
考虑标记间依赖关系的多标记分类算法
2016-08-09 03:41孙艳歌李艳灵
信阳师范学院学报(自然科学版) 2016年2期
孙艳歌 , 邵 罕 , 李艳灵
(1. 信阳师范学院 计算机与信息技术学院,河南 信阳 464000;2. 北京交通大学 计算机与信息技术学院,北京 100044)
0 引言
传统的分类学习都假设数据只有一个类标,然而在实际应用中,一个实例却往往可能同时属于多个类别.例如,一部电影可能同时属于动作片、犯罪片和惊悚片;一篇新闻报道可能同时属于国内新闻、政治新闻和经济新闻;一个场景可能同时属于日出场景和海滨场景等.在这些情况下,每个实例都对应由多个标记组成的标记集,针对这种实例的分类称为多标记学习.多标记学习目前是机器学习和数据挖掘领域研究的热点之一,其研究成果广泛地应用于如文本分类[1]、图像视频的语义标注[2]、功能基因组[3]、音乐情感分类[4]等领域.
目前,研究者提出了众多多标记分类算法,文献[5]将标记分类算法分为两类:问题转化方法和算法适应方法.前者是将多标记分类问题转化为单个或者多个单标记分类问题.而后者则是对现有的单标记学习算法进行扩展,使其能直接处理多标记数据.
近年来,如何有效地利用标记间的依赖关系中所蕴含的信息以提高分类性能,已成为多标记学习中的一个研究热点.标记之间依赖关系中往往包含潜在有用的信息,如在场景分类中,海滨场景一般也属于室外场景,而政治新闻却不太可能属于娱乐新闻等,利用这些潜在信息将有助于提高分类器的性能.因此,本文在分析总结已有研究的基础上,重点研究如何描述与利用标记间的依赖关系以取得更好的分类效果,提出了一种考虑标记间依赖关系的多标记分类算法.
1 相关工作
1.1 多标记学习模型描述
从概率的角度来看,多标记学习可看作是一个求多个标记的联合条件概率p(y|x)的问题,其中,y为0/1组成的标记向量.对于实例x预测的最优标记向量y*为使联合概率获得最大的向量,即:
(1)
用Parent(yk)表示标记yk所依赖的标记集合,则求p(y|x)可以转化为如式(2)所示的形式来求解.
(2)
由式(2)可看出,求x的标记向量的关键是如何找出标记所依赖的标记集,以尽可能准确地计算标记向量概率.
1.2 多标记分类算法
传统单标记分类算法无法直接应用到多标记分类的问题中.近年来已经提出许多解决多标记分类问题的方法,主要分为两大类:算法适应和问题转化.
通过将已有的机器学习算法经过调整、扩展或定制以适应多标记分类的任务而形成多标记方法,统称为算法适应型方法.CLARE等[2]修改了C4.5算法的信息熵的计算公式,提出了适应于多标记数据的ML-C4.5算法.ZHANG等[6]提出的使用于多标记的懒惰式算法ML-kNN算法.SCHAPIRE等[1]提出AdaBoost.MH和AdaBoost.MR两种扩展于Boosting的多标记方法.BP-MLL则是通过修改流行的反向传播算法来适应多标记数据的一种算法[7].
目前常用的问题转化算法主要两种:二值相关算法(Binary Relevance, BR)和标记幂集合算法(Label PowerSet, LP).BR方法将多标记问题转换成多个二值分类问题.并假设标记间彼此独立,并未考虑标记间的依赖关系.为此,READ等[8]提出了分类器链算法(Classifier Chain,CC),将标记随机排序形成一个链,在对每个标记分类时都考虑在链中其之前所有标记的信息.SUCAR等[9]提出了基于贝叶斯网络的改进型分类器链算法,通过建立贝叶斯网络来寻找到分类器链的适当顺序,从而达到优化的目的.LP方法将实例的标记集看作一个新标记,从而潜在地利用了标记间的依赖关系,但标记个数呈指数级增长.TSOUMAKAS等[10]提出了随机标记子集算法(Randomk-Labelsets,RAkEL),在考虑了标记间依赖关系的同时,又避免了基本LP方法的标记数过多的问题.
