
基于GMM-HMM和深层循环神经网络的复杂噪声环境下的语音识别
2016-07-09 06:30刘旺玉SHIRAISHIHIROSHI
制造业自动化 2016年5期
刘旺玉,SHIRAISHI HIROSHI
(华南理工大学 机械与汽车工程学院,广州 510640)
基于GMM-HMM和深层循环神经网络的复杂噪声环境下的语音识别
刘旺玉,SHIRAISHI HIROSHI
(华南理工大学机械与汽车工程学院,广州 510640)
摘 要:探索了工厂实时环境下控制平台使用语音输入代替键盘输入的一种新型语音识别算法。目前,在无噪声情况下,语音识别已经获得了很好的效果。但一旦考虑实时环境下的噪声,它的识别精度会大幅下降。本文结合混合高斯分布的隐马尔科夫模型与深层循环神经网络模型提出了一种新型语音识别混合模型,可以有效去除工厂复杂环境下的噪音干扰,提高语音识别的有效性。实验结果表明,此方法在噪声环境下具有良好的适应性能。
关键词:隐马尔科夫模型;深层循环神经网络;抗噪;混合模型;MATLAB
0 引言
工厂自动化技术诞生于20世纪40年代。迄今为止,随着计算机技术,无线通讯技术,现场总线技术,工业以太网技术,信息技术,机器人技术,传感器技术以及安全技术等科学技术的不断发展与创新,在经历了单机自动化,车间自动化,中央集中控制等几个重要阶段之后,工厂自动化正向工厂综合自动化发展[1]。但现阶段,键盘操作依然使用手控而不是声控。虽然个人电脑和移动终端已能部分实现声音输入与识别,但工厂实时环境下的噪声十分复杂,会严重影响到控制系统的语音识别[2]。因此,如何消除工厂噪音,在人机交互控制系统中实现敏捷的语音识别,是实现工厂自动化需要解决的关键问题之一。
抗噪语音识别技术可以分为两种。一种是适应在噪声环境下的语音适应性模型,第二种是从输入信号中除去噪声成分的去噪模型[3]。前者有并行模型结合处理算法(PMC),矢量泰勒级数法(VTS)等适应算法。语音适应性方法可以获得较高的精度,但是计算量大[4]。本文重点讨论去噪模型,实现带噪语音识别。
去噪模型也可以分为两种:一种是在能量谱领域中除去噪声的方法,另一种是通过语音特征量除去噪声的方法。前者有减谱法(SS),维纳滤波等方法,但该方法去噪后频率偏差大[5]。后者有SPLICE(Stereo Piecewise Linear Compensation for Environments),DAE (Denoising Auto Encoder)等方法,该类方法需要提前学习纯语音特征量的信息表达,然后实现适合语音特征的噪声去除[6, 7]。
近年来出现了一种新的语音识别算法,即DAE的复杂噪音去除模型RDAE(Recurrent Denoising Auto Encoder)[8]。该方法解决了语音识别中前后连续性问题。但这个模型中依然存在过度学习的问题。为了避免识别效率下降,本文提出深层循环神经网络结合高斯混合模型和隐马尔科夫模型的混合模型,可提高语音识别效果。在本文中,利用深层循环神经网络的自适应能力以及隐马尔科夫模型的良好的动态建模能力,结合高斯混合模型的鲁棒性来合成,提出混合高斯分布的隐马尔科夫模型与深层循环神经网络的混合模型,实现噪声环境下的语音识别。
本文先介绍循环神经网络及其深层学习特点,然后提出与高斯混合分布相结合的隐马尔科夫模型的混合模型合成方法,最后通过实验方法验证本文结果。
1 深层循环神经网络
深层神经网络基于上世纪50年代出现的人工神经网络,其特点是自学习和自适应性、非线性、鲁棒性和容错性、计算平行性和存储分布性。但它占用计算机的存储空间大。当数据量不足时,造成推理依据不足,无法解释自己的推理过程,甚至运算无法进行。上世纪90年代后期人工神经网络研究领域开始凋谢,隐马尔科夫模型取代了神经网络在语音识别上的地位[9]。直到2006年出现了深层神经网络。深层神经网络可以逼近人的思维,可包含多个隐藏层的神经网络[10, 11]。
1.1循环神经网络
由于声音是时间序列,其过去的状态会直接影响到将来的状态,因此循环神经网络是一种动态神经网络。通常,普通神经网络模型没有考虑时间维度,所以使用循环神经网络更适合于处理语音信号。在本文中循环神经网络的功能是使带噪语音接近纯语音[12]。

式(1)中,V是跟偏差向量c有关的权重矩阵。表示隐藏层的函数是h(1),它是非线性函数,其函数是以下式:

W是与偏差向量b(1)有关的权重矩阵。激活函数σ()在实验中使用Tanh-Sigmoid[13]。

训练网络后取最小误差。
因为输入值x的长度不一样,输入维度会很高,所以输入时采用多个输入框,以提高计算效率。为了解决前后输入框的独立性,把式(2)改成式(4)。

t表示时间,xt为当前的输入框,xt-1为前一个输入框,U为权重矩阵,输入框在时间序列上连续。其循环过程如图1所示。
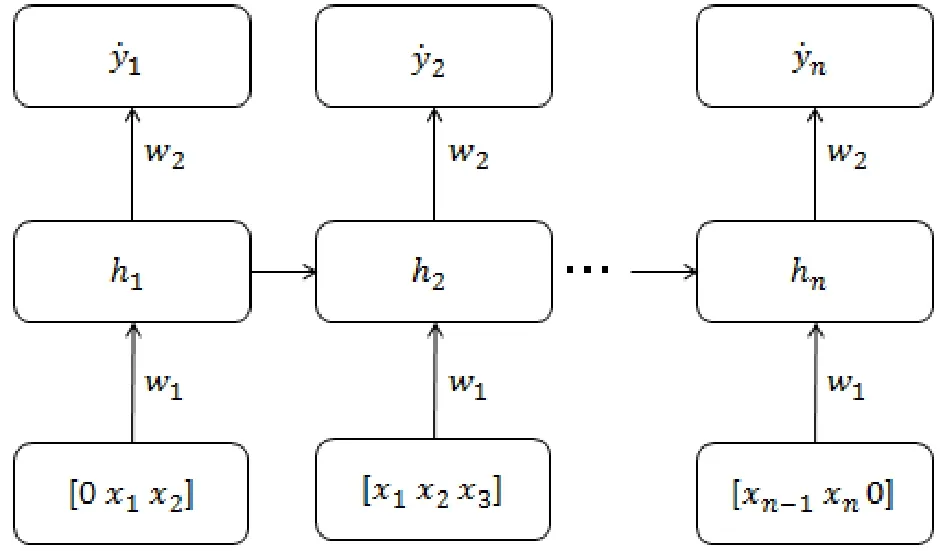
图1 循环神经网络循环过程
1.2深层循环神经网络结构
虽然循环神经网络是非线性的,但该模型不能足够接近噪声环境下的复杂信号。在本研究中拟引入更多非线性的隐藏层。我们称引入更多循环过程的神经网络模型为深层循环神经网络,是一种比单层隐藏层多的多隐藏层模型。深层循环神经网络的循环过程如图2所示。

图2 深层循环神经网络过程
在图中,i表示多层神经网络中网络的隐藏层的层数。例如i=1时候,隐藏层h就是h(1),表示第一层的隐藏层。深层神经网络的隐藏层大于1。

所以式(4)改为:从式(5)中可以看出,隐藏层h(i)与权重矩阵W(i),偏差向量b(i)之前的隐藏层的输出值h(i-1)(xt)有关。如使用深层循环神经网络模型时,式(5)可改写为:

2 混合模型
混合模型的去噪步骤包含两个重要部分:首先把带噪语音处理为接近纯语音的信号,然后对近纯语音进行识别。去噪步骤使用深层循环神经网络,需要确定隐马尔科夫模型的维数(或特征值的维数),为了防止过拟合,确定是否用随机退出技术(drop out),另外,需要确定输入框数,权重,隐藏层单元个数,隐藏层的层数,σ的激活函数,网络的初始值,训练的迭代次数等量值。一般地,输入深层神经网络的特征值维数和输入隐马尔科夫模型的维数设定是一样的。Drop out是每次训练开始时随机地删除一半的隐层单元,即每次训练的网络不一样。最后测试时所有的节点都用上[14]。为了前后连续,输入框数为奇数。例如n为当前的框时,n-1为之前状态,n+1为之后状态。所以至少需要3个输入框。隐层单元个数由语音样本及特征值的维数来决定。虽然它的值越大越能得到更好的效果,但计算量多,训练速度也降低。隐藏层越多,效果也越好,但导致计算量多,训练速度降低。σ的激活函数可以从以下函数中选择,logistic-sigmoid,tanh-sigmoid,ReLu(Rectified Linear Units)。Logistic函数[13]为:

tanh函数为:

ReLu函数[15]为:

