
快速DCT修剪在DSP上的内存访问优化方法
2016-05-30 14:16刘项洋许勇
电子学报 2016年1期
刘项洋,许勇
(安徽师范大学数学计算机科学学院,安徽芜湖241000)
快速DCT修剪在DSP上的内存访问优化方法
刘项洋,许勇
(安徽师范大学数学计算机科学学院,安徽芜湖241000)
摘要:在本论文中,我们提出一个新的内存访问优化方法以减少由权重因子(在DCT的快速修剪计算图中的余弦系数)和输入点而产生的内存访问量,实现在DSP上的快速DCT修剪.该方法通过两个步骤来减少内存访问量: 1.减少权重因子的个数; 2.将快速DCT修剪的计算流程图中两个阶段中的蝴蝶运算单元合并到一个阶段中,从而形成一个高效的蝴蝶运算单元.我们在TI TMSC320C64x DSP上应用该方法来实现修剪FCT.实验结果表明,与传统的实现方法相比,修剪FCT方法在DSP上可以平均减少40%的内存访问量,平均减少48.6%的时钟周期和平均节约32.6%的由存储加权因子导致的内存访问.
关键词:数字信号处理器(DSP);离散余弦变换(DCT);内存访问
1 引言
离散余弦变换(Discrete Cosine Transform,DCT)从1974年被文献[1]定义以来,在许多图像、语音编码应用程序中发挥了非常重要的作用,而其中最常用的是二型DCT(DCT-II).文献[2]给出了二型DCT的具体定义:
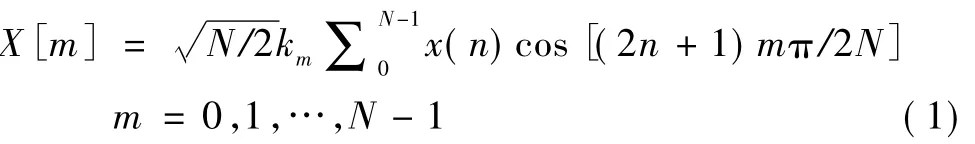
直接用硬件或软件来实现这个公式是非常低效的.为解决这个问题,文献[2]中也提出了各种直接或间接的计算的方法.此后,DCT算法的研究进展包括了radix -2nDCT[3],量化二维DCT[4]、多维矢量DCT正交矩阵变换[5]以及FPGA实现DCT[6,7]等,均是直接计算DCT.
通常这些算法都假定DCT系数的输入与输出数量相同.然而在大多数图像处理应用程序中只有低频DCT系数部分才保存最有用的信号信息,所以实际上中只需要计算这部分DCT系数就可以了.这种只计算部分DCT系数的方法通常被称为DCT修剪或修剪DCT[10].由于只计算一部分而不是完整的DCT系数,DCT修剪可以减少一些CPU的运算操作和一定数量的内存访问.因此DCT修剪一般比传统DCT速度更快,效率更高.目前也有许多算法已用于计算DCT修剪[8,9]等.Wang[10]在这些论文中首先提出有效的快速DCT修剪算法(Fast DCT Prunning).后来又有学者提出修剪FCT(Prunning FCT)[11],并且通过与前者比较计算复杂度而证明文献[10]更快.
尽管DCT修剪比传统DCT和许多已经出现在文献上的算法快,但是到目前为止,大多数快速DCT修剪算法并没有具体的软件实现,而且仅有的一些软件实现也都是基于通用处理器的.基于通用处理器的软件实现通常远比基于DSP的实现速度慢.DSP是一类特殊的经过优化以用来处理各种信号处理应用程序的处理器,如FIR滤波器、傅里叶变换FFT、DCT以及他们各自的修剪算法.在工业上,DSP作为各种信号处理应用程序的平台,发挥着重要的作用.德州仪器(TI),模拟设备公司(ADI)和飞思卡尔等DSP制造商已经提供了很多不同的DSP芯片及其评估板材和仿真工具,供大学研究和工业使用.由于其性能的优异性、灵活性以及合适的成本,基于DSP的软件实现已经成为优良的商业产品解决方案.
