
一种鲁棒自适应阈值的语音端点检测方法
2015-07-24 17:49张君昌
西安电子科技大学学报 2015年5期
张君昌,张 丹,崔 力
(西北工业大学电子信息学院,陕西西安 710129)
一种鲁棒自适应阈值的语音端点检测方法
张君昌,张 丹,崔 力
(西北工业大学电子信息学院,陕西西安 710129)
针对基于特征的语音端点检测方法在低信噪比及非平稳噪声下检测性能急剧下降的问题,提出了一种鲁棒自适应阈值的语音端点检测方法.采用表征较长时段语音谱平坦度的长时段语音谱平坦度特征,并融合Burg谱估计,与其他传统语音特征相比,提高了语音与噪声的区分度;能更准确地反映背景噪声特征,克服了固定阈值适应性较差的缺陷,从而更大程度上提高了检测的准确率.仿真结果表明,该方法在低信噪比及非平稳噪声下,检测准确率更高,说明该方法在低信噪比及非平稳噪声环境下鲁棒性更好.
低信噪比;非平稳噪声;语音端点检测;长时段信号谱平坦度;Burg谱估计
语音端点检测是指从一段带噪语音信号中区分出语音段和噪声段,准确地定位语音的起始点和结束点.它是语音识别系统的一个关键技术.有效的语音端点检测技术不仅能减少系统的处理时间、提高系统的实时性,而且能排除无声段的干扰,从而使后续的识别性能得以较大提高.端点检测的有效性在某种程度上甚至直接决定了整个识别系统的成败.
目前语音端点检测方法大致可以分为两大类:一类是基于模式识别的方法[1],因为其自身复杂度高,运算量大,因此很难在实时处理系统中使用;另一类是基于特征的方法[2-3],根据语音与噪声的不同特征来达到端点检测的目的,该方法以其简单、快速的优点被广泛地研究和应用.传统的基于特征的端点检测方法有很多,但都有其局限性[4],如:基于短时平均幅度的端点检测方法虽然简单,但难以区分弱摩擦音与结尾时的鼻音;基于短时平均过零率的端点检测方法虽然对清音的检测效果较好,但其抗噪声性能较差;基于谱熵的端点检测方法由于语谱的固有特征能够有效地区分语音和噪声,但对清音部分的检测效果较差,尤其是实际应用中的“毛刺”问题.后期,有学者提出了更复杂的结合多个特征的语音端点检测方法,如目前应用较广的基于谱熵、短时过零率与倒谱距离的检测方法,利用各自特征参数的优点,提高检测的准确率.但是,以上提到的语音特征都是在短时帧(20 ms)的基础上分析的,假定背景噪声在短时间内是稳定的,并且语音端点的判决也是在每一帧信号上进行的,这就导致了对应的端点检测方法在低信噪比,尤其是非平稳噪声环境下较差的检测性能.
近年来,Prasanta等人提出了基于长时段信号变化率测度(Long-Term Signal Variability measure, LTSV)的语音端点检测方法[5],该方法在信噪比低于5 d B环境下的检测性能有了一定的提高,在信噪比高于5dB环境下,其检测性能趋于饱和.为了更好地改善语音端点检测方法的识别性能,文献[6]提出了一种基于长时段信号谱平坦度(Long-term Spectral Flatness Measure,LSFM)特征的语音端点检测方法,该方法在一个长时窗(如30帧)下检测输入信号的谱平坦度特征,利用谱的变化特征来区分语音和噪声.该方法在低信噪比及非平稳噪声下的检测性能有了较大提高.然而,进一步的分析发现,文献[6]采用了经典的Welch谱估计法,其频率分辨率低,偏差较高,会导致语音与噪声的误分率提高,因而笔者提出了一种融合Burg谱估计与LSFM特征的语音端点检测方法,有效地降低了语音与噪声的误分率,在低信噪比及复杂噪声环境下检测性能更好,鲁棒性更强.
1 融合Burg谱估计与LSFM特征的语音端点检测方法
1.1 LSFM特征
LSFM特征参数在第m帧的值Lx(m)利用输入信号x(n)和包括本帧在内的前R帧信号的功率谱S(n, ωk)来计算.公式如下:

