
FilterFA:一种基于字符集规约的模式串匹配算法
2016-06-21 15:05张萍何慧敏张春燕曹聪刘燕兵谭建龙
通信学报 2016年12期
张萍,何慧敏,张春燕,曹聪,刘燕兵,谭建龙
(1.中国科学院信息工程研究所,北京 100093;2.中国科学院大学,北京 100049;3.信息内容安全技术国家工程实验室,北京 100093;4.中国移动(深圳)有限公司,深圳 518031)
FilterFA:一种基于字符集规约的模式串匹配算法
张萍1,2,3,何慧敏4,张春燕1,3,曹聪1,3,刘燕兵1,3,谭建龙1,3
(1.中国科学院信息工程研究所,北京 100093;2.中国科学院大学,北京 100049;3.信息内容安全技术国家工程实验室,北京 100093;4.中国移动(深圳)有限公司,深圳 518031)
多模式串匹配技术是入侵检测系统的核心技术之一,Aho-Corasick算法广泛应用于其中。针对AC自动机内存开销巨大影响算法性能的问题,提出一种基于字符集规约的改进算法——FilterFA。利用字符集映射函数将原字符集压缩为多个像字符集,针对像字符集构造新的自动机FilterFA,将空间复杂度降至。在随机数据集和真实数据集ClamAV上的测试结果表明,当像字符集大小为8,且保证误识别率小于2%时,FilterFA算法消耗的存储空间仅为AC算法的3%左右。
入侵检测;多模式串匹配;字符集规约;字符集映射
1 引言
字符串匹配问题是网络入侵检测系统的核心技术之一,在近几十年的发展中研究非常广泛。它广泛应用于信息安全、文本检索和计算生物学等领域。著名的入侵检测系统 Snort[1]包含多种规则匹配算法,如Boyer-Moore(BM)[2]、Wu-Manber(WM)[3]和Aho-Corasick (简称AC)[4]算法。其中,BM算法适合单模式串匹配问题,AC算法和WM算法适用于多模式串匹配。
自20世纪70年代以来,字符串匹配技术有着显著的发展,国内外多位研究者相继提出了上百种模式串匹配算法。根据其搜索方式的差异性,Gonalo Navarro和Mathieu Raffinot[5]将字符串匹配算法分为3类:基于前缀的模式串匹配算法、基于后缀的模式串匹配算法和基于子串搜索的模式串匹配算法。其中,基于前缀的模式串匹配算法在搜索窗口内搜索既是窗口中文本的后缀,同时也是模式串子串的字符串,这类算法可以达到亚线性的平均时间复杂度。基本思想是:在搜索窗口内从左向右逐个读入文本字符,搜索窗口中文本和模式串的最长公共前缀,其代表算法包括Multiple Shift-AND[6]和AC。Multiple Shift-AND算法利用位并行来模拟前缀识别的过程,但其应用范围受制于机器字长;AC算法使用AC自动机识别模式串的前缀。理论分析表明,AC算法具有线性的搜索时间复杂度,AC自动机的性能稳定,因而在实际中应用十分广泛。
然而在AC算法中,AC自动机的每个状态节点都需要|Σ|个指针来存储其状态转移表,空间复杂度为(各符号定义见下文)。在处理大规模的串匹配问题时,AC算法存储空间带来的瓶颈,使其匹配速度大幅度降低。
因此,如何降低AC自动机的存储空间开销,成为扩大其应用范围的关键因素之一。本文提出一种基于字符集规约的AC改进算法——FilterFA算法,通过字符集映射函数将大小为|Σ|的字符集映射到大小为|Σ′|的字符集上,使空间复杂度降低至原来的,大大降低了AC算法的存储空间开销。与此同时,该算法采用随机取模和字符概率均匀分布2种字符集映射策略,利用启发式的思想对字符概率进行了统计,构造出字符集映射函数,并在随后的随机数据和真实数据上进行测试,该算法在存储空间和匹配速度方面均取得了不错的效果。
为统一下文所用的相关符号,现定义如下:给定一组特定的字符串集合P={p(1),p(2),…,p(r)},对于任意的一个字符串T=t1t2…tn,找出P中所有字符串在T中的所有出现位置。P为模式串集合,P中的元素p(i)为模式串(或关键词),T为文本。其中,是定义在有限字母表∑上的字符串,r表示模式串的个数,表示所有模式串的长度之和,n=|T|表示待匹配文本的长度,Σ表示字母表(或字符集),σ=|Σ|表示字母表的大小。假设Σ上的字符之间相互独立,服从概率分布X~ (xi,pi),xi∈Σ。以下分析均基于字符间相互独立的假设。
