
针对事件驱动软件的测试集排序准则
2015-12-20 06:54张圣迪高建华
计算机工程与设计 2015年12期
张圣迪,高建华
(上海师范大学 计算机科学与工程系,上海200234)
0 引 言
事件驱动软件是软件的一个重要分支,GUI软件与Web软件是其中最典型的例子。它们都在测试方面面临着巨大的挑战和困难。这两类软件的测试难度主要在于:其一,它们是基于事件驱动的,图形化用户界面可以为用户提供大量的输入事件,要完全测试这些状态则需要大量的测试,同时,这些输入事件之间还可能会有一定的关联性;其二,它们都具有以用户为中心的性质,它们在开发维护的过程中经常要发生改变,而这又将带来更多的测试需求。测试集排序准则可以对测试集排序,使得可以以最少量的代价来最大程度的进行软件测试。虽然WEB 软件和GUI软件在各自的领域都有不少的研究学者对它们的测试进行研究,包括测试理论、模型、方法,但将GUI软件和WEB软件整合在一起的研究却非常少,缺少合适的研究工具以及合适的模型是主要的因素。Sreedevi等[1]对于缺少模型的问题作了一系列的研究,他们提出了一个将GUI软件和WEB软件整合在一起研究的简单模型,并且他们还提出了一些基于这个模型的测试集排序准则。本文针对这几种准则进行了扩展,提出了3种同时用于GUI软件和WEB 软件的测试集排序准则,并以一个实验来验证其有效性。
1 WEB软件测试与GUI软件测试的特点和共性
1.1 GUI软件与GUI软件测试
GUI软件包含了软件的前端图形化界面以及后台的代码。它从一个固定的事件集中接受输入并产生确定的输出。用户通过触发相应的事件来与软件交互,事件通常以某些方式被绑定在前端的某些控件上,当用户对控件实行特定的操作就触发了相应的事件,而程序则改变自身的状态来进行回应。
事件绑定机制使得用户的输入变得不确定,一方面用户可以随意触发本状态下可以触发的所有事件;另一方面即使是同一个事件,所传递的参数不同,软件程序执行结果和路径就不同。不仅如此,有些事件之间还具有关联性,它们的执行顺序也会影响程序的执行结果。由于用户输入的不确定性以及事件之间所具有的关联性直接导致了GUI软件测试的困境。研究结果表明,GUI软件的错误与它所隐含的业务逻辑有关[2]。大量可能的事件使得测试的成本巨大且效率低下,而以用户为中心的性质和用户触发事件的随意性也使得自动化测试难以实现。
GUI软件测试的研究成果主要有基于模型的测试用例生成、执行、回归测试[3]。有研究将基于代码覆盖的测试集排序准则和基于模型的测试集排序准则进行对比,得出通过基于模型的测试集排序准则排序的测试集能更快发现软件中的错误的结论[4]。
1.2 WEB软件与WEB软件测试
WEB软件包含了一个页面的集合,用户可以通过浏览器借助网络访问它们。WEB软件接收事件作为输入,并改变自身状态。现在的WEB软件前端通常使用图形化用户界面来与用户交互,所以其与GUI软件有共通之处。WEB软件的页面呈现可以是静态的编写,也可以通过服务端代码获取数据后填充而形成动态页面。事件的绑定和触发也与GUI软件类似,但WEB软件通常基于URL 的方式来进行请求。WEB软件分成客户端和服务端两部分,它们各自可以由很多种语言来实现,WEB软件的语言构成可以比较复杂,因此它的测试难度也就比较高。
