
融合句义结构模型的短文本推荐算法研究
2015-11-21 05:35原玉娇罗森林潘丽敏
信息安全研究 2015年1期
原玉娇 罗森林 林 萌 潘丽敏
(北京理工大学信息与电子学院 北京 100081)
融合句义结构模型的短文本推荐算法研究
原玉娇 罗森林 林 萌 潘丽敏
(北京理工大学信息与电子学院 北京 100081)
(571033195@bit.edu.cn)
传统的基于协同过滤的推荐系统需要收集用户兴趣喜好等相关数据,在一定程度上涉及到用户的个人隐私,当前信息安全和隐私保护是数据挖掘领域的热点之一,为了有效避免用户信息泄露带来的安全问题,提出一种融合句义结构模型的短文本推荐方法.该方法以句子为研究对象,首先利用LDA主题模型构建文章-主题矩阵,划分子主题,然后利用句义结构模型抽取句子的语义格得到句子的语义特征,基于LDA主题模型使用句义结构计算句子两两之间的语义相似度,构建相似度矩阵,融合句子的语义特征和关联特征综合加权得到句子权值,以文章内最高单句权值衡量文章权值,将文章权值统一进行排序,按照排序顺序去冗余后依次推荐.在压缩比为0.5%的条件下,ROUGE-1值达到31.388%,ROUGE-SU*达到15.701%.实验结果表明,以句子为粒度的短文本推荐算法能丰富文本的特征信息、深化语义分析层次,在数据处理过程中未收集用户信息,从而有效避免用户信息泄露等安全问题,实现更加安全、快速向用户推荐文本.
微博;短文本推荐;主题模型;自然语言处理;信息安全
在信息推荐和检索领域,推荐系统的研究非常热门.而文本推荐又是推荐系统众多应用中使用最广泛、研究最热门的方向之一.推荐系统要解决的问题是按照一定的方法对待推荐的个体内容(如电影、书籍、文本等)进行打分,个体内容得分越高,其在最后的推荐结果中排名越靠前.系统将这些个体按得分从高到低依次推荐给用户.
随着互联网的飞速发展,Web平台上的各类资源呈现出几何级数的增长,文本资源更是如此.以新浪微博为例,用户点击某一热门话题,得到的是按照热门程度或发表时间排序的所有相关微博.然而,由于数量庞大,一方面用户需要花大量时间在结果中寻找自己真正关心需要的信息,另一方面用户得到的信息经常是不全面的,甚至是不相关的或者是重复的,信息获取的效率很低.因此对微博这种短文本信息进行推荐能大大提高信息获取的效率.
现有的文本推荐模型一般基于对文本集分析或者用户日志分析进行推荐.这些模型分别可进行基于聚类的推荐、关联规则推荐、协同过滤推荐,主要是基于规则和统计的并未充分考虑文本的语义信息,对于微博这种篇幅短小,特征词稀疏,缺失结构信息的短文本,必然出现推荐结果单一、覆盖不全面、准确率不高的问题.所以解决推荐的文本与话题相关度差的问题具有十分重要的意义.
1 相关工作
推荐算法经过多年的发展已经有了很多方法和技术.代表性的方法有基于协同过滤的推荐算法[1]、基于内容的推荐算法[2]、基于图结构的推荐算法以及混合推荐结构的算法.
基于内容推荐是最早被使用的推荐方法.它根据分析用户行为,为用户推荐相似的项目,最早主要应用在信息检索系统当中,很多信息检索及信息过滤里的方法都能用于基于内容推荐中,算法的根本在于内容的获取和定量分析,微博篇幅短小,关键词特征稀疏,并且单条微博内关键词的重复率不明显,传统的基于内容的推荐算法在处理微博数据时面临着数据稀疏性问题、可扩展性问题、特征提取等问题,因此需要结合微博特性与传统推荐算法的优点来进行文本推荐.基于协同过滤推荐算法从尽量考虑用户的偏好转为追求推荐高效率的商业推荐.在常见的电子商务网站中,协同过滤算法是通过参考用户对商品的喜好程度和评分来实现推荐的.协同过滤算法的核心思想就是将用户、商品和评价三者之间建立联系,这种推荐算法不太适合处理短文本信息.
