
基于Mapreduce的afsa_km聚类算法并行实现
2016-05-14 15:49陈书会周莲英
软件导刊 2016年7期
关键词:聚类
陈书会 周莲英


摘要:针对kmeans算法对初始聚类中心敏感的问题,提出利用人工鱼群算法去优化k均值算法,即先通过人工鱼的行为进行全局搜索,得到一个初始的全局最优划分后再进行聚类,运用云平台Hadoop的并行处理框架Mapreduce对混合算法实施并行处理,从而快速准确地处理大量数据。实验结果表明,改进后的算法在执行速度、准确性、加速比及可扩展性方面都有所提高。
关键词关键词:聚类;kmeans算法;人工鱼群算法;Mapreduce
DOIDOI:10.11907/rjdk.161281
中图分类号:TP312文献标识码:A文章编号文章编号:16727800(2016)007005103
0引言
kmeans是一种基于划分的聚类算法,其相似性评价指标为距离,即两个对象距离越近,其相似度越大。算法随机地确定初始值,再优化初始划分。如果初始值选择不合适,算法就易陷入局部最优。为解决这一问题,本文采用人工鱼群算法(AFSA)进行初始化。
针对大数据时代产生的海量数据,在高效存储及计算方面,分布式平台Hadoop发挥着重要作用。本文研究了基于Mapreduce的afsa_km聚类算法,通过相关实验解决了kmeans对初始值敏感的问题,提高了海量数据处理的准确性及效率。1串行afsa_km算法
afsa_km算法利用afsa全局寻优特点,先通过鱼群行为搜索数据集中最优或者靠近最优的解,再把这些解作为kmeans的初始值。该方式在一定程度上能改善kmeans对初始中心敏感的问题,算法流程如图1所示。1.1人工鱼群算法
一般认为一片水域中食物多的地方会有较多的鱼群。全局寻优是利用鱼群追尾、群聚等行为寻找食物的过程,文献中详细说明了算法步骤。
变量定义:X=(x1,x2,…,xn)为个体状态,其中xi(i=1,2,…,n)为寻优变量,人工鱼最大步长为Step,人工鱼的视野为Visual,尝试次数为Try_number,拥挤度因子为λ,人工鱼个体间距离dij=|Xi-Xj|,人工鱼当前位置的食物浓度Y=f(X)。
追尾行为:若当前鱼的状态为 Xi,搜索其视野范围 Visual内相邻伙伴,得到其中的最优个体状态 Xj。若 Xj优于当前状态 Xi,且其周围的拥挤程度不大于λ ,则当前鱼以步长Step向该状态前进一步,否则进行觅食行为。
聚群行为:若当前鱼的状态为 Xi,搜索其视野范围Visual内相邻伙伴,得到相邻伙伴的中心状态 Xc,若状态 Xc优于当前状态 Xi,且其周围的拥挤程度小于λ,则当前鱼向该状态前进一步,否则进行觅食行为。