WEB软件测试的主要研究成果有:基于用户会话的测试用例排序和删减[5,6],这些准则基于测试长度、请求序列的出现频率以及参数值对的覆盖情况进行排序;基于代码覆盖的回归测试排序和删减[7,8];基于方法覆盖率作的测试集排序准则[9]。
WEB软件测试目前的测试工具大多基于捕捉/回放机制的测试软件,捕捉测试者与程序的交互并将其重放[10]。与GUI软件类似,用户输入的不确定性以及事件之间所具有的约束性和事件执行的不同顺序使得WEB软件的测试也面临着巨大的挑战。
1.3 WEB软件与GUI软件的共性
WEB软件与GUI软件都使用图形化用户界面,所以它们的前端有很多相似的地方,这一点Sreedevi Sampah等已经做了研究并且归纳出了一个模型[1]。而同作为事件驱动软件的两大分支,它们后台也有很多的相似之处。
(1)它们通常都采用面向对象的编程方式,实例化对象并调用它们的方法来完成功能。
(2)它们的后台代码都采用分层的模式来逐层调用,基本不允许跨层调用以及下层调用上层方法。
(3)它们方法的复杂度和它们潜在的业务逻辑或是功能的复杂性成正比,功能或业务逻辑越复杂,方法的复杂度就越高。
(4)一个事件对应一个入口,通过入口就可以找出事件的调用路径。通过静态扫描步骤得到调用路径时,并不能准确判断调用路径,对于一个事件扫描得到的调用方法数量会多于实际情况。
2 测试集排序准则的理论
2.1 需要优先测试的方法
一个GUI和WEB 软件中所用到的方法非常多,从中定义出需要优先测试的方法则是比较重要的。一般有两种:
(1)程序的业务核心方法。业务核心方法是指完成程序核心业务流程所必须经过的方法,特点是使用频繁。这种方法可以通过使用次数来辨别,根据使用日志等方法生成的测试用例中此类方法的调用次数都明显多于其它方法。另外根据使用次数也可以筛选出测试集中期望重点测试的方法,因为期望重点测试的方法往往会在测试集生成时被赋予较大的比重。业务流程中核心实体依据业务逻辑会发生的多种状态转换,状态转换通常有严格的限制使得核心实体之间具有复杂的相互依赖。它们的业务逻辑和软件中许多其它的模块都有牵连。这样的方法实现的过程中容易产生出错和疏漏,甚至会存在设计缺陷导致软件中断和数据异常从而造成损失。这样的方法具有危害性大影响面广的特点。既为了软件质量也为了用户体验,这种方法应该被优先测试。
(2)程序中实现复杂的方法。这种方法实现复杂,大多承担着数据类型转换、文件格式转换、图表统计导等高级功能,在实现之中不仅数据的处理容易发生错误,类型的转换也容易发生异常。编码中往往会留有一些漏洞使得程序存在安全隐患,这样的方法也应该被优先测试。
2.2 事件入口
