
基于聚类分析和决策树算法的服装销售预测模型
2015-09-18 07:36孙晓静
中国管理信息化 2015年9期
孙晓静,高 慧,陈 云
(上海财经大学a.信息化办公室;b.信息管理与工程学院,上海200433)
基于聚类分析和决策树算法的服装销售预测模型
孙晓静a,高慧b,陈云a
(上海财经大学a.信息化办公室;b.信息管理与工程学院,上海200433)
服装生产企业需要了解市场需求的变化趋势,以做出正确的生产和销售决策。因此,对服装销售状况进行准确的预测,成为企业有效制定发展战略的重要依托。服装的销售受销售渠道、地域、文化、经济等众多因素的影响,呈现复杂的非线性特征,导致需求预测难度较大。本文综合考虑各种影响因素,结合聚类分析和CART决策树算法构建销售预测模型,既实现了较高的预测精度,又可转化为易于理解的规则。最后以某服装运营企业为例验证了方法的有效性和可解释性。
服装销售预测;系统聚类;CART决策树
0 引言
在多元化竞争的服装市场上,顾客对服装需求的多变性也使企业常常同时面临畅销产品短缺和滞销产品积压的问题。服装销售除了受到销售渠道数量、分布等企业自身营业状况的影响,还受到地域、气象、文化、经济等多种因素的影响,导致难以对市场需求加以准确预测,无法对运营决策提供有效支持。
目前对销售额预测的研究主要可以分成两类。一类是基于个人判断法或德尔菲法的定性预测。个人判断法即销售管理人员基于个人经验,对销售量进行预测。此类方法往往以销售、管理人员对销售数据的主观判断为基础,受较多人为因素的影响,缺乏客观性和可靠性。另一类是基于现有数理模型的定量预测方法,有移动平均法、指数平滑法、季节性指数法、一元回归或多云回归法、时间序列模型预测、马尔科夫链预测模型等。
随着研究的深入,研究者们开始采用不同的定量方法实现需求的预测,如Haper提出的德尔菲法是一种专家预测方法;Richard B.Chase提出的移动平均法是利用移动平均数消除偶然性因素的影响来进行预测;R.G Brown提出的指数平滑法是根据更近的经验不断修正预测值的方法;John Neter提出的回归模型则运用回归方程式来进行预测等[1]。此外,如在《基于时间序列和PERT的服装销售预测方法研究》[2]一文中从服装销售的实际特点出发,通过引入PERT模型和时间序列模型,借鉴两模型的各自优势,实现了对销售必然性和偶然性预测的有机结合,用完全量化的时间序列模型克服了预测过程中对历史数据的主观性判断。喻琳艳在《需求随机型服装产品的灰色预测模型》一文中将服装需求分为需求确定型、随机型和季节型,提出运用灰色控制理论有关预测的理论[3],针对需求确定型和随机型服装产品建立预测模型,避免了以往仅凭经验进行管理的盲目性,得到了较好的预测结果。薛美君、沈剑剑、杨以雄在《服装销售定量预测方法新探》一文中对受季节销售影响敏感且有较长销售周期的服装销量进行预测,采用季节因子处理数据,结合最小二乘法进行时间与销售量的统计分析[4],建立时间和销售量之间的函数关系,此方法对预测服装企业未来销售需求有较好的准确度。通过分析国内外服装销售预测的研究状况,不难发现目前关于预测方法方面的研究已经比较完善,但是预测方法的研究大多偏重于将多种预测方法综合运用得出最后的预测值。然而对于服装企业的管理者来说,关注的另一个焦点是哪些因素影响了销售额,而上述模型在销售影响因素上没有做相关分析。
针对此不足,本文首先结合服装业特点,从地域、文化、经济、气象、企业发展等角度寻找影响销售的不同因素,然后用系统聚类法实现销售数据的聚类,即将企业的历史销售数据按照企业关注的类别进行相应的聚类,最后运用CART算法建立影响因素与目标销售额之间的分类规则,进而运用规则对销售进行预测。
此方法不仅可以有效预测服装销售需求,而且易于转化为关联规则,帮助管理者了解服装销售的主要影响要素,制定合理的生产、营销策略。
1 系统聚类法和CART算法