2 相关工作
多模式串匹配算法中与压缩算法相关的国内外的代表性工作介绍如下。
Aho和Corasick提出了基于前缀搜索的多模式串匹配算法——AC算法,从模式串集合构建AC自动机,通过对自动机的访问进行匹配。该算法匹配的时间复杂度正比于待扫描文本长度,不受关键词长度和文本统计特征的影响,性能比较稳定。但因其存储空间巨大带来的瓶颈,使算法匹配速度大幅度降低。为了解决自动机的存储空间引发的性能瓶颈,国内外研究者提出了多种压缩方案,目前比较常用的压缩方案有行压缩方法[7]、Banded-Row方法[8]、位图表示法[9]、双数组方法[10~12]和散列方法[13]等。
在行压缩方法状态转移表中,每个状态下的一行中只存储非空的状态转移边对应的读入字符及下一跳状态。当自动机的状态转移表非常稀疏时,该方法具有很好的压缩效果,但是状态自动机比较稠密时,该方法的压缩效果变差,甚至会超过压缩前的存储空间。
Banded-Row方法应用于Snort中,用来优化AC算法,其核心思想是:对存储矩阵的每一行,只存储从第一个非空元素到最后一个非空元素之间的元素。若用数组BV[]表示,则BV[0]中存储第一个非空元素的位置,BV[1]中存储“带宽(bandwidth)”(即第一个非空元素和最后一个非空元素之间的元素的个数),BV[2,3,…,1+bandwidth]存储第一个非空元素到最后一个非空元素之间的所有元素。该算法同样也不适用于状态自动机比较稠密的情况。
位图表示法中,状态转移表中每一行用一个与字符集大小相等的比特向量表示该行任意字符对应的下一跳状态是否为空,转移表中每一行只按照前述比特向量的顺序存储非空的转移边。该方法具有极好的压缩效果,但是搜索过程中状态转移边的查找需要硬件支持,不适合软件实现,不利于推广实现。
双数组方法使用一个一维数组重叠排列状态转移表中所有的行,但必须保证各行的非空元素不得相互冲突,另外用2个数组分别存储每一行的偏移位置和一维数组中每个元素所属的行。该方法具有较好的压缩效果,并且可以达到O(1)的状态转移速度,但处理过程中峰值内存太大,导致其不能处理大规模的串匹配问题。
散列方法的核心思想是用尽可能小的存储空间S来组织存储矩阵T,使在尽可能短的时间内(用探测S的次数来度量)来查找元素q在S中位置。Fredman等[14]给出了基于完美散列的解决办法,算法具有O( n)的空间复杂度,O(1)的最坏时间复杂度。实际应用中,计算完美散列函数的代价很大,会极大地影响算法的性能,故不具有实用性。
杨毅夫[15]等将上述几种压缩方法实现的AC算法进行了比较,实验结果表明,在存储空间方面,在多数情况下,行压缩方法占用的存储空间最小,空间压缩率达到95%以上,其次是双数组方法、Banded-Row方法和散列方法;匹配时间方面,双数组方法具有最优的匹配时间,Banded-Row 方法次之,行压缩方法较慢,位图方法和散列方法最慢。文献[15]还指出,几种方法的存储空间与稀疏性有关,位图方法、行压缩方法和散列方法的存储空间随稀疏率的增大而线性增加。在稀疏率小于5%时,Banded-Row随稀疏率的增加逐渐接近原AC算法的存储空间。而行偏移方法随稀疏率的变化很大。
除上述常见的压缩方案,近年来,对串匹配算法的压缩算法也不断更新。Nieves[16,17]提出了一种k2-tree的方法,用来解决网络图结构中关联矩阵的压缩问题。它的主要思想是利用rank-select操作将矩阵按照树的结构存储从而减少不必要的0的个数。由于采用了位操作,该算法的压缩效果极好。但查询速度与压缩之前相比,有所降低。
HashTrie算法[18]利用rank操作与散列函数结合的方法,预处理阶段将字符串及其前缀经散列函数转化为某个值,存储在B表和F表中,同时M表存储与F表相对应的字符串链表;匹配阶段,能快速定位文本串的散列函数值,若散列表中存在此散列值,则去M表进行校验,从而判断是否真正匹配。HashTrie算法的空间复杂度仅为O(| P|),优于经典多模式串匹配算法AC的空间复杂度。但HashTrie算法更适合于模式串集合规模较大、模式串长度较短的多模式串实时匹配问题。
