
基于提及关系的微博用户知识发现初探*
2015-11-21 01:55吴恺王莹
图书与情报 2015年2期
吴恺 王莹
(1.南京大学信息管理学院 江苏 南京 210046)
(2.江苏省数据工程与知识服务重点实验室(南京大学) 江苏 南京 210046)
(3.南京大学图书馆 江苏 南京 210046)
基于提及关系的微博用户知识发现初探*
吴恺王莹
(1.南京大学信息管理学院 江苏 南京 210046)
(2.江苏省数据工程与知识服务重点实验室(南京大学) 江苏 南京 210046)
(3.南京大学图书馆 江苏 南京 210046)
发现具有重要影响力的微博用户及其主题信息对于甄别高质量信息来源,充分发挥微博的媒体沟通作用,提高公民信息素养具有重要的意义。文章提出了基于提及关系的微博用户知识发现模型,分析了被提及用户与微博文本之间的联系,并利用LDA主题模型对微博用户进行聚类分析和主题词抽取,实验证明基于提及关系的主题聚类可以发现高影响力微博用户及其主题词。
微博用户;提及关系;主题词;LDA模型
1 引言
随着Web2.0和移动互联网技术的不断发展,微博已经成为人们创作、传播和发现信息的一种重要平台。一般认为,微博不仅仅是一类博客网站,而是兼具社交网络和新媒体的功能,类似于哈贝马斯所指的公共领域。不仅知名人士和社会大众通过微博参与新闻传播和公共讨论,许多官方部门以及企事业单位也纷纷开通微博,作为官方沟通平台或营销渠道,微博用户逐渐成为机构或个人在公共话题平台中的代称。在使用微博的同时,用户之间的大量行为联系也被记录下来,如果能够挖掘这些行为数据,发现和利用隐含在用户行为中的知识联系,发现微博用户间的联系和主题词,构建微博用户知识地图,对于提高微博信息利用效率,进而及时处理舆情和突发事件,提供决策支持等具有重要的意义。
2 相关工作
基于用户行为信息分析用户之间的联系是知识发现和知识组织的一种方法,笔者曾提出了一个较为通用的用户行为知识模型,通过预先定义的模式进行信息析取、数据挖掘,可以发现用户之间以及用户与主题词的联系,用于知识组织和知识服务。目前基于微博用户关系挖掘的研究主要有微博用户社群分析、关键用户识别、个性化推荐等,但现有的微博用户行为研究主要集中于微博用户的关注、转发和评论等行为,这类分析只能发现主动参与微博互动的用户信息,无法发现未参与的微博用户与相关事件之间的潜在联系,而这类联系也具有一定的情报价值,例如在突发事件中,尽快发现与事件相关的微博用户,可以有助于分析事件相关责任方,加强公共沟通,提供权威消息来源,避免网络谣言的传播。
微博字数不超过140个,微博信息中具有较为明显的主题,许多学者针对微博文本进行主题挖掘研究,张晨逸等提出了MB-LDA模型用于微博文本分析,经过在Twitter数据集上的实验,模型聚类结果的复杂度优于传统的LDA模型,得到的主题和关键词与LDA模型相当。唐晓波等利用LDA的扩展模型UserLDA对新浪微博用户进行兴趣主题建模,以进行TopN二级好友推荐,实验表明该推荐算法有较好的准确性和多样性。
知识地图是知识管理的一种重要方式,其概念最早由情报学家布鲁克斯提出,布鲁克斯提出的“知识地图”主要是指人类的客观知识,他认为人类的知识结构可以绘制成以各个知识单元概念为节点的学科认识地图。李亮认为知识地图“指向知识而不包含知识本身,它是一个向导而不是一个知识的集合。知识地图不仅可以指向人,也可以指向文献和其他的资源”。近几年隐性知识地图逐渐成为学者研究的热点,隐性知识地图除了从合著关系、引用关系等联系中发现知识外,还可以从人们日常行为的社会化大数据中挖掘。本文主要研究基于提及关系的微博用户知识发现,尝试构建微博用户的知识地图。
3 用户提及行为分析
