
基于边分类的SVM模型在社区发现中的研究
2015-10-12 02:19王鹏高铖杨华民
长春理工大学学报(自然科学版) 2015年5期
王鹏,高铖,杨华民
(长春理工大学 计算机科学技术学院,长春 130022)
基于边分类的SVM模型在社区发现中的研究
王鹏,高铖,杨华民
(长春理工大学计算机科学技术学院,长春130022)
社区发现是复杂网络研究的重要内容,也是分析网络结构的重要途径。分析了社区发现研究中存在的问题,提出了一种基于边分类的SVM模型。通过边顶点相似度和边介数来表示边的特征,从而构造分类函数。利用LFR生成社区结构已知的人工网络,通过人工网络数据训练基于边分类的SVM模型,对分类函数的参数进行估计,利用训练模型对真实网络进行社区分类并通过标准化互信息(NMI)和整体准确度来评价分类效果。实验得到了较高的整体准确度和NMI值。实验表明基于边分类的SVM训练模型对真实网络数据的社区划分有较高的准确度,表明该方法是可行的。
社区发现;边分类;SVM模型;LFR
现实世界中的很多复杂系统都可以通过将实体抽象为节点,实体之间的联系抽象为边的复杂网络来表示。社区结构是复杂网络的一个重要特征,刻画了网络中节点连接关系的局部聚集特性,对揭示复杂网络的结构和功能之间的联系有着十分重要的作用。对社区结构的研究主要有社区发现、社区演化分析、社区网络动力学分析等[1],其中,社区发现是结构分析的一个基本任务。
社区发现的基本思路就是识别网络中的节点集合,使集合内的节点之间连接紧密,集合间的联结比较稀疏。基于这个思路,2002年Girvan和Newman提出了基于边介数划分的GN(Girvan-Newman)算法[2],该算法通过计算边介数,识别社区间连接,从而切断社区间连接划分社区,但该算法具有很高的时间复杂度,不适合处理大规模网络。为了度量社区内的紧密程度,2004年Newman提出了基于模块性的FN(Fast Newman)算法[3],该算法定义模块度函数Q[4],将使函数Q值增加或者减小最少的社区合并,从而选择对应Q值最大的社区划分作为聚类结果,同样该算法的计算开销较大。2007年Raghavan等人提出了标签传播算法(Label Propagation Algorithm,LPA)[5],该算法通过节点的邻居节点标签来更新自身标签,通过标签来确定节点社区,该算法收敛速度较快,聚类精度有待提高。在前人研究的基础上,本文提出了一种基于边划分的机器学习方法,通过建立基于边划分的支持向量机模型(Support Vector Machine,SVM[8])利用人工网络数据进行机器学习,进而对真实网络数据进行分析实验来提高社区发现的准确度,并利用标准化互信息(Normalized Mutual information,NMI[10])和整体准确率来衡量结果的优劣,实验结果表明该方法是可行的。
1 基于边分类的SVM模型
复杂网络的抽象表示是由节点和连接节点的边构成的网络结构,在图论中即可表示为G=(V,E),V表示网络中的节点集合,E表示网络中边的集合[6]。那么社区发现问题即可表述为:对于任意一条边ab∈E,节点a,b是否属于同一个社区。对于二元分类问题,本文构造分类器函数h,对于边ab的特征Xab,通过计算分类函数h( )Xab的值来判断节点a,b是否属于同一个社区,遍历网络中的每一条边,由此对网络中的边进行切割,最终得到社区集合。算法流程图如图1所示。

图1 算法流程图
1.1分类函数
构造基于边的分类器函数,需要首先确定边的特征量。复杂网络中对边的特征度量主要有边介数、边聚集系数、边两端节点的度以及邻近结点个数等。本文通过计算边两端节点的Jaccard相似度和边介数来作为该条边的特征度量,并根据特征量构造分类器函数。
1.1.1Jaccard相似度
节点的Jaccard相似性是根据两节点的邻居节点的交集节点数占并集节点数的比重定义的[7],其公式如下:
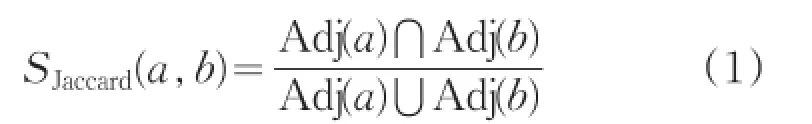
其中Adj()表示节点的邻居节点,其相似性的取值范围为[0,1]。传统的Jaccard相似度节点的邻居节点并不包含自身,但实际网络中存在边ab且。从相互关系来看,两个节点相连接在某种程度上存在相似性,因此本文采用修正的Jaccard相似度,在节点的邻居节点集合中并入自身节点。
1.1.2边介数
根据社区发现的思想,社区与社区之间联系稀疏,社区内联系密切,可以发现连接社区间的边成为社区之间沟通的主要桥梁。基于这个思想,Girvan 和Newman提出了边介数的概念:一条边的边介数是网络中任意两点的最短路径通过该边的路径数与最短路径总和的比值[1]。定义公式如下:

其中gab表示通过边ab的最短路径数,gij表示网络中任意两点的最短路径数。为了方便实验处理,本文采用标准边介数,即将边介数做归一化处理。
由边的特征向量构造分类器,本文提出通过加权的节点相似度和边介数得分来判断边的归属,从而进行切割划分社区。得分公式定义如下:
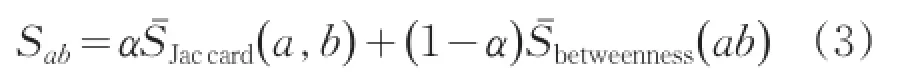
其中α为边特征向量元素的权重,Sab的取值范围为[0,1]。自然地,通过设定阈值来定义分类器函数,当Sab>τ 0<τ<1时,边ab属于社区内;相反当Sab≤τ时,边ab属于社区间,即节点a,b属于不同社区。因此,分类器函数可以表示为:

1.2SVM模型及参数估计
对模型参数的估计实际上就是对边特征向量所对应的权重向量的估计。对于社区结构已知的复杂网络很容易得到边的特征向量,同时还有边的归属,即模型的响应变量,定义如下:

在自变量与响应变量已知的情况下,通过利用SVM模型进行参数估计,进而将训练模型应用到社区结构未知的网络,进行社区发现研究。SVM模型是一种机器学习方法,该算法基于统计学习理论采用结构风险最小化原则,使得分类准确率和预测能力都能达到较高水平。
假设存在线性可分的数据集(X,Y) ,则线性判别函数即可定义为g(X)=W·X+b,那么,存在一个超平面W·X+b=0,使得数据分布在该平面的两侧。对任意xi存在平行于超平的边界面W·xi+b≥1或W·xi+b≤-1,最大化两个平行超平面的距离,即。因此,最优分类面的求解,转化为了求‖‖W的最小值,即求函数的最小值。这是一个二次优化问题,采用拉格朗日乘子法进行求解,定义Lagrange函数[9]:

其中αi>0是拉格朗日系数。在参数W,b下求Lagrange函数的极小值,关于Lagrange函数分别对W,b求偏导,得到原问题的对偶问题表达式:
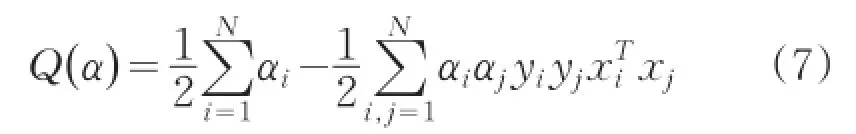

最后利用符号函数得到最优分类函数:
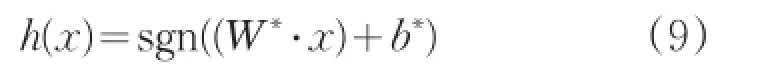
2 社区评价
对于社区结构已知的基准网络,为了比较实验结果与真实社区之间的相似程度,利用Lancichinetti提出的NMI指标来评价模型的优劣,同时本文也提出了一种新的评价指标整体准确率ρ。
2.1NMI指标
Normalized Mutual information(NMI[10],标准化互信息),是基于信息论和概率论提出的一种衡量聚类或分类效果的评价指标。NMI的值域为[0,1],其值越大说明实验结果越接近真实情况。NMI的公式定义如下:

其中X,Y为两个离散随机变量,I(X;Y )表示两个随机变量的互信息,H(X),H(Y )表示两个随机变量的边缘熵,p(x),p(y),p(x,y)分别表示随机变量的概率分布和联合概率分布。
2.2整体准确率
在社区发现试验中,真实网络的社区数量往往比实验发现的社区数量少,观察实验结果发现,真实网络社区往往被拆分成若干个子社区。在这种情况下NMI指标并不能很好的衡量算法的效果。因此文本提出了一种新的衡量指标:整体准确率ρ,其公式定义如下:
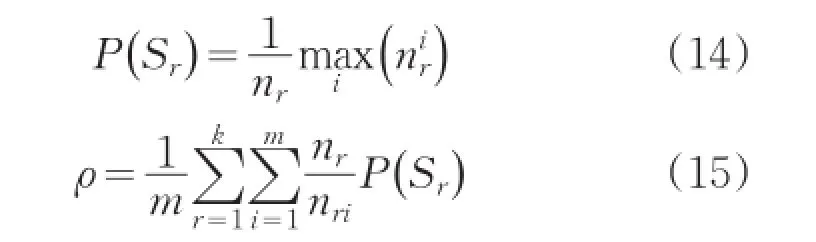
其中Sr表示实验发现的社区,nr对应为社区的节点数,表示社区Sr中节点属于第i个真实社区的个数,m为真实社区个数,k为实验发现的社区个数,nri表示社区Sr中节点属于真实社区最多的第i个真实社区的规模。
3 仿真实验及结果分析
LFR[11]是由Lancichinetti和Fortunato提出的一种标准测试网络。现实网络中的节点度服从幂律分布,利用LFR生成的人工网络节点度同样服用幂律分布,因此利用LFR生成的网络结构与现实网络相似。本文利用LFR生成的数据训练分类器,确定相应的分类器参数。为了构造具有特定性质的LFR网络,需要一定的参数配置,其中N表示节点的个数;k表示节点的平均度;maxk表示最大节点度;minc表示最小社区的节点个数;maxc表示最大社区的节点个数;最为重要的是混合参数μ,它控制社区之间的关联程度。当μ=0时,社区之间没有连接,即社区之间相互独立;当μ=1时,网络中每一条边的两个节点分别属于不同的两个社区,社区之间联系密切。
在不同混合参数μ下,对社区发现算法进行仿真实验,实验数据本文采用LFR生成的标准GN网络,训练数据利用LFR生成,参数设置为N=1000,k=10,maxk=30,minc=20,maxc=100,mu=0.5。实验结果如图2所示。
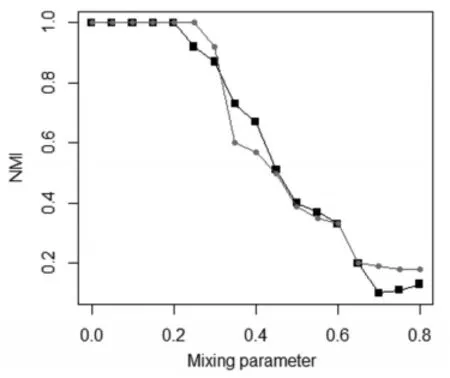
图2 训练模型与原始模型对标准GN网络划分结果比较
图2中红线表示训练模型,黑线表示原始模型,可以看出训练模型基本优于原始模型,特别是在混合参数不大的情况下,训练模型对社区发现的精准度较高。
真实数据采用经典的Zachary空手道俱乐部网络Karate、美国大学生足球赛网络Football、海豚关系网络Dolphins、美国政论著作网络Polbooks,这三个真实网络都有清晰的社区结构,方便与实验结果进行比较分析。实验结果如表1所示。
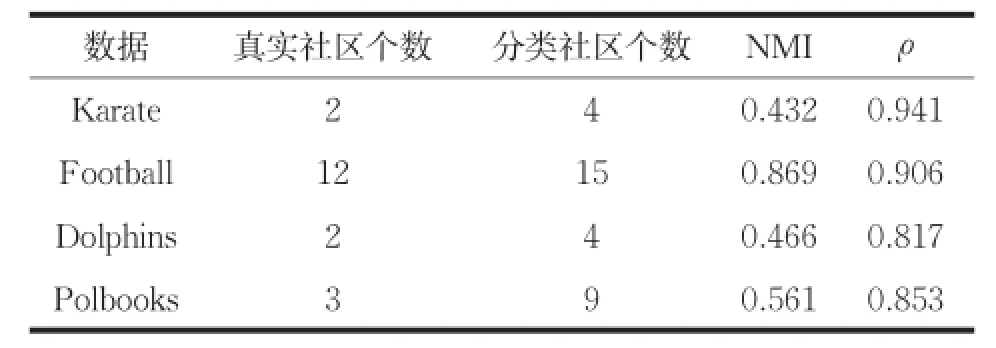
表1 真实数据的实验结果
从上表可以看出训练模型对真实网络数据有较好的分类效果,真实社区个数与分类社区个数存在一定的差别,这与模型本身和模型的训练程度有一定的关系,模型的精度可以进一步的提高。受分类社区个数影响,NMI值相对偏低,但整体准确率基本保持在较高水平,说明实验分类社区中的节点纯度很高。
4 结论
社区发现是复杂网络研究的重要内容之一,许多专家学者对这方面做出了深入的研究,也取得了很大的成果。本文基于网络中边的特征,构造分类函数,利用LFR仿照现实网络性质参数,生成一些社区结构已知的人工网络,通过人工网络数据训练基于边划分的SVM模型,利用SVM模型进行参数估计,并利用训练模型对未知网络进行社区分类,通过NMI和整体准确度评价分类结果。实验表明基于边分类的SVM训练模型对真实网络数据的社区划分有较高的准确度,说明文中的方法是可行的。
[1] 程学旗,沈华伟.复杂网络的社区结构[J].复杂系统与复杂性科学,2011,08(1):57-70.
[2]Girvan M,Newman M E J.Community structure in social and biological networks[J].Proceedings of the National Academy of Sciences,2002,99(12):7821-7826.
[3] Newman M E J.Fast algorithm for detecting community structure in networks.[J].Phys Rev E Stat Nonlin Soft Matter Phys,2004,69(6):279-307.
[4] Newman M E J,Girvan M.Finding and evaluating community structure in networks[J].Physical Review E,2004,69(2):292-313.
[5]Raghavan U N,Albert R,Kumara S.Near linear timealgorithmtodetectcommunitystructuresin large-scale networks.[J].Phys Rev E Stat Nonlin Soft Matter Phys,2007,76(3):036106-036111.
[6] Lei Tang,Huan Liu著,文益民,闭应洲译.社会计算:社区发现和社会媒体挖掘[M].北京:机械工业出版. 2012.
