
基于高斯混合模型的音乐情绪四分类研究
2015-10-12 02:18陆阳郭滨白雪梅
长春理工大学学报(自然科学版) 2015年5期
陆阳,郭滨,白雪梅
(长春理工大学 电子信息工程学院,长春 130022)
基于高斯混合模型的音乐情绪四分类研究
陆阳,郭滨,白雪梅
(长春理工大学电子信息工程学院,长春130022)
针对音乐情感复杂难以归类的问题,提出了一种在四分类坐标下建立高斯混合模型进行音乐信号归类的研究方法。在建立模型的基础上,创新地为表示情绪特性的轴两端建立模型使其转换成二层分类器进行加权判别。结果表明,为表示情绪特性的轴建立模型且权值分配在0.7和0.3的条件下,音乐的分类工作可以取得最优结果,其结果明显优于直接为每类情绪建立模型的结果。
高斯混合模型;音乐情绪分类;加权判决
随着计算机网络等一系列新兴媒体的到来,音乐逐渐渗透到我们日常生活中的各个角落。所以在海量信息的环境下,人们迫切需要对音乐信号进行有效的识别和管理。但是由于音乐信号的旋律多变性,频率复杂性等特点,使我们无法准确地描述一首音乐到底属于哪种类别。针对这种情况,结合前人研究的成果,本文对音乐信号进行简单的四分类研究,并进行了两种判别方法的比较。
本文使用的四分类模型图如图1所示,根据Thayer模型[1]转换而来。图中,纵轴代表音乐情绪能量和强烈的程度的指标(Arousal),横轴代表音乐情绪的正面或负面的指标(Valence)[1],由此形成了简单的四分类坐标系。如图所示,把音乐信号归为平静、悲伤、激动、愉快四种典型的音乐情绪风格。在此分类模型下,再进一步使用高斯混合模型实现音乐的归类。

图1 音乐情绪四分类模型图
1 高斯混合模型及EM算法
1.1高斯混合模型简介
高斯混合模型(Gaussian mixture model,GMM)是一种经常被用来描述混合密度分布的模型,即多个高斯分布的混合分布模型。在处理分类问题时,它能简单而有效地体现同一类内数据在特征空间中的分布特点,即同一类内的数据在特征空间中的分布既具有分散性又具有聚合性[2]。所谓聚类,就是按照一定的标准将事物进行区分和分类的过程。这一过程可以是无监督的,即在此过程中没有任何关于分类的先验知识,仅仅靠事物之间的相似性作为划分类的标准。聚类分析则指的是用数学的方法研究和处理给定对象的分类问题,它是一个将数据集划分为若干聚合类的过程,它将相似度较高的数据对象划分为一类,而将相似度较低的数据对象区分成其他类。
高斯混合模型是由单一高斯概率密度函数引申而来的,由于高斯混合模型能够平滑地近似模仿任意形状的密度分布情况[3],因此近年来经常被用于语音、图像识别等方面,并且取得了良好的效果。可以用提取到的音乐特征,通过训练特征获取模型参数的方法获得不同情绪类别的特征模板,然后进行音乐样本的分类判断。
在高斯混合模型中,待聚类的数据可以看成是来自于多个正态分布的混合概率分布聚合而成,而这些正态分布代表着不同的类,所以通常可以采用各个正态分布的相关参数(均值、权值与协方差)作为类的参数。
混合高斯模型的概率密度函数可以用式(1)表示:

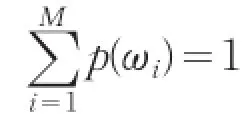

N(X;μi;∑i)为每个子分布的P维联合高斯概率分布,如式(3)表示:

由于音乐的特征参数通常具有平滑的概率密度分布,所以有限数目的高斯密度函数足以对音乐的特征参数形成一种平滑逼近。适当地选择高斯混合模型的均值、协方差和概率权重,可以完成对一个概率密度分布模型的建模。为了简化计算,通常可以使协方差矩阵∑i为对角阵,以减少需要估计的未知变量的数目,而且不影响最后结果。本文的音乐情绪建模过程依托于高斯混合模型,用各个高斯分布的参数来表示音乐特征的统计特性[4]。
1.2Expectation-Maximization算法
高斯混合模型的模型参数λ通常可以使用一组训练数据,按照某种准则来求出,使得到的高斯混合模型的模型参数能够最好地描述给出的训练数据的概率分布。这就是最大似然估计(Maximum Likelihood)的思想。首先可以假设 X=为给定的用于训练的特征矢量序列,而GMM的似然度可表示为,训练的目的是为了寻找能使P(X|λ)最大的一组λ。由于高斯混合模型的计算量较大且参数λ通常为非线性函数,因此本文采用的求解方法是Expectation-Maximization算法。
Expectation-Maximization(EM)算法是一种从不完全数据或有数据丢失的数据集中求解出模型分布参数的一种最大似然估计方法。通常在下列两种情况下,应该考虑用EM算法去估计参数:一是由于观测过程本身的限制或错误,造成了观测数据的丢失;二是参数的最大似然函数直接求解十分困难,通过假设隐含数据的存在并且引入隐含数据,使得函数的优化可以变得容易。在模式识别领域的问题中,后一种情况更为常见。这时就需要引入隐含数据和原来的不完全数据组成新的完全数据。高斯混合模型的参数估计求解就属于第二种情况。
EM算法是一种递归最大似然算法,是从一组训练样本序列中来估计模型的参数。求解过程通常分为两步:第一步是要假设知道各个高斯模型的参数(可以初始化一个,或者用Kmeans方法设置),去估计每个高斯模型的权值;第二步是基于现有估计出来的权值,再去确定高斯模型的参数。重复这两个步骤,直到波动很小,也就是近似地达到极值,以此来估计模型参数。
EM算法迭代的过程(第n+1步)如下:
混合权值重估迭代公式
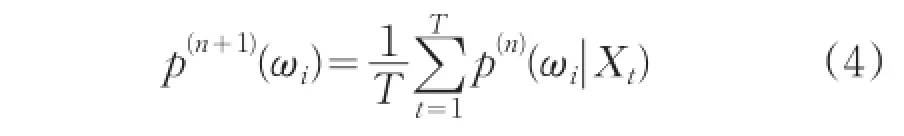
均值重估公式

方差重估公式

三个公式中的后验概率p(n)(λi|Xt),表示为:
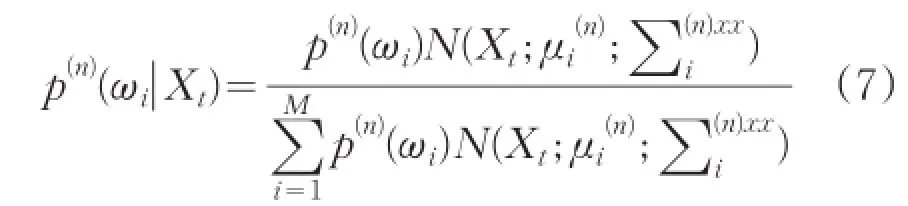
以上公式执行了求期望(E步)和最大化(M步)。对EM算法中的E步、M步不断重复迭代,当找到似然函数的极大值时停止迭代,此极大值通常即为所求结果。
2 音乐信号的特征提取
为了能真实有效的反应出音乐信号跟情绪有关的特征,本文提取了共37维特征用于实验。
2.1梅尔倒谱系数(MFCC)
人耳听觉是一个复杂的非线性的系统,针对不同的频率人耳展现出不同的灵敏度。其中对音频中低频的响应是线性的,对高频部分的响应则近似于对数响应[5]。除此之外,MFCC也具有对卷积信道失真进行补偿的能力[6]。
Mel频率与实际频率的数值计算关系可以表示为:

MFCC的求解步骤通常如下:
(1)计算之前要确定好每帧的帧长和帧移,对每帧数据进行预加重,然后进行离散傅里叶变换,计算模的平方得出离散功率谱S(n)。
(2)使用临界带通滤波方法,采用个数为M个的三角滤波器组Hm(n),利用之前的公式,将实际频率转化到梅尔频率上。再计算S(n)经过了这一滤波步骤之后的功率值,得出N个参数pm。