微博中的提及行为也称为“@”行为,即在发布的微博中加上“@用户昵称”,表示对特定用户发送信息。在此基础上,Twitter等微博应用逐步完善“@”功能,并将用户在微博中“@”某人这一行为正式称为提及(Mention)行为。以新浪微博为例,其所提供的“@”功能在微博中实现了以下几个效果:①当发布“@昵称”的信息时,其意思是“向某某人说”,对方能看到你说的话,并能够回复,实现一对一的沟通;②通过发布的信息中“@昵称”这个链接,可以直接点击到这个人的页面,方便大家认识更多朋友;③所有@你的信息有一个汇总,可以在我的首页右侧中“提到我的微博”中查看。
根据提及用户的原因和动机不同,笔者将提及行为归纳为四种类型,①引用提及:当用户引用某人的新闻或话语时,通常会在引用的话之后@原作者。②对话提及:当微博话题中提到某个用户时,会在用户名前加上@符号。③信息推送:用户认为某条信息对所@的用户(通常是互相关注的好友)有价值时,推荐其关注阅读。④征求关注,用户当发布某条信息时,希望@的用户(通常是有影响力的用户)关注以及转发,扩大影响。
比较提及关系与转发、评论关系,其知识联系的来源基础是不同的,转发评论行为反映的是自我的认识,如“我”认为转发评论的微博对“我”有价值或关联,而提及行为反映的是他我的认识,即“他人”认为提及“我”的微博对“我”有价值或关联。比较提及关系和关注关系,虽然都体现了他人对被关注/提及用户的认可,但是提及关系的优势在于其是动态的,可累积的,即能更好地反映在某个时段用户的影响力以及与某些主题的联系。因此,分析用户被提及的次数和关联文本,可以有助于发现高影响力的微博用户及其主题词。
4 基于提及关系的微博用户知识发现模型
本文基于微博用户的提及关系和主题聚类模型,提出了基于提及关系的微博用户知识发现模型(见图1),该模型包括三个模块:数据预处理、知识发现和知识组织。数据预处理模块的数据来源是微博API采集的原创微博、转发微博和评论微博,主要完成3步工作:①抓取微博信息中的被提及用户,微博与用户之间是多对多的关系;②根据提及用户的格式分析提及关系类型,去除引用型提及和对话型提及;③对微博文本进行清洗和补充,如去除网址(形如Http://)、图片、提及(形如@XX)和以往转发(形如//@XX:)等无效信息,在转发和评论微博中加上原创微博信息。经过以上工作,最终得到被提及用户和微博文本对应关系的数据库〈u,t〉。
知识发现模块的主要内容是使用LDA聚类算法发现用户关系和用户主题词。由于被提及用户对应多条微博文本,因此需要按用户对微博汇总,本文首先对微博t进行分词和叙词选择,得到一个微博叙词向量,同一条微博中的叙词权重设为1,然后将同一个用户的微博叙词向量汇合,叙词权重设为含有该叙词的微博个数,以期较为准确地反映词汇权重。最终形成微博用户—词汇矩阵〈u,d〉。
LDA主题模型是一种基于双层贝叶斯概率的主题模型,该模型基于“词袋”(bags of word)的思想,认为每个文档按照一定的概率包括若干个主题,每个主题又按照一定的概率包括若干个词语,文本生成可以看做是按照一定的概率从“词袋”中选择词汇的过程。首先按照某个概率θ选择一个主题Z,然后在这个主题中按照概率ψ再选择一次词汇w。每一次概率选择的过程服从多项式分布,θ和ψ的先验分布概率服从参数为α和β的Dirichlet分布。直接求解联合概率分布是比较困难的,必须借助一定的统计推断方法。在LDA模型中,常用的统计推断方法有EM(expectation-maximization)和GibbsSampling方法。其中Gibbs Sampling是一种马尔科夫链蒙特卡洛方法,通过不断的改变条件概率的取值对联合分布进行采样,最终推断出希望求解的联合分布。
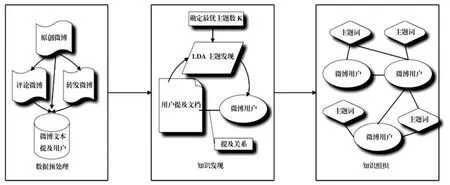
图1 基于提及关系的知识发现和知识组织模型
