
神经网络球磨机出力软测量模型的建立
2015-09-22 02:05韩良云陆金桂
动力工程学报 2015年11期
韩良云, 陆金桂
(南京工业大学 机械与动力工程学院,南京211800)
球磨机作为制粉系统的重要组成部分,在锅炉系统中被广泛应用,其系统用电量约占电厂用电量的15%,是电厂主要耗电源之一[1].因此要降低电厂电耗,必须考虑球磨机制粉系统的优化.球磨机运行优化的目标是制粉单耗最小,即要求球磨机耗电量与球磨机出力之比最小[2].球磨机的耗电量可以通过电表直接测得,而球磨机出力一般难以直接测量,需采用间接方式得到.目前已有学者在这方面有过研究,采用的方法有:差压法、噪声法、功率法、油压法和应变[3-5]等.但上述方法都是依据单一的信号判断球磨机出力,而制粉系统是一个多变量耦合、非线性对象,因此,用单一的变量等效系统出力存在很大缺陷.软测量是一种基于多变量的测量方法,其建立了可测变量与难以直接测量量(即难测量量)之间的关系,通过可测变量反映难测量量.软测量的建模过程包括可测变量的选取、训练样本的选取及模型的建立.
训练样本的选取对软测量模型有着较大的影响.若选取的样本点在设计区域内没有代表性,则建立的软测量模型测量精度难以达到要求,对球磨机制粉系统的运行优化也有很大影响.采用最优拉丁超立方法选择建模所需的样本点,可以大大提高选取样本点的均匀性和代表性[6].
笔者基于最优拉丁超立方法选取样本点,采用BP神经网络建立了球磨机出力软测量模型,建模和验证的结果表明该方法的有效性.
1 灰熵关联分析[7]
灰色系统是由邓聚龙教授在1982年创立的一门学科,主要应用于研究对象数据量小、信息不全面、影响因素较多时的影响因素分析.灰熵关联分析方法的基本思路是根据序列曲线几何形状的相似程度来判断因素间联系的紧密性,曲线越相似则序列间的灰熵关联度越大,反之则越小.灰熵关联分析的步骤如下:
(1)定义原始数据.
为便于用数学表达式表示,将参考序列设为X0={x0(1),x0(2),…,x0(n)},比较序列设为 Xi={xi(1),xi(2),…,xi(n)},i=1,2,…,m.
(2)数据无量纲化.
因为各数据列单位一般不相同,因而不宜用来直接比较,为保证分析结果的准确性,对数据的预处理十分必要.采用归一化方法将每组数据同时除以每组数据的第一个数据,具体表达式如下:
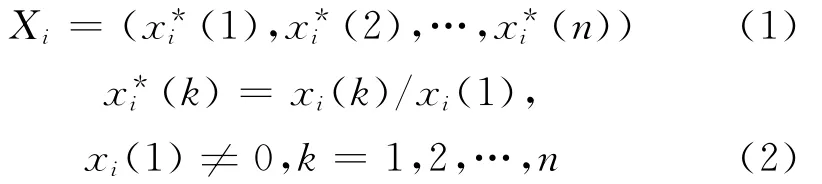
(3)灰关联差异序列.
灰关联差异序列的计算是将无量纲化后的参考序列与比较序列作差后取绝对值.表达式为:

(4)灰关联度的计算.
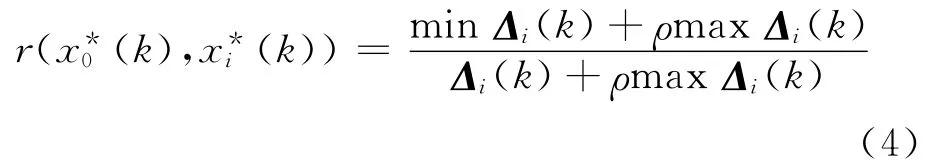
式中:r为灰关联度;ρ为分辨系数,ρ∈[0,1],一般取0.5;minΔi(k)表示矩阵Δi(k)中的最小值,maxΔi(k)表示矩阵Δi(k)中的最大值.
(5)分布密度值的计算.
计算分布密度值时,首先计算灰关联系数矩阵,然后根据式(6)计算其分布密度值.