(3)计算pm的自然对数,得到mj。
(4)对mj计算离散余弦变化,得到梅尔倒谱系数。
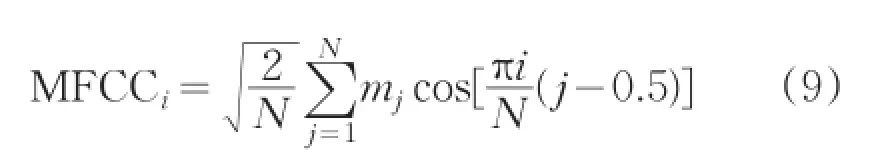
式中,MFCCi表示第K个MFCC,N代表带通滤波器的个数,mj是带通滤波器输出幅值取平方的对数。通常的MFCC只表现了语音的静态特征,如果想要描述语音的动态特征则可以计算MFCC的一阶差分。研究结果表明,MFCC能够较好的作为音频分类的特征并且能够提高音频分类的精确度[7]。MFCC的参数K通常取到12~16,根据实际需要灵活改变。根据之前学者研究的经验,本文MFCC的K取值为13。
2.2短时时域特征
2.2.1短时能量
音乐信号的能量随时间的变化明显,一般清音的能量要比浊音的能量小很多。音乐的短时能量分析,为这些幅度的变化规律提供了一个和适当的描述方法[8]。离散后的音乐信号x(n)的短时能量定义为:
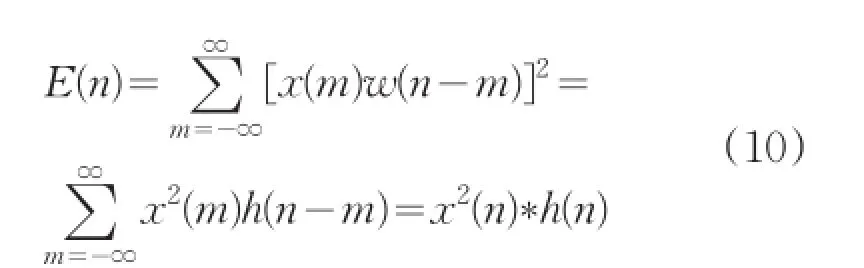
式中h(n)=w2(n)。所以,短时信号可以看成是一个信号的平方通过一个滤波器的输出。
2.2.2短时平均过零率
短时平均过零率是音乐时域分析中最常用的一种特征参数,它是指平均每帧信号内通过零值的次数,其实质是音乐信号采样点符号变化的次数。其公式为:
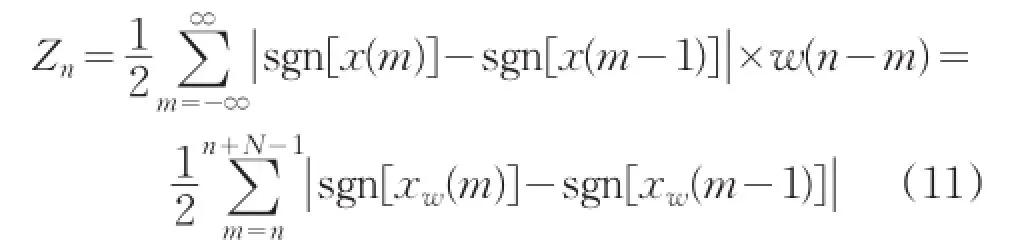
式中sgn[*]是符号函数。
2.2.3短时自相关
短时自相关是音乐采样信号的第n个样本点附近用短时窗截取一段信号,其公式定义为:
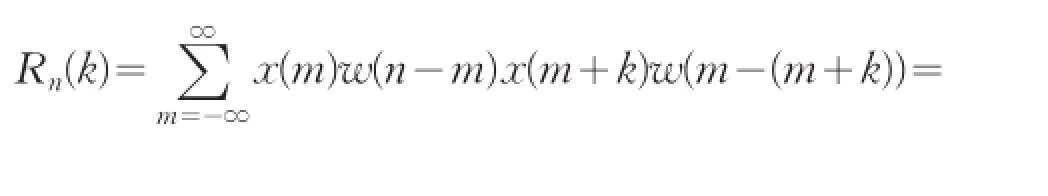
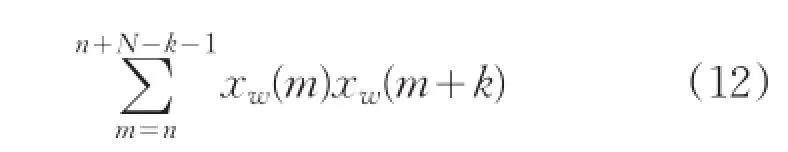
式中,n代表窗函数从n点开始加入。
2.3子带特征
按照倍频程规则把每一帧短时频谱分成7个子带,所以每个子带就包含了若干频谱的分量。把每个子带上最大的频谱分量、最小的频谱分量和平均值组合成特征序列。每一帧有7个子带,每个子带有三个特征值,所以每一帧具有21维特征值。它能有效地表达频谱能量在每一个子带上的分布情况。
3 实验过程及结果
3.1实验过程
本文主要采用了两种实验方法进行比较。第一种是直接对四种情绪类型进行建模,即分别对激动、愉快、平静、悲伤四种情绪建立模型GMME、GMMH、GMMP、GMMS。再分别求出每一个测试样本在这四个GMM下的后验概率并进行比较,后验概率最大的即认为被判决为该种情绪的音乐。
第二种是分别对表示情绪强烈程度的轴arousal的正负两端建立模型GMMA+和GMMA-,即用情绪强烈程度高的表示激动和平静的训练样本训练GMMA+,用情绪强烈程度低的表示愉快和悲伤的训练样本训练GMMA-,使这两个模型表示情绪强烈的正负。以一个测试样本来说明,就是求出这个测试样本在这两个模型上的后验概率然后根据后验概率判断其更接近于哪一端。同理,建立为表示情绪正负的轴valence的两端建立模型GMMV+和GMMV-。在这种方法下,实际上默认组成了一个两层分类器,即一个测试样本要先经过一个分类器判断情绪的强烈,再经过一个分类器判断情绪的正负。通常在涉及到多层分类器的问题上都会有权值的分配问题。对于权值的分配本文进行了7次试验来观察不同权值下的分类效果,并进行比较。