网络的初始值从zeros(矩阵都是零),ones(矩阵都是一),rand(随机地从0到1之内选矩阵的值)选择。训练的迭代次数越多效果越好,但计算量增加。
我们可以在网络中训练多个带噪语音,但训练语音越多计算量也越大。所以在不同类型的噪声环境下,重新让网络训练模型生成新模型。这样就可以减少计算量,而且不会出现平台停机的问题。
在已知噪声的环境下,增加网络的层数,去噪效果会更好。但在未知噪声的环境下,加多隐藏层并不能从带噪语音下完全去掉噪声,因为存在网络过度学习的问题[16]。使用高斯混合分布的隐马尔科夫模型可以有效解决此类问题,它具有强大的动态性,容错性和鲁棒性。由于它有分类归并的功能,对于轻微噪声环境下不同个体的语音也可以获得较好的识别结果。所谓高斯混合模型就是指对样本的概率密度分布进行估计,而估计的新模型是几个高斯模型加权之和。每个高斯模型就代表了一个类。高斯混合模型是从几个单高斯分布模型中产生出来的,定义为:

其中K是模型个数。第k个高斯的概率密度函数中μk为均值,σk为方差。对概率密度的估计就是对每个变量求和。每个求和结果就分别代表样本x属于第k个高斯的概率。K需要先确定。如果K取得很大,模型就会变得很复杂,但可以用来逼近任意连续的概率密度分布。正是因为高斯函数具有良好的计算性能,所以高斯混合模型应用广泛。
在隐马尔科夫模型的状态中,每个状态都有一个高斯混合模型,包括K个高斯模型参数。只要知道这些参数,就可以在识别时计算出一串状态转移的概率。
在噪声环境下使用隐马尔科夫模型时,它的识别率会大大降低。所以在本文中使用深层循环神经网络与混合高斯隐马尔科夫模型相结合的混合模型。获得噪音环境下的语音特征值后,先通过深层循环神经网络使特征值接近纯语音。深层循环神经网络输出的特征值输入到混合高斯分布的隐马尔科夫模型里,得到最终识别结果。混合模型的结构图如下。

图3 混合模型的结构
首先把带噪语音特征值(noise speech)和纯语音特征值(test speech)输入到深层神经网络中训练网络的权值、偏差等参数。然后在神经网络模型里输入noise speech,这样可以得到接近test speech的特征值predict speech。
在混合高斯分布的隐马尔科夫模型里先训练纯语音的特征值(train speech)。模型训练后输入predict speech,最终得到识别结果。
3 实验
3.1实验方法
本论文中使用的训练语音数据样本为:男性38人,女性57人。在识别语音样本中男性56人,女性57人的语音样本。在训练语音和识别语音中使用不同人的声音。在训练语音中共有2090个单词,识别语音中有2486个单词,总共4576个单词。在实验中使用在噪音环境下分别给出四种不同噪音强度0dB,5dB,10dB,20dB。噪音来自机加工车间,含车削加工、磨削加工、焊接加工等三种噪音。使用语音合成法把每个噪音和强度调整后跟识别语音合成起来,共有32318个识别语音数据。从语音数据中使用MFCC取出特征值。提取特征值前,先通过预加重,分帧,加窗处理。在实验中分帧的帧长为25毫秒,帧长重复部分为10毫秒。加窗处理使用汉明窗。提取MFCC为12阶,并提取它的一阶差分系数和二阶差分系数。每个系数取能量谱,总共取39阶的特征值。在高斯混合模型中使用11个模型,训练迭代次数为10次。隐马尔科夫模型是无跨越的从左向右模型,它的状态数为10个,训练迭代次数为10次。深层循环神经网络的层数为5个,其中隐藏层为3个,隐藏层的第二层定为循环神经网络。输入框为3个,隐层单元为500个,训练迭代次数为2000次。使用不同强度0dB,5dB,10dB,20dB 等4种模式,共有3种不同的噪音环境A,B,C。先采用神经网络优化,然后通过混合高斯隐马尔科夫模型识别。其过程在MATLAB系统中运行。
3.2实验结果
在实验中使用的语音波形及它的噪声环境中的语音波形如图4所示。

图4 在不同的信噪比条件下男性说“one”的语音波形
SNR是信噪比。从图4中可以看到它的值越大信号也越清楚。所以0dB时识别率是最低。图4中的数据长度为3360。分帧,加窗处理后可以分到40个数据。然后使用MFCC提取特征值。它的数据如图5所示。

图5 在不同的信噪比条件下男性说“one”的特征值
从图5中可以看到从0到15的区间变化很大。有明显的噪声干扰。我们与使用深层循环神经网络去噪后的特征值进行对比。去噪后的特征值如图6所示。