然而在实际当中,基于DSP的快速而有效的FCT修剪实现仍然很困难.众所周知,DSP系统的内存访问会导致较长的时钟延迟和大量的功耗,因此运算成本非常高.如在TI TMS320C64x DSP中,执行一个内存装载指令会花费四个时钟周期.因此频繁内存访问会大幅增加时钟周期数.尽管DCT修剪与快速DCT算法相比能减少一定数量的内存访问,但却没有根本解决问题.诸如修剪FCT[11]中还是存在大量由输入点和权重因子(余弦系数)而导致的内存访问数量,这也在很大程度上影响了速度的提高.
本文提出了一个新的减少内存访问的修剪FCT算法.首先利用修剪FCT中权重因子的性质来减少运算所需的权重因子数.然后将运算流程图内两个阶段中的蝴蝶计算结构合并到一个阶段,从而形成一个高效的蝴蝶计算结构来进行计算.实验结果表明,该方法可以节约用于保存权重因子的内存空间,并且也能显著减少运算所需的内存访问以及时钟周期的数量.
2 快速离散余弦变换的修剪算法
修剪FCT回顾:本节首先简要介绍FCT(快速离散余弦变换)的基本思想.然后简要介绍基于FCT的修剪FCT.
2.1直接FCT计算
式(1)给出了最常用的离散余弦变换: II-型DCT.
为简便起见,我们将公式右边的比例系数一起整合到X[m]中,并应用于文献[12]中提到的输入映射:
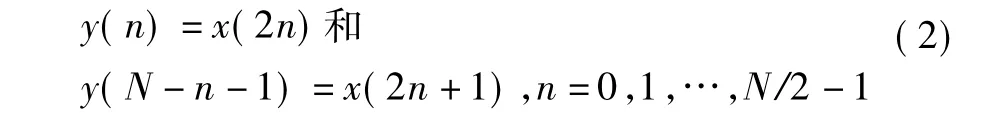
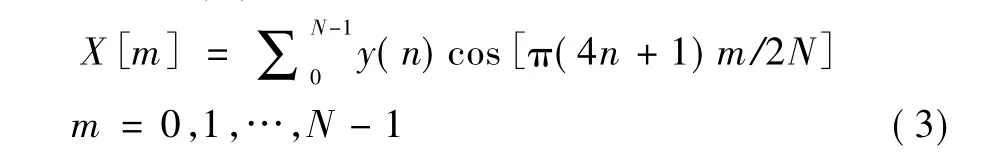
接着通过使用三角函数的性质(4)以及将式(3)中的输出序列X[M]分解为奇数与偶数索引部分.
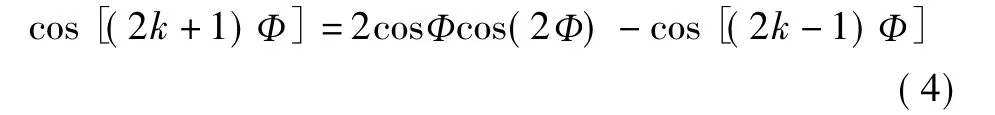
于是便有了两个N/2点DCT[12].然后进一步分解直到一系列两点输入DCT,便得到了按频率分解的FCT[11].图1列出了FCT运算流程图.(注:目前在流程图中虚线和实线是相同作用的).它由两部分组成:蝴蝶计算部分和后序操作部分.在蝴蝶计算部分除了输入点和系数(2c)不同以外,算法流程与FFT类似.如图所示,蝴蝶计算部分与后序操作部分相比,产生了大部分内存访问和CPU计算.本文的内容将专注于蝴蝶计算部分.
