
基于Chi-quare检验与词义分析的试题重复检测算法
2016-09-08 09:23雷虎任佳
电子设计工程 2016年13期
雷虎,任佳
(西安翻译学院 陕西 西安710105)
基于Chi-quare检验与词义分析的试题重复检测算法
雷虎,任佳
(西安翻译学院 陕西 西安710105)
针对无纸化考试系统入库试题重复检测问题;提出基于卡方检验与词义分析的试题重复检测算法,首先自动提取试题的特征信息词项,利用卡方检验改进公式进行特征词分析并删除冗余词;其次,结合中文WordNet词典对特征词进行词义分析,并利用Tf-Idf方法计算入库试题的特征词向量与不同题型特征词的余弦相似度;最后,根据所得相似度值判别该试题是否与题库试题重复。实验结果表明,在重复度阀值选取0.8时,算法耗时少、准确性高。
卡方检验;特征词;语义;余弦相似度;试题重复度
基于信息技术的快速发展,无纸化考试系统已经成为传统考试改革的趋势和方向。试题的质量和题库的试题量是无纸化考试系统高质量高效率运行的关键;为了适应无纸化考试题库中试题的数量和质量要求,试题入库时,由于命题者之间的协调不周,题库中试题重复时有发生,如入库试题与试题库中原有题目重复或组卷后一套测试试卷中因考点相同题型不同导致一试题题目包含另一试题答案等,都将影响无纸化考试系统的运行效果。为了降低题库中的试题重复度,命题老师在录入试题时,系统需要自动检测录入试题与题库中试题重复度,根据给定阀值判断录入试题在题库中是否存在重复的试题?而算法的好坏直接影响到入库试题是否与题库中试题重复的准确性,因此,对于无纸化考试系统的试题重复度检测算法的研究至关重要。
试题重复度算法通常分为基于词频的相似度算法和基于语义分析相似度算法,邱云飞等人提出的基于词频的试题重复度算法没有将同义特征词进行比较分析,算法效果不明显,余弦相似性计算往往与预先给定的阈值有很大关系,而且稳定性不好,当阈值确定不准确将严重影响最终结果,因此基于词频的相似度检测算法不能很好进行试题重复度地区分[1-3];基于语义的相似度算法从试题中抽取TF-IDF值较大的特征词,然后进行特征词的位置和词义分析,从而计算出基于语义和词频的试题重复度。此方法对试题重复度检测的精度较高,但因建立特征词的语义库比较困难,黄承慧、李明涛等人结合语义特性进行文本相似度计算,尽管对词语的语义关系进行了分析,但却没有将词语本身的特性(如词频、冗余等)进行分析计算,所得相似度算法复杂,而且效率不高不高[4-7]。
文中提出的基于卡方检验的语义相似度算法:预先自动提取出入库试题的特征信息词项,利用卡方检验进行验证并删除冗余词,结合中文WordNet词典进行词义分析和入库试题与题库中试题的余弦相似度计算,根据给定阀值,即可得到入库试题与题库试题是否存在重复,以此方法计算出试题重复度更加准确。
1 相关技术
1.1Tf-Idf方法
TF-IDF方法是基于特征词之间相互独立的一种试题特征词提取方法,运算效率高。在提取特征词时,将试题的文本信息按照一定的逻辑次序划分成一组特征词序列,再根据所得特征词分解成相同词义的候选特征词序列,利用余弦定理计算候选特征词序列的相似度,确定候选特征词构成试题特征词的概率,提高提取特征词的准确度。要实现试题文本的重复度检测,就需要对试题文档进行向量表示,向量空间模型(Vector Space Model,VSM)是一种经典的文档向量化表示方法,常用来进行相似度计算的数据模型。任一试题都能提取出一组特征词,按照特征词在试题中的重要程度进行权重分配,然后进行规范化正交特征词向量组成向量空间。所有要录入的试题文档都可表示为向量(T1,Q1,T2,Q2,…,Tn,Qn),Ti为特征向量;Qi为特征词Ti的权重值,通常需要构造一个关于特征词的权重计算函数用来判断试题文档的重复度。
词频(Term Frequency,TF),表示一个词语在一文档中出现的频率。TF主要思想:一个词语w1在文本D中出现的频率较高而在文本E中出现的频率较低,w1词语就具有很好的区分能力,也称为该词语贡献度较大。反文档频率(Inverse Document Frequency,IDF)的主要思想是:IDF越大,包含词语w1的文档越少,w1具有很好的区分能力。文档d1和文档d2的关键词语的TF/IDF分别是w11,w12,...w1n和w21,w22,...,w2n。
1.2Chi-quare检验
Chi-quare检验是以检验统计量χ2分布为基础一种非参数检验:设入库试题的特征词行向量为x=(x1,…..,xn),题库中试题的特征词列向量y=(y1,。..yp),其中n、p分别是入库试题和库中试题所含特征词的数目。x和y为文档中含有相同特征词(或同义特征词)的相似度。Oi表示观察频数,Ei表示期望频数,n为总频数,pi为i水平的期望频率。统计量χ2值越大,表示观察频数和期望频数差额越大;统计量χ2值越小,说明观察频数和期望频数越接近[9]。