觅食行为:若当前鱼的状态为 Xi,随机寻找一个在其视野内的状态Xj。若Xj优于当前状态 Xi,则当前鱼以步长Step向该状态前进一步,否则继续随机寻找一个新的状态。若尝试一定次数后,仍没有优于当前的状态,则当前鱼随机移动一步。
随机行为:若当前鱼的状态为 Xi,在其搜索范围内找不到更优的状态,为了扩大搜索空间,随机选择一个视野范围内的状态 Xj,便于跳出局部。
公告板:用来记录目标函数值、最优人工鱼个体状态和历史最优人工鱼个体状态。每条人工鱼在行动一次后就将自身状态与公告板进行比较,如果优于公告板状态,就改写公告板状态。
将人工鱼寻找食物的过程作为聚类时寻找类中心点的过程,满足误差平方和公式(1)即可认为找到最优中心点。
式(1)中k为聚类中心个数,ci为聚类中心,xj为聚类对象。
1.2kmeans聚类算法
kmeans是划分方法中比较经典的聚类算法,由于效率高,在对大规模数据进行聚类时广泛应用。算法以k为参数,把n个对象分成k个簇,使簇内有较高的相似度,而簇间的相似度较低。kmeans具体运行过程如下:先随机选择k个对象,每个对象代表一个簇的平均值或中心;对剩余的对象,根据其与簇中心的距离,将它赋给最近的簇,重新计算每个簇的平均值。 这个过程不断重复,直到准则函数收敛,最后输出k个聚类中心。2并行afsa_km聚类算法
文献采取的改进afsa_km算法可以很好地弥补kmeans算法的缺陷,提高算法准确度。由于整个程序是串行实现的,在处理大规模数据时,效率较低。人工鱼群算法是一种并行算法,可以在Hadoop平台上执行。本文将人工鱼群和kmeans算法全都并行化,并在Hadoop上运行。2.1并行人工鱼群算法
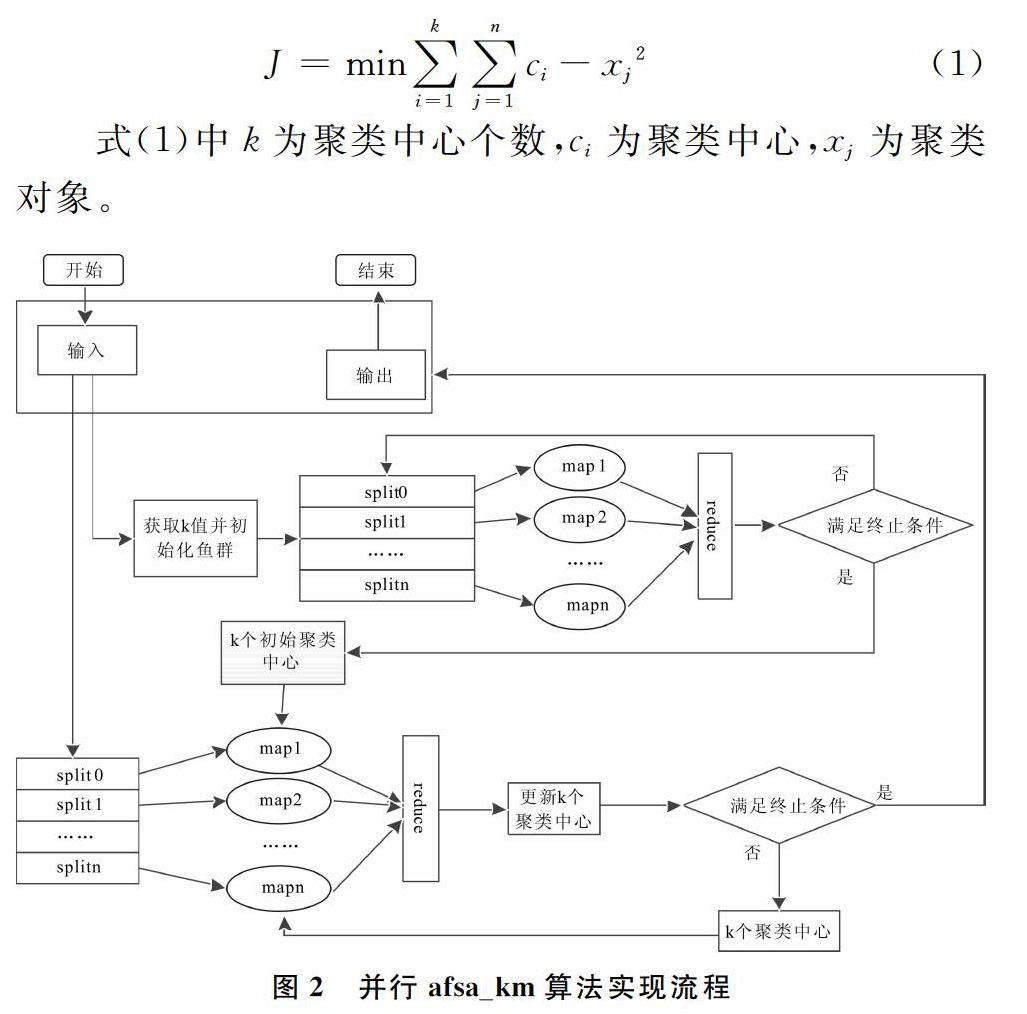
算法思想是:将鱼群划分为几个子鱼群,每个子鱼群在给定的数据集中得到本次过程的局部最优值,再汇总每个子鱼群的最优解,得到本次运行的全局最优解,算法流程如图2所示。在Hadoop中,Map函数主要完成每个子鱼群的寻优,包括觅食、群聚、追尾,输出子鱼群的最优解及适应度值。Map函数输入key为数据的行号,value为待聚类数据的各维度值。为了减少网络数据开销,使用Combine对Map端进行一次并归。
设置全局共享区域:每次节点运行完后,将各自节点上的鱼群位置和对应的适应度值记录在全局共享区,供下一次算法执行时使用。
算法首先为每个阶段初始化子鱼群,包括鱼群数量t、视野范围visual和试探次数Try_number等参数。
Map阶段的处理:
①计算子鱼群适应度,设定子鱼群初始状态X,求出对应的适应度值;②评价每条人工鱼,选择要进行的行为,包括觅食行为、聚群行为、追尾行为和随机行为;③执行人工鱼选择的行为,更新人工鱼位置信息和适应度值;④将新的人工鱼位置和适应度值传给数据共享区;⑤输出键值对<1,(位置,适应度值)>。
对数据列表中的数据按子鱼群最优适应度值进行排序。
更新公告牌。
在i次迭代后,满足终止条件即可停止迭代,输出k个聚类中心。本文使用迭代次数作为终止条件,也可以使用均方差的变化作为终止条件。
2.2并行kmeans算法
基于MapReduce的并行kmeans算法的Map函数主要完成数据点的归类工作,使用上述人工鱼群算法输出的点作为初始聚类中心。
算法开始前,首先设置一个全局共享区域,记录每次迭代得到的聚类中心。
Reduce将Combine输出结果进一步并归,求出本轮迭代的聚类中心,并更新共享区。当完成规定的迭代数之后,整个算法结束。
3实验结果
3.1实验环境
实验中的Hadoop集群由6台电脑组成,其中1台作为master,其它5台作为slaves。硬件配置:master是双核2.9GHz,8G内存;slaves都是双核2.4GHz,4GHz内存。软件配置:系统版本Ubuntu 14.04;Jdk 1.6.0;hadoop 1.2.1。
3.2准确性实验
主要对并行算法的准确性和有效性进行测试。采用人工生成的3维数据,设置成5类。测试的数据有3组:第1组data1包含2 000条数据,不含有孤立点;第2组data2包含2 000条数据,有10个孤立点;第3组data3包含20 000条数据,不含孤立点。设定afsa_km中每个子鱼群包含20条人工鱼,迭代次数为20次。
3.3集群性能实验
加速比是用来衡量算法并行处理性能的一个重要评价指标,通过计算单节点运行时间和多节点运行时间比值获得。实验采用人工生成的3组数据集A、B、C,其中A大小为32.3M,B大小为256.2M,C大小为1.8G。实验结果如图4所示。从图4中可以看出:随着计算节点增加,处理相同规模数据有较好的加速比。随着数据规模增大,加速比和节点数成线性增长,表现出良好的扩展性。加速比与对应节点数的比值即并行效率。图5所示,在处理规模较小的数据时,集群的启动和通信消耗的时间占整个处理时间比例较大,影响了算法的效率。处理的数据规模越大,算法效率也越高。综合结果是基于Mapreduce的afsa_km算法有处理大规模数据的能力。
第7期 李玲俐:谱聚类算法及其应用综述软 件 导 刊2016年标题
猜你喜欢
电子测试(2017年15期)2017-12-18
光学精密工程(2016年5期)2016-11-07
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