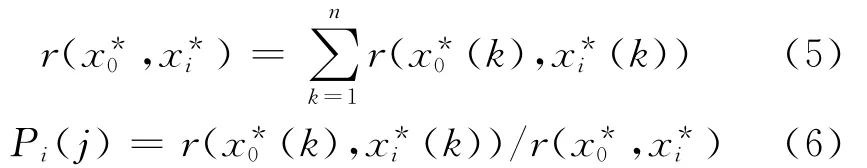
(6)计算灰熵.
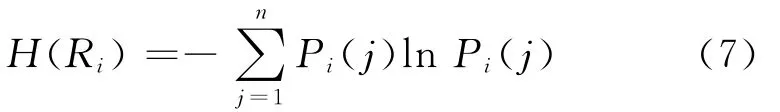
(7)计算灰熵关联度.
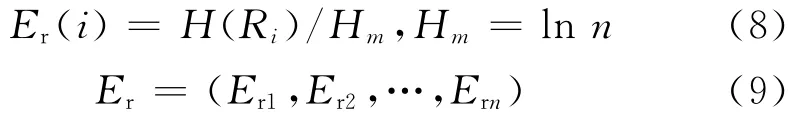
最后对Eri从大到小进行排序,Eri较大的即对指标影响较大.
2 模型建立
2.1 最优拉丁超立方法
软测量模型的建立不需要对球磨机制粉系统的先验知识有很深的理解,但需要一定量的数据作为训练样本.采用最优拉丁超立方法选取训练样本.
拉丁超立方法的基本原理是在m维空间中,将每一维的坐标区间[,],k∈[1,m]均匀地划分为n 个小区间,每个小区间记为,i∈[1,n].在形成的小区间内随机选取n个点,以保证每个因子的每个水平在试验中仅被研究一次,这就构成了m维空间、样本数为n的拉丁超立方法,记为n×m拉丁超立方法.因此,利用拉丁超立方法选取的样本点可以有效地填充样本选取空间,其采样点分布见图1.但拉丁超立方法也有其自身的弊端,如无法重复试验,一定程度上存在试验点分布不均匀的现象,且随着试验样本数的增加,丢失设计空间中一些区域的可能性也会随之增加.
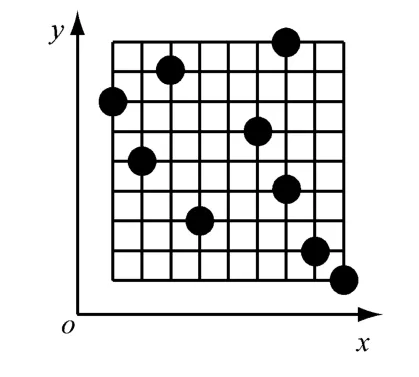
图1 拉丁超立方法Fig.1 Latin hypercube design
最优拉丁超立方法在随机拉丁超立方法的基础上改进了其均匀性,使因子和响应的拟合更加精确,选出的样本点均匀地分布在设计空间中,具有很好的空间填充能力和均衡性.其计算流程如下:(1)首先用上述随机拉丁超立方法生成初始设计矩阵;(2)通过元素交换的更新操作产生新的设计矩阵;(3)依据极大极小距离准则计算空间填充最优化条件;(4)判断矩阵是否满足最优化条件,不满足则采样改进随机演化算法,搜索全局最优解.最优拉丁超立方法的样本点分布见图2.
2.2 BP神经网络
BP神经网络是一种3层前向型网络,包括输入层、隐含层和输出层.网络上下层之间实现权连接,而每层神经元之间没有连接.输入参数正向传播,误差逆向传播.