2 考虑标记间依赖关系的多标记分类算法
2.1 问题的提出
DEMBCYNSKI等[11]提出了概率分类器链(Probabilistic Classifier Chains, PCC)算法,从最小化损失和贝叶斯最优估计角度来解释多标记问题.概率分类器链与分类器链算法类似,也对标记排序,并把每个标记前的所有标记当作其依赖标记.对于给定实例x,它的每一种标记组合y=(y1,…,ym)的概率可以由概率的乘法定则得出.
(3)
由于PCC算法需要求2m个不同标记取值的联合概率,并将概率值最大的标记集合赋予实例.由于遍历了所有可能的标记集,概率分类器链从理论上能够找到全局最优解,然而训练速度会随着标记个数呈指数级增长,时间复杂度过高.因此,PCC算法只能应用于标记数较小的数据上.
RAkEL算法利用集成学习技术训练多个分类器.每次训练都从原标记集合中随机抽取大小为k的标记子集并生成新的训练集合,集合中每个实例的新标记集为其原始标记集与这k个标记形成集合的交集.然后利用基本的LP方法对该子集训练分类器.由于每次学习时的标记数仅为k个,所以RAkEL方法在考虑了标记间依赖关系的同时,又避免了基本LP方法的标记数过多的问题.然而,采用了随机抽取的方法即假定了标记间存在随机的依赖关系,并未根据标记之间的依赖关系程度来确定各标记的依赖标记集.
2.2 考虑标记间依赖关系的多标记分类算法
尽管在过去的研究中,对多标记学习研究已经取得了一系列的进展,但针对多标记学习中依赖关系的描述与利用等问题的研究工作开展并不久,仍面临诸多挑战.根据上述分析,可将这两种算法融合起来,这样不仅充分利用PCC算法考虑标记间依赖关系的优点,又采用RAkEL算法对标记进行分组从而提高算法的性能.
算法首先利用RAkEL算法来划分若干个标记子集,然后在各个子集上通过PCC算法发现标记间的依赖关系.具体算法过程为:对于一个多标记数据,首先选取一个k值,将标记集合分为大小为k的若干个标记子集,然后在每个标记子集内部运用概率分类器链算法构建分类器,最后得出最终分类结果.算法中分类器训练伪代码如下:
输入:训练集D,大小为M的标记集L,标记子集大小k;
输出:新标记集个数m,大小为k的新标记集Ri,相应的LP分类器hi;
1:m=[M/k],i=1,j=1;
2: 设Ri为空集;
3: 若j小于等于k,则从L中随机选取标记λj,设Ri=Ri∪{λj},L=L{λj},i++,若L为空,则到步骤4;若j大于k,则返回步骤2;
4: 基于数据集D和标记集Ri利用PCC算法训练分类器hi,i++.若i≤m,则返回步骤2;若i>m,则结束.
算法的分类如下:
输入:新标记集个数m,新实例x,大小为k的标记集Ri,相应的LP分类器hi;
输出:多标记分类结果的向量表示Result;
i从1到m循环,对于每一个λj∈Ri,Result=hi(x,λj).
3 实验评价
实验是在CPU为2.8 GHz,内存为8 GB,操作系统为Windows 7的PC机上进行的,所有算法均在mulan平台下实现.Mulan[12]是一个用于多标记数据学习的JAVA开源库.
3.1 数据集描述
选用5个数据集用于实验,具体统计信息描述如表1所示.数据集及其描述可在mulan站点上获取(http://mulan.sourceforge.net/).