近年来,针对微博的推荐系统也取得了一些成果,2009年Netflix比赛冠军Koren等人首次引入矩阵分解技术应用于协同过滤推荐系统,矩阵分解模型是目前为止在评分预测方向做得最好的基础模型[3].2013年Bian等人[4]提出融合微博多媒体信息生成可视化推荐文本.SumBasic[5]是一种基于词频统计的多文档摘要技术,Inouye等人[6]在Sharifi研究的基础上提出一种基于聚类的Hybird TF-IDF摘要方法,这种方法计算词的TF(term frequency)值是该词在语料库中出现的次数除以语料库中出现的词数,而计算IDF(inverse document frequency)值时,又将每篇微博作为一个单独的文档对待,计算方法为出现该词的微博总篇数除以语料中的微博总数.实验证明将此方法应用在推荐系统文本相似度计算中取得了很好的实验效果.在国内也有一些个性化推荐系统方面的研究成果:2009年北京大学杨建[7]利用LDA模型,结合网络新闻的特点,提出了一种新闻个性化推荐系统;清华大学的路海明等人[8]提出基于多Agent 混合智能实现个性化推荐;清华大学的冯翱等人[9]提出了基于Agent的个性化信息过滤系Open Bookmark等.
针对微博推荐的系统大多基于词形词频等统计信息进行特征抽取,忽略了文本内句子的成分信息以及语句之间的关联性,对文本语义信息分析不全面,因此导致仅仅基于词形匹配的相似度计算方法无法真实反映内容相似度;同时在计算文章权值时,未充分利用文章所处的子主题信息,导致推荐的文章与子主题的相关性较差.本文针对以上问题提出一种融合句义结构模型[10]的短文本推荐方法.
2 算法原理
针对现有方法推荐文本冗余度高的问题,一方面从语义内容分析的角度出发,利用句义结构模型分析语义项之间的依存关系扩充语义维度,利用句义特征准确表达语句信息及句子内容的相似性.针对现有推荐方法文章话题性差的问题,本文一方面通过LDA主题模型计算得到文章-主题矩阵,用聚类划分子主题的方法解决由于数据稀疏性导致子主题发现不全面的问题,另一方面从挖掘句子之间的隐藏语义联系及子主题信息的角度出发,提出一种抽取句子关联特征的方法.关联特征表示句子与话题的语义联系度,利用关联特征增强相似语句的语义联系.综合加权句子的语义特征和关联特征,计算文章权值实现推荐文章.
本文方法首先将文档集合分句、句子清洗、分词和词性标注得到预处理结果,然后对预处理结果分别计算语义权值和关联权值.计算语义权值时,统计预处理结果中所有实词出现的句子频率,按句子频率从大到小排序,选择前N个词作为主题词的种子词,加入哈尔滨工业大学的同义词林扩展版(HIT IR-Lab Tongyici Cilin (Extended))进行扩展,得到扩展后的主题词表.结合主题词表,分析句子的语义特征,包括词性词法特征以及句义结构特征,对各个特征线性加权,得到句子的语义权值.计算关联权值时,需要先对预处理结果进行句子相似度计算,得到句子两两之间的语义相似值,构建相似度矩阵,利用句子两两之间的语义相似值,计算句子与类内及类外其他句子的语义相似度,得到句子的关联权值.通过LDA主题模型计算得到文章-主题矩阵聚类划分子主题,最后对句子的语义权值和关联权值综合加权,得到句子权值.每篇文章中把单句最高权值作为文章的权值,最后依次选择子主题内权重最大的文章推荐,通过去除冗余操作确保最终推荐的文章质量.算法原理图如图1所示:

图1 算法原理图

图2 预处理原理图
2.1 预处理
分句、句子清洗是预处理的第1步,将微博中噪音数据进行处理.使用中国科学院的ICTCLAS分词系统对文档进行分词处理.将有效词数(名词、动词、形容词、数词、时间词等实词)小于4的句子去除.最后,对分词后的结果去除中英文停顿词(stopwords).预处理原理图如图2所示.
2.2 LDA子主题划分
LDA模型是一种常用的主题模型,由Blei等人[11]于2003年提出.它是一个生成性的3层贝叶斯网络,将词和文档通过潜在的主题相关联.类似于很多概率模型,LDA中也做了词袋(bag of words)假设,即在模型中不考虑词汇的顺序而只考虑它们的出现次数.
LDA 模型假设主题由词项以特定概率组成,文档集共同拥有这些主题,每个文档表示为主题的概率分布,概率分布由Dirichlet分布产生.图3 中外层的大矩阵表示文档集中的每一篇文档抽取主题概率分布θm,内层的小矩阵表示从主题分布中反复抽取得到该篇文档的词.

图3 LDA图模型
LDA由文档层的参数(α,η)确定,α反映文档集中隐含主题间的相对强弱,代表了所有隐含主题自身的概率分布.θm是文档-主题分布代表文档中各隐含主题的比重,β表示主题-词分布[12],Zm,n表示文档分配在每个词上的隐含主题比重,Wm,n是文档的词向量表示.其中K为主题个数,N表示该文档的词总数,M为文档集中文档个数.θm的概率密度公式如下:
(1)
其中,参数α是一个k维且αi>0的向量,Γ(x)是Gamma函数,k维Dirichlet随机变量θ是一个k-1维的单形.Dirichlet分布属于指数族,是一种简单的单形分布.
LDA文档的生成过程是:首先使用Dirichlet分布选择主题的概率分布,基于选出的主题选择文档的词:
1) 从Dirichlet先验η中为每个主题k抽取多项式分布βk,共抽取k个分布;
2) 从Dirichlet先验数α中第m篇文档抽取多项式分布θm,共抽取M个分布;
3) 对语料库中的第m篇文档和文档中的词汇wm,n:
① 从多项式变量θm中抽取主题zm;
② 从多项式变量βk中抽取词wm,n.
单条微博通常涉及一个或多个主题,微博的这个特征正好和LDA主题模型匹配,同时LDA主题模型是完全概率生成模型,可以直接利用成熟的概率算法来训练模型,模型使用方法也比较简单.LDA主题模型的参数空间规模是固定的,与文本集自身规模无关,更适用于大规模文本集.因此本文采用LDA主题模型来推断微博的主题分布.
实验使用Gibbslda++工具计算LDA主题模型得到文档-主题概率分布,对其进行聚类划分子主题.在压缩比为0.5%情况下,实验选取一个话题调整聚类个数,ROUGE-1取值变化如图4所示:

图4 子主题参数选择实验
子主题是围绕中心主题发生的现象、后果以及原因等的说明是对中心主题不同侧面的描述,在LDA主题模型计算得到文章-主题矩阵之后聚类划分子主题.
2.3 语义权值计算
通过分析句子的语义特征,挖掘句子的内容信息最终映射到文章的语义表达,目前对句子语义特征提取的主要方法是基于词法句法分析,本文在传统词法句法分析的基础上,融入句子的句义结构特征,深化了句子分析的深度,能够更好地挖掘文本的语义信息,以句子为单位进行语义挖掘能够更加准确、深入地表达文章信息.
编号1,2的特征项是对句子有效词的统计特征.一般认为名词(noun)、动词(verb)比其他词性更重要,赋权重为2,其余词性权重为1.话题、谓词、述题特征是句子的核心内容,若该句的以上特征在主题词表内,则说明该句的核心内容跟主题相关,出现的词数越多则该句与主题联系越紧密,越能表达主题中心的意义.一般项的句义功能是描述基本项和谓词,对其表达的内容做进一步说明和补充.因此,本文也将句子一般格中包含的主题词选为特征,作为对一般项和谓词的补充.句子的语义权重值计算方法如式(2)所示:
(2)
pcon(Sk)是句子Sk的语义权重值,Fi和ui分别代表语义特征的值和该特征的加权系数.本文使用的语义特征如表1所示:

表1 句子语义特征
2.4 联系权值计算
通过句子相似度计算出句子两两之间的语义相似值,构建句子的n维空间向量表示,形式如式(3)所示,空间中的每一维wk,j是句子Sk对Sj的相似度值:
V(Sk)=(wk,1,wk,2,…,wk,n).
(3)
句子的关联特征表示句子与话题的语义联系度,通过加权计算该句与不同子主题中其他句子的语义重合度得出.句子Sk对Sj的语义重合度C(Sk,Sj)定义为句子Sj的语义权重值Pcon(Sj)与Sj对Sk的句子相似度值S(Sk,Sj)的乘积,如式(4)所示:
C(Sk,Sj)=Pcon(Sj)×S(Sk,Sj).
(4)
构建无向图G(S,E),图中的每个节点S对应一个语句,边E(Si,Sk)表示语句Si与Sk的句子相似度值.节点S的度d是与S相连的边的数目,反映了S包含信息的重要程度:d越大则对应语句所关联的语句数目越多,那么这个句子所包含的信息越重要;反之亦成立.另一方面,如果一个节点的度比较大,那么与之相关联的语句也相应的比较重要.令节点S的初始值为句子的内容权重值,通过计算其他句子对该句的语义重合度得到句子的联系权重值.考虑到同一个子主题下句子联系紧密,设加权系数为1,不同子主题下句子的加权系数由子主题的平均句子内容权重得出.
2.5 文章权值计算
文章拆分成句子集合,文章权值大小取决于句子权值大小,目前计算句子重要性大部分都仅仅偏重于挖掘句子本身的内容,而忽略了句子所处“环境”的影响.一个值得推荐的文章,内容上不仅要紧扣主题,同时也应该与语料库中的其他文章联系紧密.本文所使用的句子权重计算方法不仅考虑了句子的语义信息同时也考虑了句子的关联特征.句子权值的计算公式如下:
P(Si)=α×Pcon(Si)+β×Prel(Si),α+β=1,
(5)
P(Si)是句子Si的最终权值,Pcon(Si)是句子Si的语义权值,Prel(Si)是句子Si的联系权值,参数α调整语义权值和联系权值的权重.
2.6 文本选择
在得到热点话题下所有子主题内每篇文章权值后通过计算子主题重要性确定文章推荐的顺序以及数目,其中子主题重要性与2个方面因素有关:子主题包含的文章数目以及子主题内文章的平均权重. 如果子主题内包含的文章数目越多、文章的平均权值越大说明该子主题越重要,被推荐的可能性越大.子主题重要程度计算公式如下:
(6)
其中,S(Ci)表示子主题Ci的得分,Pave(Ci)表示子主题Ci的文章的平均权值,k表示子主题个数,Ni表示子主题Ci包含的文章个数.参数θ调整子主题内文章的平均权值和文章数目的权重,一般认为两者同样重要,本文θ取0.5.
(7)
其中,TCi表示子主题Ci的文章抽取个数,S(Ci)表示子主题Ci的得分,k表示子主题个数,R代表压缩比的值,在这里R取0.5%,Nj表示不同子主题内文章的数目.
推荐文章时,选择的文章不仅要与主题的相关度高,同时在内容上与其他待推荐文章的冗余度尽可能小,在推荐的过程中通过计算文章的相似性大于指定阈值则排除确保推荐的文章能从不同侧面反映热点话题的内容.
3 实验分析
3.1 数据源
实验数据采用NLP&&CC会议2013年中文微博观点要素抽取评测语料.该语料包含2013年3月的微博话题,类别样本不平衡,实验数据的具体描述如表2所示.其中,文本有效长度是指经过分词去除停用词后每篇微博包含的词的个数.由北京理工大学信息系统及安全对抗实验中心的博士、硕士对每个话题生成压缩比为0.5%的标准推荐文本.其生成过程如下:首先每3人对同一话题文本集提取不同压缩比的人工摘要,然后由自然语言处理小组的10名博士、硕士对3份人工摘要进行评价并计算平均得分,将平均得分最高的摘要作为标准摘要放入标准摘要集,如果得分相同则都放入标准摘要集中.