事件入口在本文中指与事件绑定的处理事件的后台方法。GUI软件和WEB软件都是事件驱动的,每一个事件都对应一个事件入口。如JSP 的WEB 软件中的表单 (form)有一个action属性,通过配置这个属性可以为form 绑定事件,图1 中 的form 指 定 的action 为 “findFinOrder”则form 绑定了事件 “findFinOrder”。图2配置事件 “findFin-Order”由finFinOrder()方法处理,提交form 就触发了事件 “findFinOrder”,而finFinOrder()方法就是事件 “find-FinOrder”的事件入口。通过finFinOrder()方法就可以得到其调用路径上的所有方法加以测试。对于GUI软件则是触发绑定在控件上的事件即可,后台会有监听器 (Liste-ner)监听并交给对应的方法处理,此对应方法就是事件入口。事件入口在文本中作为调用路径的起点。
2.3 调用路径
调用路径指的是事件所对应的事件入口所可能调用的方法组成的树形结构,它可以对软件代码进行静态扫描得到。本文中事件的调用路径用于统计测试用例调用了哪些方法以及方法在测试集中被调用的次数,本文提出的测试集排序准则将方法在测试集中的被调用的次数作为排序依据之一。
静态扫描得到的调用路径有以下特点:
(1)它包含的节点数可能多于单次实际调用的方法数量。由于不带参数的静态扫描无法精确定位程序的调用路径,故会将如分支结构中if和else会执行的方法都纳入统计,导致得到的调用路径的节点数量会多于实际。
(2)以事件入口为根节点,以事件入口所可能调用的方法为子节点,并根据它们的调用关系构成树形结构。由于GUI软件和WEB 软件都采用逐层调用的方式编码,上层调用下层的方法完成功能,并基本不允许跨层以及反向调用,故调用路径可以以树形结构描述。
如图3为调用路径的图示,调用方式为逐层调用。

图1 部分JSP代码

图2 Struts2配置
图3 调用路径
2.4 圈复杂度
圈复杂度是描述方法复杂度的指标,它基于控制流程图计算,分支和循环越多,对应的圈复杂度越高。圈复杂度数量上表现为独立路径条数,即合理的预防错误所需测试的最少路径条数。根据方法的圈复杂度可以找出实现复杂的方法,因为实现复杂的方法通常都会有较多的分支和循环来组成,其圈复杂度也就比较高。可以说圈复杂度是最接近方法复杂程度本质的度量方式。本文中的测试集排序准则将方法的圈复杂度作为排序的依据之一,找出实现复杂的方法并给予高优先级。
方法的圈复杂度基于控制流程图进行计算,如图4所示,圈复杂度在本文中应用计算方法:V(G)=e-n+2p。e是控制流图中边的数量,n是代表其中节点的数量,p代表其中组件数,由于控制流程都是连通的所以p为1。圈复杂度为V(G)=6-5+2=3。
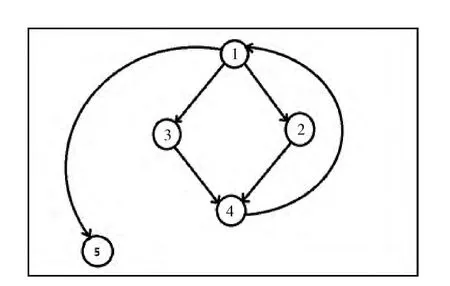
图4 方法的控制流程
已有工具可以计算出每个方法的复杂度如,Maven的JAVANCSS插件,在多数代码质量管理软件中圈复杂度都是一项重要指标。
2.5 测试集排序准则
测试集排序准则定义如下,给定一个任意测试集T,T中所有测试用例可能的排序集合P 以及P 到实数集的映射f,测试集排序准则的目标是要找出P’∈P,使得对于任意的P’’∈P 且P’≠P’’的 情 况 下,f(P’)≥f(P’’)成立。
f是一个估值函数,决定以什么标准确立测试优先级的高低。测试优先级的高低可以以覆盖率、测试代价等标准确立。
3 排序算法与测试集排序准则
本文提出的排序算法基于贪心算法,以一个未经过排序的测试集作为输入,对测试集中所有测试用例进行排序,并输出排序完成的测试集。
