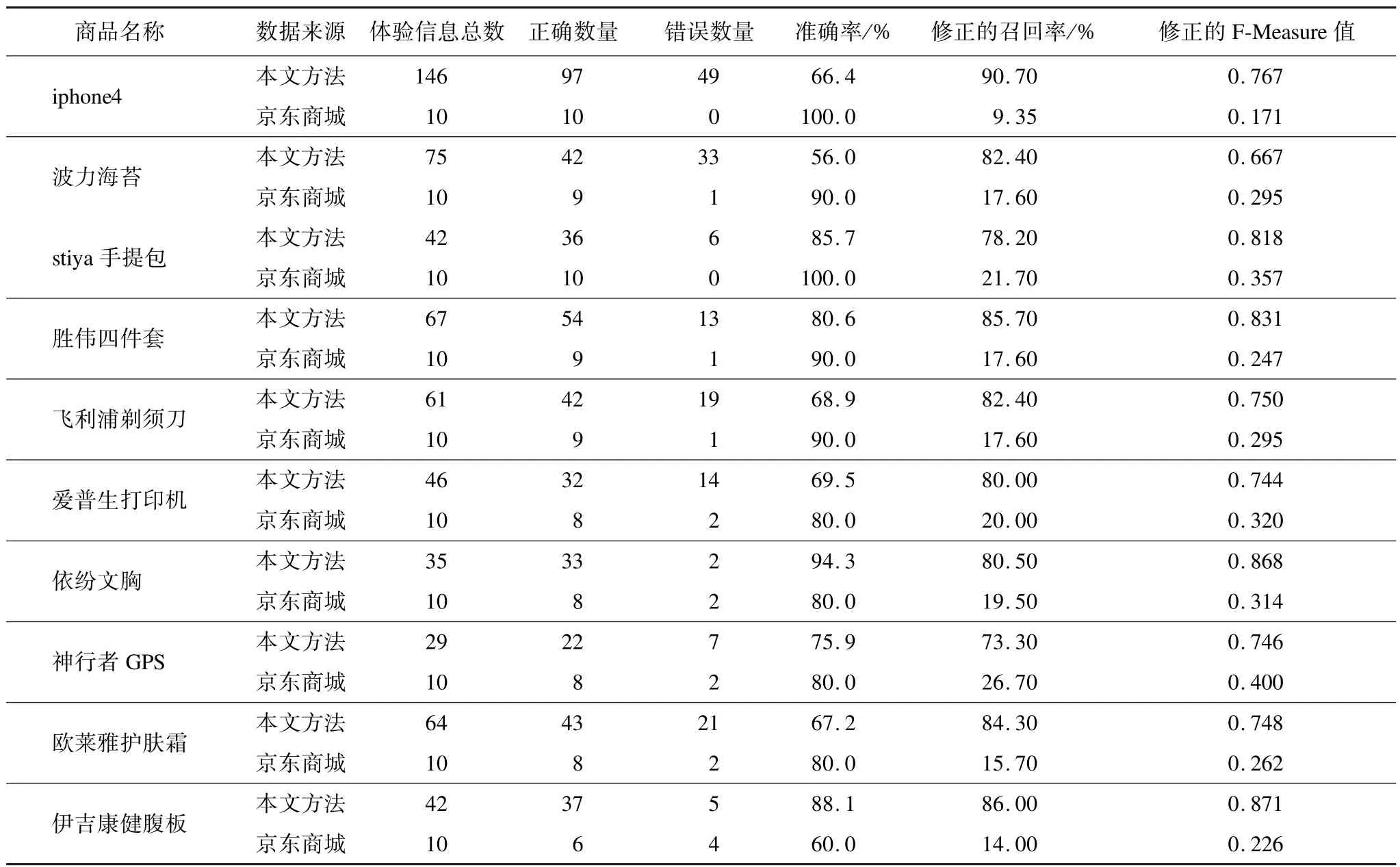
表5 用户体验信息提取结果对比
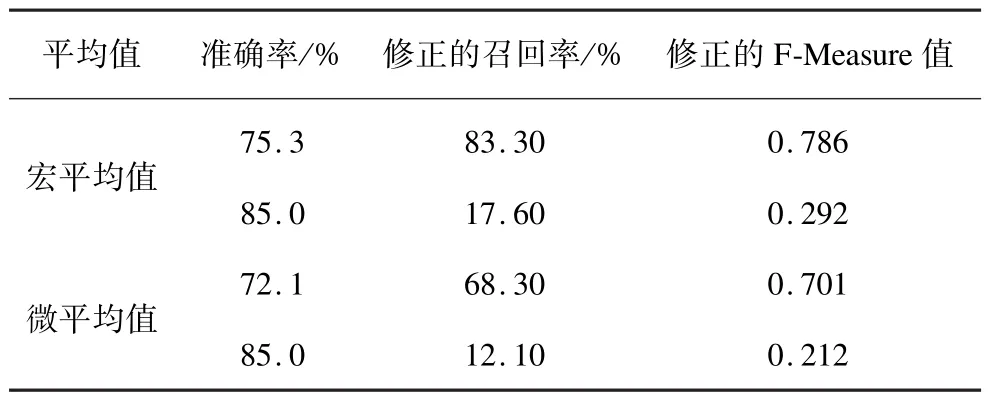
表6 宏平均值与微平均值结果对比
5 结束语
客户评论随着电子商务的发展起着越来越重要的角色,进而处理评论的技术要求也越来越高。现有方法依赖于人力,不能真正客观地从评论中提取信息。本文方法能够自动获取产品特征与特征描述词,并组成用户体验信息。实验证明该方法能够自动、全面、客观地从客户评论中获取信息。
[1] Kobayashi N,Inui K,Matsumoto J,et al.Collecting Evaluative Expressions for Opinion Extraction[C]// Proceedings of IJCNLP’05.Berlin,Germany:Springer, 2005:596-605.
