
支持向量机在预测配煤灰熔点中的应用
2016-01-26 02:56林德平
电力科学与工程 2015年8期
林德平
(山西鲁晋王曲发电有限责任公司,山西潞城047500)
支持向量机在预测配煤灰熔点中的应用
林德平
(山西鲁晋王曲发电有限责任公司,山西潞城047500)
摘要:采用支持向量机预测配煤灰熔点时,针对训练样本代表性不足的问题,提出了一种选取训练样本的方法。在国内具有代表性的煤灰成分和灰熔点数据库的基础上,分别添加现场实际中不同数量的灰熔点实验数据,将二者的集合作为训练样本集对灰熔点进行预测,并对预测结果进行分析。结果表明:训练样本的选取对支持向量机的预测结果有较大的影响,而向数据库中添加灰熔点实验数据可以有效改善训练样本代表性不足的问题,配煤灰熔点预测值的均方误差MSE=5.76,最大相对误差为6.91%。
关键词:配煤;灰熔点;支持向量机;预测;训练样本
中图分类号:TQ533.9
文献标识码:A
DOI:10.3969/j.issn.1672-0792.2015.08.012
收稿日期:2015-05-25。
作者简介:林德平(1974-),男,工程师,主要从事燃煤机组运行、调试工作,E-mail:c211205@163.com。
Abstract:In order to improve the training sample representativeness in predicting the ash fusion temperature (AFT) of blended coals by support vector