2.2修剪FCT
DCT在具备快速算法的一类转换运算中具备非常优越的能量压缩属性.正是这种可以仅仅计算部分系数的属性,使得DCT在各种图形信号处理应用程序中最适合处理有损数据压缩转换.通常,25%的DCT系数已经能够很好的压缩和恢复图像,而不会造成视觉上的差异[2].如在图1的N个DCT系数中,如仅计算前N0个低频组件(其中N0= 3,N = 16,N0不一定是2的整数幂),那么就不用处理图中虚线对应的所有运算,因此修剪FCT相比一般FCT能节省一些操作(包括CPU运算和内存访问操作).不过实际运算中,它还是存在很多由权重因子和输入点X[]而导致的内存访问.
然后式(1)就改写为
3 修剪FCT的内存访问优化方法
为了解决上述提到的问题,我们提出了内存访问优化方法,该方法通过两个步骤来应用于修剪FCT.
步骤1:利用权重因子的余弦函数属性(5),将实现N点修剪FCT的权重因子数量由N - 1减少到「(2N -1)/3」.
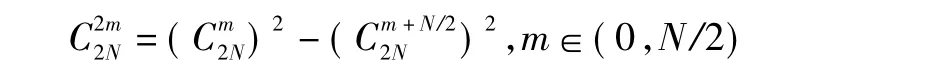

例如在图1中的阶段3和4中的蝴蝶运算单元需要分别与权重因子:结合计算.其中可用取代,推导过程如下:
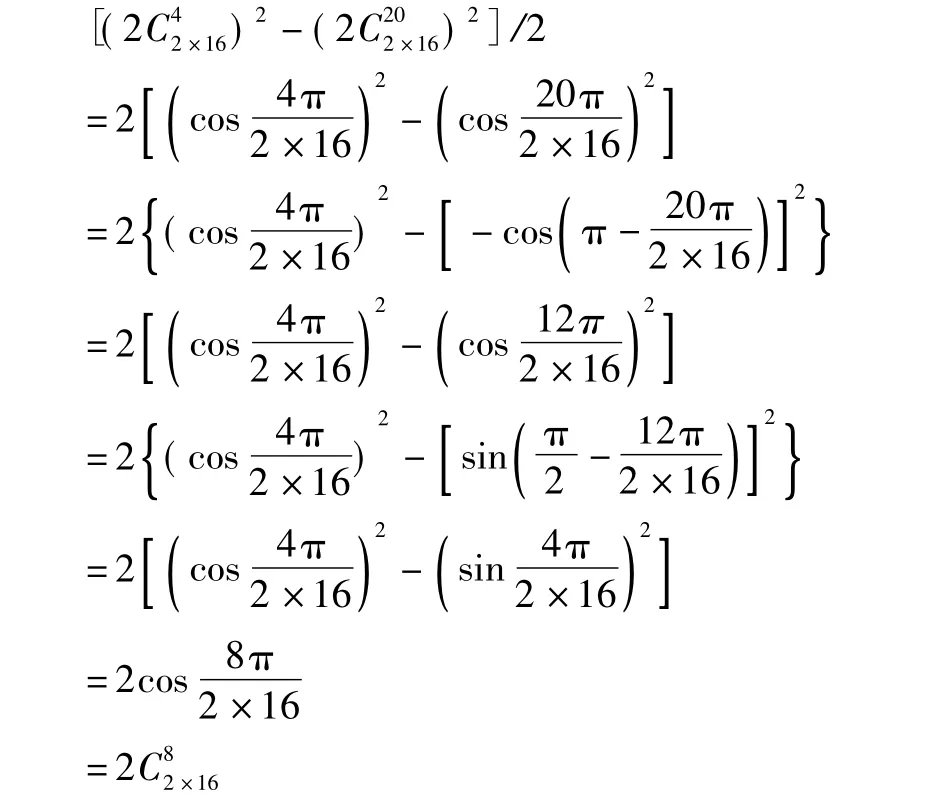
步骤2:在运用上述特性后,将相邻两个阶段中的全部蝴蝶运算单元合并到一个阶段中进行运算.