其中,G(m,ωk)与A(m,ωk)分别为功率谱S(n,ωk)的几何平均值与算术平均值,而信号的功率谱S(n,ωk)由谱估计方法得到.
当且仅当S(n,ωk)一直不变时,它的几何平均数G(m,ωk)和算术平均数A(m,ωk)才相等;在其他情况下,G(m,ωk)永远小于A(m,ωk).根据式(1),Lx(m)的范围为(-∞,0].
假设输入信号x(n)是平稳噪声,即x(n)=N(n),因为N(n)是平稳的,理想状态下噪声频谱不随时间变化,假定噪声谱已知SN(n,ωk)=σk,代入式(1),可得LN(m)=0.
如果输入信号x(n)为含加性平稳噪声语音,即x(n)=S(n)+N(n),假定噪声与语音是不相关的,输入信号的功率谱为SS+N(n,ωk)=Ss(n,ωk)+σk,其中Ss(n,ωk)为语音信号功率谱.由式(1)得

由式(2)知,输入信号的LSFM特征值与信噪比有紧密联系:如果信噪比RSNk(n)≪1,即认为输入信号为噪声情况,在任意频率点ωk处,则都有LS+N(m)≈0;如果含噪语音信号具有较高的信噪比,语音信号在不同频率处信噪比相差很大,则信号强度在不同频点处仍有较大波动,因此,LS+N(m)显著小于零.
当输入信号是非平稳噪声时,Lx(m)由噪声信号的类型及其非平稳度决定,理论分析变得很困难.然而,实验仿真表明:如果信号频谱S(n,ωk)随n的变化而幅度波动较小,那么Lx(m)趋近于零;如果S(n, ωk)在一些频点变化较大,在另外一些频点变化较小,那么Lx(m)会是较小的值;当x(n)=S(n)+N(n)时,输入信号在频点ωk处的功率谱S(n,ωk)由信噪比RSNk决定;含噪语音信号的LSFM值远小于噪声信号的LSFM值.因此基于LSFM特征的端点检测方法在非平稳噪声情况下同样具有较好的检测性能.
2.2 谱估计方法选择
一种有效的谱估计方法可以很好地估计出信号的功率谱,从而能更好地表征特征参数的区分性能.所以,谱估计方法的选择是影响语音端点检测结果的一个重要因素.谱估计方法分为两大类:经典谱估计和现代谱估计.现代谱估计是针对经典谱估计的方差性能较差、频率分辨率较低等缺点提出的,参数模型法是现代谱估计的主要内容,应用最广泛的是自回归(Auto Regressive,AR)模型,它是人们根据对过程的先验知识,建立一个近似实际过程的模型,然后利用观测数据或自相关函数来估计假设的模型参数,最后进行识别或谱估计.因为在这个过程中没有用到窗函数,所以,可以消除掉窗函数的畸变影响,得到比经典谱估计更高的频率分辨率.对比其他的AR估计方法,Burg法求出的AR功率谱密度估计非常逼近于真值.另外,它能确保产生一个稳定的AR模型,并且能高效计算.因此文中采用Burg算法进行谱估计.
2.3 融合Burg谱估计与LSFM特征语音端点检测判决
融合Burg谱估计与LSFM特征的语音端点检测方法的系统框图如图1所示.

图1 语音端点检测系统框图
输入信号首先用汉宁窗加窗分帧,汉宁窗宽度为20 ms,帧移10 ms,然后采用Burg谱估计估计输入信号的功率谱.在第l帧窗口上,Lx(l)由当前帧及前R-1帧信号计算得到,Lx(l)与判决阈值TTHR(l)相比较,初次判决前R帧信号是否为语音段.结果用Dl来表示,如果Dl=0,则说明结束于第l帧的前R帧信号是噪声段;如果Dl=1,则说明是语音段.
语音端点检测的最终判决如图2所示,因为帧移为10 ms,所以每10 ms会有一个L值,每10 ms会判决一次,在第l帧窗口上,总共采集R+1次判决Dl,Dl+1,…,Dl+R+1,然后这R+1次判决进行投票表决,如果有80%是语音段,则认为10 ms的帧移是语音信号,否则认为是噪声.