知识组织模块用于组织和表示主题聚类所发现的知识关联,知识关联包括两种类型,其一是用户之间的关联,例如微博用户A和用户B同属于一个主题聚类,则可以认为这两个用户具有相似性。其二是微博用户与主题词之间的关联,LDA聚类结果中给出了主题词在各个聚类中出现的概率,概率越大,则越能表示该聚类的主题。在判断某个用户的主题词权重时,本文提出微博用户的LDA主题词算法公式如下:
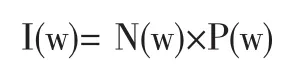
其中N(w)为〈u,d〉中用户词汇的频数权重,P(w)为LDA聚类所得到的主题词概率,依据主题词算法得分选择微博用户的主题词。
5 实验过程
笔者选择了2014年的6个突发性公共事件,以时间为序,分别为马航MH370事件,西安幼儿园病毒灵事件、上海福喜食品事件、湖南湘潭校车事件、昆山工厂爆炸事件和H7N9病毒流行事件。采集了以这些事件为关键词的6000条原创微博及其转发和评论数据,并标记了微博的事件类别。在总计200803条微博信息中,含有提及用户信息的有16987条,所占比例为8.46%,其中24.06%的提及行为最终得到了用户的回应。以上数据表明提及行为在微博日常使用中占有相当的比例,其分析的结果具有一定的代表性。
由于新浪微博是中文微博,需要对微博进行中文分词。本文采取的分词软件基于“ICTCLAS”算法,所采用的词典为“Sogou标准词库”和网络用语词库,ICTCLAS算法在分词时能够给出词性。分词后,按照以下原则选择词汇:①去除停用词;②保留字数大于2个字的词;③去除词性为形容词、数量词、介词、副词等词汇;④合并了部分同义词汇,例如“H7N9禽流感”和“H7N9”、“江苏”和“江苏省”等。被提及用户的分布具有明显的长尾特征,为了使微博用户信息较有代表性,笔者选取了被提及次数较高的前200位认证用户进行研究,这些用户粉丝数最少的为5101,最多的达7000多万,其中151名用户的粉丝数超过50万,平均发布的微博数为25883条。
本文实验采用R语言的“topicmodels”软件包,在进行微博LDA主题聚类时,需要设定聚类数和参数,根据经验数值,取α=50/K,β=0.01,聚类数K依据统计语言模型中常用的评价标准——困惑度(Perplexity)来进行选取,经过对不同聚类数的实验,本文最终选择聚类数为70。通过聚类分析可以发现微博用户与主题、主题词之间的联系(见表1)。
为了比较算法抽取主题词的准确率,需要设计一种实验,本文为每个用户人工标注了5个主题词,标引方法是将政府微博、企业微博和专业人士微博用户及其相关的微博文本(已分词)提供给若干个阅读者,每人负责一部分微博用户,阅读者根据微博文本内容选择与微博用户及突发事件相关性最高的5个主题词,选择词汇的原则是以表现事件和用户的语义特征为主,偏重于标题或话题的词汇。

表1 部分微博用户的所属聚类和主题词
对一个主题词抽取算法效果的评价应当包括两个方面:①能准确抽取出反映主题的词汇;②抽取出的词汇中不能反映微博用户特征的词汇,即无效词汇越少越好。因此,本文实验采用在信息检索领域常用的F-measure指标来比较本文的主题词方法和传统的TFIDF方法效果,F-measure是一种综合了精度(precision)和召回率(recall)的聚类评价指标。
本文在实验中使用算法分别为每个微博用户抽取了n=5,6,7,8,9,10个词汇作为候选主题词,与人工标引词汇比较,分别计算每个微博算法下的精度、召回率和F指数,对于每个n值,计算全部微博用户指标的平均值作为总体的F-measure值,实验得到的平均指标,说明在发现和抽取表示主题语义的词汇时,LDA主题词算法的表现要略优于TFIDF算法(见图2)。
6 分析与讨论