综上所述,针对存储空间进行压缩的多种算法在处理串匹配问题时各有优缺点,而且同一种方法在不同数据集上差别也很大。除HashTrie算法采用位向量的形式存储模式串信息之外,传统算法多采用二维状态转移矩阵存储模式串信息,内存消耗巨大。已有的压缩方法没有考虑到针对字符集压缩的方法,而AC自动机适用于小字符集的应用场景。因此,本文将从字符集方面入手,设计更加高效的多模式串匹配压缩算法,这具有重要的理论和实际意义。
3 FilterFA:基于字符集归约的模式串匹配算法
AC算法是串匹配的经典算法,是目前应用最广泛的算法之一。AC自动机的空间复杂度为,与字符集大小成正比。当字符集较大时,存储空间会迅速增长,成为影响算法性能的一个重要因素,是处理大规模串匹配问题的一个瓶颈。Gonalo Navarro和Mathieu Raffinot[5]在随机数据集上,对多种串匹配算法进行比较。实验表明,基于前缀搜索的AC算法、基于后缀搜索的WM算法和基于子串搜索的SBOM算法是最为有效的算法。由图1可以看出,相对于大字符集应用场景,AC自动机更适用于小字符集的应用场景。
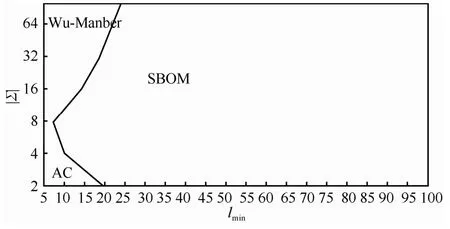
图1 搜索1 000个模式串最有效的算法图谱
针对AC算法适用于小字符集这一特点,FilterFA算法从字符集出发,利用启发式的字符集变换策略,将大字符集转化成小字符集,并利用转化后的小字符集构造自动机FilterFA,最终降低算法的存储空间开销。FilterFA算法的自动机压缩基本原理如图2所示。
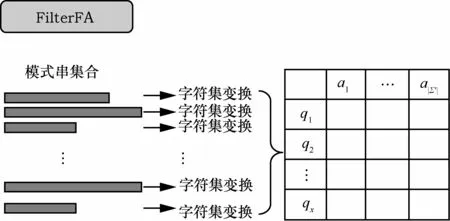
图2 FilterFA算法的自动机压缩基本原理
定义1设Σ为原字符集(大小为σ),Σ′为新定义的字符集(大小为σ′),且|Σ′|<|Σ|,将由模式串集合在像字符集Σ′上构建的确定自动机称为FilterFA。设f∶Σ→Σ′是字符集Σ到Σ′的映射。记映射前字母的概率分布为si(0≤i<|Σ|),映射后字母仍然服从某一概率分布为qi(0≤i<|Σ′|),则称f为从字符集Σ到字符集Σ′的映射函数。
FilterFA算法主要包含3个阶段:数据训练阶段、预处理阶段和扫描阶段。
在数据训练阶段,依据训练文本数据,统计每个字符出现的概率信息。按照字符概率均匀分布的原则,求解使误识别率最小的字符集映射函数。利用该映射函数,将大字符集压缩为多个像字符集。在训练数据集上求解字符集映射函数时,基于字符独立假设,像字符集服从依概率均匀分布,把FilterFA算法误识别率降到最低,从而将因误匹配而产生的多余校验对算法匹配速度的影响降至最低。
在预处理阶段,主要任务是FilterFA自动机的构造。根据模式串集合在小字符集范围上,构建Trie树,再由Trie树构建FilterFA自动机。
在扫描阶段,利用预处理阶段得到的FilterFA自动机对文本进行扫描,最终输出所有正确匹配的结果。
FilterFA算法的基本处理流程如图3所示。
3.1 误识别率和像字符集Σ′大小的选择
在利用字符集映射函数将一个大的字符集映射到一个较小的字符集上时,有很多种方法,如随机取模。随机取模的方法简单易操作,却存在着多对一映射冲突的问题。即不同的字符经过字符集函数映射之后,变成相同的字符。例如,若字符i和字符o通过f映射之后,变为相同的字符,在扫描阶段,就会出现将“string”和“strong”误识别的情况。因此,在利用字符集映射函数在小字符集范围内构造FilterFA,进行匹配的过程中,会出现误匹配的情况。
定义2设f∶Σ→Σ′是字符集Σ到Σ′的映射函数,p(i)是定义在有限字母表(字符集)Σ上长度为mi的模式串。T=t0t1…tn−1是长度n的文本串。称通过此字符集映射函数f变换得到的FilterFA自动机扫描文本T后引起的对该模式串错误识别的概率(即误匹配的次数与报告的总匹配次数之比)为模式串p(i)的误识别率。
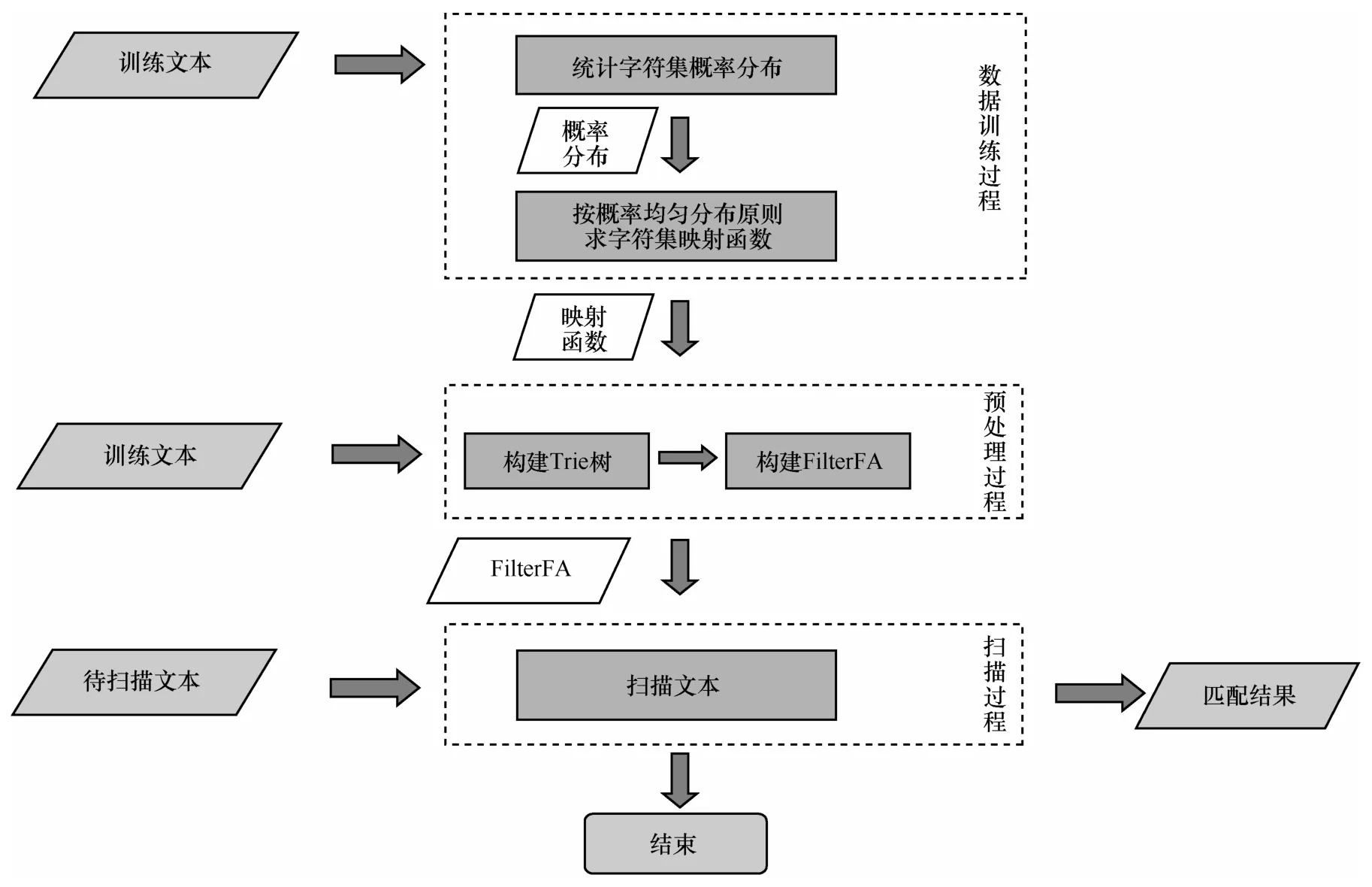
图3 FilterFA算法的基本处理流程
设p=p0p1…pm−1是长度为m的模式串,t=t0t1…tm−1是长度m的文本串,假设字符间相互独立,则p与t的误匹配的概率Prfalse为
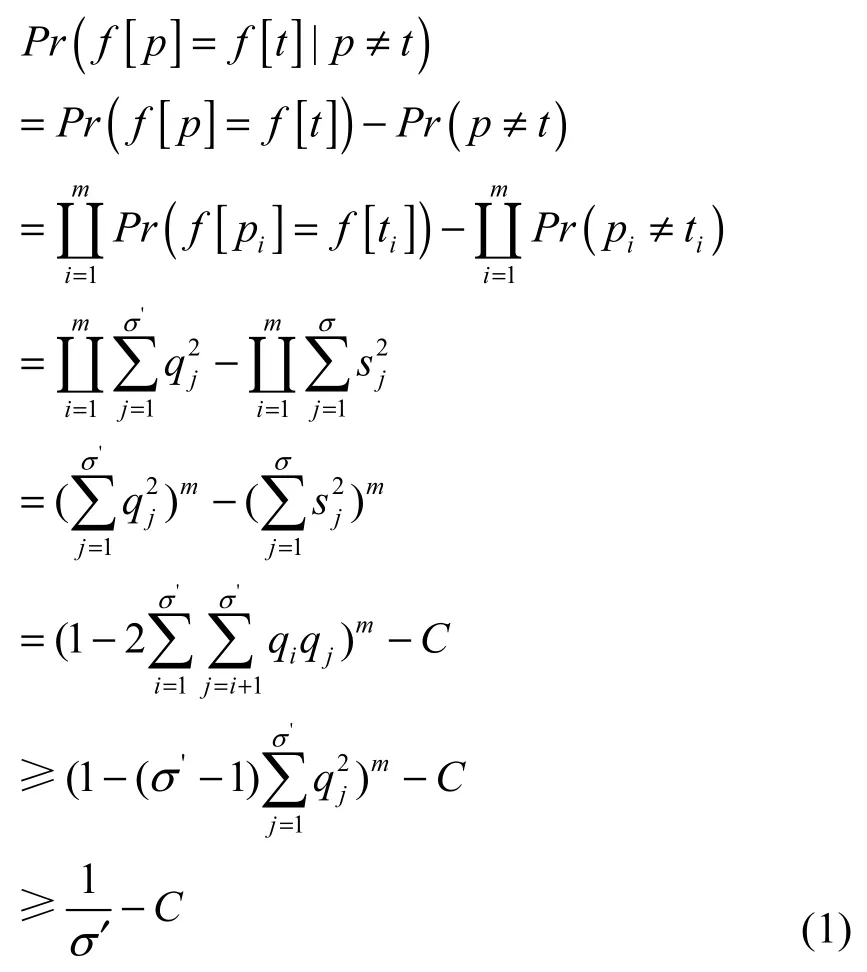
其中,C为常数,和已知的训练数据集有关。
