
Spark框架下的受众分群及矩阵分解的推荐算法研究
2016-08-09 07:23周虹君殷复莲陈怡婷周嘉琪伊成昱
中国新通信 2016年11期
周虹君 殷复莲 陈怡婷 周嘉琪 伊成昱
【摘要】 本文针对协同过滤推荐算法中存在的矩阵稀疏问题,提出了基于聚类和矩阵分解的推荐算法,并结合隐式反馈信息构建的电视用户收视偏好模型,将推荐算法应用有电视动画受众分群和推荐中。针对受众分群和节目推荐所使用的聚类算法和推荐算法涉及大量的迭代计算的问题,采用了高效的分布式计算系统——Spark进行电视动画节目推荐研究。该方法提高了推荐准确度,运行时间明显减少,具有较强的可扩展性。
【关键词】 Spark 受众分群 矩阵分解 推荐 电视动画 节目标签
引言
推荐算法是目前应用较广的数据挖掘技术,在学术研究和应用方面都得到了广泛关注。Shihang H[1]在MapReduce上实现了对网络服务的协同过滤推荐,而MapReduce并不擅长推荐算法的迭代计算;Jing M[2]构建了大规模的广告推荐系统;Duo L[3]提出了基于统计模型的推荐方法,以解决协同过滤算法中的矩阵稀疏问题,并将其应用于用户行为分析及推荐中;YiBo H[4]提出了基于聚类的协同过滤推荐算法,但其涉及的迭代式计算较多,致使无法实现较高的效率。Manda W[5]等人在Spark上实现了基于ALS模型的协同过滤推荐。结合以上研究以及存在的问题,文本利用Spark在内存计算和迭代计算上的优势,提出了Spark框架下受众分群及聚类分解的推荐算法,将其应用于广电动画节目受众推荐研究中。本文使用隐式反馈信息构建“用户-标签”收视偏好模型,通过聚类划分用户簇实现受众分群,然后使用矩阵分解的推荐算法针对不同的用户簇进行推荐,可进一步降低矩阵的稀疏性。使用“用户-标签”收视偏好模型进行受众分群,一方面可以通过标签实现对用户的肖像刻画,另一方面可以使得各用户簇的特性更加直观。
一、用户收视偏好模型
动画节目受众分群和推荐需基于用户收视偏好模型,本文使用隐含在用户与节目交互之中的隐式反馈信息构建该模型,包括二元数据(如用户是否观看了某个动画节目)和计数数据(如用户收看某动画节目的收视时长、收看次数)[7]。
1.1“用户-标签”偏好模型
使用爬虫技术获取动画节目标签并与用户收视数据结合,形成“用户-标签”基本模型,使用收视时长、节目播出时长重构出“用户-标签”偏好模型的特征——忠诚度和兴趣度,构成“用户-标签”偏好集合:IL={L1,L2},L1、L2分别表示用户对节目的忠诚度和兴趣度。
忠诚度:某用户收视含某标签的节目总时长与含该标签的节目播出总时长的关系,表征该用户对某标签的忠诚程度。如式所示:


原始的收视偏好矩阵很稀疏,通过矩阵分解可有效降低收视矩阵的稀疏程度[6]。矩阵分解的求解方法很多,常用方法有:最小二乘迭代法ALS和随机梯度下降法SGD。
ALS模型中,对R≈PQT固定P求解Q,然后再固定Q求解P,重复交替这两步直至算法收敛[5]。本文基于Spark分布式计算框架,因此采用更易于分布式计算的ALS算法。
2.2推荐算法的评价指标
为评价算法推荐的准确性,本文中采用一下评价指标:均方误差MSE、均方根误差RMSE、全局平均准确率MAP[7]。MSE表示评价数据的变化程度,其值越小,说明推荐模型描述实验数据具有更好精确度,RMSE为其标准差。而MAP是基于排名的评价指标,其值越高说明推荐的节目越精准,节目的排位也更能满足用户。其具体定义分别如下式
三、实验及结果分析
本文使用某省单月用户收视作为实验数据, 进行动画节目核心受众分群及其推荐。实验在Linux上搭建Spark平台,并使用Python API、Anaconda科学计算集成以及IPython Notebook作为IDE。
3.1“用户-标签”偏好模型的受众分群
(1)Spark平台下的K-means受众分群
计算动画节目受众所投入的累计时长,取时长最长的70个动画标签进行降维处理,并构建“用户-标签”偏好矩阵。使用K-Means聚类实现用户分群,本文将最大迭代次数设为100,确保算法达到收敛。由于聚类簇数K会影响最后的聚类效果,因此需要通过实验来确定。目标函数WCSS是K-means聚类的内部评价指标,其数值可以表征聚类结果的误差,其值越大,代表聚类的误差越大。本实验通过改变K值,综合聚类效果及运行时间确定K的取值。实验结果如图1: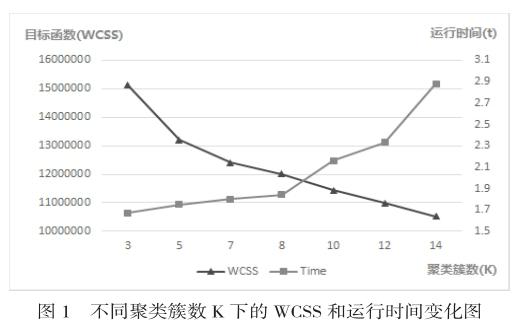
随着K增大,目标函数WCSS数值降低,聚类效果越好,同时运行时间也增加。综合不同K下的WCSS和运行时间,本文选择K=8作为聚类的簇数,根据“用户-标签”偏好模型,将用户划分成8类。