machine (SVM), a new method of sample selecting was proposed. A new training group was established by adding different experimental data to a representative database and this group was used to predict AFT of coal blending. The results show that the selection of training sample plays a significant role in predicting results, that the new training group could improve the representativeness of training samples, and that the MSE of the predicted value equals 5.76 with the maximum error percentage being 6.91%.
Keywords:coal blending;ash fusion temperatures;support vector machine;prediction;training sample

0引言
在煤种复杂多变,安全高效生产和国家政策的多重压力下,国内越来越多的燃煤电厂采用了配煤掺烧技术,而配煤的结渣特性与机组的安全运行有着紧密的联系[1]。配煤的灰熔点,尤其是软化温度ST,在影响锅炉结渣的因素中代表了煤灰本身的特性,该指标不仅与其结渣特性息息相关,更是固态排渣锅炉的重要安全指标之一[2]。本厂因为经济性和环保性的原因燃用的是烟煤和贫煤的配煤,且燃用的煤种来源于周边的二十几个煤矿,各个煤种的煤质指标有所差异。如果掺配的煤种和比例选择不当,极易造成锅炉结焦,给安全运行带来危害。
支持向量机(Support Vector Machine,SVM)是Vapnik等人根据统计学理论在VC维理论和结构风险最小原理基础上建立的一种新的学习方法,它能有效解决小样本、非线性、高维数和局部极小点等实际问题[3],已成功应用到工程实际领域。
在预测灰熔点的实际运用中,赵显桥等[4]采用支持向量机算法和BP神经网络算法对灰熔点进行建模和对比研究;李建中等[5]采用支持向量机结合遗传算法建立灰熔点预测模型;二者都得到了较好的预测效果,但所选用的样本数目较少。而本厂在利用支持向量机预测灰熔点指导配煤时恰恰遇到了样本代表性不足的问题,造成预测效果不理想。因此,本文提出了一种在现场实际中采用支持向量机预测灰熔点时选取训练样本的方法,并运用该方法对配煤的灰熔点进行预测。
1灰熔点实验及数据预处理
实验选取近期燃用过的20种煤样,在对煤样干燥和研磨后,按照国标GB/T 212-2008中的要求,用快速灰化法制得灰样,并进行灰熔点测定;煤灰成分采用X荧光光谱分析进行测定。测得的煤灰成分、煤样灰分和灰熔点实验结果如表1所示。
选取48组混煤实验结果(如表2所示)对支持向量机的预测结果加以验证。