当某一试题特征词t和试题类别k之间的相关程度满足卡方分布时,m1表示类别k中包含t的文档频数,m2表示不在类别k中包含t的文档频数,m3表示类别k中不含t的文档频数,m4表示不在k中不含t的文档频数,则卡方检验中χ2的统计量可以表示为:

χ2值越高表明特征词t与类别k的相关性就越大,式(2)计算时当m1×m4-m2×m3>0时,所得值越大表示特征词t与试题类别ck中特征词相关性就越大,特征词在试题类别k中出现的次数就越多,即特征词属于的类别k的概率越大;当值为零时表示试题类别k与特征词t无关,即特征词t与试题类别特征词相互独立。对于试题的所有试题类型计算特征词χ2值,并按式(3)进行排序后删除所有类别的低于阀值的试题特征词。

当m1×m4-m2×m3<0时,表示特征词t与属于类别k的概率较小,但在其他试题类别中出现的概率较大,这时χ2(kt)也较大,表明卡方检验的统计量χ2(kt)增大了试题特征词与类别k的相关性较小而与其他类别相关性较大的特征词的权重值,而且题库中同种类别试题数量较大,特征词构成复杂,入库试题特征词与题库试题特征词进行卡方验证时算法运算量较大,不仅提高了算法的复杂度而且影响了算法的准确性。这也是卡方检验进行特征词类别相关性验证时的不足之处。
特征词的提取算法直接影响试题重复度检测的准确度,通过上述的卡方检验的不足分析,在提取入库试题的特征词时减少题库类别和综合考虑特征词与其他类别试题特征词的集中度和分散度改进Chi-quare检验的χ2计算。
1)建立同类试题模板,确定题库中各类试题的关键特征词和候选特征词库。针对无纸化考试系统的试题类型较少,试题内容较少的特点,在开始构建题库之前建立各种题型(如选择、操作、计算题型)模板,并将模板的词汇构成题库类别关键特征词向量Ki={t1,t2,……tn},i为试题的种类,题库中每道试题除关键特征词外的其他贡献度较大的词汇组成候选特征词Li={tf1,tf2,……tfn}。这样不仅减小了命题的难度而且大大缩小了题库试题的特征词范围,减少了进行特征词卡方验证时的算法复杂度。
2)集中度。集中度表示试题特征词ti在所属题型中,同时也存在其他题型中,f(tm)表示入库试题特征词t在试题类别km中出现的文档个数,集中度∂计算公式为:
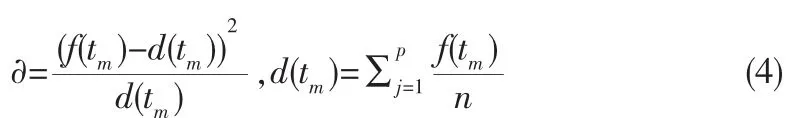
3)分散度。分散度表示试题特征词ti在所属题型中,同时也在其他题型中,f(tm)表示入库试题特征词t在试题类别km中出现的文档个数,分散度为f(tm)。
改进Chi-quare检验的χ2计算公式如下:

卡方统计量计算的改进公式引入了集中度和分散度两个因子,并对相同试题类型建立试题模板,形成特定类的特征词库,使公式(2)增大了特征词在某一题型类中出现频率低而在其他类中出现次数较多的的权值问题得到了解决。
1.3同义特征词相似度计算
传统试题重复度算法,特征词权重采用TF-IDF计算得出,特征词的同义词没有被考虑,导致试题的重复度检测仅限于字面意思,遗漏了试题同义特征词的重复度检测。利用专业工具词典对试题特征词加权检测,算法准确性高,但特征词典与同义词典的建立困难;对于试题文本中的任意两个特征词,如果在试题中的相同位置可以互相替换而试题表达的意思一致,则认为这两个特征词的相似度大,否则相似度小。对词义是影响特征词相似度的关键因素,特征词相似程度可以用特征词的词义相似度来衡量。
入库试题的同义特征词向量Sa={(ta1),f(ta2),…f(tai)}和题库试题的特征词向量Sb={tb1,tb2,……,tbj},其中f(t1)表示入库试题特征词ta1的所有同义词向量,同义特征词向量有中文WordNet词典提取出来;Sa和Sb中特征词及同义特征词向量的相似度能够确定Sa和Sb分别对应的试题的重复度,基于同义词的特征词相似计算中的权值Q由特征词的TF-IDF值计算,公式如下:

其中,Tfidf(tjk)=Tf(tjk)×Idf(tjk)×γ,Idf(tjk)=log,γ为特征词的权重值;Tf(tjk)可由特征词tjk在试题中出现的次数除以题库试题总数计算。由此可见,TfIdf值与特征词tjk在试题中的出现次数成正比,与特征词tjk在题库中的出现次数成反比。两个特征词向量的余弦相似度公式为:

试题特征词的词义相似度可用特征词的同义词向量的相似度计算,公式如下:

试题的重复度可以由试题同义特征词向量与题库中试题特征词向量的相似度计算,而试题同义特征词向量与题库中试题特征词向量的相似度计算通过同义特征词向量的相似度Fv和特征词的余弦相似度Cs进行运算,公式为:

2 算法设计
2.1特征词提取
首先,试题特征信息预处理。通过词性标注、语义标注的方法进行特征词分词,用特征词表示试题信息,并完成提取特征词和删除停用词(如的、和、在等词)。题库中的试题信息提取特征词后形成试题的特征词向量,每个特征词在试题中的贡献不同。为了建立特征词空间向量模型,需要从含有大量特征词的试题信息中选取贡献较大的特征词。
其次,特征词权重计算。向量空间模型将试题文本信息表示为数字形式,但特征向量维数较大。因此需要对特征词进行权重排序,选取权重较大的特征词,将那些高度冗余的或者对试题重复率区分贡献不大的特征项删除。选取词频高的同义词为候选特征词,并对每个同义词根据词语相似度加权,给同义词加权时,如无同义词,则Sim(ti,tj)值为0。

最后,相似度计算:将优化得到的特征词及候选特征词,形成特征词向量。用卡方检验计算ti与其同义词之间的相似度,将所得Sim值与β比较,若Sim值大于β,则给ti加权并删除ti同义词;若Sim值小于β,表示该同义词无关紧要,可以直接删除该同义词;计算完所有词语的权重后,找出权重最大的前N个词语作为试题信息的特征词。
2.2基于卡方检验与词义分析的试题重复检测算法
卡方检验与词义分析的试题重复检测算法设计如下:
1)在无纸化考试系统中的试题入库时,需要对入库试题预先利用工具软件NLPIR分词系统提取试题的特征信息词项,然后对特征信息词项与题库中试题的特征词进行卡方(χ2)统计量改进公式(5)进行检验,删除冗余词项,构成试题的同义特征词行向量Sa={ta1,ta2,…tai},题库中所有试题的特征词样本向量Sb构成列向量,利用中文WordNet词典找出行向量中的特征词Ta1在列向量Sb中的同义特征词Tbk,形成Sa的同义特征词向量Sf(a)={(ta1),f(ta2),…f(tai)}。
2)将行向量Sa中每个特征词与列向量Sb的相似度之和除以Sa中特征词的个数K作为向量Sa与Sb的词义相似度,用Fv(Sa,Sb)表示。
3)特征词的TF-IDF权值由公式(7)计算,向量Sa和向量Sb的余弦相似度Cs(Sa,Sb)由公式(7)得出,由公式(6)计算集合Sa和Sb中的元素加权因子Q。
4)由公式(9)计算得到的同义特征词向量的相似度,即为Sf(a)和Sb代表的试题之间的重复度。
5)以此类推,得出行向量Sa与所有列向量Sb的试题重复度,如存在一个大于给定的试题重复阀值时,则此试题与题库中试题存在重复,不能入库;如所有值都在限定的重复度阀值范围之内,则表明入库试题与题库中现有试题没有重复,可以入库。
3 算法实现
算法中因试题特征词在提取和确认时会受试题文本的长度影响,因此,实验时选择Access计算机等级考试二级题库作为实验数据,题库中已有1 560道试题。现有450道试题准备入库,首先将准备入库的试题1利用工具软件NLPIR进行分词,然后利用卡方检验进行特征词词义相似度计算,删除冗余词。其次利用TF-IDF算法对特征词进行权值计算,并利用中文WordNet词典进行语义相似度计算,最后计算出试题文本特征词与题库中试题2的相似度,即可得到入库试题与题库试题的文本相似度。