系统聚类法是目前使用最多的一种聚类方法。决策树学习是以实例为基础的监督归纳学习算法,通过一组无次序、无规则的实例推理出决策树表示形式的分类规则,其中最著名的决策树算法有ID3、C415、CART等[5-10]。考虑到本模型的输入数据集并不完全服从某类特定分布,而且不同指标体系对应的数据类型也不同,既有连续变量又有离散变量,因此采用CART算法[10]。
系统聚类算法能够对服装销售中的目标销售额进行聚类,并能得到较好的结果,将此结果作为CART决策树算法的输出。然后寻找与目标销售额相关的外界影响因素与企业内部的影响因素,将这些因素作为决策树的输入。运用CART算法形成影响因素与目标销售额之间的分类规则,最后运用规则对销售进行预测。
2 基于聚类和决策树的服装销售预测模型
2.1整体模型
为了更有效地配置现有资源,实现企业利润最大化,需要借助科学的方法分析不同销售网点所处的具体市场环境,针对不同的市场环境制定不同的销售额指标,同时对各类市场环境下,不同网点的未来销售额进行预测。
决策树算法可以通过对输入数据的分析,在学习的基础上得到分类规则,因此,可以先寻找与目标销售额相关的外界影响因素与企业内部的影响因素,将这些因素作为决策树的输入,运用决策树算法形成影响因素与目标销售额之间的分类规则,从而帮助管理者了解目前的销售受到了哪些外部因素的影响。同时,还可以运用已有规则对未来市场的销售进行预测。
基于上述分析,本文提出了聚类分析与决策树算法相结合的销售预测模型。该方法首先从服装的整体销售入手,通过聚类分析,将历史记录中的人均销售额分组,结合企业实际分析要求,划分成3大类区间,表示销售业绩的“可观,一般,较差”3个层级;然后建立包括地域因素、经济因素、文化因素以及企业自身因素等一系列可能对销售产生影响的属性集合,决策树将这些属性和从聚类中得到的3大销售区间联系起来,得出属性集合与人均销售额之间的关联规则;最后通过决策树就可以将未来销售网点的人均销售额和用属性描述的销售原型联系在一起,预测出未来属性发生变化时所对应网点的人均销售额,以此指导管理者进行科学的决策。整个模型主要包括聚类分析,建立指标体系和建立决策树模型3步,主要流程如图1所示。

图1 基于聚类分析和决策树算法的服装销售预测模型流程图
(1)聚类分析:运用系统聚类法对研究时期内对应的人均销售额进行聚类,形成若干类销售区间,作为决策树模型的分类目标;
(2)建立影响因素指标体系:寻找影响服装销售的各类影响因素,即包括各类外部影响因素,也包括企业自身的影响因素,建立完善的影响因素指标体系;
(3)建立决策树模型:将影响因素对应的属性向量作为决策树模型的输入,人均销售额的聚类区间作为决策树的分类目标,训练决策树模型,挖掘出影响因素和人均销售额之间的关联规则,用建立的规则对新网点的人均销售额进行预测,同时通过对最终决策树的分析,指导企业分析市场环境。
2.2基于聚类分析的销售数据聚类分析模型
本文使用系统聚类法实现销售需求的聚类。聚类过程主要包括3个步骤:距离计算,合并聚类,决定类的个数和类,整个过程如图2所示。

图2 系统聚类过程图
2.2.1距离计算
计算N个销售数据任意两者间的距离 {dij},即销售额的差值,记为D={dij},构造N个类,每个类中只有1个样本,其中:

xi表示第i个销售额,xj表示第j个销售额,i,j∈(1,2,…,N)。
2.2.2类的合并
对以上数据用平均距离法进行聚类分析。平均距离法是将类与类之间的距离定义为两类中所有样品对之间的平均距离,假设用G表示某一类,即本项目中的销售区间。G中有k个元素,i、j表示G中第i、j个因素;令Gp和Gq中分别有p和q个样品,类与类之间平均距离D(p,q)定义为Gp和Gq中所有两个样品对之间距离的平均。可以根据式(2)计算类之间的平均距离,然后将平均距离最近的两类进行合并,得到新类,再计算新类与各类直接的平均距离,依次重复,直至所有样本聚类完毕。

式中,i、j表示G中第i、j个销售额;令Gp和Gq中分别有p 和q个销售额数据。