[2] Li Zhuang,Feng Jing,Zhu Xiaoyan.Movie review Mining and Summarization[C]//Proceedings of the 15th ACM International Conference on Information and Knowledge Management.[S.1.]:ACM Press,2006:43-50.
[3] Hu Mingqing,Liu Bing.Mining Opinion Features in Customerreviews[C]//Proceedings ofthe 19th National Conference on Artifical Intelligence.San Jose, USA:AAAI Press,2004:755-760.
[4] Pang Bo,Lee L.Opinion Mining and Sentiment Analysis[J].Foundations and Trends in Information Retrieval,2008,2(1/2):1-135.
[5] Pang Bo,Lee L,Vaithyanathan S.Thumbs Up? Sentiment Classification Using Machine Learning Techniques[C]//Proceedings of ACL’02.[S.1.]: Association for Computational Linguistics,2002:79-86.
[6] 徐琳宏,林鸿飞,杨志豪.基于语义理解的文本倾向性识别机制[J].中文信息学报,2007,21(1):96-100.
[7] 朱嫣岚,闵 锦,周雅倩,等.基于hownet的词汇语义倾向计算[J].中文信息学报,2006,(1):14-20.
[8] Nasukawa T,Yi J.Sentiment Analysis:Capturing Favorability Using Natural language processing[C]//Proceedings of the 2nd International Conference on Knowledge Capture.Sanibel Island,USA:ACM Press,2003:70-77.
[9] 刘宏哲,须 德.基于本体的语义相似度和相关度计算研究综述[J].计算机科学,2012,39(2):8-13.
[10] Turney P D,Littman M L.Measuring Praise and Criticism:Inference of Semantic Orientation from Association[J].ACM Transactions on Information Systems,2003,21(4):315-346.
[11] 朱 杰,刘功申,陈 卓.中文文本倾向性分类技术比较研究[J].信息安全与通信保密,2010,(4):56-58.
[12] Makhoul J,Kubala F,Schwartz R,et al.Performance Measures for Information Extraction[C]//Proceedings of DARPA’99.[S.1.]:IEEE Press,1999:249-252.
编辑 索书志
Research on Information Automatic Extraction of User Experience from Customer Reviews
HU Lingchuan,TAO Xiaopeng
(School of Computer Science,Fudan University,Shanghai 201203,China)
Customer reviews are playing an increasingly important role in people’s daily lives,from which people want to obtain some information about user experience.However,with the continuous development of the Internet,it is pretty difficult for users to get the useful information in a rapid and accurate way.The common practice is to collect experience information manually or half-manually,and calculate the frequency of tem.This paper presents an automatic method to extract information about the user experience from customer reviews,it extracts product features and feature description through semantic segment filtering redundant information,and consists of user experience information,it implements information extraction rapidly and precisely.Abundant experiments show that this method is available and can guarantee very high precision and recall ratio.
customer reviews;feature mining;emotion analysis;semantic segment extraction;user experience;semantic similarity
1000-3428(2015)01-0049-05
A
TP391
10.3969/j.issn.1000-3428.2015.01.009
胡令传(1990-),男,硕士,主研方向:自然语言处理,机器翻译;陶晓鹏,副教授、博士。
2013-12-26
2014-02-27 E-mail:hulingchuan@hotmail.com
中文引用格式:胡令传,陶晓鹏.客户评论中用户体验信息自动提取研究[J].计算机工程,2015,41(1):49-53.
英文引用格式:Hu Lingchuan,Tao Xiaopeng.Research on Information Automatic Extraction of User Experience from Customer Reviews[J].Computer Engineering,2015,41(1):49-53.
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
开放教育研究(2020年2期)2020-03-31
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
自动化学报(2017年4期)2017-06-15
国防科技大学学报(2016年6期)2017-01-07
现代语文(2016年21期)2016-05-25
中文信息学报(2015年4期)2015-04-21
电测与仪表(2015年3期)2015-04-09
大连民族大学学报(2015年2期)2015-02-27