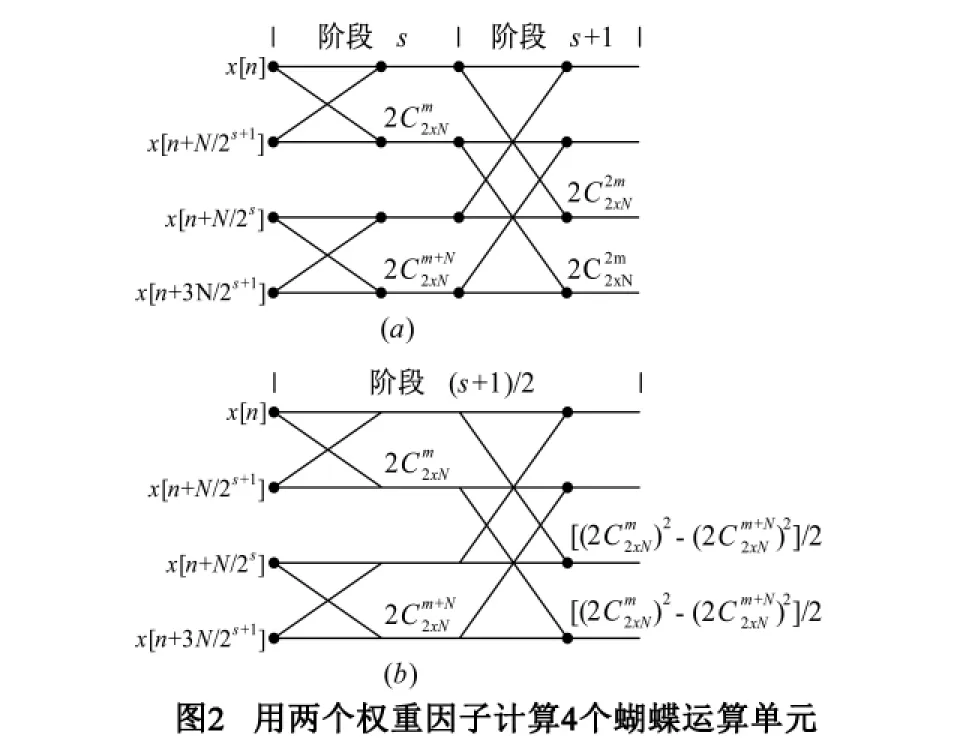
在修剪FCT计算流程图中蝴蝶计算部分的阶段s中有N/2s个不同的权重因子,它们按照如下方式进行排列:阶段s(s =0,1,2,……,log2N - 1)的第一个权重因子是:= cos(kπ/2N));阶段s的第二个权重因子由第一个权重因子中的k加上N得到,即第三和第四个权重因子是由前两个因子分别在他们的参数k上加N/2得到.在同一阶段的其余权重因子都是通过这个递归过程而产生.因为在运行修剪FCT算法前对输入点进行了重排序[12],所以在每个阶段里的所有的蝴蝶运算单元都可以按照自然数输入序列的常规方式来从上向下逐一进行计算.图2(a)描绘出一般情况下在阶段s和s + 1中相邻的4个蝴蝶运算单元之间的计算关系.
定理如图2(a)所示,修剪FCT的蝴蝶计算部分阶段s和s +1(s≤log2N -1)中的四个蝴蝶运算单元只需通过加载如图2(b)所示的两个权重因子和来计算.
证明根据图2(a),阶段s +1的蝴蝶运算单元需要结合权重因子计算,而,根据三角函数属性: cos2A = cos2A—sin2A,权重因子2cos(2mπ/ 2N)可改写成2(cos(mπ/2N))2-2[sin(mπ/2N)]2,第一项而第二项2[sin(mπ/2N)]2可变为:2 { cos[(π/2)-(mπ/2N)]}2= 2{ cos[(π/2)+(mπ/2N)]}2= 2 { cos[(m +N)π/2N)]}2这样就可以得到阶段s + 1的权重因子:
因此,阶段s + 1内的权重因子可以由阶段s内的两个权重因子推导出,所以只需加载这两个权重因子便可以一起计算这4个蝴蝶运算单元.