2.2.3类个数的确定
Milligan(1984)和Cooper(1985)提出了以下3个最好准则:①伪F统计量;②伪统计量;③立方聚类准则CCC。通过判断这3个值在聚类数为多少时达到峰值来选择类的个数。
2.2.4聚类结果
通过上述方法,企业的N个历史销售记录可以聚成K类(K≤N),每一类代表一个销售区间,对应不同的销售情况,表示为Ω∈{SCL1,SCL2,SCLK}。
2.3基于决策树算法的销售需求预测模型
本文采用CART决策树模型实现影响因素和销售区间之间的映射,挖掘出两者之间的关联规则。具体流程如图3所示。

图3 CART决策树模型流程图
2.3.1训练和测试数据集的建立
对于经营品牌的企业,其直接销售的是产品商标,经过生产厂商和各级经销商最终售给消费者。因此,企业当前的商标销售量反映的是后续时期的市场需求。因此,本文将T时期的影响因素与T+1时期的销售区间配对,形成数据集T={Ai,SCLi+1},i∈[1,2,…,N]。其中,Ai表示第i时期的属性向量,SCLi+1表示第i+ 1时期的销售情况,N表示历史数据的总时间长度。然后,选取其中的TRD个数据作为训练数据,则剩余的N-TRD个为测试数据。
2.3.2销售影响因素获取
本项目综合考虑了影响销售的地域角度、气象角度、文化角度、经济角度和企业角度,确定了各类因素所对应的具体属性集合。根据文献《地域性文化影响下的服装分析》《浅谈地域差异对服装设计的影响》《我国女装市场营销环境分析及评价研究》,《女性品牌服装消费心理的实证研究》《浅谈地域差异对服装设计的影响》以及企业自身关注的指标。综上可得本文中所提出的44个影响因素属性集合(见表1),表示为Ai=(A1,A2,…,A44)。
2.3.3决策树的训练
采用数据集T中的TRD个训练数据对决策树进行训练,以第i时期的销售影响因素Ai为输入,以第i+1时期的销售类SCLi+1为输出,得到一棵初始决策树。
其中,CART决策树的分支生成规则如下:从众多的输入属性Ai中选择GINI系数最小的一个或多个属性,作为树节点的分裂变量,把测试变量分到各个分枝中,重复该过程建立一棵充分大的分类树,然后用剪枝算法剪枝,得到一系列嵌套的分类树,最后用测试数据进行测试,选择最优分类树。其中GINI系数的计算公式如下:
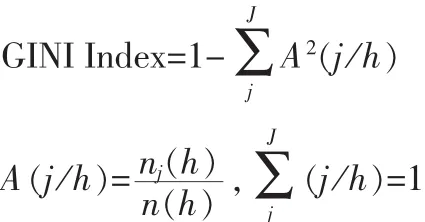
A(j/h)是从训练样本集Ai中随机抽取一个样本,当某一测试变量值为h时属于第J类的概率;nj(h)为训练样本中测试变量值为h时属于第J类的样本个数;n(h)为训练样本中该测试变量值为h的样本个数;J为类别个数。
2.3.4冗余因素删选
如果初始决策树将所有的影响因素均筛选出来,则说明不存在冗余因素;此时,需要分析预测精度是否理想,如果不理想,则需要调整初始属性集合,可以通过增减属性,逐次进行实验,观察预测精度是否提高。
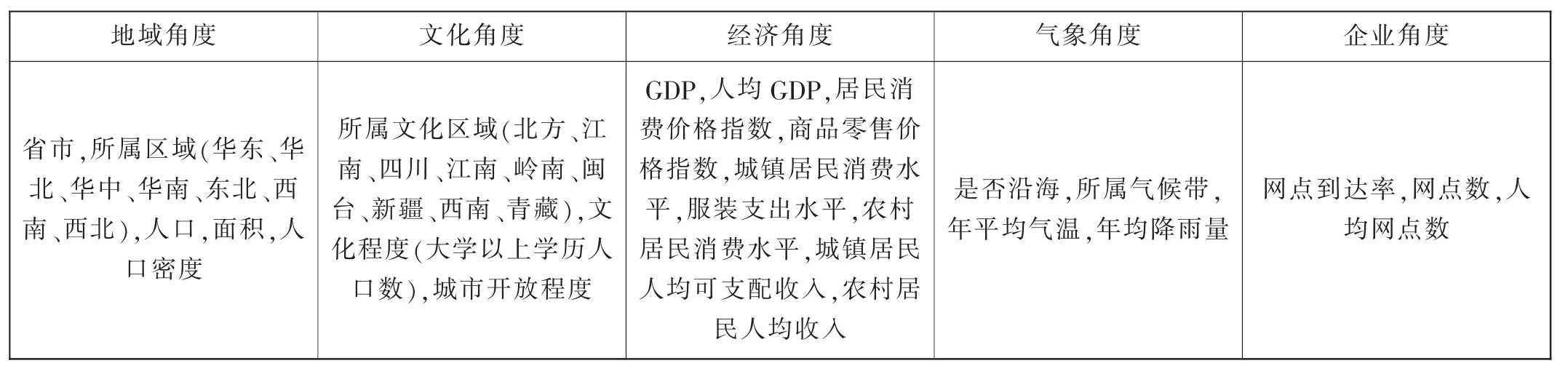
表1 销售影响因素
如果初始决策树未将全部的影响因素筛选出来,说明原始属性集合中存在冗余因素,此时需要进一步观察表1中对应的各个角度,如果整个角度内的所有因素均未被筛选出来,说明该角度内所有因素对规则的形成均不起作用,删除整个角度;如果所有角度内均有属性被筛选出来,说明各个角度均对规则形成起作用,此时各个角度内未被筛选出来的属性即为冗余属性,继而按照各个角度逐次去掉冗余属性,并观察每次改进后的预测精度是否提高,直至删除四大角度内的所有冗余因素。然后观察预测精度是否理想,如果不理想,则通过增加属性或者增加其他角度,重复上述步骤进行实验,直至到达理想预测精度。
2.3.5最终决策树的生成
使用所有的数据进行训练,形成对样本解释度最高的决策树。根据该决策树进行预测和相关分析。
3 实证分析