在该排序方法中会调用的方法:
(1)coverage()接受单个测试用例t为输入,输出t中测试集排序准则所关心的元素。例如以覆盖方法数量作为衡量标准排序,coverage(t)返回t所覆盖的方法的集合。coverage()可依据测试集排序准则的需求去除重复元素。
(2)allcoverage()接受测试集T 为输入,返回测试集T 中每个测试用例t中测试集排序准则所关心的元素之合。例如以覆盖方法数量作为衡量标准,输入测试集中有 {t1,t2}两个测试用例,那么返回的就是t1与t2覆盖方法集合的合。该方法同样可以依据测试集排序准则的需求去除重复元素,除去重复元素后,结果相当于对测试集中的每个测试用例运行coverage()并取并集。而对于不关心重复元素的测试集排序准则,allcoverage()通常返回空集合。此方法的输入测试集T 一般为已被选择优先测试的测试用例的集合,主要目的是引入反馈机制,对已经被覆盖过的方法做出权值递减等处理。
(3)score()接收coverage()和allcoverage()的返回值作为参数。计算测试用例的评分,评分是排序的最终依据。
3.1 排序算法Order Test Suite
步骤:
(1)接收未排序的测试集T 为输入,其中的测试用例记为t1……tn;
(2)构造一个空的集合R 来存放输出排序完成后的测试集;
(3)统计测试集中所有方法的圈复杂度以及测试集中事件的调用路径;
(4)设置标志变量p为MININT;
(5)对于R 运行allcoverage()方法,对于某些不关心重复元素的测试集排序准则,allcoverage()返回空集合;
(6)对于测试集T 中的测试用例t运行coverage()方法;
(7)将coverage(t)的返回值以及allcoverage(R)的返回值传递给score()运算;
(8)将score()返回值v与p比较,若v大于p则将s赋值给p并将测试用例t作为候选测试用例记为s,若已有s则用t替换原来的s。若v小于p则不做处理。若v=p则随机决定是否将t作为候选测试用例;
(9)重复 (5)~ (8)直到所有T 中的测试用例都被评分,将测试用例s插入到R 的尾部,并将s从T 中移除;
(10)重复 (4)~ (9)直到T 中所有测试用例都被移除,即所有测试用例都被排序,输出R。
3.2 测试集排序准则
3.2.1 APSFuncation准则
这种测试集排序准则引入方法被调用的次数,来确定哪些方法是业务上比较重要的,覆盖这些重要方法的测试用例应该被优先执行。对于事件驱动软件,均有必须实现的核心功能,在软件运作中会被经常使用。这些功能往往都牵涉到很多的类和数据库中的表,这样的功能往往业务逻辑是比较复杂的,比较容易出错。
对于这个测试集排序准则,需要使用事件的调用路径,根据事件调用路径统计测试集中所有被覆盖的方法被调用的次数,存放在一个以Java实现的列表中,每个统计出的方法信息以 {method,testcase,value}形式存放,其中method是方法,testcase是调用method最多的测试用例,若有相同调用次数的测试用例则随机选取,value是method在整个测试集中被调用的总次数。如M8方法被调用5次,其中t1调用M8次数最多,则记为 {M8,t1,5}。coverage(t)会在列表中寻找testcase为测试用例t的记录,并寻找其中value值最大的记录并返回value值。此测试集排序准则allcoverage()返回空集合所以score()对coverage()的返回值不做任何处理直接返回,并将其作为测试用例的评分。