根据上述公式推导过程,当q1=q2=…=qm,即通过字符集映射之后得到的像字符集满足依概率均匀分布时,因字符集映射而引起的误识别率最小,为。因此,在具体实现时,采用字符集映射函数减少计算代价、提高算法效率,同时,按照依概率均匀分布原则选取字符集映射函数,从而将FilterFA自动机误识别率降至最低。
字符集Σ在通过字符集函数f映射之后,得到一个较小的字符集Σ′。存储空间与字符集的大小成正比,字符集越小,存储空间越小。FilterFA自动机的存储空间也因此降低,字符集变化前后二者的存储空间比为。字符集映射函数f不同,映射得到的像字符集Σ′大小不同,对模式串匹配速度的影响也不同。
在式(1)的推导过程中,可以看出,随着字符集的减小,存储空间开销减小,误识别率反而增大。对于同一个文本来说,FilterFA自动机误识别率越大,需要校验的次数越多,从而使匹配系统的性能降低。
在算法设计时,选取不同的字符集映射函数在大小不同的像字符集上测试,考察误识别率对匹配速度的影响。由表1可以看出,字符集映射函数的选取对算法的性能影响差异显著;在像字符集大小固定时,误识别率越大,匹配速度越小。因此,字符集映射函数的选取对算法性能的影响至关重要。一方面要尽可能降低存储空间开销,另一方面要控制误识别率以减少校验工作量。综合以上2方面,在FilterFA算法中,选取合适的使算法误识别率较小的字符集映射函数对算法性能影响巨大。
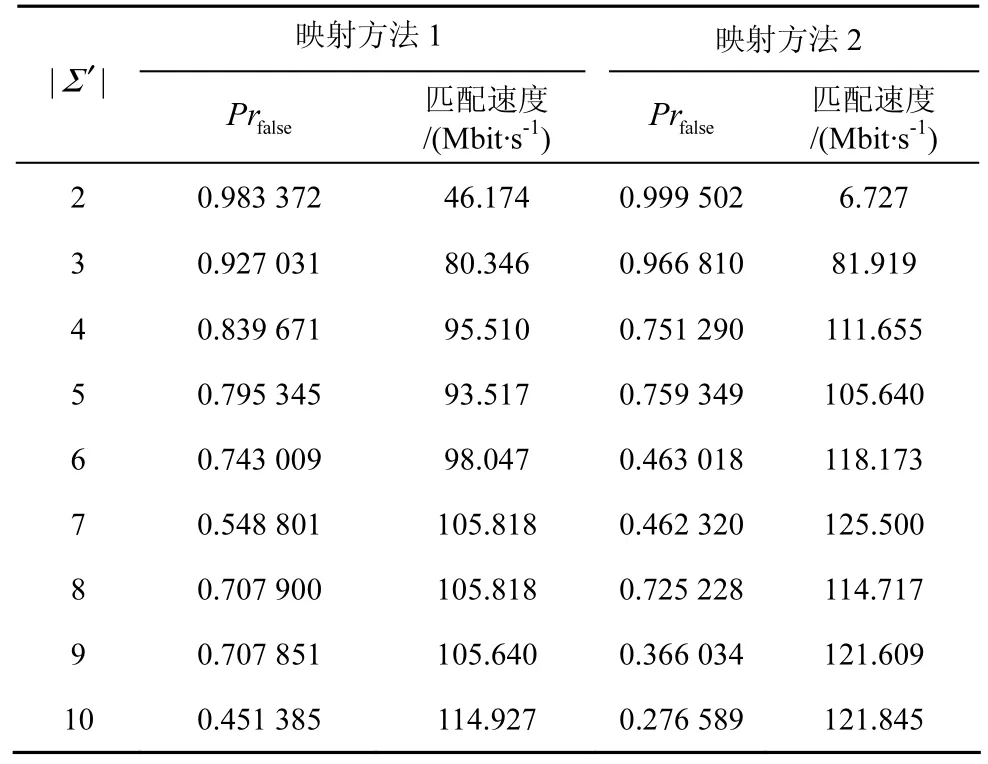
表1 误识别率对匹配速度的影响
3.2 字符集映射函数求解
依据训练数据集统计得到原字符集中字符的概率分布,求解字符集映射函数,问题抽象如下。
已知字符集Σ,Σ上的字符服从概率分布X~ (xi,pi),xi∈Σ,p(i)是定义在有限字母表(字符集)Σ上长度为mi的模式串。T=t0t1…tn-1是长度n的文本串。求字符集映射函数f,使通过该字符集映射函数f变换得到像字符集Σ′,满足在Σ′上构造的FilterFA自动机扫描文本T后引起的识别率Prfalse最小。
由上节分析可知,当像字符集服从等概率均匀分布时,由字符集映射函数压缩字符集而引起的误识别率最小。因此,原问题进一步抽象为按照字符依概率均匀分布的原则求字符集映射函数问题,如下。
已知字符集Σ,Σ上的字符服从概率分布X~ (xi,pi),xi∈Σ。求字符集映射函数f,使经f映射之后得到的像字符集Σ′,Σ′上的字符服从等概率均匀分布。
进一步,可将上述问题转化为如下组问题。
如何把原字符集Σ分为σ′组,使分组后的字符子集服从等概率分布,即。
上述字符集分组问题是一个NP问题,利用启发式方法近似求得最优解:统计原字符集中所有字符出现的概率,并将字符集的所有字符按其概率大小进行排序;将出现概率大于等于的字符单独分为一组,把其余字符依次添加到当前概率最小的分组;通过交换任意2个元素的分组,使分组后的概率尽可能均匀。
近似最优映射函数求解算法具体实施过程见算法1。
算法1近似最优映射函数求解算法

3.3 FilterFA自动机的构建与扫描过程
在预处理阶段,主要任务是FilterFA自动机的构造。读入模式串,利用算法1得到的字符集映射函数将模式串映射为新的模式串;针对映射后得到的像模式串,采用AC算法中Trie树的构造算法,构建对应的Trie树;将Trie树完全化,得到FilterFA自动机。
FilterFA算法中FilterFA自动机的具体构造过程如算法2所示(其中,算法2中Trie的构造采用文献[5]中的Trie算法)。
算法2FilterFA自动机的构造

在扫描过程中,读入文本,对文本中的字符进行逐个扫描。每扫描一个字符,经字符集映射函数映射,并将映射后得到的字符传送至FilterFA自动机。自动机根据当前状态节点和字符进行跳转,每跳转至一个新的状态节点,同时判断其是否为终止状态。若当前状态为终止状态,说明当前位置出现可能匹配。鉴于字符集映射函数可能将不同的字符映射为同一字符,需要对匹配结果进行进一步校验。把该终止状态对应的模式串同对应位置的文本串后缀中的字符进行一一比较,验证是否为正确匹配结果。校验至模式串最后一个字符,校验过程结束。校验完成,读入下一个字符,开始新一轮搜索;若当前状态为非终止状态,则直接读入下一个字符,开始新一轮搜索,直至整个文本扫描一遍为止,返回最终匹配结果。
FilterFA算法的具体扫描过程见算法3。
算法3FilterFA算法的扫描过程