图6 去噪后的特征值
从图6中可以看到带噪的特征值逼近纯语音的特征值。虽然还有微小的差别,但使用高斯混合分布的隐马尔科夫模型可以获得较高的精度。
为了比较混合模型的优点,在实验时,用混合高斯分布的隐马尔科夫模型(GMM-HMM)、隐藏层是单层的循环神经网络(RNN-GMM-HMM)、不循环的深层神经网络(DNN-GMM-HMM)进行比较。实验结果如表1所示。

表1 隐马尔科夫模型与混合模型的识别率
A是车削加工的噪音。B是磨削加工的噪音。C是焊接加工的噪音。GMM-HMM是隐马尔科夫模型。DRNN-GMM-HMM是深层循环神经网络与混合高斯分布的隐马尔科夫混合模型。从表中也可以看出:识别纯语音的时候,隐马尔科夫模型和混合模型都超过99%.但是一旦带上噪音时,隐马尔科夫模型的识别率开始大大降低,0dB时已经低于50%,在噪声环境C中降低到21%。然而,在混合模型中虽然识别率也降低,但是大大高于隐马尔可夫模型。到了0dB时它的识别率仍达到90%左右,是隐马尔科夫的2倍以上。
4 结论
本文探索了在工厂实时噪音背景中如何进行语音识别的解决方案。通过使用深层循环神经网络,把带噪语音处理到接近纯语音,然后通过混合高斯分布的隐马尔可夫模型进行语音识别,可以获得较高的识别精度。通过理论分析和实验验证,证明了该方法具有明显的优点。本文研究结果对于在工厂实时噪音环境下高效、敏捷实现语音控制的人机交互控制系统的实现提供了一种解决途径。
参考文献:
[1] 自动化在线.探求工厂自动化技术的发展史[EB/OL].(2012-06-08)[2015-09-15].http://ww.autooo.net/classid119-id95581.html.
[2] 糟谷敏宏,村上憲也.音声認識における背景雑音の影響[J].全国大会講演論文集,1991,42(2):116-117.
[3] Cui X, Afify M, Gao Y,et al.Stereo hidden Markov modeling for noise robust speech recognition[J].Computer Speech & Language,2013,27(2):407-419.
[4] 山口耕市, 森尾智一,赤羽俊夫,等.コンパクトな単語音声認識,テキスト音声合成 (特集: ユーザインタフェース)[J]. シャ-プ技報, 2000 (77): 26-32.
[5] 松本弘.雑音環境下の音声認識手法[J].情報科学技術フォーラム FIT2003,2003.
[6] Stouten V,Wambacq P.Model-based feature enhancement with uncertainty decoding for noise robust ASR[J].Speech communication,2006,48(11):1502-1514.
[7] Bengio Y, Yao L,Alain G,et al.Generalized denoising autoencoders as generative models[A].Advances in Neural Information Processing Systems[C].2013:899-907.
[8] Maas A L, Le Q V,O'Neil T M, et al. Recurrent Neural Networks for Noise Reduction in Robust ASR[A].INTERSPEECH[C].2012.
[9] 清水亮.ディープラーニングはビジネスにどう使えるか? [EB/OL].(2015-05-20)[2015-09-20]. https://wirelesswire. jp/2015/05/30505.
[10] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J].Science,2006,313(5786):504-507.
[11] Hinton G E,Osindero S, Teh Y W.A fast learning algorithm for deep belief nets[J].Neural computation,2006,18(7):1527-1554.
[12] Vincent P, Larochelle H, Bengio Y,et al. Extracting and composing robust features with denoising autoencoders[A]. Proceedings of the 25th international conference on Machine learning.ACM[C].2008:1096-1103.
[13] 史峰,王小川,郁磊,等.MATLAB 神经网络30个案例分析[M].北京:北京航空航天大学出版社,2010.
[14] Srivastava N, Hinton G, Krizhevsky A,et al. Dropout:A simple way to prevent neural networks from overfitting[J].The Journal of Machine Learning Research,2014,15(1):1929-1958.
[15] Nair V,Hinton G E. Rectified linear units improve restricted boltzmann machines[A].Proceedings of the 27th International Conference on Machine Learning(ICML-10)[C].2010:807-814.
[16] 柏木陽佑,齋藤大輔,峯松信明,等.Deep Learningに基づくクリーン音声状態識別による雑音環境下音声認識[J].日本音響学会講演論文集,2013:1-8-3.
Speech recognition in complex noise environment based on GMM-HMM and deep recurrent neural network
LIU Wang-yu, SHIRAISHI HIROSHI
中图分类号:TN912.34;TH18
文献标识码:A
文章编号:1009-0134(2016)05-0142-05
收稿日期:2016-01-26
基金项目:国家自然科学基金资助项目(51375178)
作者简介:刘旺玉(1966 -),女,陕西西安人,教授,博士,研究方向为现代加工方法与结构优化设计。