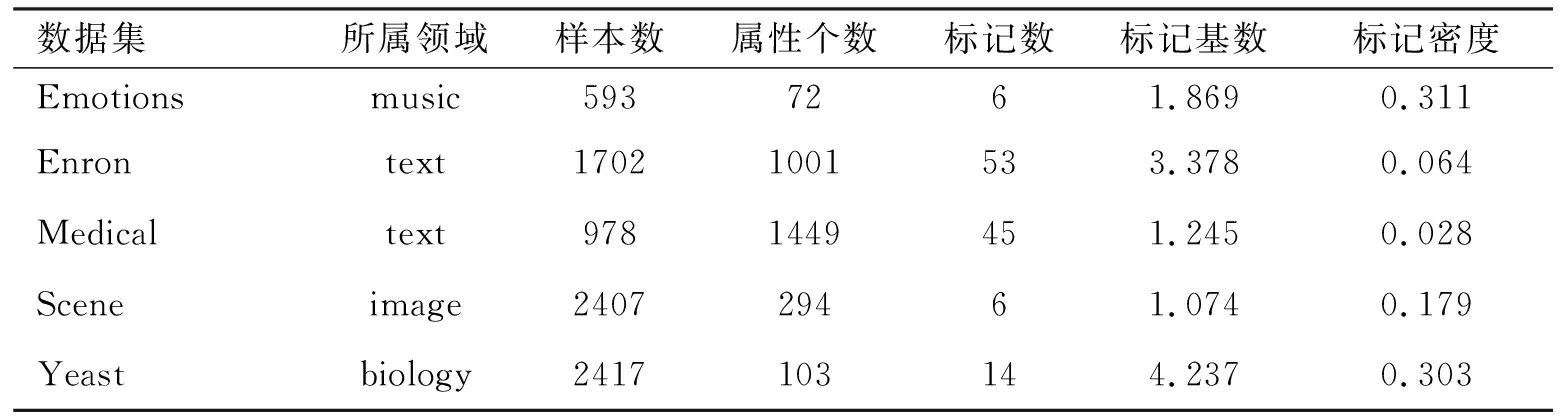
表1 数据集合描述Tab. 1 Characteristic of datasets
3.2 评价标准
为了便于给出各评价标准的数学定义,首先给出将要用到的数学符号.设
D= { (x1,C1), (x2,C2), …, (xn,Cn)},
为测试实例集,其中xi表示第i个实例,Ci表示xi对应的真实标记集合.给定一个分类器h和测试实例xi,Yi表示分类器h对其预测标记集合.
采用如下评价指标来度量多标记算法的性能:
(1) 汉明损失(Hamming loss):用于考察样本在单个概念类上的误分类情况,其定义如式(4)所示.
(4)
(2) 准确率(Accuracy):用于统计每个真实标记集与预测标记集的交集大小与真实标记集与预测标记集的并集大小的比,并求均值.其定义如式(5)所示.
(5)
(3) F1测度(F1 measure):是查准率和查全率的综合指标,其定义如式(6)所示.
(6)
3.3 与其他算法进行比较
与本文算法比对的算法包括:BR算法、CC算法、PCC算法和RAkEL算法.在上述5个数据集上对比了本文所提出的算法和各相应的比对算法,并统计了各算法在上述3种评价标准下5次10重交叉验证所得数据的均值的实验结果,如表2至表4所示.加“*”号表示相应的算法在当前的平均标准和数据集上表现最好.