以模式串集合{he,hers,she}为例,其对应的AC自动机和FilterFA自动机分别如图4和图5所示。
3.4 空间和时间复杂度分析
下面分析FilterFA算法的空间复杂度和时间复杂度。
定理1FilterFA算法的空间复杂度为,数据训练阶段的时间复杂度为,预处理阶段的时间复杂度为,搜索阶段的平均时间复杂度为O(n)。
证明
1) 空间复杂度:FilterFA算法的数据存储结构为FilterFA自动机。自动机有个状态,每个状态节点需要|Σ′|个指针来存储其状态转移表。因此,FilterFA算法的空间复杂度为。
2) 数据训练阶段的时间复杂度:在数据训练阶段,主要任务为字符依概率排序和分组。在对原字符集依概率排序时,采用快速排序算法所需时间为。将原字符集分为组,对于任一字符,查找当前概率最小的分组,需要,最终分组需要时间为。因此,数据训练阶段的时间复杂度为。
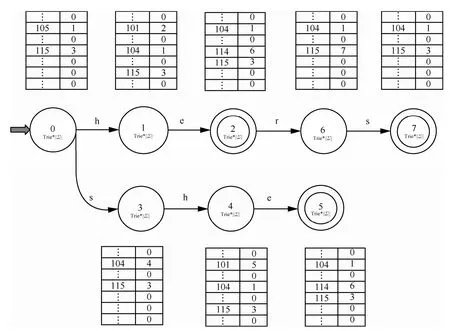
图4 模式串{he,hers,she}对应的AC自动机
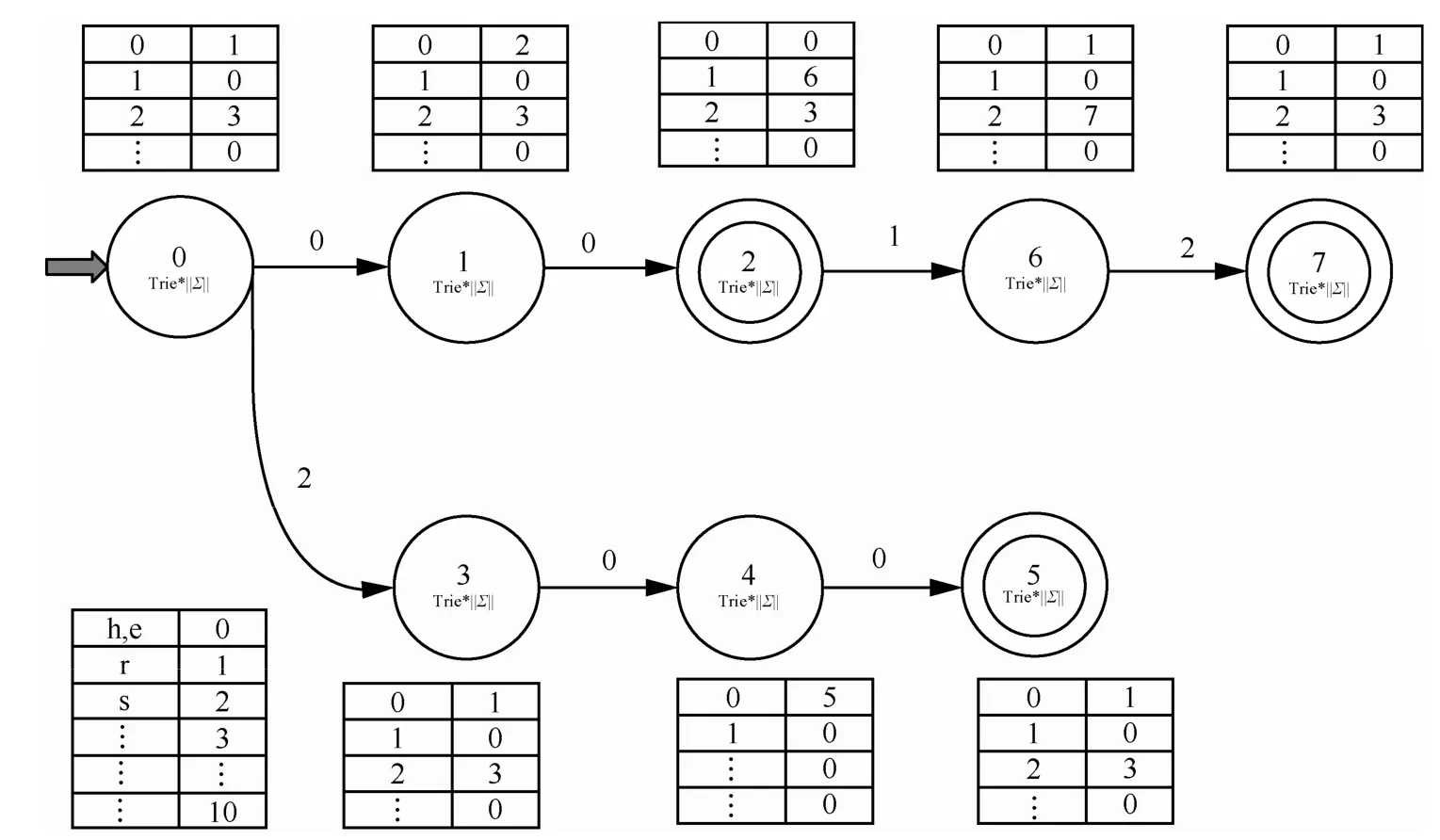
图5 模式串{he,hers,she}对应的FilterFA自动机
3) 预处理时间复杂度:在预处理阶段,需要将原字符集映射为较小字符集,通过字符集映射函数进行字符集变换仅需要O(1)的时间。其余处理流程和AC相同,构造FilterFA自动机所需时间为。因此,FilterFA算法预处理阶段的时间复杂度为。
4) 搜索时间复杂度:在搜索阶段,对于每个文本位置i,需要从当前位置开始搜索,查找所有可能出现的模式串。因此,FilterFA算法搜索阶段的平均时间复杂度为O(n)。
表2是FilterFA算法同经典的AC算法[2]、HashTrie算法[12]的空间和时间复杂度比较。

表2 FilterFA算法和AC算法、HashTrie算法复杂度对比
在存储空间方面,AC算法的空间开销主要用于存储状态转移的二维矩阵,算法空间复杂度与字符集大小σ成正比。FilterFA算法将原字符集压缩成较小的字符集,再以Trie树的结构存储,优于传统的AC算法。HashTrie算法采用位向量和散列表结合的方式存储模式串集和的信息,空间复杂度,优于AC和FilterFA算法。
在预处理时间方面,AC算法的预处理时间与模式串规模|P|和字符集大小σ相关;HashTrie算法预处理阶段的时间复杂度为,与字符集大小σ无关;FilterFA算法复杂度和HashTrie算法的预处理时间复杂度一致,仅与模式串规模|P|线性相关,与字符集大小σ无关,优于传统的AC算法。
在搜索时间方面,FilterFA算法和AC算法一致,只需将文本扫描一遍,查找所有的匹配位置即可,平均时间复杂度为O(n)。而HashTrie算法的最坏时间复杂度与最长模式串的长度lmax线性相关,高于AC算法和FilterFA算法。FilterFA算法在搜索阶段,要优于HashTrie算法。
综上,由理论分析可知,FilterFA算法不仅降低了自动机空间存储开销,同时,还保持了AC的线性搜索时间复杂度。
4 实验评估
本节通过在真实数据集和随机数据集上测试,从存储空间和匹配速度2个方面,将FilterFA算法和AC算法、HashTrie算法进行对比。此外,在2种数据集上对FilterFA算法的误识别率进行实验性分析,分别考察模式串规模、字符集规模同误识别率之间的关系。
实验硬件环境如下:CPU AMD Processor 8378 2.41 GHz,内存3.25 GB。
实验软件环境如下:Windows 7 32位,编译平台Microsoft Visual Studio 2010。
实验选取的测试数据集包括2部分:开源系统中提取的真实数据集和随机生成的数据集。其中,真实数据集包括MIT入侵检测数据集[19]、Snort规则集[1]、ClamAV规则集[20]、URL数据集[21]。随机数据集为系统随机生成的模式串集合和文本数据集。
ClamAV规则集+MIT入侵检测数据集:从开源反病毒系统ClamAV 0.90.1版本中抽取的部分精确模式串,作为待匹配的模式串集合。来自MIT公开的网络入侵检测数据集mit_1999_training_week1_ friday_inside.dat(约62.7 MB)作为待扫描文本,抽取其中一部分(约32.4 MB)作为训练数据集,剩余部分作为测试数据集。