神经网络模型结构如图3所示,设输入层输入向量为 X=(x0,x1,…,xm),其中任一输入信号用xi表示;隐含层有n个节点,其中任一神经元用yj表示;输出层有p个节点,其中任一神经元用zk表示;输入层与隐含层之间的连接权值用uij表示(i=0,1,…,m;j=0,1,…,n),隐含层与输出层之间的连接权值用vjk表示(k=0,1,…,p),则神经网络参数传递过程可表示为:
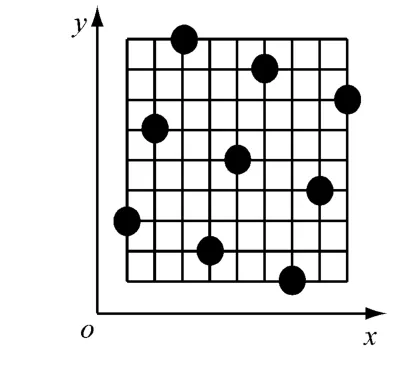
图2 最优拉丁超立方法Fig.2 Optimal Latin hypercube design

隐含层输出
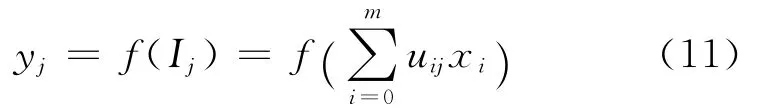
其中,f()表示隐含层的传递函数.输出层输入

输出层输出
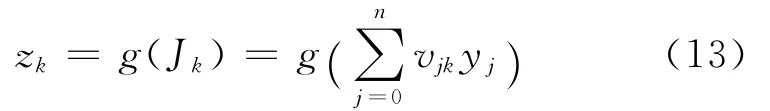
其中,g()表示输出层的权值.
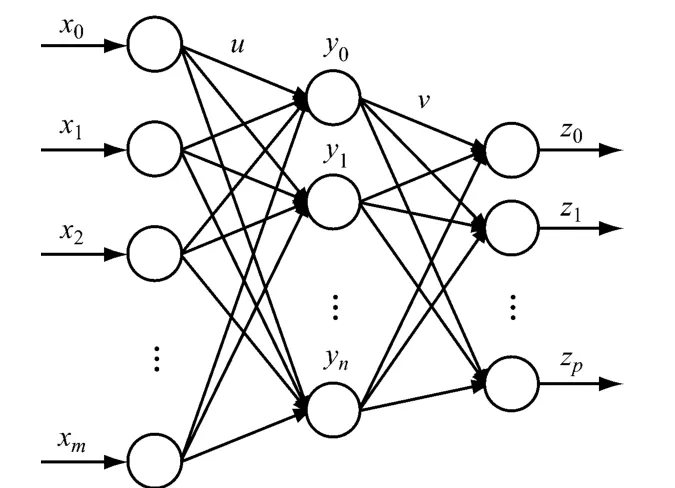
图3 三层神经网络结构Fig.3 Neural network with three-layer structure
3 球磨机出力软测量建模实例
3.1 软测量建模策略
球磨机制粉出力软测量建模过程如下:
(1)根据球磨机制粉系统的运行特性及相关文献介绍确定球磨机制粉出力的影响因素.
(2)数据的采集与预处理.从南京某电力公司现场采集相关数据用来建模,并删除这些数据中变化较大的数据.
实际的工作中,地质工程投资时非常复杂的,会受到多方面因素影响,上述安全投资模型是在特定条件下建立的,和地质工程实际情况具有一定的差距。但是实际工作中我们能够以这一模型作为借鉴,从而提升投资的科学有效性,降低其风险。比如,地质工程成本中包含有形成本和无形成本,如事故发生后引发的执政危机,因此,政府相关部门会强制性的要求相关企业在左右决策点的右部进行投资,以便于进一步确保工程的安全性。
(3)用灰熵关联法分析出力影响因素,选择对出力影响较大的因素用于建模.当用于建模的变量过多时会引起过学习现象,变量过少时会引起欠学习现象.因此,选择合适的建模变量数可以提高软测量的测量精度.
(4)采用最优拉丁超立方法,在影响因素的设计范围内选取样本点,建立试验设计表.由于随机法选择的试验样本点不具有代表性,当预测样本不在训练样本范围内时,模型的预测结果会出现较大偏差.最优拉丁超立方法选取的样本点拥有很好的均匀性与代表性[6],从而保证测量结果的精度.
(5)从采集的数据中选择合适的数据代替试验设计表中的数据.由于条件限制,生成的样本数据无法进行现场试验,即生成的样本点仅有输入量而无法得到输出量.因此,利用最优拉丁超立方法产生的样本点不能直接用于建模.笔者通过作差计算从采集的数据中选择与试验设计表数据差值最小的数据,代替原试验设计表中的数据.