3.2.2 WeightedFunction准则
这个测试集排序准则引入方法的圈复杂度来找出实现复杂的方法,测试用例所覆盖的方法的圈复杂度的总和越高,它所被给予的测试优先级越高。
这个测试集排序准则需要使用事件的调用路径以及测试集中方法的圈复杂度,测试集中方法的圈复杂度以列表形式储存,其中的每一个元素都是 {method,cycle}形式,method是方法,cycle是方法的圈复杂度。coverage(t)获取测试用例t所调用的各个方法的复杂度信息,将测试用例t调用方法的圈复杂度作为权值,将其相加作为返回值。
此测试集排序准则allcoverage()返回空集合,sorce()将coverage()的返回值作为测试用例评分返回。
3.2.3 WeightedFunctionWithFeedback (WFFB)准则
前两节提出的测试集排序准则从两个不同的方法对测试集进行排序,但是两者都有一些共同的缺点:
(1)前两节提出的测试集排序准则都专注于一个单一属性在测试集中的覆盖率对测试集进行排序。这样的测试集排序准则针对性强,但通常并不能非常好的应对所有测试集。对于某些测试集排序效果很好的测试集排序准则可能对于另一些测试集效果并不佳。生成测试集的策略和项目本身的性质等都可能影响排序测试集排序准则的效果。如对于圈复杂度相近的方法组成的测试集中,圈复杂度作为排序依据的效果会大大降低,反之亦然。
(2)前两种方法的另一个主要缺点是没有反馈机制。由于测试用例执行有先后,同一个方法在测试集中可能会被执行多次。而因为它的一部分代码在前一次或几次的执行中已经被测试了,所以一个已经被执行过的方法的重要性应比它未执行时低。而前两种方法对于已被执行过的方法并未做出处理。
本节提出的WFFB 准则在WeightedFunction的基础上与APSFunction结合,将圈复杂度和方法被调用的次数结合共同作为排序依据。不依据单一属性排序可以增加测试集排序准则效果的稳定性,更适用于普遍情况,以此来一定程度弥补缺点 (1)。
同时,本节提出的WFFB准则将会引入反馈机制来解决缺点 (2)。当有测试用例被选择优先执行时,这些测试用例所覆盖的方法在接下来的排序中的权值会降低。权值降低的公式为
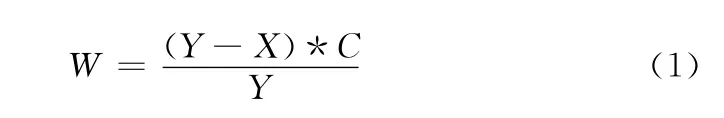
式中:C——方法的圈复杂度,Y——方法在测试集中总共被覆盖的次数,X——方法在先前被选择的测试用例中被覆盖的次数,W——得到的新权值。式 (1)可以确保重复执行时方法的权值递减,同时又可以根据测试集的情况自动调节。覆盖高调用次数以及高复杂度的方法的测试用例优先级最高,而覆盖高复杂度低调用次数的方法的测试用例和覆盖低复杂度高调用次数的方法的测试用例则相对持平。从而补足了依据单一属性的不足。