在减少权重因子后,我们将每两阶段中的蝴蝶运算单元合并在一个阶段中以形成一个如图2(b)所示的高效蝴蝶运算单元,所以当log2N是奇数时,该方法要将阶段1到阶段log2N -1内的所有蝴蝶运算单元合并到(log2N -1)/2个阶段内来计算,而在阶段log2N最后奇数阶段)中的所有蝴蝶运算单元还需用传统的修剪FCT方法来计算.
利用完该方法后,图1中的蝴蝶计算部分便可重新被画为图3所示.假设图1和3均需要计算16个DCT系数,即图中的实线和虚线没有区别,那么图3需要加载10个权重因子,而图1的传统修剪FCT却需加载15个权重因子.此外在图3中由输入点X[]产生的内存访问只发生在图中黑色和白色圆圈,而图1里的由输入点导致的内存访问却发生在所有蝴蝶运算单元两边所有圆圈内.
如果仅需计算部分DCT系数,则可以省略两图中的虚线部分,也就省去了相应的运算操作,并减少了图中由黑圈所标识的内存访问量.如图1所示,在16点修剪FCT中,当N0= 3,也即只计算3个DCT系数时,蝴蝶计算部分中因输入点产生的内存访问量为87,而当N0=16时它增加为128,相比之下在图3中,当N0= 3,因输入点产生的内存访问量为仅为43,而当N0= 16时它增加为64.

4 内存访问优化方法的性能评价
假设N点输入中计算N0个DCT系数,同时查看N0是2的整数幂的特殊情况,在传统修剪FCT的蝴蝶计算部分中,由输入点产生的内存访问量为(2log2N0+3)N -3N0,采用本文的方法后,内存访问量减少到如下表达式:

并且该方法可以使N点修剪FCT中由权重因子产生的内存访问量从N -1它减少到「(2N -1)/3」.
为了能方便全面推广,我们选取了一款比较通用的处理器: TI TMSC320C64x DSP为测试平台.实验中编写了两段C代码来对比:代码C1用传统算法实现修剪FCT,代码C2则基于内存访问优化方法实现修剪FCT.两段代码都包括一段相同的基于[11]的后序操作部分.测试环境采用德州仪器设计的软件开发工具Code Composer Studio(CCS).由于篇幅限制,我们只能用如下三个表来报告当修剪值N0为2的整数幂时的对比数据:表1列出时钟周期数;表2列出由权重因子和输入点产生的内存访问量;表3列出存储权重因子所需内存量.
结果表明,应用该方法的修剪FCT相比于传统方式能减少平均40%的由权重因子和输入点产生的内存访问量,减少平均48.6%的时钟周期数和节约平均32.6%的内存空间.目前公认25%的DCT系数就能很好地重建图像[2],而当修剪值N0为N的25%时,该方法可以减少平均44%的内存访问数量,以及减少平均51.3%的时钟周期数.
5 结论
本文提出了实现修剪FCT算法的内存访问优化方法.它先利用权重因子的余弦函数属性来减少计算过程中所需加载的权重因子数,然后将计算流程图中两个阶段中的蝴蝶运算单元合并到一个阶段以形成一个高效蝴蝶单元结构.实验结果表明:相比于传统实现算法,该方法可以减少平均40%的内存访问数量,减少平均48.6%的时钟周期数和减少平均32.6%的用于存储权重因子的内存空间.