(6)确定BP神经网络结构.
(7)基于BP神经网络建立球磨机制粉出力软测量模型.
(8)利用所建立的数据验证模型的测量精度.
3.2 辅助变量的确定
根据球磨机制粉系统的运行特性、相关文献介绍[8]及实际测量条件,在南京某电力公司选择的测量量为:球磨机入口一次风压力、入口一次风温度、入口一次风体积流量、出口风粉混合物温度、出口风粉混合物压力、球磨机电流以及给煤量.由于球磨机出力无法直接测量,当制粉系统处于稳态工况时,其给煤量与球磨机出力近似相等,因而在对球磨机制粉系统影响因素分析及出力软测量时,将球磨机的给煤量等效为球磨机出力.
从采集的数据中随机选取10组数据作为灰熵关联分析的数据,如表1所示.灰熵关联分析计算结果见表2.从表2可以看出,对球磨机出力影响最大的因素是出口风粉混合物压力,其次分别是入口一次风压力、入口一次风体积流量、球磨机电流、入口一次风温度和出口风粉混合物温度.分析结果与文献[8]和文献[9]的结果相类似,验证了分析结果的可靠性.为简化软测量模型的复杂程度,在建立软测量模型时,选择对球磨机出力影响最大的前5个因素作为辅助变量,即出口风粉混合物压力、入口一次风压力、入口一次风体积流量、球磨机电流和入口一次风温度.
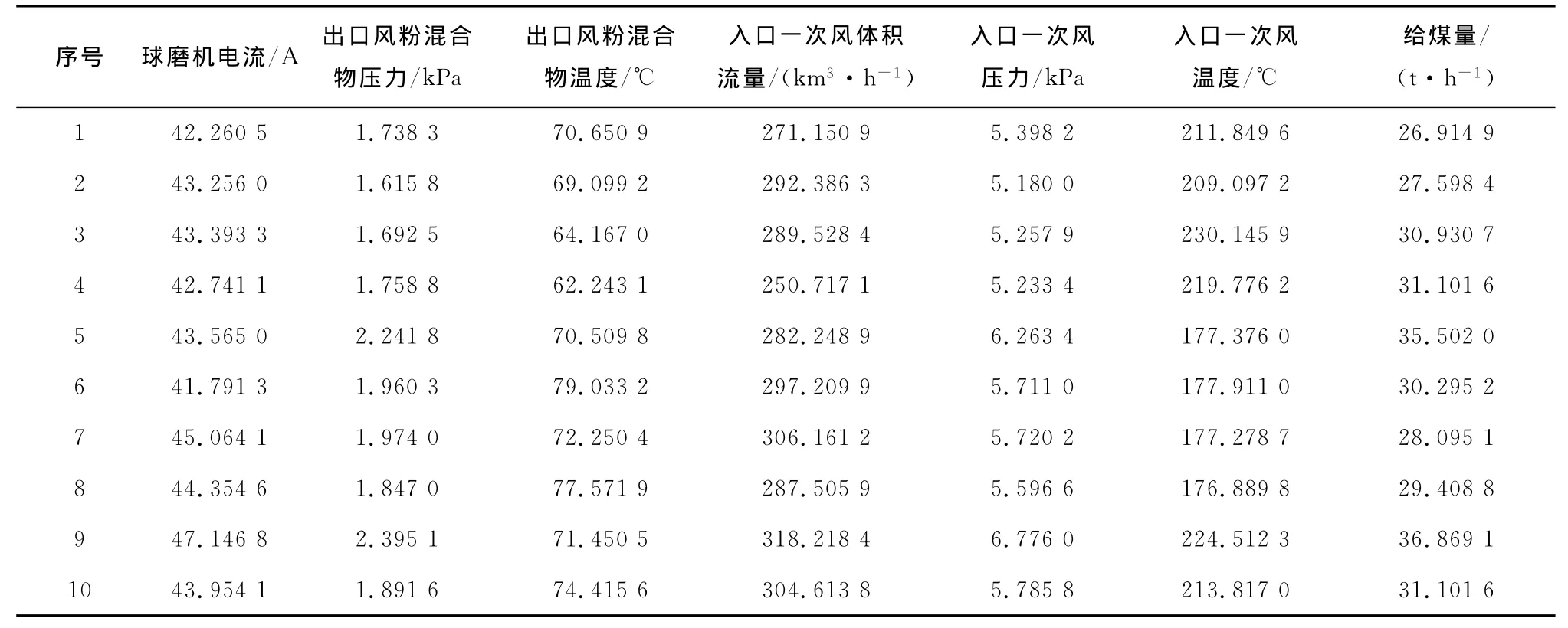
表1 影响因素分析数据Tab.1 Analysis results of various influencing factors

表2 灰熵关联分析结果Tab.2 Analysis results by grey entropy correlation method
3.3 软测量样本点的选取