Snort规则集+MIT入侵检测数据集:从开源入侵检测系统Snort2009.06中提取部分精确模式串,作为待匹配的模式串集合。同样将MIT数据集作为待扫描文本和训练数据集。
URL规则集+URL数据集:从网络骨干路由器流量中采集的约2 000万(2.60 GB)条URL规则。从中随机抽取25 000条长度大于4的URL作为待匹配模式串。抽取约2.3 GB作为待扫描文本,并从中抽取1.09 GB作为训练数据,剩余的URL为测试数据。
随机数据集:随机生成模式串集合和待扫描文本。模式串个数由1 000增加到1 000 000,模式串和文本中的字符服从等概率独立同分布,生成每个字符的概率为。
4.1 存储空间
算法的存储空间消耗与模式串的个数、长度和字符集大小等因素密切相关,由算法所采用的数据结构决定。
在存储空间方面,从图6中的实验结果可以看出,在随机数据集上,模式串规模从1 000增加到20 000。随着模式串规模的增大,AC算法的空间开销线性增长,FilterFA算法的空间开销变化幅度较小。当像字符集大小为8,且保证误识别率小于2%的条件下,FilterFA算法消耗的存储空间仅为AC算法的3%左右。FilterFA算法消耗的存储空间远低于AC算法,二者存储空间比仅为3%左右,这与理论分析值4%基本相符。

图6 在随机数据集上,FilterFA算法和AC算法的存储空间与模式串规模的关系(固定像字符集大小为10 )
将FilterFA算法和AC算法、HashTrie算法对比,在真实数据集ClamAV上进行测试,将最短模式串长度控制在8~22。从表3中的实验结果可以看出,HashTrie算法的存储空间最低,FilterFA算法的存储空间次之,但均优于AC算法。FilterFA算法与AC算法,二者存储空间比约3%,即FilterFA算法消耗的存储空间仅为AC算法的3%左右,与随机数据集上的测试结果一致。相较于AC算法和HashTrie算法,FilterFA算法存储空间高于HashTrie算法,但提供了一种不同于已有算法的新机制。将大字符集映射之后再构造自动机的策略,在节约内存空间开销上效果显著。通过对字符集的直接作用,很好地压缩了算法自动机的内存开销。
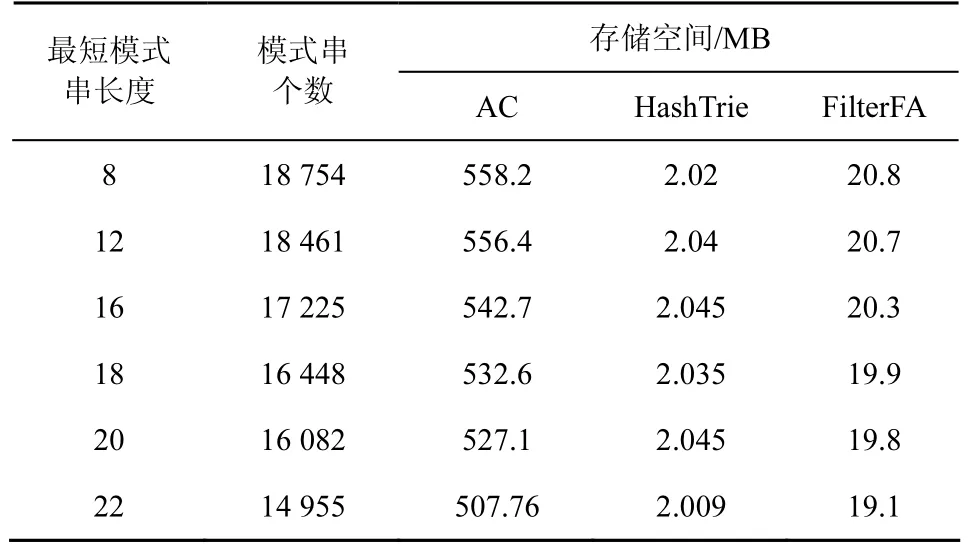
表3 FilterFA算法和AC算法、HashTrie算法的存储空间对比
4.2 匹配速度
在随机数据集上,固定像字符集大小为10,模式串规模从1 000变化到20 000。随着模式串规模的增大,2种算法的匹配速度均下降。在下降的过程中,FilterFA算法匹配速度仍快于AC算法,约为AC算法的1.4~2.2倍。实验结果如图7所示。
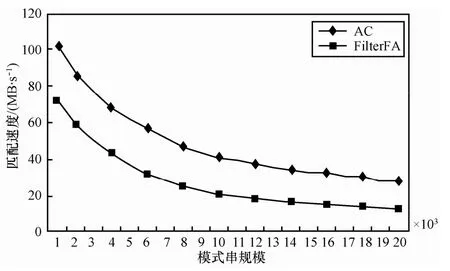
图7 在随机数据集上,FilterFA算法和AC算法的匹配速度对比(固定像字符集大小为10)
在真实数据集ClamAV上,固定新定义的字符集大小为8,保证误识别率不超过2%,将最短模式串长度控制在8到22变化,同样将FilterFA算法和AC算法、HashTrie算法进行对比测试。从表4中的实验结果可以看出,FilterFA算法的匹配速度略低于AC算法,略优于HashTrie算法。3种算法匹配速度基本维持在同一个数量级,与理论分析一致。这是因为在真实数据集上,字符并不一定完全服从等概率分布,对于某些概率分布偏差较大的数据,FilterFA算法造成的误识别率较大,从而使FilterFA算法在校验过程中,增加了校验工作量,整体相对损失了一部分性能。
4.3 误识别率
误识别率是由字符集映射函数的引入而产生的。字符集映射函数将字符集映射成一个较小的字符集,必然存在2个不同的字符映射为同一个字符的情况,使FilterFA自动机在匹配过程中,可能产生误识别。
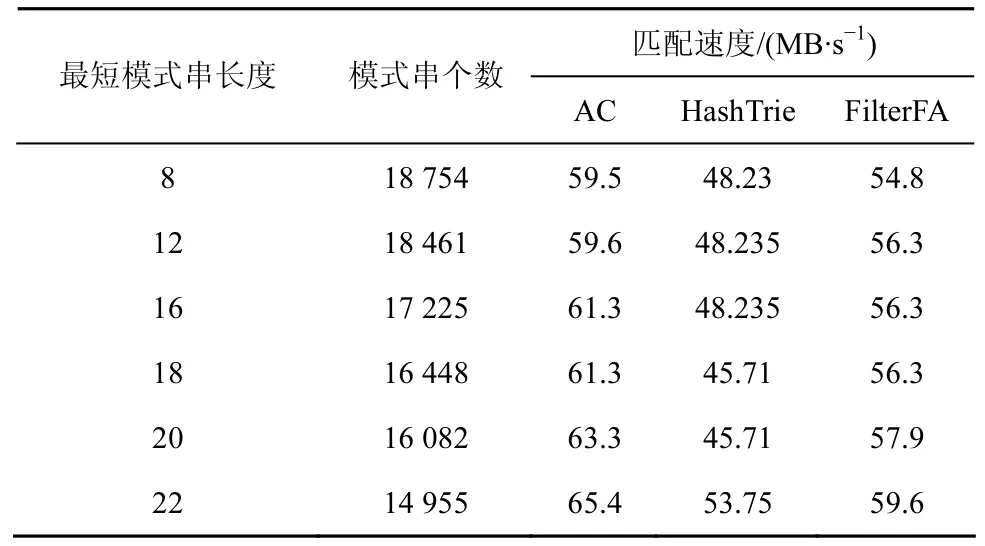
表4 FilterFA算法和AC算法、HashTrie算法的匹配速度对比
在真实数据集和随机数据集2种数据集上对FilterFA算法的误识别率进行实验性分析,考察模式串规模和误识别率之间的关系。
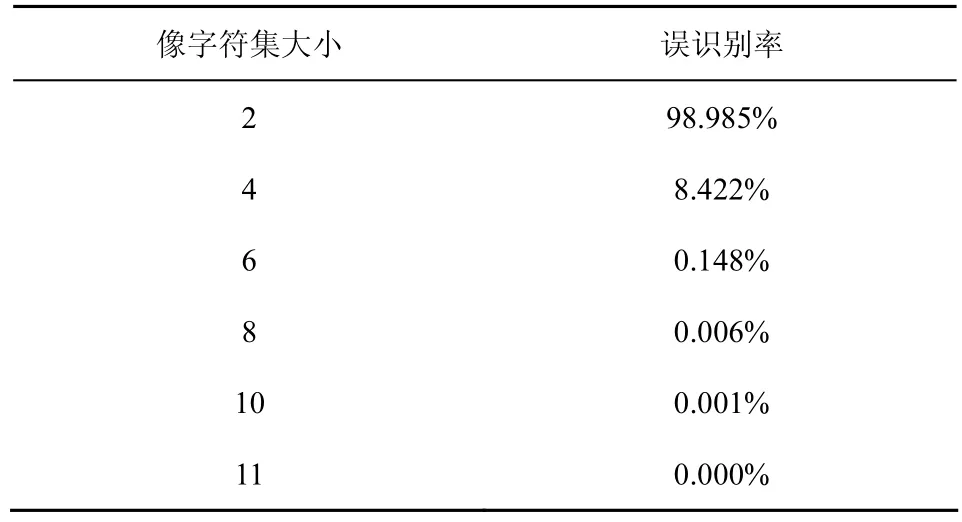
