
基于云平台的知识关联挖掘研究
2016-08-13 09:44刘晶晶
无线互联科技 2016年12期
凌 玥,刘晶晶,章 韵
(南京邮电大学,江苏 南京 210046)
基于云平台的知识关联挖掘研究
凌 玥,刘晶晶,章 韵
(南京邮电大学,江苏 南京 210046)
针对用户动态浏览过程,文章提出了一种基于权值矩阵的FP-Growth关联规则。经过时间因子过滤,得到初始矩阵,进一步计算出权值向量,用于FP-Growth算法改进。同时,解决了动态事务项集部分更新及支持度变化的问题,分析频繁项集的关联规则,在云平台上进行并行处理,改进算法性能和时空间效率,最终得到更有效、更精准的频繁项集,为后续推送研究做基础。
数据挖掘;Hadoop;关联规则;MapReduce近年来,“云计算”[1]和大数据(Big Data)[2]技术在全世界迅猛发展,引起了全世界的广泛关注。大数据技术发展的主要推动力来自并行计算硬件和软件技术的发展,以及近年来行业大数据处理需求的迅猛增长。其中,大数据处理技术最直接的推动因素,当数MapReduce大规模数据分布存储和并行计算技术,以及开源Hadoop MapReduce并行计算系统的普及使用。从宏观角度分析,数据挖掘等同于“数据中的知识发现”,但从微观上看,数据挖掘只是KDD过程的一个关键步骤。KDD包含数据清理[3]、数据集成、数据选择、数据变换、数据挖掘[4]、模式评估、知识表示几个环节[5]。本文基于关联规则[6]的推荐思想:挖掘了论文之间的相关性,即用户读取文献及其参考文献时间与其之间相互引用次数累计,找出两者的关系密切程度,再排序选出优先推送,研究了这一问题并提出了一个在页面浏览时间因子矩阵的基础上挖掘频繁项集的关联规则算法。关联规则挖掘方法自提出以来已有很多改进算法,本文从事务项的时间角度,针对用户浏览轨迹,停留时间及路径等问题,提出了一种基于时间矩阵FP-tree关联规则挖掘方法。
1 关联规则问题描述及关联规则实现
1.1 关联规则和FP树及FP-Growth算法
1.1.1 关联规则
一个关联规则[7]是一个形式如下的蕴含关系:,其中,且。
X(或Y)可以被认为是一个总和,称为项集,并称X为前件,Y为后件。如果 X是事务集ti∈T的一个子事务,则称ti包含X。支持度(Support,)和置信度(Confidence),这两个是关联规则判断的主要数据指标,决定是否是关联规则。频繁项集就是如果项集I的支持度大于等于预定义的最小支持度阈值,则I是频繁项集。
关联规则是通过频繁项集挖掘,构成形如X→Y蕴含关系,其中,并且。同时计算蕴含式X→Y的置信度,若其置信度大于等于预定义的最小置信度阈值,则是有效的关联规则。
1.1.2 FP树
FP树[8]是通过依次顺序读取事务数据记录,并把每个事务映射到一棵根结点为null的树上,根据树生成的路径模拟数据事务关系,它是一种输入数据的压缩形式。
1.1.3 FP-Growth算法
FP-Growth 算法[9]的最核心的步骤是 FP 树的构造过程,需要扫描两次事务数据集:第一次扫描事务数据集,计算出所有事务中项支持度,找出满足支持度的项(1 频繁项),并且将频繁项按支持度值降序排列;第二次扫描,以前一次扫描获取的事务集为基础构建一棵以“null”为根的FP树;然后FP-Growth算法将FP-tree划分成条件子树,以自底向上方式探索树,相当于基于后缀的方法对频繁项集的挖掘。FP树中的每一条路径映射一个事务,通过对指定结点的路径考察,可以挖掘以该结点结尾的频繁项集。
1.2 关联规则实现
1.2.1 浏览轨迹日志信息
当用户浏览知网等网站服务器时,在服务器中会记录用户浏览过程相关联的一些日志文件信息。在日志文件中,每条记录被称作项或条目,这样可以根据用户浏览文献的习惯,对其浏览路径及用户在页面停留时间做信息采集,通过关联分析找出频繁项集,关联规则挖掘的目标是发现用户对站点各页面的访问之间的关系。
1.2.2 用户浏览路径关联规则挖掘
关联模式的挖掘算法通常是把用户的访问时间或者用户的访问频率当作浏览过程中很重要的一个环节。通过日志分析可以把用户这些浏览轨迹的信息能够形成用户在网页上最频繁浏览的路径,是可以将信息转换成数据形式存入数据库中,通过对数据库中数据遍历路径进行挖掘得出频繁项集。
在造林之前,应该详细科学合理、精心组织情况下,根据生态区位的重要性规划林地,根据造林地的地理优势、水分等条件进行合理布局,尤其是道路与排灌设施等。为此,加快修建新的主干道,进一步完善排灌设施。对于油茶幼树种植靠近田地边田埂上的,幼树栽植应尽量保持与田埂一定的距离,方便于后续作业、油茶果实采摘运输等。排水方面措施:在幼苗的周围填土使之形成垄状,垄约高于地面25厘米,组织有关人员及时开挖排水沟渠,及时排出去多余的水分。科学合理规划建设油茶林地,为油茶栽培奠定良好基础。