本文的分析和实验基于被提及的微博用户与相关微博文本之间的联系,在实验中按照被提及的次数选取了前200位微博用户,按用户类型笔者将这些用户分为新闻媒体、政府微博、企业微博、明星名人、专业人士五类,经过主题聚类和主题词抽取,可以得到以下一些结论:
(1)提及关系分析可以发现特有微博用户联系。在其他微博研究中,不参与发布、转发和评论的微博用户通常被忽略,被认为与事件无关。本文研究的200位微博用户中有82位用户并未参与发布、评论和转发微博,占全部用户的41%,通过提及关系分析,发现了这些用户与相关事件之间的潜在联系。
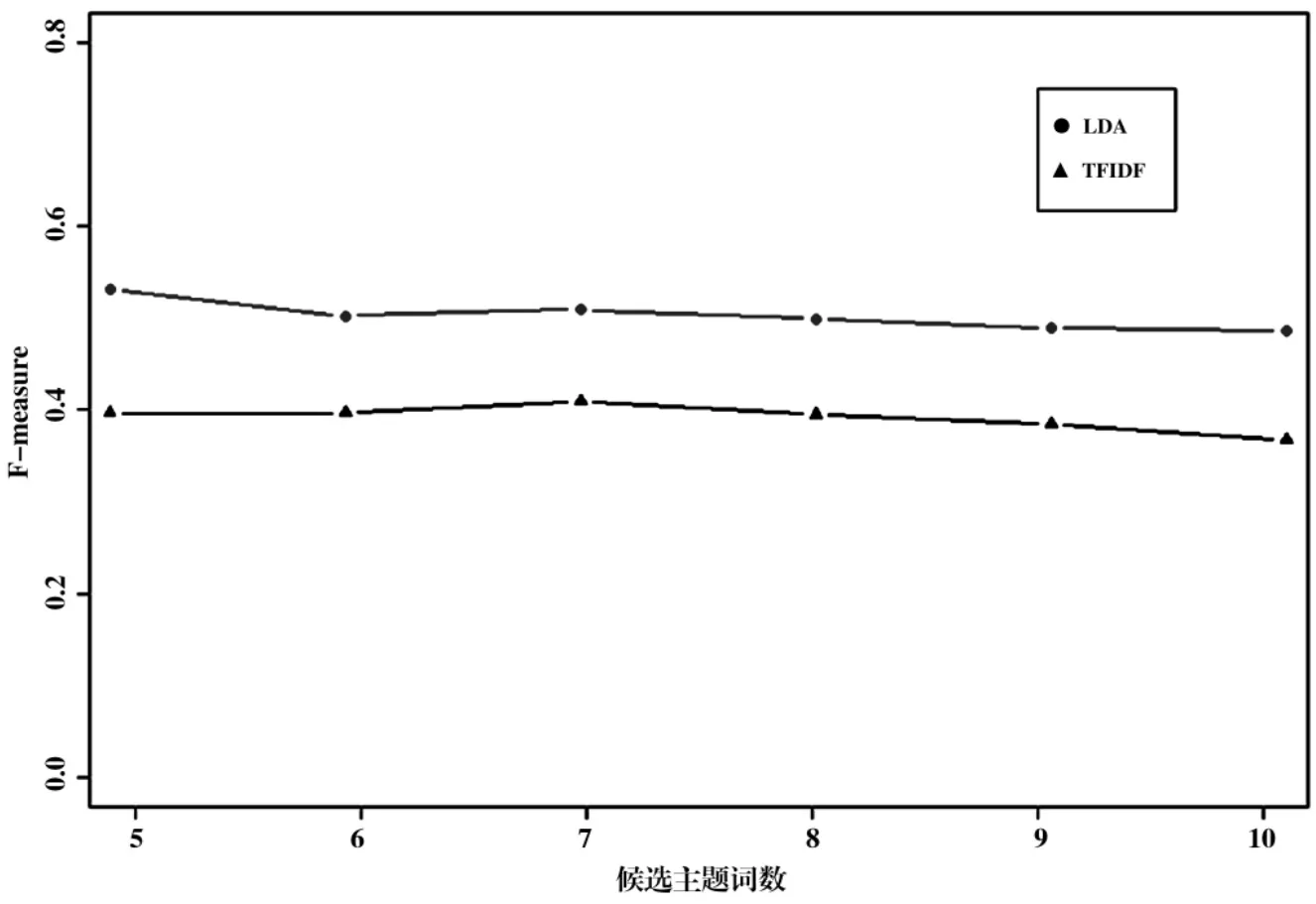
图2 主题词抽取算法F-measure值比较
(2)被提及的新闻媒体、明星名人类微博用户与多个主题相关。新闻媒体和明星名人类微博可以看做是“影响力型”微博,他们是公共话题的传播者和积极参与者,往往出现在多个主题事件中,大众提及这些用户的动机是为了征求关注,扩大传播。与这些用户相关的事件主题只是说明较受大众关注,与“影响力型”微博用户间没有特定的知识联系。
(3)被提及的政府微博和企业微博与相关事件存在潜在关联。政府微博、企业微博和专业人士微博可以看做是“专业型”微博,通过提及行为分析,可以分析这些微博与事件的隐性知识联系。以MH370事件为例,公众认为与事件相关,应及时发布准确信息的用户有“@飞常准”、“@马来西亚航空”、“@北京边检”等。在上海福喜事件中,被提及的微博用户包括“@上海食药监”和涉嫌使用上海福喜公司产品的洋快餐企业,虽然最初发现食品问题的是麦当劳,但肯德基、德克士等快餐企业也从福喜公司采购食品原料,因此食品主管部门应该及时检查这些企业并向公众说明。通过分析这些机构微博与事件的关联,有助于发现突发事件相关主体、及时发布最新消息并与公众沟通,减少损失。
(4)本文的主题词算法能够发现专业型微博用户的专业领域。例如在昆山爆炸事件中,被提及的用户“@赴汤蹈火的老兵”为“北京市公安消防总队原副总队长”,发现的相关主题词为“事故;粉尘;明火”。“@烧伤超人阿宝”为北京积水潭医院烧伤科主治医师,发现的相关主题词为“烧伤;病情;事故”。根据本文实验中专业人士微博的主题词知识图谱可以发现相关领域的权威专家,例如与孩子相关的有“@崔玉涛”和“@张思莱医师”等,这些都是知名的儿科专家(见图3)。
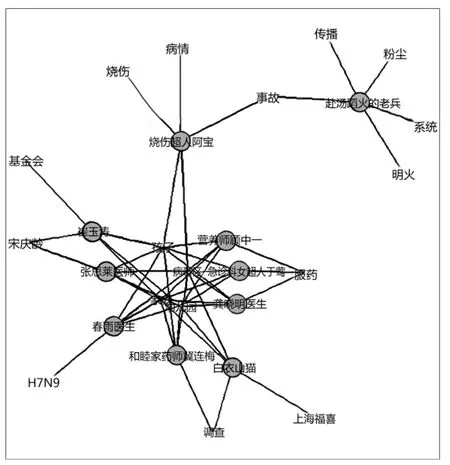
图3 突发事件中专业人士微博的主题词知识图谱
7 结语
本文探索了基于微博中的用户提及关系挖掘微博用户的知识联系,提出了一个微博用户知识发现模型,分析了不同类型微博用户与主题和特征词间的知识联系。实验证明通过LDA聚类的方法,可以有效地发现与专业型微博用户相关的主题和主题词,LDA主题模型是一种生成模型,具有扎实的概率理论基础,能够较好发现用户与词汇间的语义关系,本文下一步的研究方向是进行微博用户的主题演化研究。
[1]Kwak H,Lee C,Park H,et al.What is Twitter,a social network or a news media?[A].Proceedings of the 19th international conference on World wide web[C].ACM,2010:591-600.
[2]苏新宁.面向知识服务的知识组织理论与方法[M].北京:科学出版社,2014:37-38.
[3]吴恺,苏新宁,郑昌兴.基于用户行为信息的知识组织模型构建研究[J].情报资料工作,2015,202(1):14-19.
[4]王连喜,蒋盛益,庞观松,等.微博用户关系挖掘研究综述[J].情报杂志,2012,31(12):91-97.
[5]张培晶,宋蕾.基于LDA的微博文本主题建模方法研究述评[J].图书情报工作,2012,56(24):120-126.