表5 FilterFA算法误识别率和像字符集规模大小的关系
在随机数据集上,所有字符等概率分布。选取随机取模为字符集映射函数,理论上由随机数据集取模得到的像字符集亦是等概率均匀分布的。由表5的测试结果可以看出,随着像字符集规模的增大,像字符集大小由2增大到11,误识别率逐渐减小。当像字符集大小为11时,误识别率趋于0。这也是解释了为何在之前的实验中,采用的是新定义的字符集大小为10时的字符集映射函数。和理论分析的结果一致,像字符集规模越大,将不同字符映射为同一字符的概率越小,误识别率越小。
表6是固定像字符集大小为10时,误识别率随模式串规模变化而变化的情况。当模式串规模不断增大时,误识别率随之增大。模式串规模由2 000逐渐增加至1 000,误识别率由0增加至0.005。增加幅度相当小,在6%之内,误识别率始终维持在合理的范围之内。
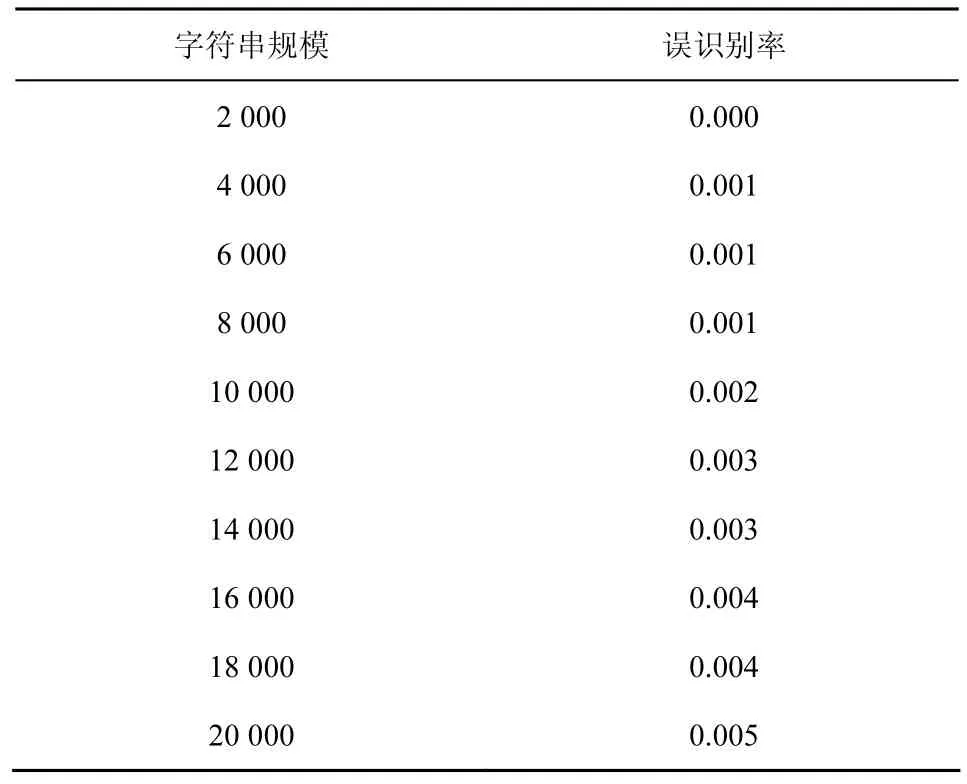
表6 FilterFA算法误识别率和像模式串规模大小的关系
此外,在3种真实数据集上,分别采用2种字符集映射函数对字符集进行变换,测试字符集映射函数对FilterFA自动机误识别率的影响。
映射函数一:随机取模函数(modN,N为任意小于σ的自然数);
映射函数二:依概率均匀分布得到的字符集映射函数,即由算法1中的算法得出的映射函数。
从表7可以看出,在所有测试的数据集上,随着字符集规模不断增大,数据集大小从6变化到20,2种映射函数下的FilterFA算法的误识别率均逐渐变小。在数据集规模较大时,真实数据集Snort和ClamAV上的测试结果表明,依概率均匀分布得到的字符集映射函数方法产生的误识别率远小于随机取模函数产生的误识别率。基于依概率均匀分布的字符集映射函数优于基于随机取模的字符集映射函数方法,这种优势在真实数据集ClamAV上,表现更为显著。在这2种数据集上,更适合采用基于依概率均匀分布的字符集映射函数。在URL数据集上,依概率均匀分布的方法产生的误识别率要高于随机取模方法产生的误识别率。当字符集规模较大时,两者差异显著。这可能是由URL数据集与依概率均匀分布方法字符间相互独立的假设前提相冲突导致的。因此,在URL数据集上,基于依概率均匀分布的字符集映射函数并不适合,需要进一步寻找更加适合、高效的字符集映射函数。

表7 随机取模函数与依概率均匀分布函数对FilterFA算法误识别率的影响对比
5 结束语
本文提出了一种基于基于字符集规约的模式串匹配算法——FilterFA算法。与经典的多模式串匹配算法AC算法相比,FilterFA算法大大减少了自动机存储空间消耗,同时保持了AC的线性搜索时间复杂度。与HashTrie算法相比,FilterFA算法空间复杂度高于前者,在搜索阶段优于前者。不同于HashTrie算法的递归散列机制,FilterFA算法从字符集出发,利用字符集映射函数,将原字符集压缩为多个像字符集,针对像字符集构造新的自动机FilterFA,将空间复杂度降至。在定义字符集映射函数时,给出一种基于字符概率均匀分布求解字符集映射函数的算法——基于字符独立假设,求解当像字符集服从等概率分布,且FilterFA误识别率最小的近似最优解。将FilterFA算法产生的误识别率控制在尽量不影响算法匹配速度的小概率范围内。
在随机数据集、Snort数据集和ClamAV数据集上,FilterFA算法均取得了较好的实验效果。在随机数据集和真实数据集ClamAV上的测试结果表明,当像字符集大小为8,且保证当误识别率小于2%时,FilterFA算法的存储空间远低于AC算法,FilterFA算法消耗的存储空间仅为AC算法的 3%左右。2种算法存储空间比约3%,同时2种算法的匹配速度相当。对于URL数据集来说,测试结果表明,基于依概率均匀分布的字符集映射函数并不适合。
依概率均匀分布方法中字符间相互独立的假设并不适用于所有的真实数据集,字符间相互独立的假设具有一定的局限性,研究字符间相互关系的情况下字符集映射函数的求解策略具有一定的现实意义。在规则和文本数据不同分布的情况下,字符间不相互独立的情况下,字符集映射函数又该如何设计。在下一步工作中,将研究更加普遍意义下的字符集映射函数求解方法以及更加高效的自动机压缩方法。
[1]Snort.Org [EB/OL].https:// www.snort.org/.