在实验之前需要对音乐进行预处理。为了计算方便,本文对每首音乐只提取了最能代表其特征的30s的音乐片段。提取片段后需要进行预加重、归一化及加窗分帧处理。本文预加重的系数为-0.9375,所加窗为汉明窗。在默认采样频率为44100的条件下,分帧的帧长选为1024,帧移为512。每种情绪的训练音乐有10首,共计40首。每种情绪类别的测试音乐有5首,共计20首。
3.2直接建立情绪GMM的实验结果
由于GMM阶数的选定尚无统一标准,为了后续实验的进行,需要对阶数M进行比较选取,通常阶数M的选择为16、32、64,所以本文在前人研究的基础上对三种阶数下的GMM分类效果分别进行实验,结果见表1。

表1 不同阶数对GMM正确率的影响
由表1可知,M等于32和64时正确个数相同,但是由于M等于64时增加了计算量,而且结果并没有明显的优势,所以接下来的实验中的M选为32。而且M等于64时可能会出现过拟合现象不利于构造灵活可用的模型。M等于16时正确个数偏低是因为出现了欠拟合的情况,即16阶的高斯混合模型不足以表达实际的训练样本的特征。
3.3建立轴GMM加权后分类的实验结果
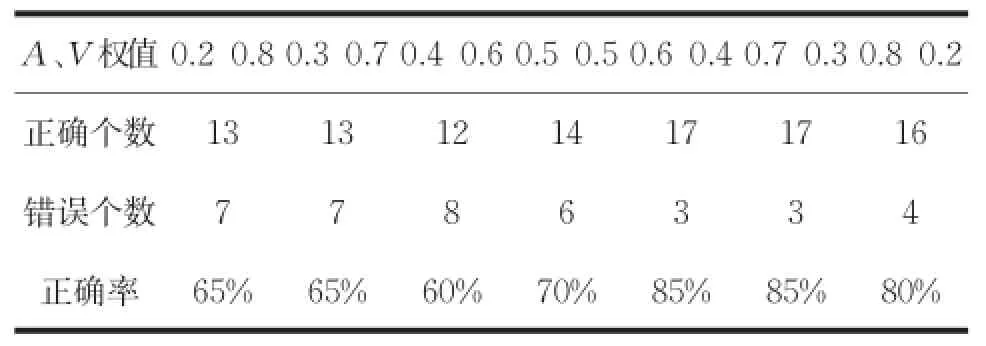
表2 不同权值对正确率的影响
从表2结果来看,当A、V权值分配0.6 0.4和0.7 0.3时的正确率一致,所以为了更进一步的区分,再加入十首测试样本,即使用30首测试样本进行测试。结果如表3所示。
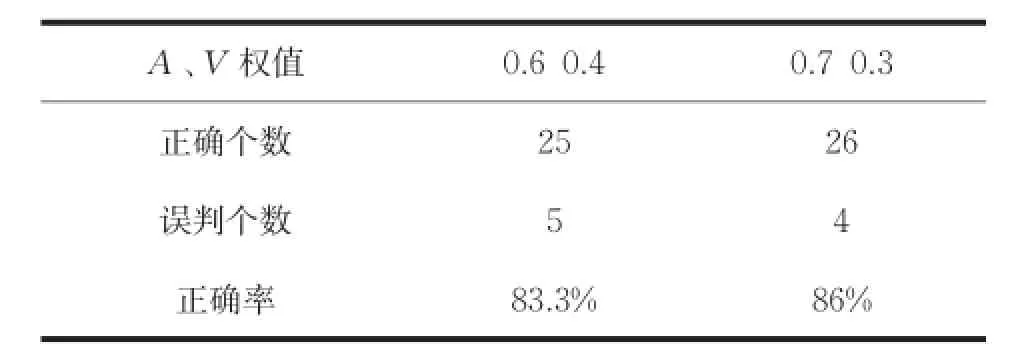
表3 增加测试样本后两权值的比较
结果表明,在30首测试样本的测试下,权值分配为0.7和0.3取得的效果较好。之所以在20首测试样本下有结果一样的情况产生原因主要有两条:一是所选择的训练样本和测试样本数过少,没有更明晰的分辨出优劣性;二是所选择的训练歌曲范围不够广或者类型判别不够准确,导致在判别时会出现模糊的状况。
4 结论
本文结合高斯混合模型对四分类音乐情绪进行了研究,结果表明在加权0.7、0.3的情况下取得的效果最好。与王磊[9]做过的基于Adaboost算法的分类结果相比较来看,并没有达到97%的准确率,可能是因为本文特征选取的不够全面,但大体结果一致。本文在情绪分类上仅仅区分了易于辨认的四类情绪,但是音乐表达的情绪远远不止于此,所以在类别的数量上还有需要增加的空间。
[1] 徐凯春.音乐情感参数化系统的研究与实现[D].广州:华南理工大学,2013.
[2] 龚勋.高斯混合模型(GMM)参数优化及实现[J].西南交通大学信息学院学报,2010(1):2-3.
[3] 程远国,耿伯英.基于高斯混合模型的无线局域网定位算法[J].计算机工程,2009,35(4):25-27.
[4] 时丹.音乐风格相似性检测算法研究[D].大连:大连理工大学,2013.
[5]Mesaros A,Astola J.The Mel-Frequency Cepstral Coefficients in the Context of Singer Identification [C]//ISMIR,2005:610-613.
[6] 蒋伟.基于高斯混合模型的说话人识别研究[D].成都:电子科技大学,2008.
