
基于关联规则的数据挖掘技术在独立院校招生中的研究
2015-11-08 06:24纪威刘志伟
计算机与网络 2015年13期
纪威 刘志伟
(天津商业大学宝德学院,天津 300384)
基于关联规则的数据挖掘技术在独立院校招生中的研究
纪威刘志伟
(天津商业大学宝德学院,天津300384)
文章结合独立院校招生工作的实际情况,简要介绍了数据挖掘技术的基本概念、挖掘过程及模型,同时利用数据挖掘技术中的关联规则及算法探讨在独立院校招生决策方面的基本应用。通过对大量招生数据及新生信息进行有效挖掘和分析,寻找学生入学信息诸多因素与在校培养结果之间的关联关系,从而为我院招生决策者提供科学依据与决策支持,进而将对独立院校在快速多变的生源竞争中把握发展方向起到引领作用。
数据挖掘独立院校招生决策关联规则
1 引言
独立院校相对普通高校而言是国家按照新机制、新模式与社会力量合作举办的具有本科层次的学院,其生源质量是独立院校的生存之本,在生源竞争越来越激烈的情况下,如何利用已有信息资源为招生决策服务,是我们面临的紧迫课题。随着数据挖掘技术在教育招生环境下的应用,可以对招生系统积累的海量数据进行挖掘和提炼,进行多维分析、合并归类和高度集成,从而获取有价值的信息,大大提高招生决策水平,有效增强独立院校的竞争力。
2 数据挖掘技术
2.1数据挖掘概念
数据挖掘又被称作数据库中的知识发现(KDD)。它是从海量的、不完全的、有噪声的、模糊的、具有不确定性的数据集中,提取蕴含在其中的、事先未知的、可信赖的、有用的规律和知识的过程。发现知识的方法可以是数学的,也可以是非数学的;可以是演绎的,也可以是归纳的[1]。发现的知识要可接受和理解,并能被用于信息处理,优化查询,支持决策和过程控制等,还可以用于数据自身的维护。
2.2数据挖掘过程
在数据挖掘过程中,被探讨的对象是整个操作的基础,数据挖掘的全部过程受它驱动,最终挖掘结果需要它的支撑,系统的整体研究工作需要它的指引。挖掘过程不是自动进行,多数需要人工的引导和干预。在数据挖掘整个过程中,大约有60%的时间需要对数据库进行前期整理和数据准备,因为数据的准确性和格式化对数据挖掘的影响较大,而通常来说,数据挖掘的后续操作只占总工作量的10%左右。数据挖掘过程步骤的具体内容如图1所示:

图1 数据挖掘的过程
3 数据挖掘模型
数据挖掘模型的建立要从对数据的分析开始。针对选定的挖掘算法,将数据转化成一个分析模型。建立的分析模型是否适合挖掘算法对挖掘能否成功起着关键的作用[2]。数据挖掘模型主要分两种,一种是Fayyad总结出的过程模型,以下称为Fayyad过程模型:另一种是遵循CRISP-DM标准的过程模型,本文称其为CRISP-DM过程模型。
3.1Fayyad过程模型
Fayyad过程模型偏向于技术方面,因此,数据挖掘可以理解为一个循环迭代过程,该模型从数据入手,到知识结束。从图2中可以看出,该过程模型的执行分以下几个部分:
(1)数据预处理:包括数据提炼清洗、数据合成、选择数据、转换数据等几个过程;
(2)数据挖掘:这是知识挖掘的基本步骤之一,功能就是利用智能方法挖掘数据知识或规律模式;
(3)模式评估:根据规定的评估要求从数据挖掘结果中挑选出有价值的模式知识;
(4)知识表示:利用可视化的数据表达技术,提供给用户需要挖掘出的有用知识。
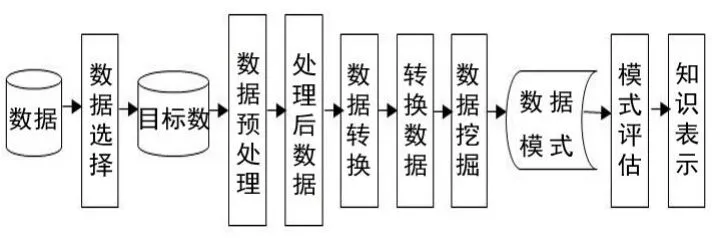
图2 Fayyad挖掘模型过程
3.2CRISP-DM过程模型
CRISP-DM(Cross-Industry Process for Data Mining交叉行业数据挖掘过程标准)如图3所示。CRISP-DM过程模型注重技术的应用,解决了Fayyad模型存在的两个问题。CRISP-DM过程模型从数据挖掘技术应用的角度划分数据挖掘任务,将数据挖掘技术与应用紧密结合,更加注重数据挖掘的模型质量和如何与业务联系问题相结合。CRISP-DM强调,数据挖掘不单是数据的组织或者呈现,也不仅是数据分析和统计建模,而是一个从理解业务需求、寻求解决方案到接受实践检验的完整过程。