该测试集排序准则同样需要使用事件调用路径以及测试集中方法的圈复杂度。在WeightedFunction 的基础上,算法在每一轮排序中,将现有的排序结果集R 作为输入参数传入allcoverage()中,返回R 中覆盖的方法,统计这些方法被覆盖的次数X。对于每个测试用例t,score()对每个其覆盖的方法,将X 与方法总共被调用的次数Y 以及方法的圈复杂度C 代入公式,更新方法在这一轮中的权值。将t所覆盖的每个方法的权值相加作为测试用例的评分。
4 示 例
表1所示,t代表测试用例,t1、t2、t3组成了一个测试集T。M 代表方法。t1包含两个事件E1、E2,两个事件的入口分别是M1和M3;t2包含事件E3,入口为M6;t3包含事件E4,入口为M8。图5表达了各个方法间的调用情况,M1会调用M2和M4,M3会调用M4等。M 边上的数字代表其圈复杂度,在表2中列出。本文的方法的圈复杂度由方法的控制流程图基于McCable方法计算得到,即V(G)=e-n+2p。

表1 示例包含的事件和事件入口
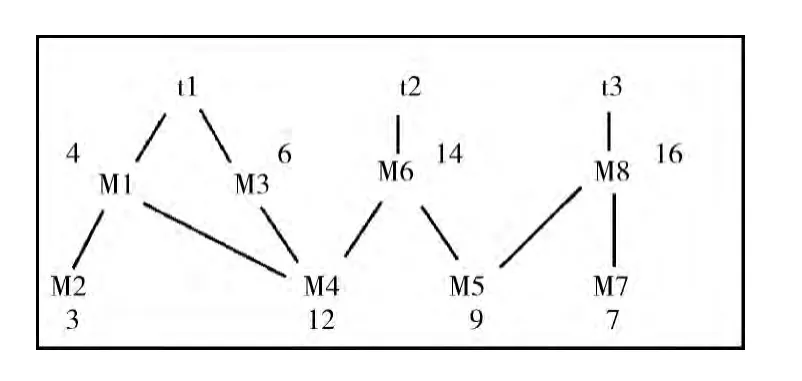
图5 示例各个事件可能调用的方法树

表2 各个方法的圈复杂度
4.1 APSFuncation排序示例
对于示例,由事件调用路径统计得到的方法在测试集中被调用的次数见表3,对于方法M5,t2和t3拥有相同的调用次数故使用随机来决定,假设随机结果为t2,由于与t1相关的最大值是3所以coverage(t1)返回3,同理coverage(t2)=2,coverage(t3)=1,此测试集排序准则allcoverage()返回空集合而sorce()对coverage()的返回值不作处理,所以排序结果为t1,t2,t3。
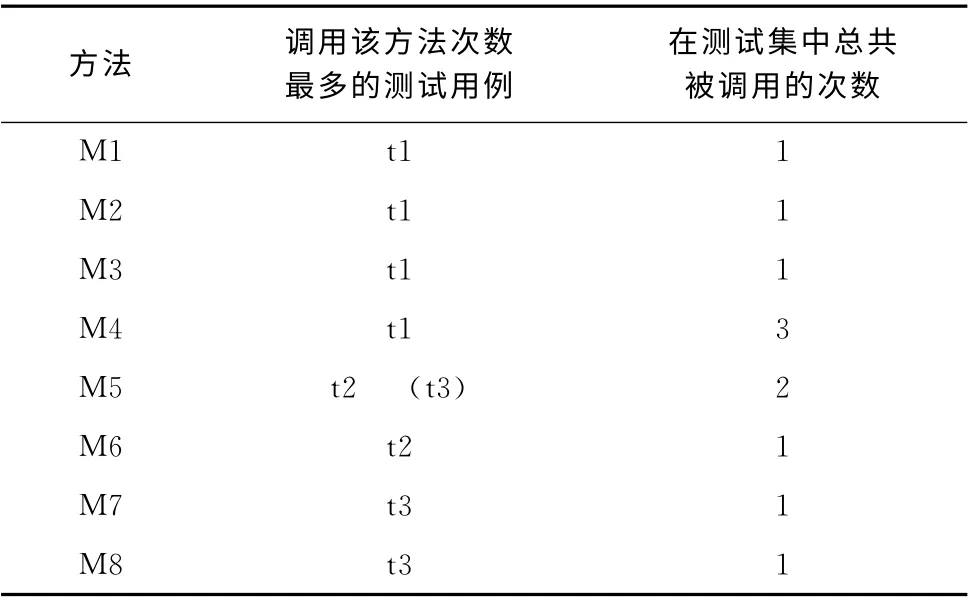
表3 各个方法被调用的情况
4.2 WeightedFunction排序示例
对于示例,方法的圈复杂度见表2,所以对于各个测试用例评分结果见表4。

表4 WeightedFunction排序过程
此测试集排序准则allcoverage()返回空集合而sorce()对coverage()的返回值不作处理,所以排序结果是t1,t2,t3。
4.3 WFFB排序示例
对于示例,方法的圈复杂度见表2,所以对于各个测试用例第一轮的测试用例评分见表5。

表5 WFFB的第一轮排序
第一轮评分的结果是t1 被选为优先测试的测试用例,将t1放入R 中。随后开始第二轮测试用例评分。
如表6所示,由于M1、M2、M3、M4在t1中已被覆盖过,故它们在第二轮的评分中权值有所降低。以M4 为例,查表3可知,M4 在测试集中总共被调用3 次故Y 为3,而M4在已被选择的t1中被覆盖2次故X 为2,M4的圈复杂度为10故C为10,代入式 (1),本轮M4的权值为10* [(3-2)/3]=3.3,为原来的1/3。第二轮评分的结果是t3被选为优先测试的测试用例,将t3放入R 中。最后的排序结果为t1,t3,t2。

表6 WFFB的第二轮排序
5 实 验
表7中是 “BBS系统”的一部分,对这部分进行实验来研究一个问题:以上3个测试集排序准则的有效性如何?