图2 语音端点检测系统端点判决
2.4 自适应阈值选择
需要说明的是,Lx(m)总是小于等于零,为了方便对比,选择作为观测值.
要确定在第m帧的判决阈值TTHR(m),进而来判断结束于第m帧的长时窗信号为语音还是噪声,这是一个统计决策问题.需要两个缓冲器BN(m)与BS+N(m),BN(m)存储在过去100个长时窗中初次判决为噪声的值,BS+N(m)存储在过去100个长时窗中初次判决为语音段的值.不失一般性,假定BN(m)与BS+N(m)均服从正态分布.

损失函数以误分率为基准,即要选择最佳的TTHR(m)使损失函数H取最小值,根据贝叶斯估计计算得最佳阈值为

在仿真试验中,取α=0.55时,检测的准确率最高.为了初始化阈值,采取如下方法:
得到第1个Lx(m)值需要R帧信息,即0.3 s.在实验仿真中,通常假设测试信号最初的1.3 s是背景噪声,这样就可以得到100个长时窗下初次判决为噪声段的值,存为BINL,同样假定其服从正态分布,令μN和分别为BINL的均值和方差.初始阈值设定为(仿真表明p=3性能最佳)

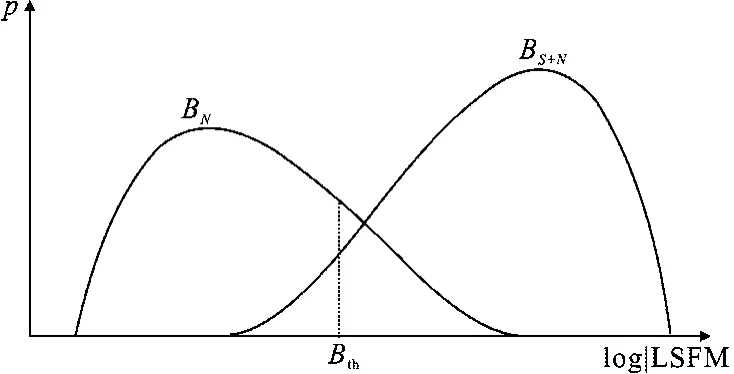
图3 BN(m)和BS+N(m)示意图
2 实验仿真及分析
为了说明该算法的可行性和优越性,在MATLAB平台上做了相应的实验仿真.随机地从TIMIT语料库中选择一段纯净语音,与采自NOISEX-92的5种不同类型的噪声(白噪声、pink噪声、汽车噪声、坦克噪声和机枪噪声)合成多段信噪比不同的含噪语音,然后利用不同方法对其中的语音端点进行检测.
汽车噪声环境下,信噪比为-10dB时,基于Welch谱估计与基于Burg谱估计的LSFM方法检测结果如图4所示.

图4 -10dB汽车噪声下基于两种谱估计的LSFM方法的检测结果
从图4可以看出,基于Welch谱估计的LSFM方法在采样点为0.84×104~0.90×104段内将噪声误判为语音,在采样点为1.64×104~1.68×104段内将语音误判为噪声,而基于Burg谱估计的LSFM方法则无误判.相比Welch谱估计,基于Burg谱估计的LSFM方法检测准确率明显提高.
通过实验仿真,统计出当信噪比为-10dB时,双门限法、LTSV法、基于Welch谱估计的LSFM法与基于Burg谱估计的LSFM法这4种语音端点检测方法在5种不同噪声环境下的检测准确率,如表1所示.

表1 4种方法在不同噪声类型下检测准确率(-10dB) %
为了能更好地说明问题,统计了当信噪比分别为-10dB,-5dB,0 B,5dB,10dB时,上述4种语音端点检测方法的检测准确率的平均值,如图5所示.

