
Spark计算引擎的数据对象缓存优化研究
2016-03-24 00:24陈康王彬冯琳
中兴通讯技术 2016年2期
关键词:并行计算
陈康 王彬 冯琳


摘要:研究了Spark并行计算集群对于内存的使用行为,认为其主要工作是通过对内存行为进行建模与分析,并对内存的使用进行决策自动化,使调度器自动识别出有价值的弹性分布式数据集(RDD)并放入缓存。另外,也对缓存替换策略进行优化,代替了原有的近期最少使用(LRU)算法。通过改进缓存方法,提高了任务在资源有限情况下的运行效率,以及在不同集群环境下任务效率的稳定性。
关键词:并行计算;缓存;Spark;RDD
Abstract:In this paper, Spark parallel computing cluster for memory is studied. Its main work is about modeling and analysis of memory behavior in the computing engine and making the cache strategy automatic. Thus, the scheduler can recognize a valuable data object to be cached in the memory. A new cache replacement algorithm is proposed to replace least recently used (LRU) and have better performance in some applications. Thus, the performance and reliability of the Spark computing engine can be improved.
Key words:parallel computing; cache; Spark; resilient distributed dataset(RDD)
大数据处理的框架在现阶段比较有影响力的是基于Google所发明的MapReduce[1]方法及其Hadoop[2]的实现。当然,在性能上传统的消息传递接口(MPI)[3]会更好,但是在处理数据的方便使用性、扩展性和可靠性方面MapReduce更加适合。使用MapRecuce可以专注于业务逻辑,不必关心一些传统模型中需要处理的复杂问题,例如并行化、容错、负载均衡等。
由于Hadoop通过Hadoop分布式文件系统(HDFS)[4]读写数据,在进行多轮迭代计算时速度很慢。随着需要处理的数据越来越大,提高MapReduce性能变成了一个迫切的需求,Spark[5]便是在此种背景下应运而生。
Spark主要针对多轮迭代中的重用工作数据集(比如机器学习算法)的工作负载进行优化,主要特点为引入了内存集群计算的概念,将数据集缓存在内存中,以缩短访问延迟。
Spark编程数据模型为弹性分布式数据集(RDD)[6]的抽象,即分布在一组节点中的只读对象集合。数据集合通过记录来源信息来帮助重构以达到可靠的目的。RDD被表示为一个Scala[7]对象,并且可以从文件中创建它。
Spark中的应用程序可实现在单一节点上执行的操作或在一组节点上并行执行的操作。对于多节点操作,Spark依赖于Mesos[8]集群管理器。Mesos能够对底层的物理资源进行抽象,并且以统一的方式提供给上层的计算资源。通过这种方式可以让一个物理集群提供给不同的计算框架所使用。
Spark使用内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。使用这种方法,几乎可以将所有数据都保存在内存中,这样整体的性能就有很大的提高。然而目前Spark由于将缓存策略交由程序员在代码中手动完成,有可能会引起缓存的低效甚至程序出错,主要原因如下:
(1)程序员如果缓存无用的数据,将会导致内存未被充分利用,降低内存对程序性能的提升;
(2)错误的缓存甚至会产生内存溢出等严重后果,直接导致程序崩溃出错;
(3)程序中有具有缓存价值的数据得不到缓存,将使程序不能达到最高效率。
随着项目变大,代码量增加,这个问题会变得越来越严重。如果使用自动分析的方法,自动完成缓存的工作,无疑会降低程序员负担以及避免上述的问题。下面将对这方面进行初步研究,通过分析与建模,目的是使内存的使用更加智能有效,并加速任务的运行速度。
1 Spark中缓存优化研究
我们分3个方面对Spark中的缓存进行研究:一个是缓存自动化方法;一个是缓存替换方法改进;最后是程序执行调度顺序与缓存的关系。
1.1 Spark中的缓存
Spark通过将RDD数据块对象缓存在内存中这一方式对MapReduce程序进行性能上的提升改进。以经典的PageRank[9]算法为例,Spark比Hadoop快3倍左右。
以逻辑回归算法实验代码为例,如图1所示。
可以看出:在使用Spark时,从第2轮迭代计算开始,points的数据可以从缓存中直接读取出来,因此获得了极高的加速比。
1.2 数据对象的自动缓存
对于Spark来说,并不是每个RDD都要缓存到内存当中,需要进行筛选保留有价值的RDD存入内存。目前Spark中这种筛选的工作都交由程序员手动完成。以PageRank作为例子,如图2所示。
代码中有3个变量,且3个变量都是RDD类型,其中第1行最后的cache操作,会导致links 被缓存到内存,在循环中可以从内存中直接读取,而ranks和contribs则没有被缓存,这就是Spark 当前的缓存机制。
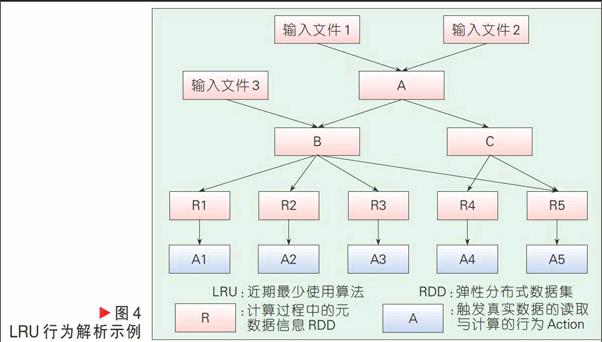
将缓存的工作交由程序员手动完成,对于系统本身的实现来讲,是简化了许多,但是对于程序员来讲则是极大的挑战。对于复杂操作,程序员通常很难直接分析出具有缓存价值的数据对象进行缓存。sortByKey是用来对数据依据其指定的键值进行排序的一个常用操作,具体如图3所示。
猜你喜欢
软件导刊(2017年1期)2017-03-06
计算机应用(2016年12期)2017-01-13
科学与财富(2016年15期)2016-11-24
大经贸(2016年9期)2016-11-16
中国新通信(2016年16期)2016-10-18
计算机辅助工程(2016年3期)2016-08-01
电脑知识与技术(2016年14期)2016-06-30
科技视界(2016年11期)2016-05-23
电脑知识与技术(2015年12期)2015-07-18
湖南大学学报·自然科学版(2015年2期)2015-04-20