2支持向量机预测模型
在支持向量机回归预测中,通过非线性映射Φ(xi)将训练样本(y1,x1),(y2,x2),…,(yl,xl)隐射到一个高维的特征空间,并在这个特征空间中建立线性模型:
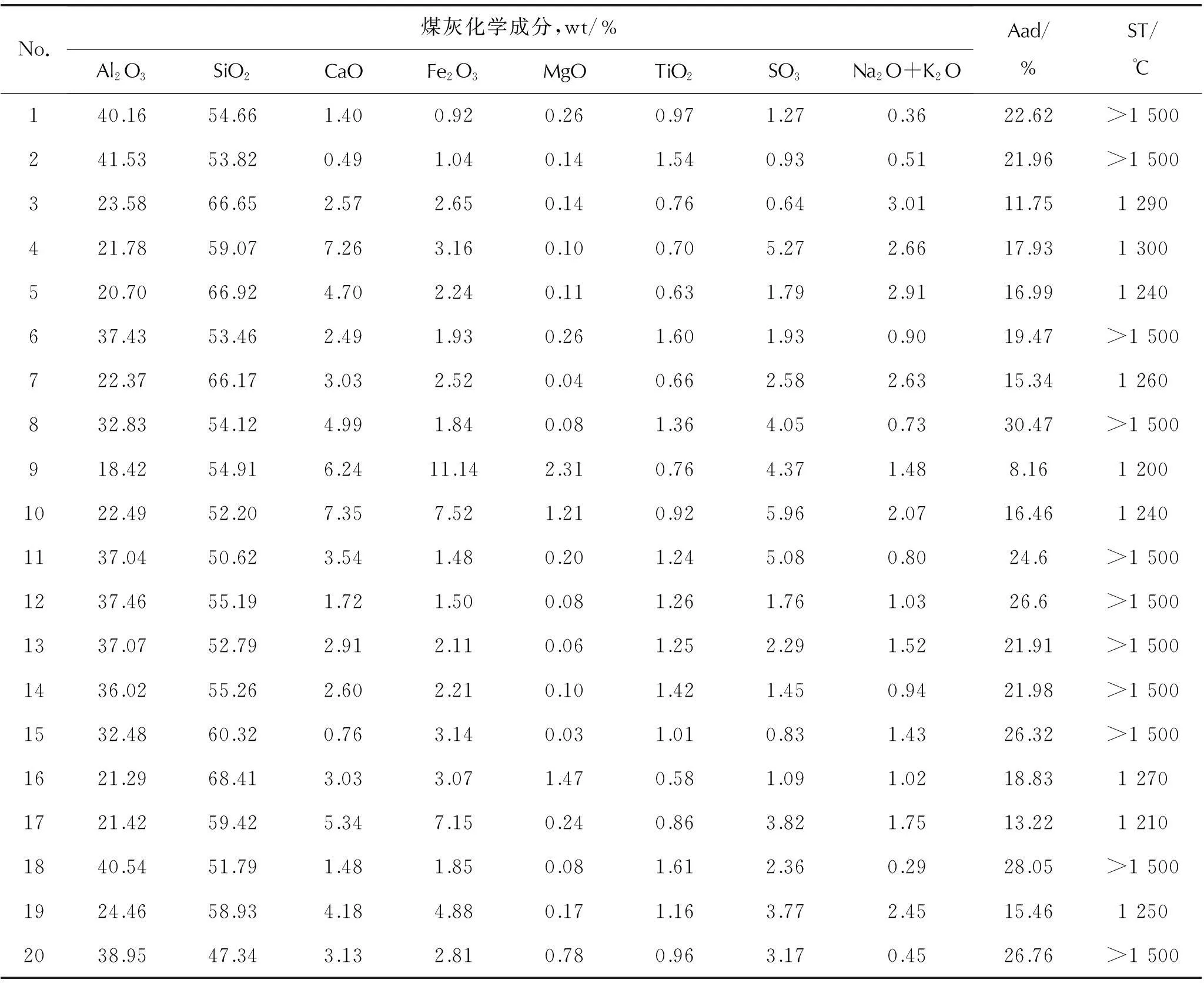
表1 煤灰化学组成和灰熔点实验值
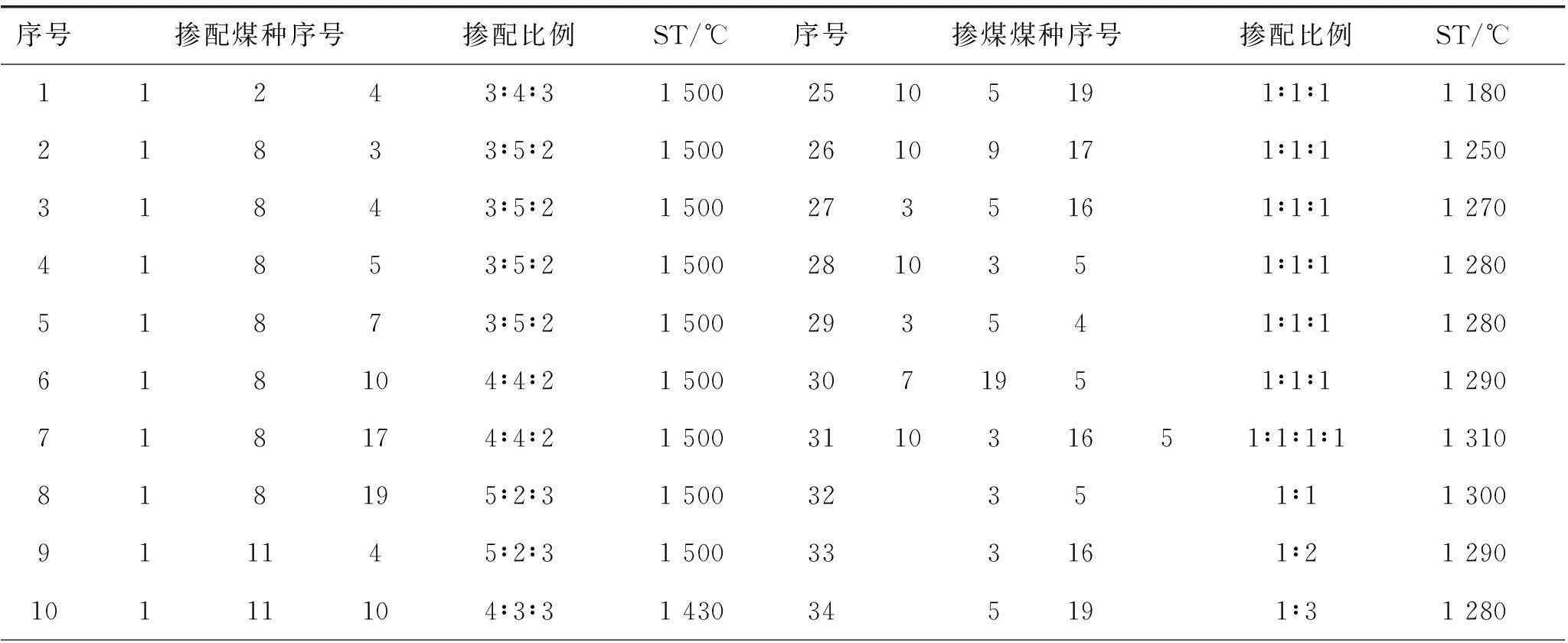
表2 配煤方案
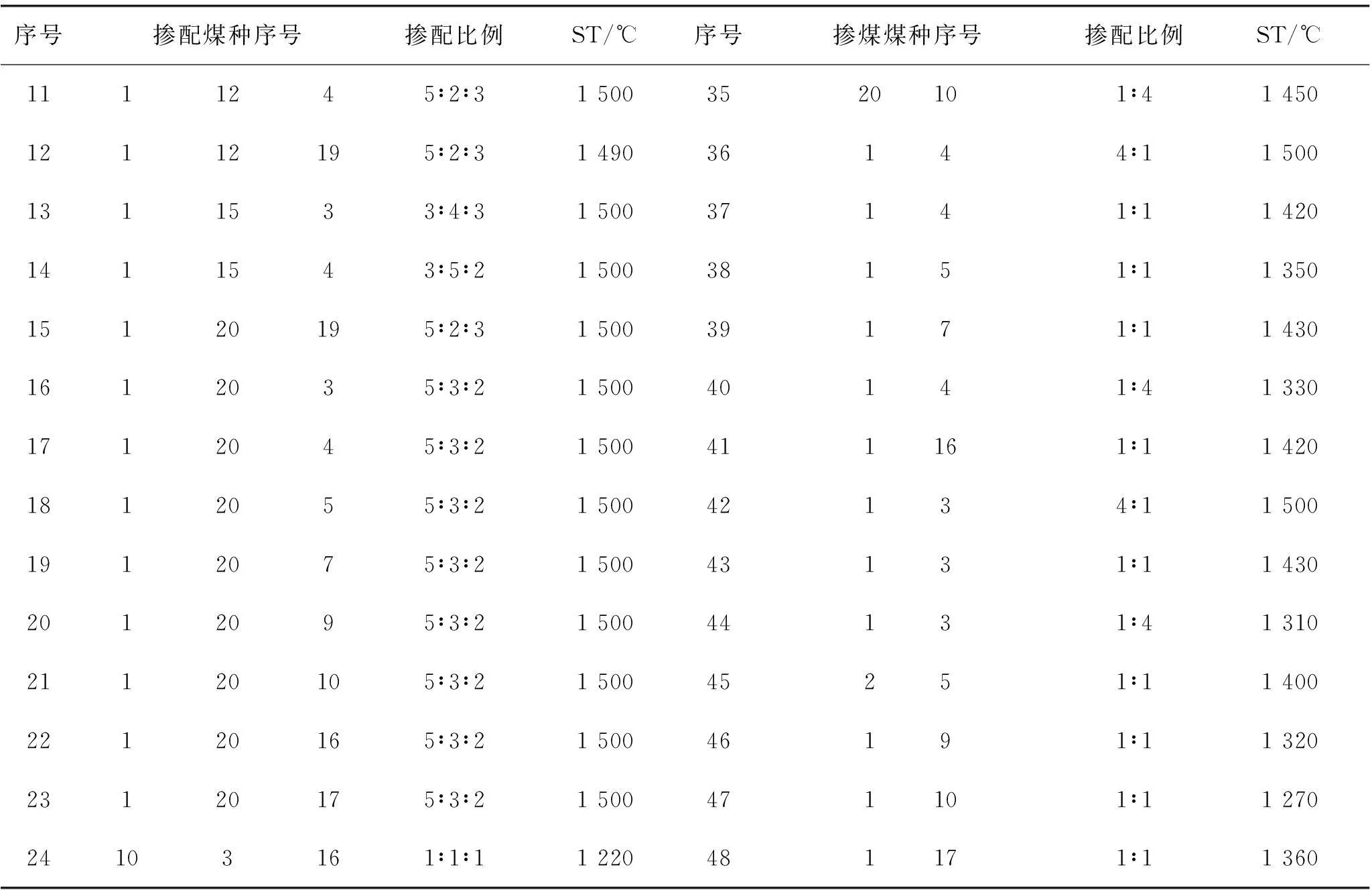
续表2

(1)
并用该模型来估计回归函数,其中w为权向量,b为阈值。
对于ε-支持向量机,其约束优化问题可表示为:


(2)
式中:C为拉格朗日乘子上限(误差惩罚参数);ξi,ξi*为松弛因子;ε为不敏感损失系数。
引入拉格朗日函数将式(2)转化为对偶问题,通过解其对偶问题从而得到式(1)的解:

(3)
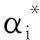
模型采用Al2O3,SiO2,CaO,Fe2O3,MgO,TiO2,SO3,Na2O+K2O等煤灰成分作为预测模型的8个输入量,软化温度ST作为输出量,不敏感损失函数取为0.001,拉格朗日乘子上限C参考文献[6,7]中的直接确定法计算,依据KEERTHI K等人的理论[8]:支持向量机的核函数选用径向基函数好于线性函数;因此,模型的核函数选用径向基函数,并依据文献[8]中的核校准法(Kernel Alignment,KA)确定核参数λ。选用中国科学院中国典型煤种热转化特性数据库中的78组煤灰成分和灰熔点数据作为初始数据,并用以下3个指标作为评价预测结果的标准。