利用最优拉丁超立方法在各影响因素的设计区域内选取样本点,然后从现场采集的数据中选择相关数据代替原设计数据,具体步骤为:(1)确定辅助变量的个数及范围;(2)依据最优拉丁超立方法选点规则在设计区域内得到试验设计表;(3)将上述试验设计表的第i(i=1,2,…,n)组数据与采集的所有样本数据分别作差;(4)同组数据的差值相加;(5)选择其中差值最小的一组数据代替试验表的第i组;(6)将已经选择过的数据从采集的数据中删除,以免新生成的试验设计表存在重复的数据;(7)重复步骤(1)~步骤(6)完成试验设计表中其他数据的替换,直至所有数据替换完成.
球磨机制粉出力影响因素较多,上述灰熵关联分析确定的5个辅助变量的设计范围即为采集数据的最大值和最小值的区间,如表3所示.
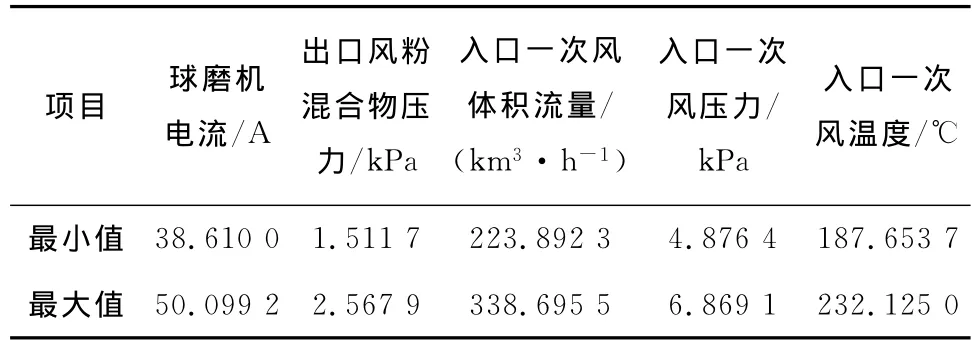
表3 设计变量范围Tab.3 Scope of design variables
利用最优拉丁超立方法在设计范围内选出样本点,然后从采集的数据中依照上述规则选出符合条件的样本点代替原数据.新生成的训练样本见表4.
3.4 软测量模型的建立与误差分析
神经网络的第一层为输入层,其节点数由输入参数的个数确定;第二层为隐含层,相关文献已证明只要隐含层节点数足够多,单隐含层的神经网络就可以映射所有的连续函数.
隐含层节点数的选择是一个复杂的问题,与研究的对象、输入和输出节点数有直接的关系.与隐含层层数相类似,若隐含层节点数太少,则神经网络获取的解决问题的信息量就会太少,不利于神经网络的预测;若隐含层节点数太多,则会增加样本训练的时间,有时也会导致“过学习”现象的出现,从而导致神经网络泛化能力下降.因此,参考式(14)选择隐含层的节点数.由于模型输入层节点数为5,经过计算隐含层节点数取11.

式中:h为隐含层节点数;n为输入层节点数.