图3 CRISP-DM过程模型
该模型的执行分以下六个步骤进行:
(1)业务理解:对客户实际需求与目标的理解,转换为数据挖掘的一个定义和为了达到此项目目标的初步解决方案;
(2)数据理解:检测目前数据的基本质量,对相关数据有初步的了解和掌握,探寻数据中有意义的子集数据,从而形成对潜在数据信息的假设;
(3)预处理:包括从最原始海量数据中创建最终有价值数据集的所有工作,主要包括:数据制表,记录参数,数据转换和选择,以及清理数据等;
(4)建模:有针对性的选择和使用多种建模方法,并将其参数结果校准为理想的数据值;
(5)评估:评估目前已经建立的模型,确保构建的模型达到企业需求的目标;
(6)部署:把所有建模数据信息用客户能够操作的方式呈现和组织出来。
CRISP-DM过程模型从数据挖掘技术应用的角度划分数据挖掘任务,将数据挖掘技术和应用紧密结合,注重数据挖掘的质量和如何与业务问题相结合。
4 在独立院校招生中的应用研究
4.1关联规则及其Apriori算法
4.1.1关联规则的概念
关联规则挖掘在数据挖掘中是最经典的算法之一。它是指在交易数据、关系数据或其它信息载体中,查找存在于项目集或对象集合之间的频繁模式、关联、相关性或因果关系,可以发现隐藏在数据之中、不易被发现的关联事件。
设I={i1,i2…in。}是项的集合。记W为数据库事务Z的集合,这里每个事务Z是项的集合,并且使得ZI。对应每一个交易有惟一的标识符,记作ZIW。设M是一数据项的集合,当且仅当MZ,那么称交易Z包含M。关联规则是具有MN的蕴涵式,其中MI,NI,并且M∩N=。规则MN在交易数据库W中的支持度S是包含M和N的交易数与所有交易数之比,记为Support(MN),即Support(MN)=P(MUN);规则MN在交易集中的置信度C是指包含M和N的交易数与包含M的交易数之比,记为Confidence(MN),即 Confidence(MN)=P(N|M)。同时满足最小支持度阂值(min_sup)和最小置信度闭值(min_conf)的关联规则称强规则,用0~100%之间的值表示支持度和置信度值。
4.1.2Apriori算法
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。该算法是由Agrawal等人在1993年设计的一种基本算法,这是一个基于两阶段频集思想的方法[3],关联规则挖掘算法的设计可以分解为两个子问题:①找到所有支持度大于最小支持度的项集,称为频繁项集;②使用第1步找到的频繁项集产生期望的规则。其算法的实现过程可描述为:首先, Apriori算法求出项数为1的频繁集L1,然后,再由L1产生项数为2的候选集C2,扫描事务数据库W,计算支持度求出L2,依次类推,产生Ck,扫描W求出Lk。一旦从数据库中产生了频繁集,则可以从中直接产生强关联规则。
4.2关联规则在独立院校生源分析中的挖掘流程
4.2.1挖掘问题的提出
利用全国院校秋季高考统招考生基本信息和在校期间诸多成绩等数据,从高考分数、学生素养、生源区域等方面,对学生的入学基本信息与在校期间各项成绩指标进行关联性分析,从而提取在数据背后隐藏的有价值信息。
4.2.2数据前期准备
本系统需用到多个源信息数据库,第一要将多个源数据库中的信息进行整合;第二检索全部相关因素的信息数据,并从中挑选出信息用于数据挖掘的应用;第三再对选出数据实施相关的转换操作,加工之后的数据不仅反映源信息的真实情况还要适合挖掘算法的实际需要。数据预处理进程中的一个难点工作就是数据的转换,它需要在系统建设实施中不断实践摸索、逐步修正,进而完善数据的转换方案,同时将系统数据的质量问题得到最终解决[4]。数据准备工作大体上分为以下三部分:
(1)学生信息预处理工作