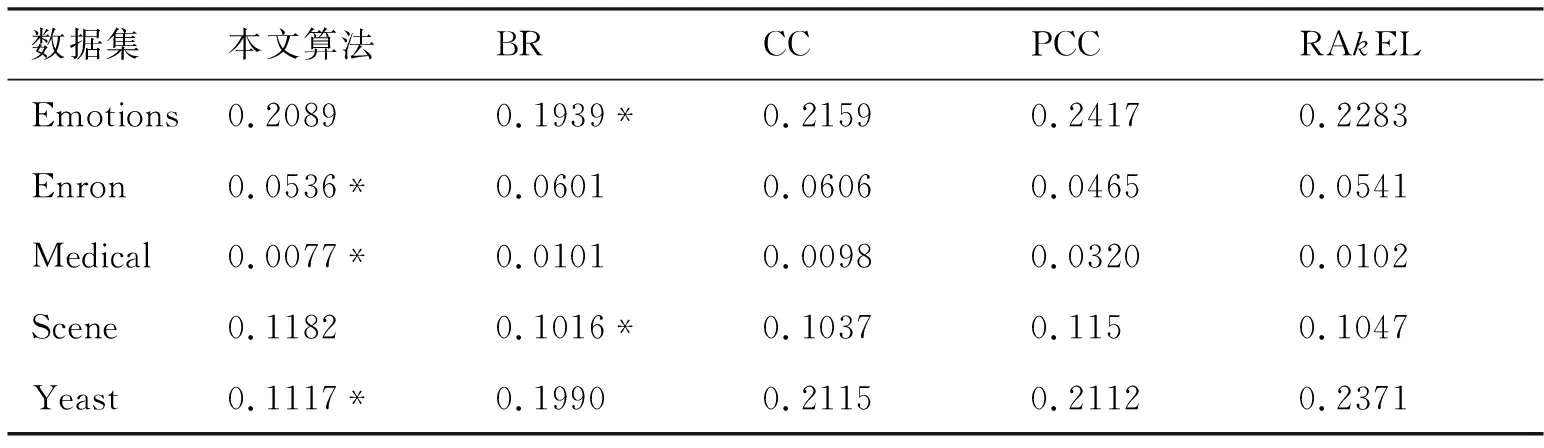
表2 不同算法的汉明损失
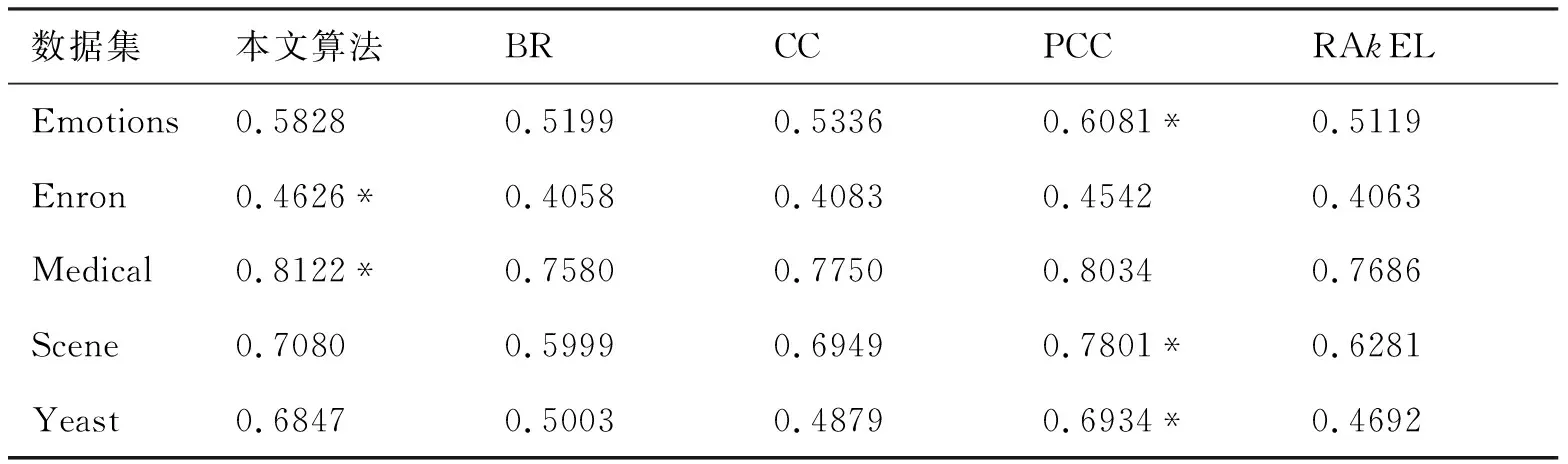
表3 不同算法的准确率
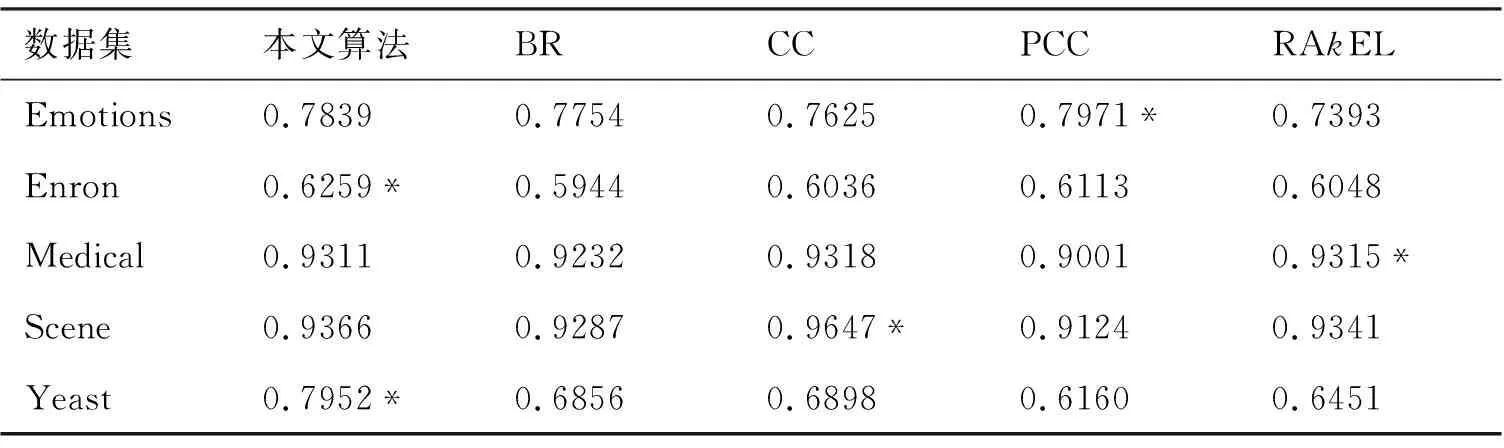
表4 不同算法的F1测度
表2~表4给出了本文算法与其他算法在5个数据集上的汉明损失、分类准确率和F1测度上的对比情况.通过比较分析,发现本文算法在标记数目比较大的数据集Enron、Medical和Yeast上具有明显的优势,而在标记数较小的数据集Emotions和Scene上表现并不具有明显优势,这是由于过分强调标记间的依赖关系反而可能降低算法的性能.总之,实验结果表明,本文所提出的算法较之分类器链和其他对比算法,能够更为有效地利用标记间的依赖关系,从而能够更为准确地预测实例是否属于某一标记,尤其适用于标记数目较大的数据集.
4 结论
本文重点研究如何有效地利用标记间的依赖关系来提高多标记分类算法的性能.在分析了已有算法特点的基础上,提出了一个考虑了标记间的依赖关系的多标记分类算法.并通过实验验证了算法的有效性.然而,目前的大多数研究主要针对有标记的数据进行处理的,然而在实际应用中的许多数据具有非完全标记识的.因此,对此类的数据进行分类是值得研究的问题.
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
南京大学学报(数学半年刊)(2020年1期)2020-03-19
吉林大学学报(理学版)(2018年4期)2018-07-19
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
都市丽人(2015年4期)2015-03-20
航天返回与遥感(2014年5期)2014-07-31
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中原工学院学报(2014年4期)2014-04-01