[7]Laarhoven T V,Marchiori E.Network community detectionusingedgeclassifierstrainedonLFR graphs[C].ESANN 2013:21st European Symposium on Artificial Neural Networks,Computational IntelligenceAndMachineLearningBrugesApril 24-25-26,2013.Proceedings,2013.
[8] Guyon I,Weston J,Barnhill S,et al.Gene Selection for Cancer Classification using Support Vector Machines[J].Machine Learning,2002,46(1-3):389-422.
[9] 巩知乐,张德贤,胡明明.一种改进的支持向量机的文本分类算法[J].计算机仿真,2009,26(7):164-167.
[10]Lancichinetti A,Fortunato S,Kertész J.Detecting the overlapping and hierarchical community structureincomplexnetworks[J].NewJournalof Physics,2009,11(15):19-44.
[11]Radicchi F,Castellano C,Cecconi F,et al.Defining and Identifying Communities in Networks[J]. Proceedings of the National Academy of Sciences of the United States of America,2004,101(9):2658-2663.
The SVM Model Based on Edge Classification Research in Community Detection
WANG Peng,GAO Cheng,YANG Huamin
(School of Computer Science and Technology,Changchun University of Science and Technology,Changchun 130022)
The community detection is an important part of the complex network research,and it is also the important way to analyze the network structure.In this paper,the problems existing in the community detection research are analyzed and a kind of SVM model based on the edge classification is proposed.Based on vertex similarity and edge betweenness the characteristics of the edge are represented,so the classification function is constructed.The artificial network of the known community structure is generated by LFR.Through artificial network data training based on edge classification of SVM model,the parameters of classification function are estimated and the real network community is simulated by using the trained model.The higher overall accuracy and NMI values are got in the experiment.Experiments show that the edge classification of SVM trained model have higher accuracy on real network data and the method is effective.
community detection;edge classification;SVM model;LFR
TP391
A
1672-9870(2015)05-0127-04
2015-06-08
王鹏(1973-),男,副教授,E-mail:635461179@qq.com
杨华民(1963-),男,博士,教授,博士生导师,E-mail:yhm@cust.edu.cn
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
数学小灵通(1-2年级)(2021年4期)2021-06-09
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
中国卫生(2015年12期)2015-11-10