招生录取结束后,学生的基本信息包括:新生录取情况(招生的年份、录取的专业方向);学生基本信息内容(应试卷种、科类、考生号、姓名、出生日期、性别、身份证号、考何种外语、考生类别、民族、政治面貌、毕业学校、毕业类别、考试类型、户口所在地、获奖情况、专业志愿填报等);考试成绩内容(高考总成绩、各门课程单独成绩、加分状况、考生会考成绩等)。为了方便进行数据挖掘操作,需要对以上信息进行适当的转化与归约等一系列预处理工作。在上述内容中,操作最困难的预处理数据是:高考总成绩和考生来源地。普通高等学校招生是在全国高考基础上进行分省录取操作,各个省份根据录取院校所属一本、二本、三本、高职的层次和录取招生的计划类型将各院校录取时间划分成不同的批次,然后按照所在省份招生计划总数和考生报考总数按照一定比例(一般为1:1.1)规划出各个院校录取批次控制分数线。各录取院校在所属批次内按照各省公布的专业招生计划数来进行考生录取工作,由于各个省份招生专业计划不一样,各个录取批次的控制分数线不同,故院校在各省的最终录取分数线也不同,直接导致录取考生的分数也有较大的差异,所以无法将全部学生的高考分数直接进行对比,因此要将各个省份的学生考试总成绩转换成标准分数才能操作。
(2)考生来源地预处理工作
在普通高校招生考试中,对于考生来源地的原始数据信息统计工作,内容过于详细,与数据挖掘技术要求在操作上不太一致,因此要针对不同的数据挖掘目标,对考生来源地信息进行归约操作。在这里,可将同省考生归为一类;也可按全国各省份在版图中的所属位置大致规约为:东南地区、西南地区、西北地区、东北地区、华中地区、华东地区和华北地区等部分;还可按照省会、地区、城镇、乡村等将考生来源地进行规约操作。
(3)在校成绩预处理工作
学生在校期间要进行四年的学习生活,在这个过程中包括8个学期,每个学期都有各门课程的考试成绩、综合测评、比赛获奖及毕业设计、毕业论文、毕业实习和就业等相关数据内容。其中,每个学期各门课程的成绩只体现在专业学习中的情况,而综合测评的成绩则是学生在校期间德智体等多方面真实情况反映,它是一种量化和科学化的计算方法。每个学年的综合测评成绩按智育和德育来进行考核,其中智育成绩占70%,德育成绩占30%。在我院,将每名学生按年级、专业分别进行统计,其综合测评成绩以优、良、中、及格、不及格五个等级标准来表示,从而进一步的推进数据挖掘工作。
4.2.3数据关联规则的挖掘
通过上述预处理工作,同时在基于数据分析的基础上,针对学生入学信息与在校间成绩进行关联操作,从而寻找学生在入学时的多因素与在校间成绩的基本关系[5]。在这里,可参考不同的维度对学生高考成绩、考生类别、来源地、毕业学校、获奖状况等与大学综合测评成绩之间的关联关系进行有效的分析。通过数据的关联分析,可得出不同科类、不同地区、不同入学成绩水平以及不同素质学生在经过大学四年的教育培养后所产生结果的关联性与差异性,然后再从人才专业培养结果的角度出发,逆向分析出哪类学生更具有学习的潜质、更能成为本专业优秀毕业生等,从而总结出具有实际参考价值的结论,更好的指导学校招生计划制定与宣传工作的开展。4.2.4模型解释与评价
在数据关联分析之后,会导出一系列的关联规则,我们则要在多种关联规则中选取有用的规则条款,并进行解释和评价,同时参考关联规则分析结果,合理地设定最小支持度(min_sup)与最小可信度(min_conf)是非常必要的[6]。如果可信度过大或支持度过大,部分所需的关联规则就不可能挖掘出来;如果可信度过小,则所产生的关联规则冗余度相对较大,很难从中发现有价值的关联规则数据;如果支持度过小,则频繁项集产生所需的时间可能无法忍受,频繁项集的数量也会随之非常巨大。
5 结束语
随着数据挖掘技术在独立院校招生领域的广泛应用,其价值已经不可估量,它能从海量学生信息中发现各种潜在规则,构建考生信息数据仓库,为招生决策分析提供基础,指导招生决策人员进行招生策略地调整,科学地指导招生、合理设置专业、高效地开展宣传,从而达到提高新生报到率和保证生源质量的目的。
[1]许硕.数据挖掘技术在民办高校招生工作中的应用研究[J].辽宁师专学报(社会科学版),2012,(06):112-114.
[2]李霞.数据挖掘在高校教学和管理中的应用研究[J].广东外语外贸大学学报,2012,(04):97-100.
