
个性化推荐算法设计研究
2015-09-18 02:32赵鑫
中国管理信息化 2015年8期
赵 鑫
(辽宁行政学院,沈阳 110161)
个性化推荐算法设计研究
赵 鑫
(辽宁行政学院,沈阳 110161)
全球信息总量疯狂增长,信息超载问题越来越严重。个性化推荐系统能够有效解决当前信息过载的问题,因此,个性化推荐算法设计研究具有重要意义。本文主要以个性化推荐系统的概念为出发点,对个性化推荐算法分类进行分析,最后阐述了个性化推荐算法常用的数据集。
个性化;推荐算法;协同过滤
由于网络数据正在快速的发展,人们能够接触到的海量的信息,例如,拥有数百万种独特商品的亚马逊,在Google Music曲库中,有上千万首歌曲,淘宝在线商品数量达到8亿件以上,腾讯微信用户以及新浪微博用户都超过5亿以上,这些用户很难在海量的信息中找到自己喜欢的信息,也就是所谓的“信息过载(information overload) ”的问题,而推荐系统和搜索引擎是解决此问题的关键技术,和搜索引擎相比较,用户更喜欢使用个性化的推荐系统,这是由于个性化推荐系统能够主动的对用户浏览过的日志、注册的信息以及历史评分记录等方面进行分析,从而找出用户更感兴趣的项目特征,然后对用户感兴趣的信息进行私人定制,根据用户项目信息和用户需求,对推荐的内容和信息的变化进行及时的调整,实现“以用户为中心”的服务。对个性化推荐算法进行设计,能够有效的解决当前信息过载的问题,让用户更快捷、方便的进行对信息的搜索和浏览。
1 个性化推荐系统的概念
个性化推荐系统主要根据用户喜好特点以及拥有的购买行为,从而自动的推荐用户有兴趣的商品或者是信息。这种系统的出现是由于电子商务规模的扩大,使商品数量以及信息等都在上涨,用户在这种情况下,需要用大量的时间才能够找到自己喜欢的信息,因此,为有效的解决这个问题,个性化推荐系统就此诞生。也就是说,个性化推荐系统是一个拥有在大量数据中挖掘的能力,从而形成的高级智能商务平台,能够帮助电子商务网站为顾客提供的完全个性化的信息服务以及决策支持。如图1所示。
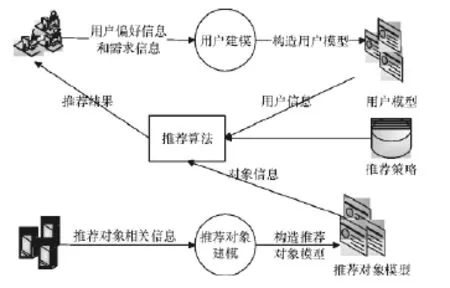
图1 推荐系统模型
2 个性化推荐算法的分类
推荐系统是利用信息源给用户进行预测和项目推荐,在整个过程中,具有重要的作用。根据信息的不同。比如,信任度、标签、人口统计信息等,以及对评价指标的考虑。
2.1基于内容的推荐算法
这种推荐法也称为基于内容的信息过滤推荐(content-based recommendation),基于内容的推荐算法不需要用户对推荐对象给予评价,但是要把推荐对象的特征进行抽取出来,从用户以前所选择的对象内容去感应用户的偏好,然后用于偏好相似的对象推荐给用户。其效用函数( u,c)可表示为f( u,c) = score( ContentBasedProfile(u) ,Content(c))。Score 可以用二者的余弦相似度进行计算。最后用所得到的函数值对其进行排序,将最前面的项目当做推荐对象。该算法的推荐结果虽然符合用户的喜好,但是缺乏新颖度。
2.2协同过滤推荐算法
该算法是根据系统里其他用户的历史数据或者评分记录(比如,亚马逊用户购买商品的记录),协同过滤推荐( collaborative filtering recommendation)是当今最为流行的一种算法,目前,主要的协同推荐技术有两种,一种是基于模型的协同推荐,一种是基于内存的协同推荐,基于模型的协同推荐是通过历史数据预测模型,然后通过模型参与评分预测,后者是使用历史记录数据进行的预测模型,它们的不同是由于客户的偏好。
2.2.1基于模型的推荐算法