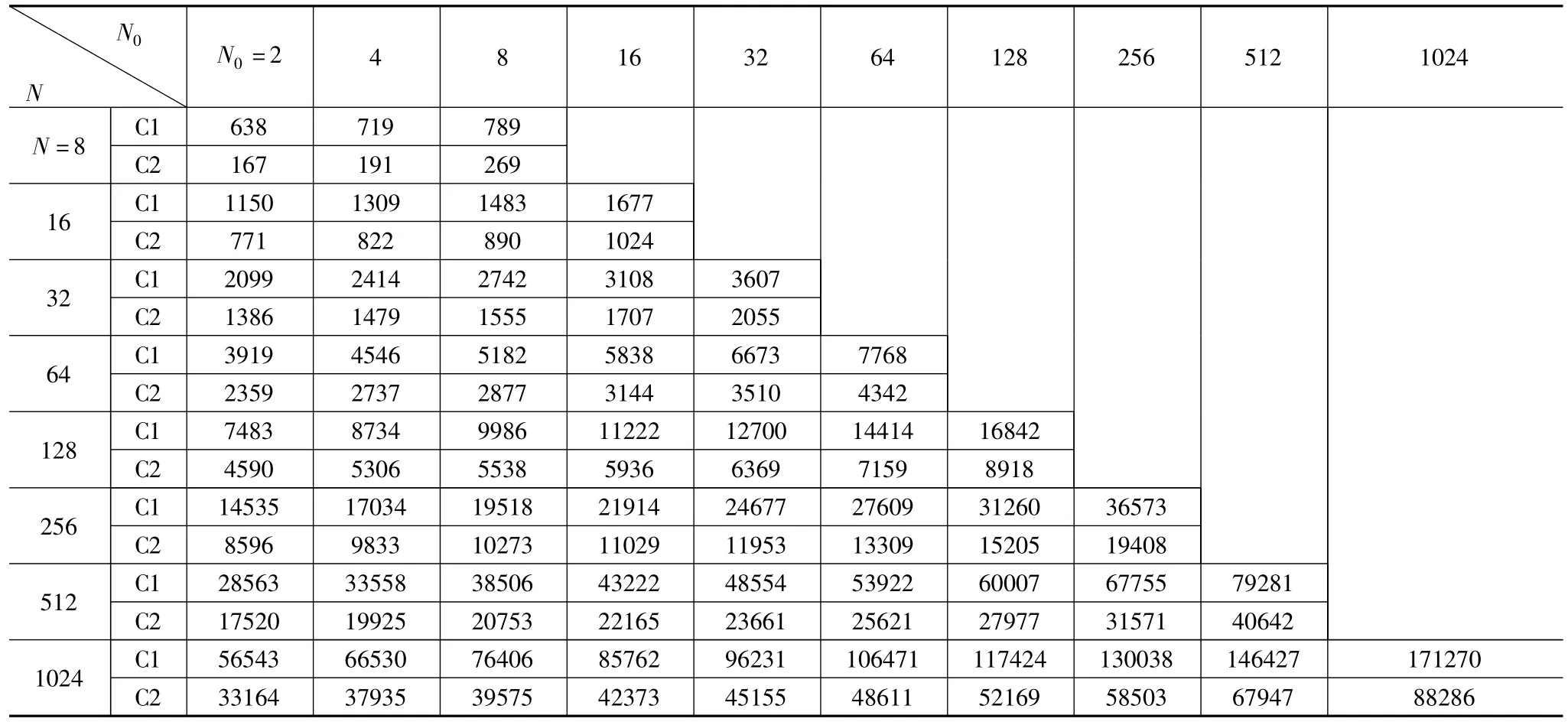
表1 时钟周期数的比较
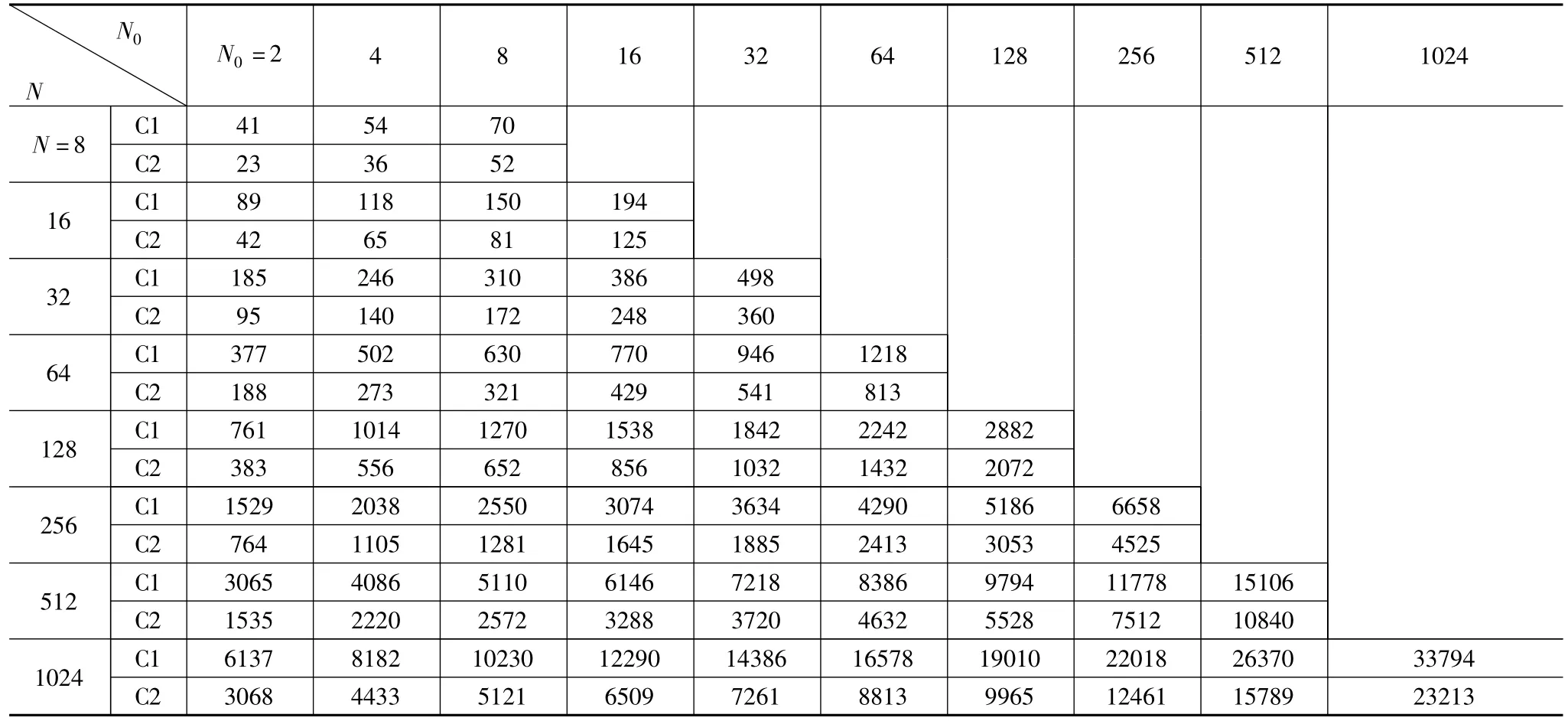
表2 内存访问量的比较
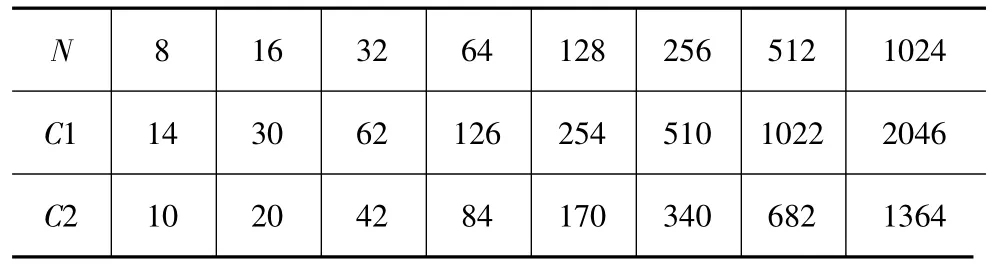
表3 存储权重因子所需内存空间(Byte)的比较
参考文献
[1]N AHMED,T NATARAJAN,K R RAO.Discrete Cosine transform[J].IEEE Transactions on Computers,1974,C -23: 90 -93.