绝对误差区间宽度Range(误差上限Tsx与下限Txx的差值):

(4)
相对误差绝对值的平均数:
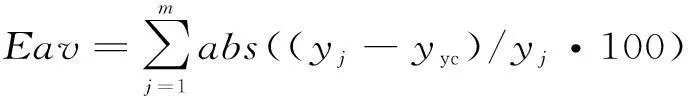
(5)
均方误差:
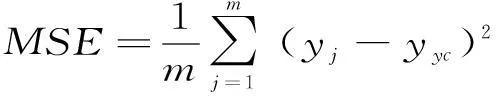
(6)
式中:m为预测样本数;yj和yyc分别为预测样本的实测值和预测值。
3预测结果及分析
分别用下面3种情况来研究训练样本对预测结果的影响,并选取合适的煤灰数据作为训练样本,进而对配煤方案的灰熔点进行预测。
3.1 训练数据中未添加单煤或配煤数据
用78组初始数据分别作为训练数据和检验数据训练模型并检验模型的可靠性,再用模型分别对序号为1 ~ 23,36 ~ 48的配煤和20种单煤,进行ST值预测,预测结果如图1所示。分析图1可知:采用78组数据作为训练数据,可以很好地预测序号为1 ~ 23的配煤的ST值,其预测值的相对误差绝对值的平均数Eav=1.92%,绝对误差范围在-68~ 51 ℃之间,Range=119 ℃,MSE=5.33,预测效果很好,同样,对检验数据也有着较好的预测;但是在对20种单煤和另外13种配煤进行预测时,MSE分别为47.83和81.58,预测效果不理想。这说明选取的训练样本代表性不足,建立的支持向量机模型泛化能力不足,不能对所有单煤和配煤的ST值进行有效预测。
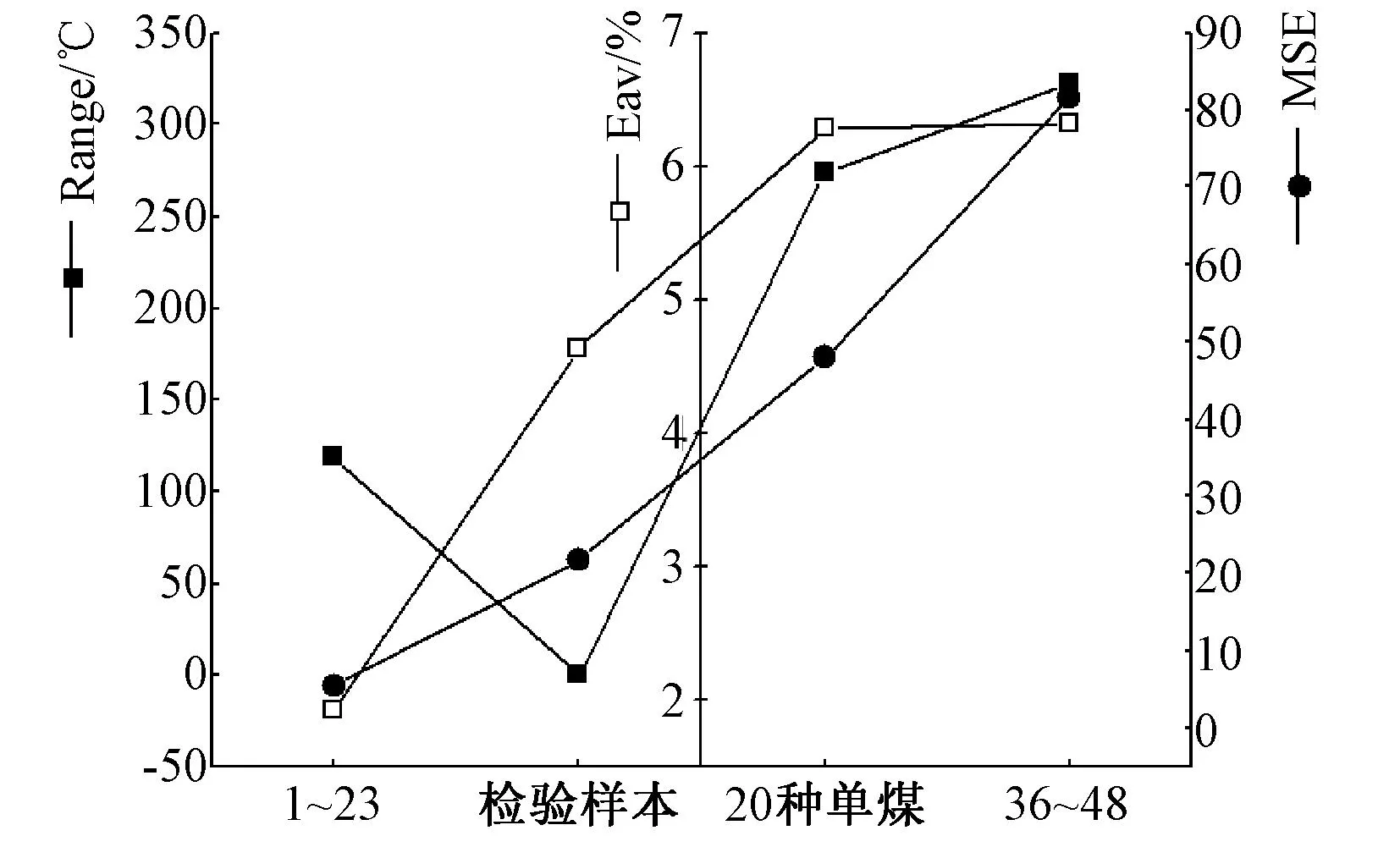