1.2.3 基于用户浏览分析的时间因子
网页的有效性与用户所浏览网页时的浏览行为是密切相关的。从表面上能够看出网页对用户整个浏览过程中的重要性的浏览行为很多,其中最为重要是用户在某一网页上的浏览时停留的时间和来回重复浏览某一网页的次数。在依据阅读文献的习惯及上述关联规则FP-tree的基础上,考虑用户在页面的浏览时间及次数这方面的因素,将时间因子作为关联规则过滤因子,来更好地计算出用户浏览的路径。
1.2.4 基于矩阵的FP-Growth改进算法
根据研究发现将矩阵运算和树的存储结构相结合应用于关联规则挖掘是比较高效且实用算法改进方法的手段。矩阵被认为高效的且有利于提高关联规则效率及减少空间开销的算法之一。树形结构,可以直观明朗地表示频繁项集之间的内在联系,便于动态更新处理。
2 基于云平台算法设计
2.1 算法步骤
根据上面的分析,得出理论分析步骤及改进算法思想流程如下:(1)扫描数据库,依据时间因子的约束,得到时间过滤矩阵。(2)在时间过滤矩阵的基础上,计算每个项目支持度,生成权值矩阵,调用剪枝函数(大于支持度阈值)得到频繁矩阵。(3)通过程序扫描频繁矩阵,及数据库或最小支持度变化,动态更新频繁矩阵,采用MapReduce并行框架,来构建FP树。(4)在并行化FP树输出结果中,用关联挖掘算法FP-Growth(FP-tree,最小支持度)挖掘最终的频繁项集。(5)最后通过频繁项集在聚类中加权筛选,得出最终的频繁项集,得到关联关系。
2.2 MapReduce模型并行化设计
基于云平台的MapReduce 的改进FP-Growth 算法MR-FP具有以下两个步骤:(1)第一次MapReduce任务计算事务中项的支持度构成权值矩阵。首先是将数据库分割成小数据块,后将这些块被发送服务器进行支持数的并行计算。这个计算过程可以通过MapReduce分布式地计算完成,计数结果构成为频繁列表和项目是按降序排序的频繁矩阵,频繁项目的所有项目被分为若干组。(2)第二次MapReduce任务执行MapReduce-FP-Growth(MR-FP)算法计算满足支持度频繁项集关联挖掘。在MR-FP算法是将改进算法中的一些步骤做并行化处理,实现分布式处理。它需要MapReduce处理并收集从节点的频繁项集,将矩阵数据映射到FP树,读取事务项目矩阵列表和根据改进算法在从节点建立自己的本地条件FP树并且在从节点同时进行递归调用,得出频繁项集,最后reduce合并形成最终频繁项集。并行化的核心任务,将串行算法中对各频繁项的条件FP树挖掘,改为在从节点结点处理,进行并行化递归挖掘,最后再合并成频繁项集,并以<频繁项,频繁项集>输出。至此,项集挖掘结束并由此得到关联规则。
3 实验结果和性能分析
3.1 硬件和软件环境
实验云平台环境为5台服务器节点组成的Hadoop集群,其中1个节点作为Hadoop集群的Master结点,剩余4个节点作为slave节点。各节点操作系统为Linux CentOS 6.7、Mahout 0.8等,并根据Hadoop的环境搭建约定,建立集群环境。
3.2 关联实验结果分析
在图一的实验中可以看出,相比于传统的算法,并行化算法的运行效率大大提高,尤其是随着事务规模的增加,这种优势更加凸显。另一方面,在事务规模较小时,并行算法的运行效率反而会低于传统算法,原因是并行化算法中需要使用额外时间的开销来实现各个节点(map、reduce等)的管理和调度,这在小规模事务处理时占了大部分运行时间。但随着事务规模的持续增大时,并行化算法效率超过了传统算法,优势相当明显。
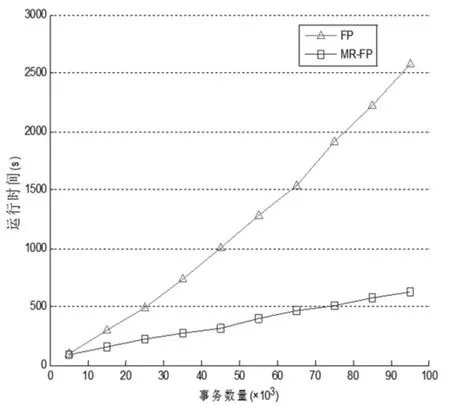
图1 串行与并行算法性能比较
4 结语
针对用户动态浏览过程,提出一种基于矩阵的FPGrowth的关联规则分析。对服务器日志信息进行数据提取,并根据本文提出的时间因子过滤,得到初始矩阵,继续对矩阵做进一步处理,将改进后的权值矩阵用对FP-Growth进行算法改进,同时解决了动态事务项集部分更新及支持度变化的问题,得出频繁项集,对频繁项集中的项基于聚类的结果进行加权筛选,最终得到更有效、更精准的频繁项集,得出关联规则,为推送工作做准备。
基于对云平台的MapReduce框架的研究,可以将上述算法进行并行化。对实验进行评价,进行实验,减少了挖掘时间和内存空间的消耗。
[1]赵广才,张雪萍.云计算技术分析及其展望[J].电子设计工程,2011(22):4-7.
