
基于体感和3D虚拟仿真技术的静态手语—口语互译软件设计与实现
2016-05-14 15:49吴金波帖军郑禄
软件导刊 2016年7期
吴金波 帖军 郑禄
摘要:基于当今社会对手语翻译的迫切需求,系统分析了手语翻译、口语翻译、练习系统、自定义手语、娱乐模块五大功能模块。基于体感和3D虚拟仿真技术,设计并实现了静态手语-口语互译软件系统。从指尖坐标获取、语音识别、口语翻译、练习系统、体感游戏、自定义手语六大方面详细介绍了其技术路线与实现过程。
关键词关键词:体感技术;手语翻译;Kinect;Unity3D
DOIDOI:10.11907/rjdk.161417
中图分类号:TP319文献标识码:A文章编号文章编号:16727800(2016)007006702
0引言
据调查,目前全世界有3.6亿的听力障碍人士,其中有近2 100万来自中国,手语是听力障碍人士实现沟通的主要语言,然而由于大部分人不懂手语,使得聋哑人士和普通人之间的交流十分困难。而通过人工进行手语和口语实时互译,来解决大多数人的沟通问题又极不现实。随着计算机科学技术的飞速发展,以体感和虚拟现实为代表的各种新兴技术的出现,使得通过技术的创新、融合以更加低廉的成本和更高的效率满足日益增长的需求成为可能。将体感和3D虚拟仿真技术相结合,并运用于静态手语和口语互译实现中,不仅极大提高了效率,同时也为当前手语翻译研究提供了一个新的切入点。
1功能分析
手语翻译: 用户只需要在Kinect前面做出相应的手语动作,系统便能自动捕捉,通过分析并处理深度图像数据,将其翻译并以文字的方式展现出来[1]。
口语翻译: 系统提供了两种方式,分别是文本输入方式和语音输入方式。用户可以选择使用文字或是语音的方式向系统传递需要翻译的信息,单击“翻译”按钮后,3D虚拟人物就会将其自动转化为手语展示给用户,相当方便。
练习系统: 用户通过观看3D虚拟人物所做的手语动作来分辨出其对应的手语意思,并点击系统显示在界面上多个汉语意思中自己认为正确的一个,然后系统会对用户的分辨结果作出判断,通过直观简洁的流程让用户更好地学习手语。
自定义手语:自定义手语功能目前只支持自定义一种手语(再见时的摆手动作),该功能是预留给下一版作为扩充之用。
娱乐模块: 主要以体感游戏的方式呈现给用户,用户通过简单的手势来控制游戏主角,从而融入游戏[2]。
2系统设计
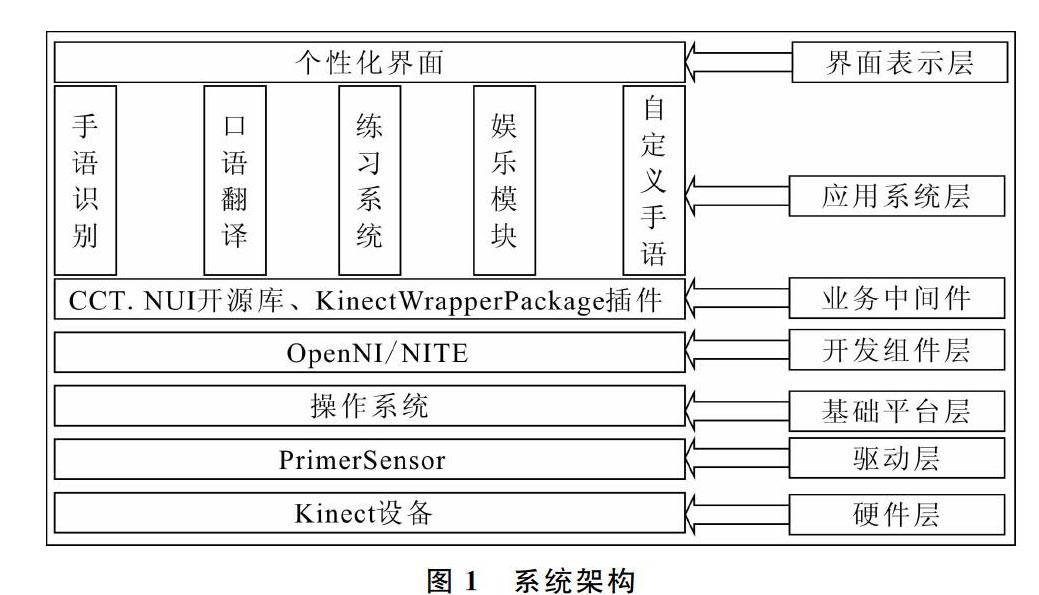
本系统以Unity3D为开发平台,使用CCT.NUI开源体感识别库、OpenNI/NITE组合开发包和KinectWrapperPackage中间件的接口进行开发。系统整体架构如图1所示。
2.1OpenNI简介
OpenNI(开放式的自然交互)是一个非营利组织,该组织专注于提高和改善自然交互设备,应用软件的互操作能力,通过使用这些硬件和中间件来很方便地访问和使用一些设备。
OpenNI的API允许开发人员直接基于最原始的数据格式编写中间件上层算法,而不管这些数据是由哪个传感器设备产生。OpenNI的这种机制给了传感器制造商一个充分的自由空间去制造自己的传感器而不用考虑上层OpenNI兼容的应用程序。
OpenNI API使得自然交互应用开发人员通过传感器输出的标准化数据类型来处理真实的三维数据,这些标准化的数据类型可以表示人体全身、手的位置,或者仅仅是一个含有深度信息的像素图等。
2.2系统模块组成
本系统主要包括静态手语识别、口语识别、练习系统、娱乐模块、自定义手语库共5个模块。