表2 实验数据
3.2 评价方法
本文采用多文档摘要的通用评价方法ROUGE[13]toolkit(v1.5.5)作为评价标准.ROUGE方法通过计算候选摘要与标准摘要的词单元重合度来区分候选摘要的质量,计算的值包括ROUGE-N,ROUGE-W(本文w取1.2)和ROUGE-SU等.具体计算公式如下:
(8)
(9)
(10)
其中,n代表n-gram的长度,S表示文档,其中下标ref表示文档属于标准摘要,下标candi表示文档属于待评价摘要,Countmatch(gramn)表示同时出现在待评价摘要和标准摘要的n-gram的个数,Count(gramn)为标准文摘中的n-gram个数.
3.3 对比实验
为了验证本文方法的有效性,建立了2个对照方法与本文方法进行对比实验.
Hybird TF-IDF[6]是Inouye于2011年提出的一种基于聚类的微博话题摘要方法,该方法计算词的TF(term frequency)值是该词在语料库中出现的次数除以语料库中出现的词数,而计算IDF(inverse document frequency)值时,又将每篇微博作为一个单独的文档对待,计算方法为出现该词的微博总篇数除以语料中的微博总数.并已被证明比一些主流的多文档摘要方法效果要好.SumBasic[5]是经典的基于词频统计的多文档摘要方法,在DUC06测评大会上按代表性指标排序排名第三,并已取得实用.把这2种方法应用到微博推荐系统中,在压缩比分别为0.5%的条件下,3组系统的实验结果如图5、表3所示,图6、表4展示了本文方法处理6组话题ROUGE指标值.

图5 对比实验结果
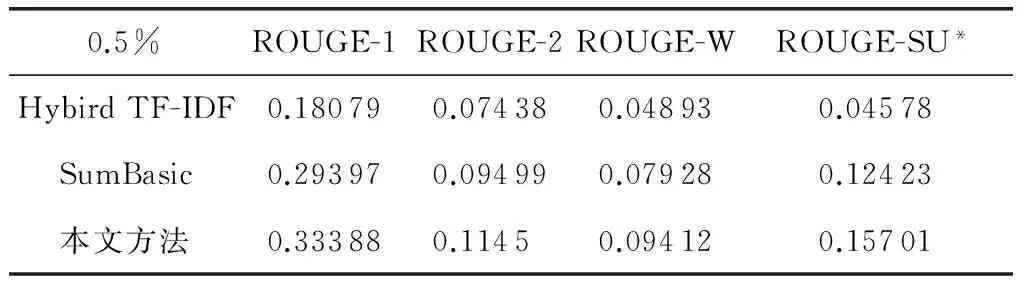
0.5%ROUGE-1ROUGE-2ROUGE-WROUGE-SU*HybirdTF-IDF0.180790.074380.048930.04578SumBasic0.293970.094990.079280.12423本文方法0.333880.11450.094120.15701