BP神经网络的激活函数采用S型函数,函数表达式如下:
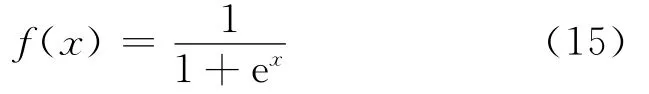
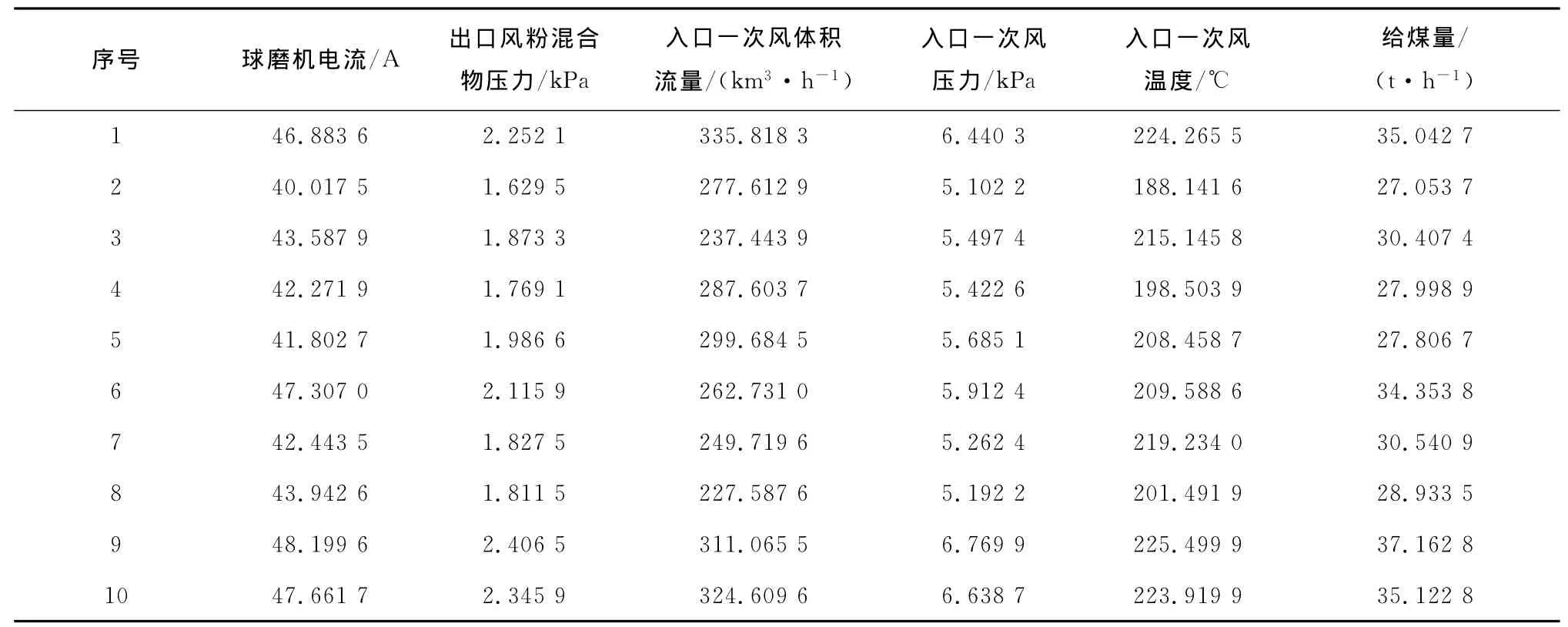
表4 软测量训练样本Tab.4 training samples of soft sensor
依据上述BP神经网络的结构设置,选用表4中前7组数据作为训练数据,建立球磨机制粉出力的软测量模型.最后3组数据作为验证数据,来验证数据预测分析结果,如表5所示.