表1 试题信息表
入库试题经过工具软件NLPIR分词系统预处理后,得到试题的特征信息词项格式如表2所示。
在卡方进行特征词检验时,用类别数的倒数、某特征项在某类中文档覆盖率的大小、某特征项在某类文本中出现的频率对检测试题的特征词进行降维处理,再利用手工方法进行特征词重复度准确度评估。实验过程中,特征词阀值分别选取试题文本的60%、70%、80%进行特征词提取,实验结果表明,当选取试题文本长度的60%的特征词时,试题特征词的重复度计算效果最好;当阀值为80%时,因为特征词较多,增加了算法的复杂度。表3为3种算法在试题重复度阀值取0.6,、0.8、0.9值时认为试题重复的准确率和耗费时间的对比分析表。

表2 预处理后的试题特征信息表

表3 3种算法的重复度检测结果比较
图1为3种算法在试题量为450,试题余弦重复度阀值分别取0.6,、0.8、0.9时的算法准确性比较图,图2为3种算法在试题量为450,试题余弦重复度阀值分别取0.6,、0.8、0.9时的算法耗费时间比较图。

图1 3种算法在不同阀值的准确性分析图
实验时,对入库的450道试题分别运用3种算法进行比较,算法A表示基于词频的余弦相似算法,算法B表示基于词频和语义相结合的余弦相似算法,算法C表示基于卡方检验的试题语义重复度余弦算法;由实验结果发现:当算法C的特征词阀值选取试题文本长度的60%,特征词余弦相似度阀值取0.8时,计算试题重复度准确性最高、耗费时间较短。

图2 3种算法在不同阀值的耗费时间分析图
4 结束语
本文利用卡方统计量对试题的特征词进行了修正,使得特征词同时兼顾词频和词义要素,为试题的重复度检测提供重要依据。实验结果表明根据本文算法计算得出的试题重复度能够有效减少题库中试题的重复率,减少了运算的复杂度,并大大提高了运算准确性。目前,无纸化考试系统正处于不断完善与发展中,文中算法的语义相似度仅从中文WordNet词典进行语义分析,因涉及同义词范围较大导致算法效率不高,后期的研究可根据不同的考试科目建立专业词典,并根据不同的试题类型设置试题模板,以此为基础设计更加合理的试题重复度算法。
[1]邱云飞,王 威,刘大有,等.一种词频与方差相结合的特征加权方法[J].计算机应用研究,2012,29(6):2132-2134.
[2]谢 华,王 健,林鸿飞,等.基于特征选择的质心向量构建方法[J].计算机工程,2012,38(1):195-210.
[3]Selvi P,Gopalan N P.Sentence similarity computation based on WordNet and corpus statistics[C]//roceedings of International Conference on Computational Intelligence and Multimedia Applica-tions.Washington,DC:IEEE Computer Society,2007:9-14.
[4]李明涛,罗军勇,尹美娟,等.结合词义的文本特征词权重计算方法[J].计算机应用,2012,32(5):1355-1358.
[5]Guan Hu,Zhou Jingyu,Guo Minyi.A Class-feature-centroid Classifier for Text Categorization[C]//Proc.of 2009 www Conference.Madrid,Spain:IEEE Press,2009:201-210.
[6]黄承慧,印鉴,侯昉.一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011,34(5):856-864.
[7]任姚鹏,陈立潮,张英俊,等.结合语义的特征权重计算方法研究[J].计算机工程与设计,2010,31(10):2381-2387.
Algorithm of feature terms semantic similarity based on chi-square test
LEI Hu,REN Jia
(Xi'an Fan Yi university,Xi'an 710105,China)
According to the question repeatability problem of paperless examination.The algorithm of Feature semantic similarity is proposed based on Chi square test.First,automatic extraction of words features information from the question,delete the redundant words by test,Second,analysis feature words semantic under the Chinese WordNet Dictionary,and calculate the cosine similarity of feature vectors by using the TF-IDF method,Finally,according to the result to determine whether the question is put into question database.The experimental result shows that the algorithm is good robustness,high accuracy,high efficiency under the threshold selection 0.8.
chi-square test;feature terms;semantic;cosine similarity;question redundancy
TN919
A
1674-6236(2016)13-0026-04
2015-07-03稿件编号:201507038
陕西省高等教育教学改革研究重点项目(13BZ69);陕西省教育厅专项科学研究项目(16JK2078)
雷 虎(1976—),男,陕西西安人,硕士。研究方向:数据挖掘与图像处理。