[2]BOYER R S,MOORE J S.A fast string searching algorithm [J].Communications of the ACM,1977,20(10):762-772.
[3]KHARBUTLI M,ALDWAIRI M,MUGHRABI A.Function and data parallelization of Wu-Manber pattern matching for intrusion detection systems[J].Network Protocols and Algorithms,2012,4(3):46-61.
[4]AHO A V,CORASICK M J.Efficient string matching:an aid to bibliographic search[J].Communications of the ACM,1975,18(6):333-340.
[5]NAVARRO G,RAFFINOT M.Flexible pattern matching in strings:practical on-line search algorithms for texts and biological sequences [M].Oxford City:Cambridge University Press,2002.
[6]BAEZA-YATES R A,GONNET G H.A new approach to text searching[C]//12th International Conference on Research and Development in Information Retrieval.1989:168-175.
[7]DENCKER P,DORRE K,HEUFT J.Optimization of parser tables for portable compilers[J].ACM Transactions on Programming Languages and Systems,1984,6(4):546-572.
[8]NORTON M.Optimizing pattern matching for intrusion detection[EB/OL].http://www.idsresearch.org,2004.
[9]TUCK N,SHERWOOD T,CALDER B,et al.Deterministic memory-efficient string matching algorithms for intrusion detection[C]// IEEE INFOCOM.2004.
[10]AHO V,SETHI R,ULLMAN J D.Compilers:principles,techniques,and tools[M].New Jersey:Addison-Wesley.1985.
[11]AOE J,MORIMOTO K,SATO T.An efficient implementation of trie structures[J].Software-Practice &Experience,1992,22(9):695-721.
[12]ZIEGLER S.Smaller faster table driven parser,unpublished manuscript[Z].Madison Academic Computing Center,1977.
[13]TARJAN R E,YAO A C.Storing a sparse table[J].Communications of the ACM,1979,22:606-611.
[14]FREDMAN M,KOML´OS J,SZEMER´EDI E.Storing a sparse table with O(1) worst case access time[J].Journal of the ACM,1984,31(3):538-544.
[15]杨毅夫,刘燕兵,刘萍,等.串匹配算法中的自动机紧缩存储技术[J].计算机工程,2009,35(21):39-41.YANG Y F,LIU Y B,LIU P,et al.Automation compact representation technology in string matching algorithm[J].Computer Engineering,2009,35(21):39-41.
[16]NIEVES R,LADRA B S.K2-trees for compact web graph representation[C]//String Processing and Information Retrieval Lecture Notes in Computer Science,2009,5721:18-30.
[17]NIEVES R,LADRA B.S.Compact representation of web graphs with extended functionality[J].Information Systems,2014,39(1):152-174.
[18]张萍,刘燕兵,于静,等.HashTrie:一种空间高效的多模式串匹配算法[J].通信学报,2015,36(10):172-180.ZHANG P,LIU Y B,YU J,et al.HashTrie:a space-efficient multiple string matching algorithm[J].Journal on Communication,2015,36(10):172-180.
[19]Available online[EB/OL].http://www.ll.mit.edu/IST/ideval/.
[20]Available online[EB/OL].http://www.clamav.org/.
[21]Available online[EB/OL].http://urlblacklist.com/.

张萍(1987-),女,河南唐河人,中国科学院信息工程研究所博士生,主要研究方向为网络与信息安全、内容过滤等。

何慧敏(1987-),女,山东菏泽人,中国移动(深圳)有限公司工程师,主要研究方向为串匹配算法。
张春燕(1989-),女,河北衡水人,中国科学院信息工程研究所实习研究员,主要研究方向为信息内容安全和高性能计算。
曹聪(1987-),男,山东枣庄人,博士,中国科学院信息工程研究所助理研究员,主要研究方向为数据挖掘、文本抽取、常识知识获取。
刘燕兵(1981-),男,湖北麻城人,博士,中国科学院信息工程研究所副研究员,主要研究方向为文本算法设计、图数据管理与挖掘、网络流识别与处理等。
谭建龙(1974-),男,湖南长沙人,博士,中国科学院信息工程研究所研究员、博士生导师,主要研究方向为网络数据流管理、算法设计、海量正则表达式匹配、图像匹配算法等。
FilterFA:a multiple string matching algorithm based on specification of character set
ZHANG Ping1,2,3,HE Hui-min4,ZHANG Chun-yan1,3,CAO Cong1,3,LIU Yan-bing1,3,TAN Jian-long1,3
(1.Institute of Information Engineering,Chinese Academy of Sciences,Beijing 100093,China;2.University of Chinese Academy of Sciences,Beijing 100049,China;3.National Engineering Laboratory for Information Security Technologies,Beijing 100093,China;4.China Mobile (Shenzhen) Co.,Ltd.,Shenzhen 518031,China)
Multiple string matching is one of the core techniques of intrusion detection system,where Aho-Corasick algorithm is widely used.To solve the problem that huge storage overhead of AC would influence performance deeply,an improved algorithm ——FilterFA,based on specification of character set was proposed.This algorithm compressed large character by the character set mapping function,and constructed a new automata based on the mapped character set,then space complexity decreased to.Experiments on synthetic datasets and real-world datasets (such as ClamAV) show that the storage overhead of FilterFA is only about 3% of that of AC,while the size of the character set is 8,and the false recognition rate is less than 2%.
intrusion detection,multiple string matching,specification of character set,character set mapping
s:The Strategic Priority Research Program of the Chinese Academy of Sciences (No.XDA06031000),Xinjiang Uygur Autonomous Region Science and Technology Project(No.201230123)
TN925
A
10.11959/j.issn.1000-436x.2016277
2016-08-11;
2016-10-11
张萍,zhangping@iie.ac.cn
中国科学院战略性科技先导专项基金资助项目(No.XDA06031000);新疆自治区科技专项基金资助项目(No.201230123)
猜你喜欢
计算机工程与科学(2022年2期)2022-03-22
智能计算机与应用(2021年6期)2021-12-17
数学物理学报(2021年3期)2021-07-19
综艺报(2020年21期)2020-11-30
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电脑爱好者(2019年17期)2019-10-30
智富时代(2019年4期)2019-06-01