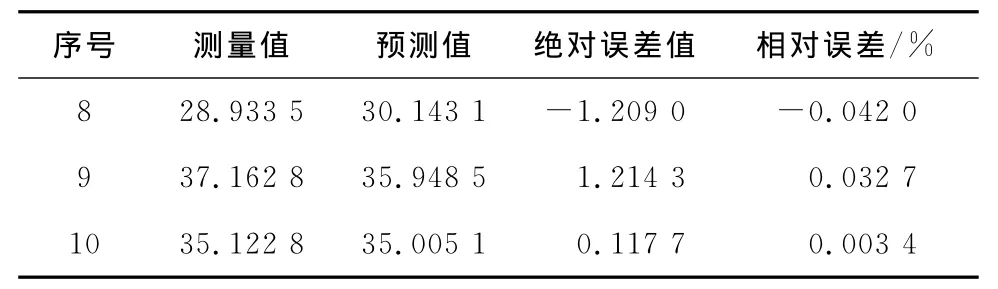
表5 验证数据预测分析结果Tab.5 The prediction results of validation data
由表5可知,当用建立的软测量模型验证3组数据时,预测结果相对误差的最大值为-4.2%,最小值仅有0.34%,验证数据相对误差均在较小范围内.由此可见,基于最优拉丁超立方法选取训练样本并利用BP神经网络建立的球磨机制粉系统软测量模型具有很好的预测性能.
4 结 论
针对火电厂球磨机制粉出力难以直接测量的问题,首先利用灰熵关联分析法分析了球磨机制粉出力的影响因素,选取球磨机出口风粉混合物压力、入口一次风压力、入口一次风体积流量、球磨机电流和入口一次风温度5个对制粉出力影响较大的因素作为软测量模型的辅助变量.然后利用最优拉丁超立方法从现场采集数据中选出训练样本,基于BP神经网络建立球磨机的制粉出力软测量模型,并用验证数据验证了模型的效果.结果表明,所建立的模型具有很好的预测能力.
[1]王恒,贾民平,陈左亮.基于LS-SVM和机理模型的球磨机料位软测量[J].电力自动化设备,2010,30(7):92-95.WANG Heng,JIA Minping,CHEN Zuoliang.Soft measurement based on mechanism model and LS-SVM for fill level of ball mill[J].Electric Power Automation Equipment,2010,30(7):92-95.
[2]郝勇生,于向军,赵刚,等.基于改进粒子群算法的球磨机运行优化[J].东南大学学报(自然科学版),2008,38(3):419-423.HAO Yongsheng,YU Xiangjun,ZHAO Gang,et al.Optimization for ball mill operation based on improved particle swarm optimization algorithm [J].Journal of Southeast University(Natural Science Edition),2008,38(3):419-423.
[3]KANG Enshun,GUO Yugang,DU Yuyuan,et al.Vibration signal processing and analysis in ball mill[C]//Proceedings of the 6th World Congress on Intelligent Control and Automation.Dalian:Institute of Electrical and Electronics Engineers,2006.
[4]张怡强.功率(电流)法对球磨机煤位的控制与应用[J].华东电力,2001,29(7):48-49.ZHANG Yiqiang.Power (current)method for the control and application of coal mill[J].East China Electric Power,2001,29(7):48-49.
[5]KOLACZ J.Measurement system of the mill charge in grinding ball mill circuits[J].Minerals Engineering,1997,10(12):1329-1338.
[6]赖宇阳.Isight参数优化理论与实例详解[M].北京:北京航空航天大学出版社,2012:95.
[7]张岐山,郭喜江,邓聚龙.灰关联熵分析方法[J].系统工程理论与实践,1996(8):7-11.ZHANG Qishan,GUO Xijiang,DENG Julong.Grey relation entropy method of grey relation analysis[J].System Engineering-Theory and Practice,1996(8):7-11.
[8]苏志刚.球磨机制粉出力的软测量研究[D].南京:东南大学,2006.
[9]赵珊珊,白焰.神经网络模糊多模型软测量在球磨机存煤量测量方面的应用[J].动力工程学报,2011,31(10):745-750.ZHAO Shanshan,BAI Yan.Application of fuzzy multi-model soft sensor in mill load measurement based on neural network [J].Journal of Chinese Society of Power Engineering,2011,31(10):745-750.
猜你喜欢
防爆电机(2022年2期)2022-04-26
今日自动化(2022年1期)2022-03-07
石油化工建设(2019年6期)2020-01-16
电子制作(2019年20期)2019-12-04
VOGUE服饰与美容(2019年4期)2019-06-11
现代面粉工业(2018年6期)2018-02-14
快乐作文·低年级(2017年9期)2017-10-11
现代工业经济和信息化(2016年8期)2016-05-17
出版与印刷(2015年1期)2015-12-20
新疆钢铁(2015年1期)2015-11-07