表7 GAMEBBS的情况
测试评判标准我们使用APFD (average percentage of faults detected),APFD 是Rothermel定义的一个用来评估测试集排序准则效力的标准。公式如下
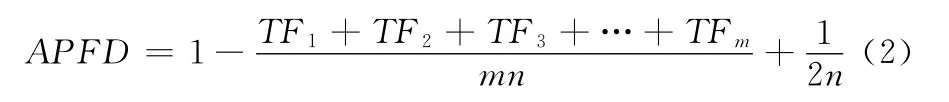
其中,n是测试集T 中测试用例的数量,m 是总共被测试出的错误数量,F 是所有被T 检测出的错误的集合。TFi是检测出的软件错误i的测试用例在T 中的排序位置。TFi越小APFD 就越大,所以排序在前的测试用例检测出的错误越多,那么APFD 就越大,测试集排序准则的效果就越好。
图6表示了GAMEBBS的部分方法调用图,将其导入到排序算法,再导入GAMEBBS中的各个方法的圈复杂度。最后,根据测试集的事件入口来获取对应的调用路径得到方法被调用的次数,依据方法被调用的次数信息和圈复杂度信息对测试集进行排序。使用的测试用例基于使用记录日志得到,工程中的错误由人工录入。
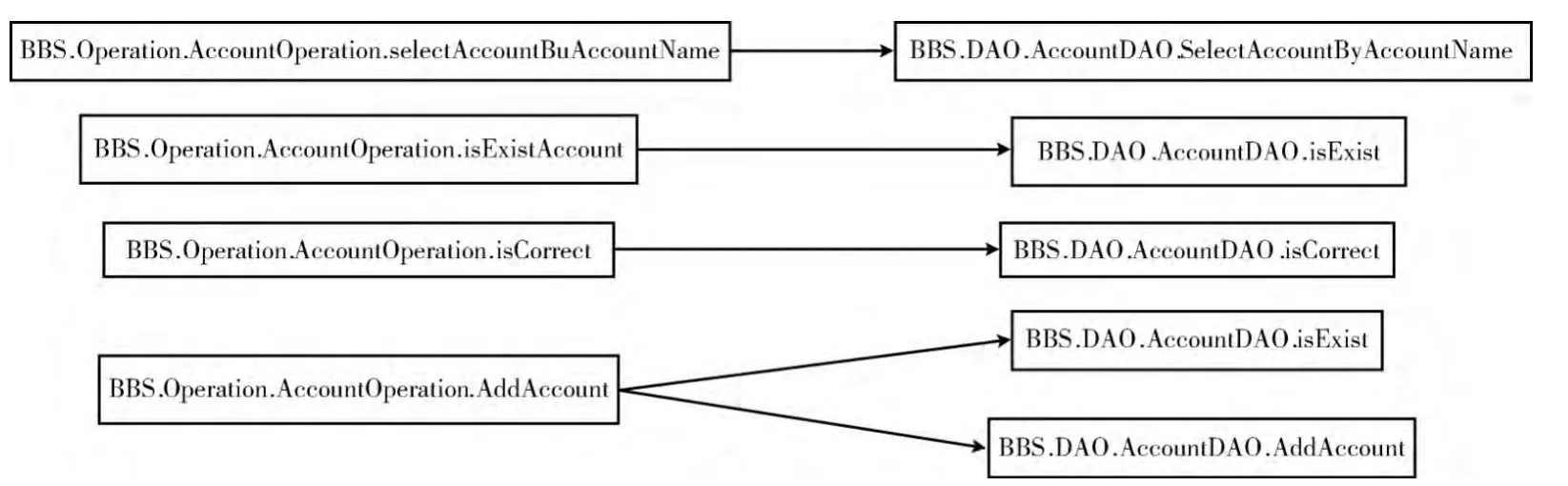
图6 GAMEBBS部分调用
此处引入了两个测试集排序准则进行辅助比较:GBest贪心最佳准则,给予发现最多错误的测试用例高测试优先级;Random 随机排序。
运行程序,得到的AFPD 情况如图7所示。
APFD 值列表,见表8。
从图7和表8中可以看出,由于WFFB综合考虑了方法在测试集中被调用的次数以及方法自身的圈复杂度,故WFFB的结果相比较于其它的测试集排序准则略优一些。而由于测试集中有一些复杂的导入和报表生成方法,并在其中布的错误数相对较多,所以WeightedFunction排第二。实验的测试集在各个调用数量上差距并不非常明显,所以APSFunction仅在Random之前。也印证了依据单一属性排序的测试集排序准则对于测试集的特性依赖较大。今后将进行更大量的实验以对这些测试集排序准则有一个更精确的研究结果。

图7 各个测试集排序准则的APFD
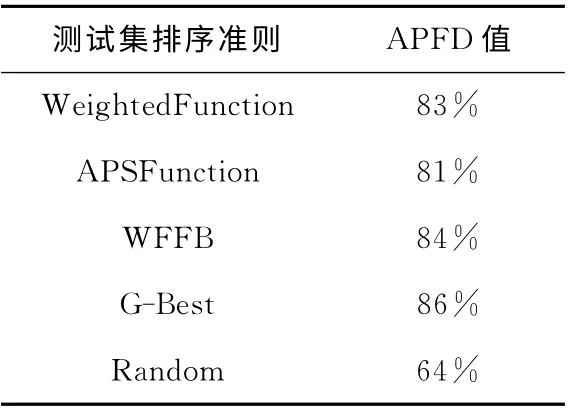
表8 APFD 统计
6 结束语
本文从后台代码角度分析了:①GUI软件和WEB软件在实现以及调用方式上的共性。②事件和事件入口以及调用路径之间的联系。③圈复杂度、方法被调用的次数与测试优先级的关系。借由此提出和实现了3 种可以适用于GUI和WEB的测试集排序准则。通过实例阐述排序方式并通过实现验证其有效性。
然而,仍有未解决的问题:①对于依据复合属性排序的测试集排序准则探索不够全面深入,应更多的探索复合准则的可能性。②实现的代码泛用性不足,并且自动化程度不够,应加以改进,使其能够适用于更多的测试集排序准则,并提高自动化程度。③实验量不够,对测试集排序准则的有效性的展现不够充分。应加大实验量,更精确的研究制定的测试集排序准则的效力,特别是依据复合属性排序的测试集排序准则的效力。今后将就以上三点作为主要研究方向。
[1]Bryce R,Sampath S,Memon M.Developing a single model and test prioritization strategies for event-driven software [J].IEEE Transactions on Software Engineering,2011,37 (1):48-64.
[2]Brooks P,Robinson B,Memon AM.An initial characterization of industrial graphical user interface systems [C]//Proc IEEE Int’l Conf Software Testing,Verification,and Validation,Edmonton,2009:11-20.