使用节目标签对分群后的各类簇用户进行肖像刻画。表3为各类簇前十个高频核心标签。如表,类1用户偏爱冒险、国产动画;类2用户的兴趣集中在益智和战斗、冒险类动画;类3用户偏向亲子和家庭类动画,可预测其主要受众为低龄儿童;类4用户的兴趣集中在辅导、音乐类及真人秀节目;类5用户的标签集中在搞笑和益智类;类6用户的兴趣度明显集中在音乐、辅导等益智类的节目;类7用户喜欢剧情、冒险、战斗类的动画;类8用户偏向于游戏、综艺等少儿类节目。

(2)不同平台下受众分群的对比
本实验在Spark和R中使用K-menas对实验数据进行聚类,并就其CPU占用时间进行对比。实验结果如表4。使用Spark受众分群的CPU占用时间比R少一个数量级,时间减少约80%,说明在迭代运算方面,Spark更有优势。
3.2矩阵分解的协同过滤推荐算法
使用“用户-节目”收视偏好模型,根据分群后结果,使用矩阵分解的协同过滤算法分别对各类用户推荐,本实验使用ALS进行矩阵分解。实验将用户的最大因子向量维度设为100维,最大迭代次数设为10次,收敛阈值设为0.01。
本实验对某月收看动画节目天数最多(29天)的机顶盒的用户进行推荐,受众分群后该用户属于用户簇5,此类用户偏爱冒险、奇幻、搞笑类动画。推荐结果按照偏好评分取前50个节目。
(1)有无受众分群的推荐结果比较
实验中,分别对经过受众分群的用户和未分群的用户进行节目推荐,预测出的评分表示用户对该节目的偏好程度。为用户ID=174294377推荐评分高的前十个节目,如表4:
可以看出,受众分群后的推荐结果可挖掘到未分群推荐所忽略的节目,例如偏好评分较高的《熊出没之丛林总动员》和《大风车》,未出现在无受众分群的推荐列表中。因此,受众分群的协同过滤推荐可以挖掘到更多更加满足用户收视偏好的节目。
(2)有无受众分群的推荐结果、以及用户原始偏好指数对比
表5显示,矩阵分解的推荐算法在整体上表现都是优秀的,无论是有无进行受众分群的推荐,都没有较严重的误差;另一方面,受众分群后进行推荐相比于未分群进行节目推荐,更加接近用户原始偏好指数,推荐结果的可信度更高。
(3)有无受众分群的推荐结果评价指标对比
该实验对全部用户进行动画节目推荐,分别计算两个推荐方式的MSE、RMSE、MAPK、和运行时间,实验结果如表6: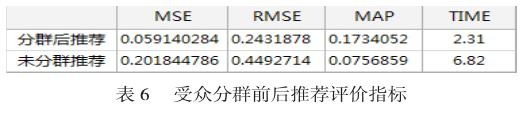
上图显示,经过受众分群的推荐,其MSE和RMSE的值越低,说明节目推荐的准确度越高,其准确率提高了60%;另一方面MAP的值越高,说明就排名而言,受众分群的推荐更接近用户的偏好。从运行时间而言,该算法节省了50%的运行时间。
四、总结
本文基于分布式处理框架Spark,提出了基于聚类和矩阵分解的推荐算法,并结合隐式反馈信息构建的电视用户收视偏好模型,将推荐算法应用有电视动画受众分群和推荐中。通过对高频受众进行有无受众分群的推荐,对比验证得出,基于受众分群的节目推荐,可以挖掘出传统推荐所忽视的节目,从个体上,提高了所推荐节目预测评分的准确性,从整体上,提高了推荐节目列表的排名准确度。该方法能够明显减少推荐时间并且提高推荐准确度,具有良好的可扩展性。
参 考 文 献
[1] Shihang H,et al.Collaborative filtering of web service based on MapReduce[C]. ICSS.2014
[2] Jing M.A recommend system for modelling large-scale advertising[C].CCT.2014
[3] Duo L, et al. A NEW ITEM RECOMMEND ALGORITHM OF SPARSE DATA SET BASED ON USER BEHAVIOR ANALYZING[C].ICSP.2014
[4] YiBo H. An Item Based Collaborative Filtering Using Item Clustering Prediction[C].ISECS.2009
[5] Manda W, et al. Algorithmic Acceleration of Parallel ALS for Collaborative Filtering: Speeding up Distributed Big Data Recommendation in Spark[C].ICPADS.2015
[6] 郑凤飞,黄文培.基于Spark的矩阵分解推荐算法[J].中国机器学习会议.2015
[7] Nick P.Machine Learning with Spark[J]. Packt Publishing - ebooks Account.2014
[8]ZAHARIA M,et al.Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing[C].EECS.2011