[6]张晨逸,孙建伶,丁轶群.基于MB-LDA模型的微博主题挖掘[J].计算机研究与发展,2011,48(10):1795-1802.
[7]唐晓波,祝黎,谢力.基于主题的微博二级好友推荐模型研究[J].图书情报工作,2014,58(9):105-113.
[8]李亮.知识地图——知识管理的有效工具[J].情报理论与实践,2005,28(3):233-237.
[9]新浪微博.@功能上线,微博上交流更方便[EB/OL].[2015-03-20].http://blog.sina.com.cn/s/blog_61ecce970 100fhky.html.
[10]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].The Journal of machine Learning research,2003(3):993-1022.
[11]Thomas L G,Mark S.Finding scientific topics[J].Proc Natl Acad Sci U S A.,2004,101(Suppl 1):5228-5235.
[12]唐晓波,王洪艳.基于潜在狄利克雷分配模型的微博主题演化分析[J].情报学报,2013,32(3):281-287.
The Initial Exploration on Microblogger Knowledge Discovery with User Mention Relations
Finding high influence microblogger could help to identify high quality information source,develop the ability to communication of public,and therefore increase information literacy.This article proposes a microblogger knowledge model from user mention relations and analysis the relation of mentioned microblogger and microblogging contexts based on LDA model.Experiment shows the cluster model can find theme related high influence microblogger and feature words.
microblogger;mention relation;feature words;LDA model
G252.0
A
10.11968/tsygb.1003-6938.2015050
吴恺(1979—)男,南京大学信息管理学院博士研究生;王莹(1980-)女,南京大学图书馆馆员。
*本文系国家社会科学基金重大项目“面向突发事件应急决策的快速响应情报体系研究”(编号:13&ZD174)研究成果之一。
2015-04-13;责任编辑:魏志鹏
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
阅读与作文(英语初中版)(2019年8期)2019-08-27
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
电子技术与软件工程(2016年23期)2017-03-06
档案管理(2014年6期)2014-10-30
商品与质量·消费研究(2013年7期)2013-08-29
城市建设理论研究(2011年28期)2011-12-31