图5 不同端点检测方法对比
从表1与图5中可以看出,在低信噪比环境下传统的双门限法已经失效,LTSV法与基于Welch谱估计的LSFM法的检测性能有了较大提高,但显然基于Burg谱估计的LSFM方法更胜一筹,其对低信噪比下平稳噪声(白噪声)与非平稳噪声(汽车噪声、坦克噪声等)均有良好的检测性能,即使在机枪噪声环境下也能体现出其优越性,验证了基于Burg谱估计的LSFM方法在低信噪比及复杂噪声环境下进行语音端点检测的有效性和鲁棒性.
3 结束语
笔者提出了一种融合Burg谱估计与LSFM特征的语音端点检测方法,该方法采用Burg谱估计,提高了LSFM特征的区分度;并采用了一种自适应阈值,根据贝叶斯估计来调整判决段的阈值,进一步提高了检测的准确率.大量实验仿真表明:在低信噪比和非平稳噪声环境下,该方法的检测准确率达到了约88%以上,而传统基于特征的语音端点检测方法只有约70%,说明融合Burg谱估计与LSFM特征的语音端点检测方法在低信噪比及非平稳噪声下具有更好的鲁棒性.而值得注意的是,使用长时窗进行信号分析会造成语音端点判决的延时,因此在系统检测延迟与系统检测性能方面需要一个良好的折中方案,这也是下一步研究的重点.
[1]Suh Y,Kim H.Multiple Acoustic Model-based Discriminative Likelihood Ratio Weighting for Voice Activity Detection [J].IEEE Signal Processing Letters,2012,19(8):507-510.
[2]Yang X L,Tan B H.Comparative Study on Voice Activity Detection Algorithm[C]//Proceedings of IEEE International Conference on Electrical and Control Engineering.Piscataway:IEEE Computer Society,2010:599-602.
[3]Von Zeddelmann D.A Feature-based Approach to Noise Robust Speech Detection[J].ITG-Fachbericht,2012(236):243-246.
[4]江亮亮,杨付正,任光亮.利用两级时域联合的包层语音质量评价模型[J].西安电子科技大学学报,2013,40(3):14-19. Liangliang Jiang,Fu Zheng,Guangliang Ren.Packet-layer Model for Voice Quality Assessment Using Two-level Temporal Pooling Scheme[J].Journal of Xidian University,2013,40(3):14-19.
[5]Ghosh P K,Tsiartas A,Narayanan S.Robust Voice Activity Detection Using Long-term Signal Variability[J].IEEE Transactions on Audio,Speech,and Language Processing,2011,19(3):600-612.
[6]Ma Y N,Nishihara A.Efficient Voice Activity Detection Algorithm Using Long-term Spectral Flatness Measure[J]. EURASIP Journal on Audio,Speech,and Music Processing 2013,2013(1):21.
(编辑:王 瑞)
Robust adaptive threshold speech endpoint detection method
ZHANG Junchang,ZH ANG Dan,CUI Li
(School of Electronic Information,Northwestern Polytechnical University,Xi’an 710129,China)
Due to the fact that traditional Speech Endpoint Detection methods’performance degrads greatly in a low signal-to-noise ratio and nonstationary noise,a novel robust adatpive threshold endpoint detection method is proposed.First of all,the LSFM parameter is employed as the distinctive feature and the Burg spectrum estimation is applied to figure out the power spectrum,which can enhance the discriminative ability in classifying speech signals and noise,compared with the traditional speech features.Furthermore, an adaptive threshold based on the Bayes estimation criterion is involved in the final judgment,which overcomes the defect of the fixed threshold in adaptability and improves the detection performance to a greater degree.Simulation results show that compared with the traditional feature-based Speech Endpoint Detection methods,the accuracy of the proposed method has a high accuracy rate,which proves that the new method has a better robust performance in a low SNR and nonstationary noise.
low signal-to-noise ratio;nonstationary noise;speech endpoint detection;long-term spectral flatness measure;Burg spectrum estimation
TN702
A
1001-2400(2015)05-0115-05
2014-04-25< class="emphasis_bold">网络出版时间:
时间:2014-12-23
陕西省自然科学基金资助项目(2011JQ8038)
张君昌(1969-),男,副教授,博士,E-mail:zhangjc@nwpu.edu.cn.
http://www.cnki.net/kcms/detail/61.1076.TN.20141223.0946.020.html
10.3969/j.issn.1001-2400.2015.05.020
猜你喜欢
数学物理学报(2022年2期)2022-04-26
现代仪器与医疗(2022年1期)2022-04-19
数学物理学报(2020年3期)2020-07-27
北京航空航天大学学报(2019年9期)2019-10-26
中学生数理化·教与学(2019年8期)2019-09-18
微型电脑应用(2019年4期)2019-04-26
雷达学报(2017年3期)2018-01-19
计算机应用与软件(2017年3期)2017-04-14
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
装备环境工程(2015年1期)2015-02-06
