
基于文本挖掘的科研项目管理辅助决策系统研究与实现
2016-11-09 01:11杨生举施韶亭
计算机应用与软件 2016年9期
蒙 杰 杨生举 施韶亭
(甘肃省科学技术情报研究所甘肃省科技评价监测重点实验室 甘肃 兰州 730000)
基于文本挖掘的科研项目管理辅助决策系统研究与实现
蒙杰杨生举施韶亭
(甘肃省科学技术情报研究所甘肃省科技评价监测重点实验室甘肃 兰州 730000)
针对科研项目管理中重复申报、重复立项和项目与评审专家匹配性等问题,通过文献分析法深入分析科研项目管理辅助决策研究现状,提出一种基于文本挖掘的科研项目管理辅助决策解决方案。采用ICTCLAS分词技术、改进的TF-IDF算法和余弦相似性算法等综合技术,确定科研项目之间的相似性、项目和专家之间的匹配性,为科研项目管理提供可靠的决策支持。详细介绍系统的总体架构、关键技术和关键步骤。该解决方案在甘肃科技计划项目管理中的应用,有效解决了科研项目重复申报、重复立项和项目与专家匹配性等问题,提高了科研项目管理水平和科研资金使用效益。
科研项目管理辅助决策系统文本挖掘相似性分析
0 引 言
近年来,国家财政大力支持科技创新,积极实施创新驱动发展战略,科技事业得到快速发展,涌现出一系列重大科技成果。如:载人航天、嫦娥登月工程、蛟龙号深海载人潜水器、天河系列高性能计算机、杂交水稻技术、人类基因组研究、第四代移动通讯、集成电路装备、高速铁路等一批重大技术实现跨越式发展。随着科技经费投入的持续增加,科研项目的申报数量也大幅增长,随之而来的问题是,科研项目重复申报、重复立项、相近似研究等现象日趋严重。一些科研项目申报单位或申请者缺乏诚信,或者对科研项目的研究现状和创新性分析不足,以相同或相近似的研究内容重复申报科研项目,严重影响了科技资源与经费的合理配置,阻碍了科技进步和社会发展。
1 研究现状