[7] 李剑.神经网络在音乐分类中的应用研究[J].计算机仿真,2010(11):168-171.
[8] 徐桂彬.基于相关主题模型的音乐分类方法研究[D].苏州:苏州大学,2012.
[9] 王磊,杜利民,王劲林.基Adaboost的音乐情绪分类[J].电子与信息学报,2007,29(9):2067-2072.
Music Emotion Four Classification Research Based on Gaussian Mixture Model
LU Yang,GUO Bin,BAI Xuemei
(School of Electronic and Information Technology,Changchun University of Science and Technology,Changchun 130022)
For the problem of music emotional complexity and difficult to categorize,we proposed a method to establish Gaussian mixture models in four classifications.On the basis of establish models,we innovated established GMM for shaft at both ends of the emotional model and converted it into two-layer weighted classifier discrimination.The results shows that the GMM for shaft models and weight distribution under the condition of 0.7 and 0.3,the musical work can obtain the best classification result,and the result is better than the result of directly establish models for each type of emotion.
Gaussian mixture model;music emotion classification;weighted judgment
TP343
A
1672-9870(2015)05-0107-05
2015-07-01
陆阳(1991-),男,硕士研究生,E-mail:457625762@qq.com
郭滨(1965-),男,教授,E-mail:guobin@cust.edu.cn
猜你喜欢
现代装饰(2022年5期)2022-10-13
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
数学小灵通(1-2年级)(2020年4期)2020-06-24
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
江苏通信(2018年4期)2018-12-04
自动化学报(2017年7期)2017-04-18
电影故事(2015年16期)2015-07-14
中国卫生(2014年12期)2014-11-12