[3]韦映梅,邹海林.基于数据挖掘技术的招生电子档案信息系统模型构建[J].兰台世界,2014,(14):19-20.
[4]徐健.数据挖掘技术在高校招生信息处理中的应用[J].农业网络信息,2013,(11):133-137.
[5]何小明,张自力.基于OLAP与数据挖掘的高考招生数据分析[J].计算机科学,2012,(06):175-187.
[6]何广东.基于数据挖掘的高校招生决策支持系统的设计与实现[J].无线互联科技,2012,(11):93-94.
Research of Independent Colleges Admissions Base on Data Mining Technology of Association Rules
JI Wei,LIU ZHI-wei
(Tian Jin University of Commerce Boustead College,Tianjin 300384,China)
In this paper,the actual situation of independent enrollment colleges,introduces the fundamental concepts of data mining technology,mining and modeling process,while using data mining techniques and algorithms of association rules on the fundamental application in independent colleges admissions decision-making.Through a large number of freshmen admissions data and information for effective mining and analysis,looking student enrollment information and culture and many other factors relationship between the results in the school,so as to provide a scientific basis and decision support to hospital admissions decision-makers,and thus will be independent hospital grasp the development direction of the school play a leading role in the students compete in the rapidly changing.
data mining;independent colleges;admissions decisions;association rules
TP274
A
1008-1739(2015)13-58-4
定稿日期:2015-06-12
本文系天津商业大学宝德学院科研基金规划课题《基于B/S结构的新生报到系统网络平台的研究》成果,项目编号:BD20129106
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
新世纪智能(数学备考)(2021年9期)2021-11-24
数学小灵通(1-2年级)(2021年4期)2021-06-09
大众投资指南(2021年35期)2021-02-16
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
Coco薇(2017年11期)2018-01-03
电力与能源(2017年6期)2017-05-14
读者(2017年5期)2017-02-15
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