本项目中针对某知名绒线厂家的销售情况进行分析,运用系统聚类分析与CART决策树算法相结合的销售预测方法。该方法首先从绒线产品的人均销售入手,通过聚类分析,将历史记录中的人均销售额划分成“可观,一般,较差”3个层级;然后建立包括地域因素、经济因素、文化因素以及企业自身因素等一系列可能对销售产生影响的属性集合,CART决策树将这些属性和从聚类中得到的3大销售区间联系起来,得出属性集合与人均销售额之间的关联规则,并用不同年份的销售数据进行测试,检验决策树的预测精度;最后用所有的数据进行训练和测试,得到一棵完全解释树(如图4),对企业目前的市场销售进行分析解释。

图4 最终决策树
对最终决策树的分析如下:
(1)对企业销售起重要影响的因素包括是否属于江南区域(上海,江苏,浙江,安徽,江西,湖南,湖北),网点到达率,人均网点数,人均GDP等因素;
(2)运用这棵树进行人均销售额的预测,一方面,当获取第N年的影响因素的所有数据后,将其做为这棵决策数的输入数据集,即可得出新的规则,从而帮助预测出新的不同规则下对应的销售区间;
(3)这棵树通过对影响因素与人均销售额的关联分析,挖掘出一系列的规则,这些规则对企业更好地了解当前市场环境有重要的指导意义。
4 结论
影响因素的多变使得服装销售的预测越来越复杂。本文提出了一种基于聚类分析和决策树算法的服装销售预测模型。聚类分析将销售额进行分类,决策树找到了影响因素和销售额之间的关联规则,基于规则对未来的销售进行预测,构成了本文的销售预测模型。通过实证分析,该模型的预测准确率与其他预测模型相比有了很大的提高。然而,在决策树的分类中出现了一些错误,这些错误的产生是由于对服装销售影响因素的掌握不充分造成的。考虑到服装销售市场的复杂性,可以将决策树算法与其他算法相结合,如遗传算法,神经网络等智能算法,这些算法有待于进一步的讨论。
主要参考文献
[1]Celia Frank,Ashish Garg,Amar Raheja,et al.ForecastingWomen’s Apparel Sales Using Mathematical Modeling[J].International Journal of Clothing Science and Technology,2003,15(2):107-125.
[2]万艳敏,陈胜,戴淑娇.基于时间序列和PERT的服装销售预测方法研究[J].丝绸,2006(11).
[3]喻琳艳.需求随机型服装产品的灰色预测模型[J].国际纺织导报,2006(8):78-80.
[4]薛美君,沈剑剑,杨以雄.服装销售定量预测方法新探[J].东华大学学报,2004,30(6):75-77.
[5]刘栋,宋国杰.面向多维时间序列的过程决策树模型[J].计算机应用,2011,31(5):1374-1377.
[6]汪海锐,李伟.基于关联规则的决策树算法[J].计算机工程,2011,37 (9):104-109.
[7]琚春华,肖亮.基于地域因素的连锁商业分布式决策树算法[J].系统工程理论与实践,2011,31(6):1126-1133.
[8]刘映池,张毅.运用系统聚类法对高校学生进行分类[J].教育与教学研究,2009,23(9):69-70.
[9]张琳,陈燕,李桃迎,牟向伟.决策树分类算法研究[J].计算机工程,2011,37(13):66-70.
[10]陈辉林,夏道勋.基于CART决策树数据挖掘算法的应用研究[J].煤炭技术,2011,30(10):164-166.
10.3969/j.issn.1673-0194.2015.09.031
F270.7
A
1673-0194(2015)09-0064-04
2015-01-29
猜你喜欢
生活用纸(2022年12期)2023-01-25
玩具世界(2021年3期)2021-08-23
玩具世界(2021年3期)2021-08-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
电子设计工程(2015年6期)2015-02-27