(1) 静态手语识别。静态手语识别是本系统最核心的模块之一,用户只需要在Kinect可识别范围内做出相应手语动作,系统通过分析处理从Kinect获取的深度和骨骼数据,将其翻译成汉语,以文字的形式显示在屏幕上,简单直观[3]。
(2) 口语识别。口语识别模块提供了两种方式以方便用户向系统传递需要翻译的信息,分别是文本框输入、语音识别输入。①文本框输入:用户直接在输入框输入需要翻译的内容,单击“翻译”按钮,系统的3D虚拟人物便将此内容以手语的形式展示出来;②语音识别输入:用户只需开启语音识别,然后在Kinect可识别的范围内直接说出想要翻译的内容,Kinect识别出信息后便会显示在文本框内,用户确认内容无误后,单击“翻译”按钮,3D虚拟人物便会将其翻译[4]。
(3) 练习系统。用户点击“开始”后,系统会按照一定顺序选择一则手语的动画并播放出来。用户可以根据动画判断相应的手语意思并选择,系统会作出判断。该系统简单易用,适合大多数人的日常学习。
(4) 娱乐模块。主要以体感游戏的方式呈现,用户通过简单的手势来控制游戏主角。
(5) 自定义手语。用户在自定义手语页面只需单击录制按钮,手势录制进程即被启动,视频录制完毕后,通过算法处理加入到程序中,关闭录制进程并在自定义手语库页面的文本框内填写对应的文字意思,然后单击“提交”按钮,自定义的手语便自动保存。
3技术路线与实现
3.1指尖坐标获取
在手势识别模块中,最关键的部分就是对于手指指尖坐标的获取。Kinect本身无法直接识别出手指,而开源库体感识别库CCT.NUI实现了Kinect对手指指尖坐标的捕捉,同时兼容OpenNI/NITE以及Kinect SDK两种驱动及其开发包。可以通过CCT.NUI的接口,很方便地获取到指尖坐标,进而对坐标进行处理,通过有限自动机转化成相应手语。手语识别过程如图2所示。
3.2语音识别
利用Kinect对特定命令识别(recognition of command)的功能,将Kinect SDK中的Microsoft.Speech.dll作进一步封装,将原本只能识别英文的DLL封装成可以识别中文的DLL,从而达到识别中文语音的目的。再利用进程间的通信,把通过Kinect识别的语音传到主进程中,从而实现Kinect与Unity3D的交互。
3.3口语翻译
当系统获取到需要翻译的信息后,需要让3D虚拟人物将其以手语的方式展示出来。此过程是首先将能够识别的手语制作成一个个3D动画,然后分别导入到Unity3D中,利用Unity3D的动画系统,将其循环播放。至于手语动画的选择,则由输入系统所需要翻译的信息决定,从需要翻译的信息到手语的转化过程同样是借助有限状态机实现。口语翻译流程如图3所示。
3.4练习系统
练习系统主要分为两个部分:手语展示部分和用户选择结果判定的决策部分。通过将每一则手语和特定的汉语意思进行关联,当系统以一定的顺序播放手语动画时,用户可以同步进行语意判定,系统的判定决策系统由状态机实现。
3.5体感游戏
基于Unity3D的体感游戏也是本项目的一个技术难点。Kinect与Unity3D本身并不能直接进行数据交互,如果自己去写中间件将花费大量时间,将大量时间花在系统的非核心部分是得不偿失的,因此采用现有的中间件便成为了最佳选择。本软件中采用的是卡内基梅隆大学的KinectWrapperPackage插件,只需将此插件包导入到Unity3D里便可使用插件包提供的接口,方便地获取到Kinect的数据,再通过获取到的骨骼数据进行处理,识别出相应手势,再将其转化为控制游戏角色的指令,就能实现体感控制。体感控制实现流程如图4所示。