图1 支持向量机分别预测4类数据的结果
3.2 在训练数据中仅添加单煤数据
在78组初始数据的基础上,分别从20种单煤中提取2(表1中序号分别为1、3的单煤)、4(表1中序号为1 ~ 4的单煤)、6个(表1中序号为1 ~ 6的单煤)煤灰成分数据加入训练数据,剩余单煤灰熔点数据作为预测数据,预测结果见图2。
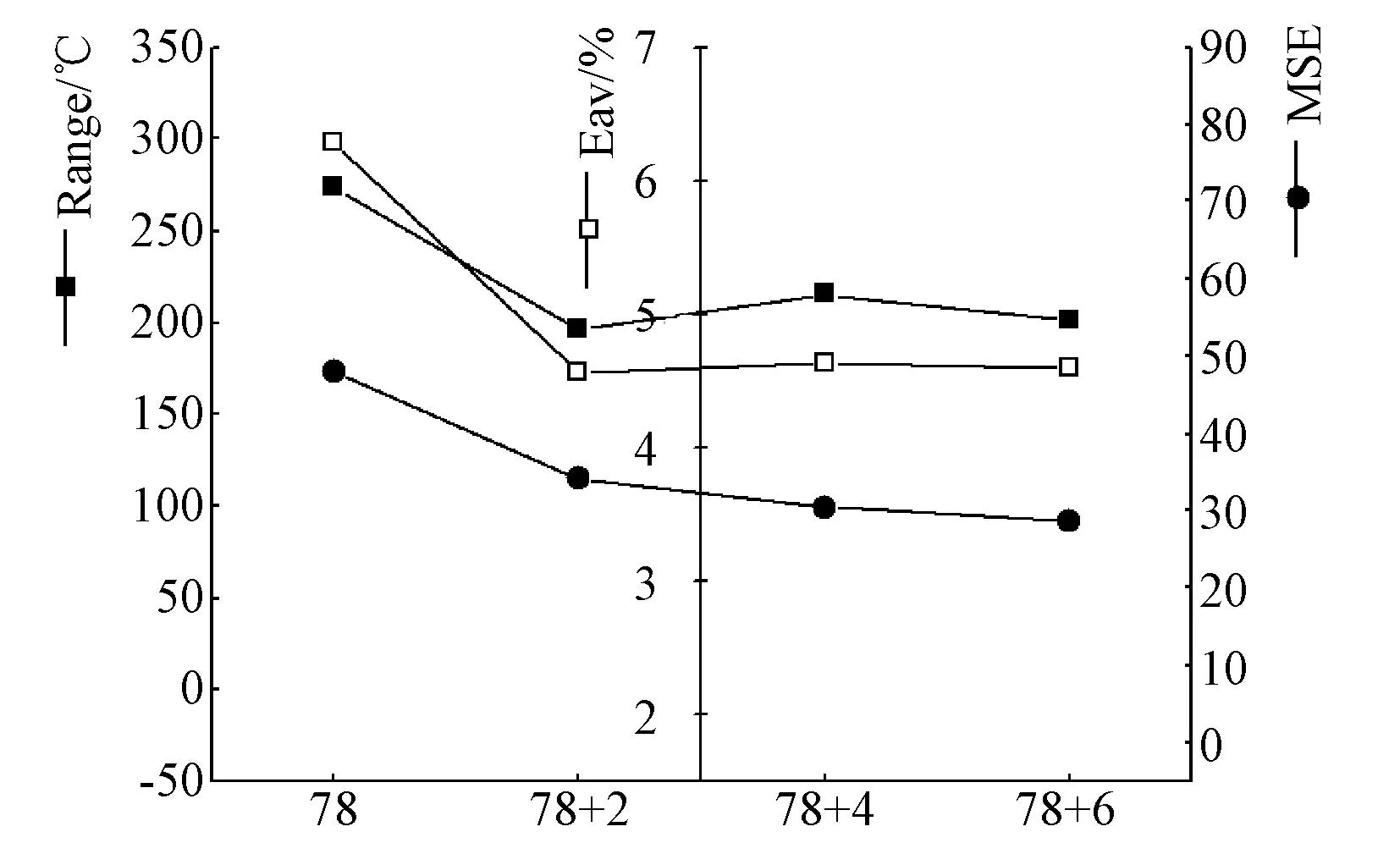
图2 分别添加不同单煤数据的预测结果
分析图2可知:(1)在78组原始数据基础上,添加2组单煤数据后,支持向量机对单煤灰熔点的预测效果得到大幅改善,Eav由6.29%变为4.56%,MSE从47.83下降为34.28,Range也由274 ℃缩小至196 ℃;(2)随着单煤数据添加组数的增加,MSE呈现下降的趋势,但变化趋势不大,而Eav和Range几乎不发生变化;(3)总结(1)和(2)可得出结论,向训练样本中添加灰熔点实验数据能改善训练样本代表性不足的问题,但改善的程度有一定的限制。这种情况的出现与支持向量机泛化能力较强的特点有一定关系。
3.3 在训练数据中添加单煤和配煤数据
在3.2中78+6共84组训练数据的基础上添加表2中12组配煤方案的煤灰数据,对剩余的36组数据(表2中序号为6 ~ 41的配煤方案)进行ST值预测。预测结果较为精准:Range=162 ℃,绝对误差在-69 ~93 ℃之间,Eav=1.74%,均方误差MSE=5.76。预测结果如图3所示。
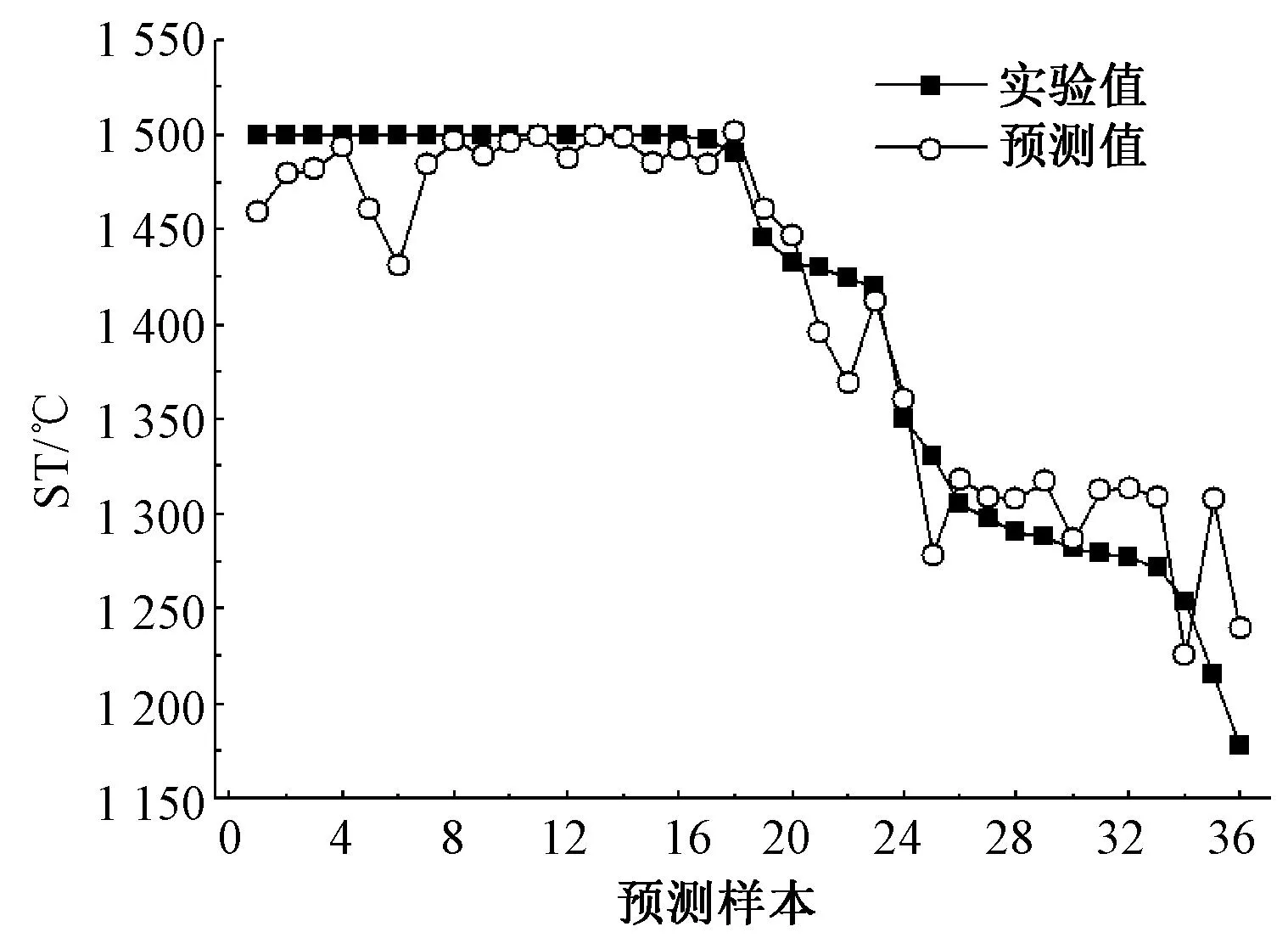