项目数量及用户规模的增长,致使出现数据集稀疏的问题愈加严重,比如,Netflix的影评数据集就缺失大约99%的数量,因此,基于内存的协同算法要将大规模的增长,而且,由于数据出现稀疏的现象,推荐结果的质量就会产生下降的趋势。基于模型的推荐算法( model-based collaborative filtering),其中心思想就是利用客户的评分结构进行评分预测模型,从而使用了数据挖掘计算模型和多种计算学习,通过模型实现对评分的预测。
2.2.2基于内存的协同推荐算法
根据对基于内存协同推荐的考虑角度的不同,可以将其分为基于用户( User-based) 和基于项目 ( Item-based) 的协同推荐。基于内存的协同推荐( memory-based collaborative filtering)也叫做启发式的协同推荐,能够对用户的历史数据进行分析从而提供预测结果,比如,用户-影评矩阵。在 User-based 模型中,用户间相似度能够选择不同的相似度函数来计算。
3 个性化推荐算法常用的数据集
3.1Netflix 数据集
这种数据集主要是来自电影网站的Netflix,这个网站有480 189位用户对17 770部电影进行了共有100 480 507条的评分记录,数据区间为[1,5]的离散整数值,与MovieLen 评分有所不同,Netflix目前是全球规模最大的电影评分数据集,但由于该比赛已经结束,因此,该数据集目前已不对外开放。
3.2腾讯微博数据集
在2012年,由于数据挖掘与知识竞赛(KDD-Cup),因此,腾讯微博数据集形成,此数据集是在腾讯4.25亿微博用户中,经过50天的数据采样得到的。该数据集有6 000万信息员或被推荐用户、300多万收听动作和3亿多条推荐记录,该数据集的规模现已超过原来的 KDD Cup比赛。
3.3Yahoo! 音乐数据集
该数据集主要包含了用户对专辑、单曲、歌手等不同音乐元素进行评分,对于评分的区间是0-100之间的证书,一共涉及624 961个音乐元素,1 000 990 个用户,262 810 175条评分记录。
3.4CiteULike 数据集
该数据集是由施普林格出版社( Springer)提供协助用户管理、存储及分享学术文章的网站,用户可以根据自己感兴趣的论文,给它们打上标签,从而可以在专门的地方查找到,并且还能够为其他选择论文的朋友提供依据。CiteULike 公布了包含给论文打标签和收藏论文的数据集,其中,这个数据集有1 793 954篇论文、52 689个用户和2 119 200个用户与论文间的关系。
4 结 语
个性化推荐在电子图书、电子商务等领域被广泛的应用着,随着个性化推荐系统的不断的变化,推荐算法逐渐暴露出越累越多的缺点,有待解决。因此,对个性化推荐算法设计进行研究,不仅能够实现完善个性化推荐系统,同时还能够促进企业的可持续发展,进而为社会做出贡献。
主要参考文献
[1]赵亮,胡乃静,张守志.个性化推荐算法设计[J].计算机研究与发展,2012(8):986-991.
[2]余力,刘鲁,李雪峰.用户多兴趣下的个性化推荐算法研究[J].计算机集成制造系统,2013(12):1610-1615.
[3]陈洁敏,汤庸,李建国.等.个性化推荐算法研究[J].华南师范大学学报:自然科学版,2014(5):8-15.
10.3969/j.issn.1673 - 0194.2015.08.059
TP301.6
A
1673-0194(2015)08-0078-02
2015-02-09
猜你喜欢
高技术通讯(2021年5期)2021-07-16
科学大众(2020年23期)2021-01-18
文苑(2020年4期)2020-05-30
当代陕西(2019年13期)2019-08-20
汽车观察(2019年2期)2019-03-15
新闻传播(2018年12期)2018-09-19
汽车与新动力(2016年6期)2017-01-04
中国卫生(2016年5期)2016-11-12
中国卫生(2015年1期)2015-01-22
生物进化(2014年2期)2014-04-16