[3]Yuan Xun,Cohen Myra B,Memon AM.Interaction testing:Incorporating event context [J].IEEE Transactions on Software Engineering,2011,37 (4):559-574.
[4]Bogdan Korel.George koutsogiannakis experimental comparison of code-based and model-based test prioritization [C]//International Conference on Conference:Software Testing,Veri-fication and Validation Workshops,2009:77-84.
[5]Sampath S,Bryce R,Viswanath G,et al.User-session-based test cases for web application testing [C]//Proc IEEE Int’l Conf Software Testing,Verification,and Validation,Lillehammer,2008:141-150.
[6]Sreedevi Sampath,Renee C Bryce,Sachin Jain,et al.A tool for combinatorial-based prioritization and reduction of user-session-based test suites[C]//IEEE International Conference on Software Maintenance,2011:574-577.
[7]Arpad Beszedes,Tamas Gergely,Lajos Schrrettner,et al.Code-coverage-based regression test selection and prioritization in WebKit[C]//IEEE International Conference on Software Maintenance,2012:47-55.
[8]Dusica Marijan,Arnaud Gotlieb,Sagar Sen.Test case prioritization for continuous regression testing:An industrial case study [C]//IEEE International Conference on Software Maintenance,2013:541-543.
[9]Hong Mei,Dan Hao,Lingming Zhang,et al.A static approach to prioritizing JUnit test cases[J].IEEE Transactions on Software Engineering,2012,38 (6):1258-1275.
[10]Rick Hower.Web site test tools and site management tools[EB/OL].[2014-04-09].http://www.softwareqatest.com/qatweb1.html.
猜你喜欢
铁道通信信号(2020年6期)2020-09-21
商品与质量(2019年34期)2019-11-29
中国惯性技术学报(2019年6期)2019-03-04
测控技术(2018年5期)2018-12-09
传感器与微系统(2018年7期)2018-08-29
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
信息安全研究(2016年4期)2016-12-01
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