[2]Wu X,ZHU X,Wu G Q,et al.Data Mining with Big Data[J].Knowledge&Data Engineering,2014(1):97-107.
[3]KARR A F.Exploratory Data Mining and Data Cleaning[J].American Statistical Association,2006(473):1152-1154.
[4]SHI Y,XU W,CHEN Z.Data Mining and Knowledge Management[J].Springerbriefs in Business,2015(3327):1-11.
[5]唐汇.基于自然最近邻居的离群检测算法研究[D].重庆:重庆大学,2014.
[6]张素兰.一种基于事务压缩的关联规则优化算法[J].计算机工程与设计,2006(18):3450-3453.
[7]SAHOO J,DAS A K,GOSWAMI A.An efficient approach for mining association rules from high utility itemsets[J].Expert Systems with Applications,2015(13):5754-5778.
[8]GADIA K,BHOWMICK K.Parallel Text Mining in Multicore Systems Using FP-tree Algorithm[J].Computer Science,2015(45):111-117.
[9]BORETLT C.An Implementation of the FP-growth Algorithm[J].International Workshop on Open Source Data Mining Frequent Pattern,2010(3):1-5.
Based on A Cloud Platform Knowledge Association Mining Research
Ling Yue,Liu Jingjing,Zhang Yun
(Nanjing University of Posts and Telecommunications, Nanjing 210046,China)
In view of the user dynamic browsing process, this paper proposes a FP - Growth of association rules based on weight matrix,after a time factor filter, gets the initial matrix, further compute the weight vector, used for FP - Growth algorithm is improved. At the same time, solved the dynamic part of the update transaction itemsets and support the analysis of frequent item sets of association rules,on the cloud platform for parallel processing, the algorithm to improve performance and space efficiency, eventually get frequent itemsets,more effective and more accurate for subsequent push research foundation。
data mining; Hadoop; association rules; graphs
凌玥(1995— ),女,江苏无锡,本科。
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
新世纪智能(数学备考)(2021年9期)2021-11-24
河南水利年鉴(2020年0期)2020-06-09
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
计算机工程(2014年6期)2014-02-28
长春大学学报(2013年8期)2013-06-21
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
网络安全与数据管理(2010年1期)2010-05-18