[2]K R Rao,P Yip.Discrete Cosine Transform: Algorithms,Ad-vantages,Applications[M].New York: Academic.1990.
[3]M Wezelenburg.General radix - 2n DCT and DST algori thms[A].Proceedings of the International Conference on ECCTD’97[C].Budapest,Hungary,1997.789 -794.
[4]李永亭,齐咏生,肖志云.基于量化的二维DCT优化算法研究[J].计算机工程与应用,2010,46(2): 181 -183.
[5]沈鹏.基于多维矢量DCT正交矩阵变换及熵编码算法的研究[D].吉林:吉林大学,2011.
[6]刘斌,何剑锋,孙玲玲.基于FPGA的H.264 DCT算法的硬件实现[J].现代电子技术,2012,35(10): 90 -92.
[7]许亚军,韩雪松,韩应征.AVS二维DCT变换的FPGA实现[J].电视技术,2013,37(11): 18 -21.
[8]R Stasiliski.On pruning the discrete Cosine and Sine transforms[A].IEEE MELECON 2004[C].IEEE,2004.269 -271.
[9]Mohamed El-Sharkawy,Waleed Eshmawy.A fast recursive pruned DCT for image compression applications[A].Proceed-ings of the 37th Midwest Symposium on Circuits and Systems[C].Los Angeles,USA: IEEE,1994.887 -891.
[10]Z Wang.Pruning the fast discrete Cosine transform[J].IEEE Trans Communications,1991,39(5): 640 -643.
[11]Athanassios N Skodras.Fast discrete Cosine transform pruning[J].IEEE Transactions on Signal Processing,1994,42(7): 1833 -1837.
[12]A N Skodras,A G Constantinides.Efficient input-reordering algorithms for fast DCT[J].Electronics Letters,1991,27(21): 1973 -1975.
刘项洋男,1979年6月生于安徽省芜湖市,博士,现为安徽师范大学数学计算机科学学院讲师,主要研究方向为数字信号处理算法、嵌入式计算.
E-mail: 33736326@ qq.com

许勇男,1966年12月生于安徽省六安市.博士,安徽师范大学数学计算机科学学院教授,研究方向为计算机网络和嵌入式计算.
E-mail: yxull@ mail.ahnu.edu.cn
Memory Access Optimization Method for the Implementation of Fast DCT Pruning on DSP
LIU Xiang-yang,XU Yong
(School of Math and Computer Science,Anhui Normal University,Wuhu,Anhui 241000,China)
Abstract:In this paper,we propose a memory access optimization method to minimize the memory accesses due to weighting factors(cosine coefficients in the computation diagram of fast DCT pruning)and input points for implementing fast DCT pruning on DSP.The proposed method reduces the number of memory accesses in two steps: 1.Reduce the number of weighting factors; 2.Combine butterflies at two stages in fast DCT pruning diagram to form an efficient butterfly structure in one stage and calculate them.The proposed method is applied to implement Pruning FCT on TI TMSC320C64x DSP.Experimental results show that the proposed method can achieve an average of 40%memory access reduction,48.6%clock cycle reduction and 32.6%of memory space saving for weighting factors to compute Pruning FCT on DSP comparing with the conventional implementation.
Key words:digital signal processor(DSP); discrete Cosine transform(DCT); memory access
作者简介
收稿日期:2014-05-19;修回日期: 2015-07-06;责任编辑:李勇锋
DOI:电子学报URL:http: / /www.ejournal.org.cn10.3969/j.issn.0372-2112.2016.01.034
中图分类号:TN911.23
文献标识码:A
文章编号:0372-2112(2016)01-0227-06