图6 不同话题的ROUGE值

0.5%ROUGE-1ROUGE-2ROUGE-WROUGE-SU*毒玩具0.325280.142860.099940.12633查韦斯0.291310.052910.081020.1176曼联vs皇马0.300610.070510.075530.12728王语嫣0.339170.075370.09310.16558锤子ROM0.35730.138240.086740.17275中国方言式英语0.389610.207110.128430.23254
4 结 论
本文提出一种融合句义结构模型文本推荐方法.在数据处理过程中未收集用户信息从而有效避免用户信息泄露等安全问题,同时能够产生较优的推荐结果,以满足推荐系统的需要.本方法首先利用LDA主题模型计算得到文章-主题矩阵划分子主题,用句义结构模型分析句子的语义特征得到语义权值,基于LDA主题模型使用句义结构计算句子内容相似值,得到句子的关联特征.最后综合加权句子内部语义特征和外部关联特征得到句子权值,通过计算得到文章权值.实验证明通过LDA主题模型划分子主题的方法,可以有效解决由于微博文本数据稀疏导致的子主题发现不全面的问题,分别计算句子的语义权值和关联权值深化语义分析层层次,提高了语义挖掘的深度使得文章相似性计算更准确,考虑文章与主题的相关性,从而使得推荐文章与子主题相关性更高.
下一步研究的重点是引入句子结构项之间的依存关系作为特征,完善句义结构模型的特征体系,计算文章权值时引入新的特征性,从而生成更高质量的推荐系统.
[1]Wang J, Li Z, Yao J, et al. Adaptive User Profile Model and Collaborative Filtering for Personalized News[M]. Berlin: Springer, 2006: 474-485
[2]Barranco MJ, Martinez L. A method for weighting multi-valued features in content-based filtering[G]LNAI. Berlin: Springer, 2010
[3]Koren Y, Bell R. Recommender Systems Handbook[M]. Berlin: Springer, 2011: 145-186
[4]Bian J, Yang Y, Chua T. Multimedia summarization for trending topics in microblogs[C]Trends in Applied Intelligent Systems. New York: ACM, 2013: 1807-1812
[5]Vanderwende L, Suzuki H, Brockett C, et al. Beyond SumBasic: Task-focused summarization with sentence simplification and lexical expansion[J]. Information Processing and Management, 2007, 43(6): 1606-1618
[6]Inouye D, Kalita J K. Comparing Twitter summarization algorithms for multiple post summaries[C]Proc of the 3rd IEEE Int Conf on Privacy, Security, Risk and PASSATSocialcom2011. Los Alamitos, CA: IEEE Computer Society, 2011
[7]杨建. 基于LDA模型的新闻个性化推荐系统后台的设计与实现[D]. 北京: 北京大学, 2009
[8]路海明, 卢增祥. 基于多Agent混合智能实现个性化网络信息推荐[J]. 计算机科学, 2000, 27(7): 32-34
[9]冯翱, 刘斌, 卢增祥, 等. Open Bookmark——基于Agent的信息过滤系统[J]. 清华大学学报: 自然科学版, 2001, 41(3): 85-88
[10]罗森林, 韩磊, 潘丽敏, 等. 汉语句义结构模型及其验证[J]. 北京理工大学学报, 2013, 33(2): 166-171
[11]Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(45): 993-1022
[12]杨潇, 马军, 杨同峰, 等, 主题模型LDA的多文档自动文摘[J]. 智能系统学报, 2010, 5(2): 169-176
[13]Harabagiu S M, Hickl A. Relevance modeling for microblog summarization[C]Proc of the 5th Int AAAI Conf on Weblogs and Social Media. Menlo Park, CA: AAAI, 2011

原玉娇
硕士研究生,主要研究方向为文本安全、中文信息处理.
yuanyujiao@bit.edu.cn

罗森林
教授,博士生导师,主要研究方向为信息安全、媒体计算、生物信息处理.
luosenlin@bit.edu.cn

林 萌
硕士研究生,主要研究方向中文摘要、文本信息处理.
lemon0919@bit.edu.cn

潘丽敏
工程师,主要研究方向为图像处理、信息安全.
panlimin@bit.edu.cn
Research on Short Text Recommendation Merging Sentential Semantic Structure Model
Yuan Yujiao, Luo Senlin, Lin Meng, and Pan Limin
(SchoolofInformation&Electronics,BeijingInstituteofTechnology,Beijing100081)
Based on the collaborative filtering traditional recommendation system need to collect relevant data of user’s interests and p
, to a certain extent involved in the user’s personal privacy, current information security and privacy protection is one of the hot field of data mining, in order to avoid disclosure of user information with to security issues, In this paper, we propose a new short text recommendation method based on sentential semantic structure model. We fist use topic model structure text-theme matrix to several subtopics. We employ sentential semantic structure model to extract semantic features to get sentential semantic features. Then LDA topic model fusing sentential semantic structure model is used to calculate the pairwise sentence similarities and construct the similarity matrix. Then we acquire sentential relationship features. At last, combining both sentential semantic features and relationship features, the most informative text are extracted from each subtopic. Experimental results demonstrate the improvement of our proposed framework, ROUGE-1 value is 31.388% while ROUGE-SU*value is 15.701% on compress ratio at 0.5%.The results indicate that introducing sentential semantic structure model can better understand sentential semantic and using both sentential semantic features and relationship features can also enrich the features representation.
microblog; short text recommendation; topic model; natural language processing; information security
2015-07-30
国家242信息安全计划资助项目(2005C48);北京理工大学科技创新计划重大项目培育专项(2011CX01015)
TP391
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
开放教育研究(2020年2期)2020-03-31
江苏通信(2018年4期)2018-12-04
自动化学报(2017年7期)2017-04-18
中国修辞(2017年0期)2017-01-31
信息安全研究(2016年4期)2016-12-01
中国社会历史评论(2016年2期)2016-06-27