图3 支持向量机预测配煤方案ST值
4结论
(1)采用支持向量机预测煤灰ST值时,训练样本的选取对预测结果有着较大的影响:若训练样本代表性不足,将导致预测结果极大偏离ST实验值。
(2)向训练样本中添加灰熔点实验数据能有效改善训练样本代表性不足的问题,但并不能完全克服这一问题。
(3)在采用支持向量机预测灰熔点时,提出了一种选取训练样本的有效方法:在国内具有代表性的78组煤灰成分和灰熔点数据的基础上,分别添加现场实际中6种单煤,12种配煤的煤灰成分和ST数据,将二者的集合作为训练样本集对灰熔点进行预测。
(4)采用(3)中选取训练样本的方法对ST值进行预测,取得了较好的预测结果:Range=162 ℃,绝对误差在-69 ~93 ℃之间,Eav=1.74%,均方误差MSE=5.76。
参考文献:
[1]夏季. 火电机组配煤掺烧全过程优化技术研究与应用[D]. 武汉:华中科技大学,2013.
[2]王洪亮,王东风,韩璞.基于模糊神经网络的电站燃煤锅炉结渣预测[J].电力科学与工程,2010,26(6):28-32.
[3]杨淑莹.模式识别与智能计算:MATLAB技术实现(第二版)[M].北京:电子工业出版社,2011.
[4]赵显桥,吴胜杰,何国亮,等.支持向量机灰熔点预测模型研究[J].热能动力工程,2011,26(4):436-439.
[5]李建中,周昊,王春林,等.支持向量机技术在动力配煤中灰熔点预测的应用[J].煤炭学报,2007,32(1):81-84.
[6]闫国华,朱永生.支持向量机回归的参数选择方法[J].计算机工程,2009,35(14):218-220.
[7]Cherkassky V, Ma Y Q. Practical selection of SVM parameters and noise estimation for SVM regression[J].Neural Networks,2004,17(1):113-126.
[8]Keerthi S,Lin C.Asymptotic behaviors of support vector machineswith Gaussian kernel[J].Neural Computation,2003,15(7):1667-1689.
The Application of Support Vector Machine in Predicting Ash Fusion Temperature of Blended Coals
Lin Deping
(Lujinwangqu Power Generation Limited Liability Company, Lucheng 047500, China)
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
科技创新与应用(2020年6期)2020-02-29
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
北京理工大学学报(2016年6期)2016-11-22
价值工程(2016年29期)2016-11-14
电视技术(2016年9期)2016-10-17