近年来,科研项目重复申报、重复立项的问题得到科技管理部门和学术界的关注和重视,国内学者分别从科技评估、分析预警、查新查重等几个方面对科研项目管理辅助决策手段进行了研究,以辅助科技管理部门科学管理科研项目,从而使高质量高水平的科研项目优先得到资助,有效提高科技投入的效率。文献[1]提出借鉴美日等发达国家科技评估的成功经验,引入第三方评估机构,选用合适的评估方法对科研项目进行事前、事中、事后和跟踪评估,并及时将评估意见反馈给项目申请者,然而科技评估周期长、成本高,对新申报的大批量项目进行事前评估并不可行;文献[2]以辅助决策模型为研究对象,以项目管理过程中积累的大量科研、财务、人事等基础数据为依托,提供了数据统计查询,态势分析、分析预警等三个级别的决策支持功能,为科技管理部门掌握科研动态、科研活动趋势提供了支撑,不足之处是不能对项目重复申报、重复立项做出及时有效的监测和预警;文献[3]提出依靠科技查新结构查重的方式,一定程度上可以减少科研项目的重复立项,但是查新工作量大、时间紧,“查全率”和“查准率”也受到多种因素的影响,难以有效地解决科研项目重复立项和相近似研究等问题。
借鉴国内外现有科研项目管理辅助决策手段的成功经验,本文运用文本挖掘等相关信息技术,设计和实现了基于文本挖掘的科研项目管理辅助决策系统。通过综合分析科研项目之间的相似性、项目与评审专家之间的匹配性,为科技管理部门科学管理提供决策支持,有效地提高科研项目的管理水平和实施绩效。
2 系统设计
该系统以科技计划管理系统[4]和专家信息管理系统积累的大量半结构化或非结构化科研项目和专家信息为支撑,遵循简单性、适应性、一致性、可靠性和经济性的设计原则[5],采用自顶向下、逐步分解的方法,将系统分解为数据抽取、数据分析、数据展示三大子系统。系统功能结构如图1所示。
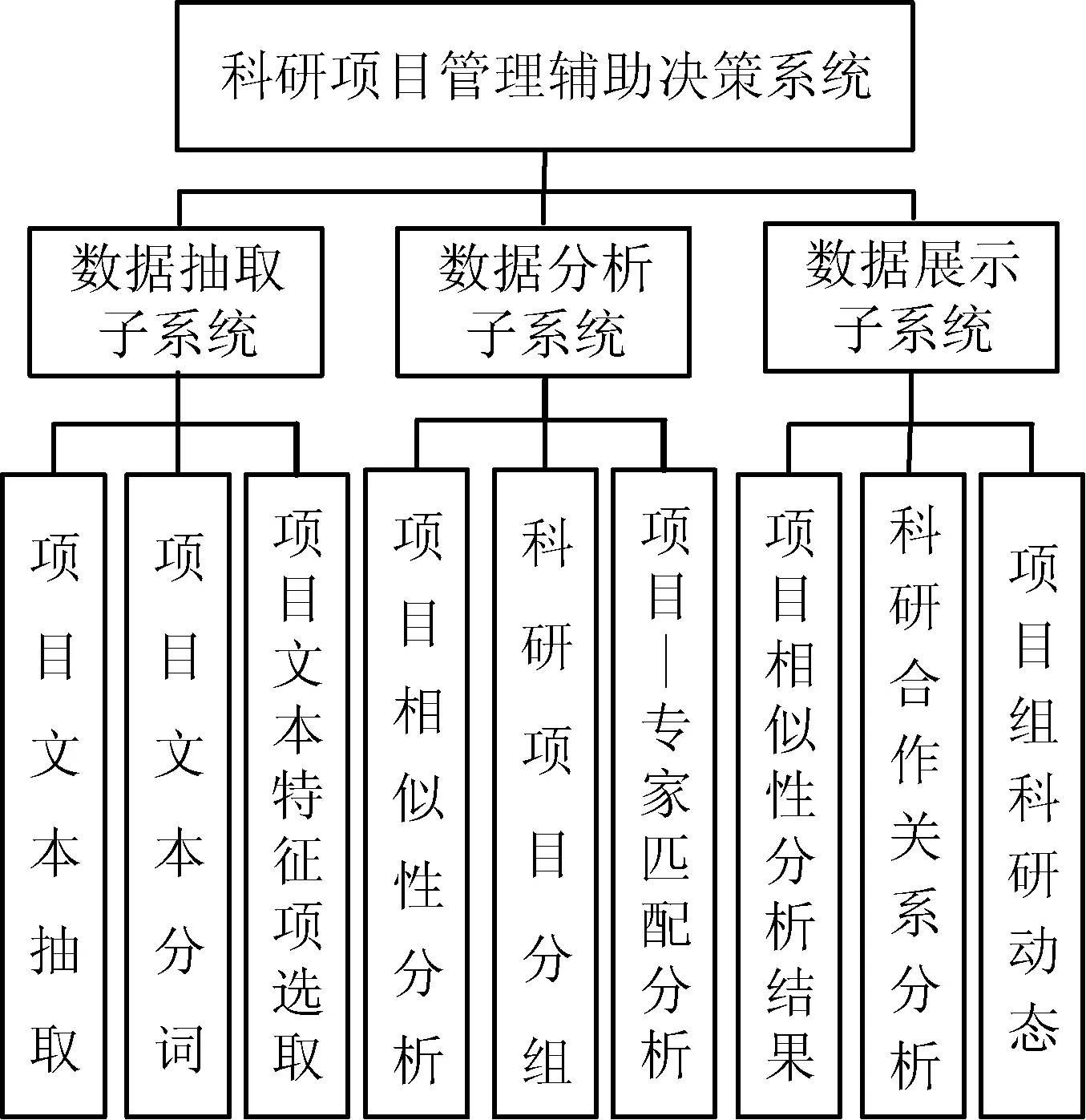
图1 系统功能结构图
2.1数据抽取子系统
数据抽取子系统主要包括项目文本抽取、分词和特征项选取三个功能模块。
文本抽取模块利用数据库相关技术,从科技计划管理系统和专家信息管理系统数据库中,批量抽取项目名称、项目简介、项目研究的科学依据和意义、项目主要研究内容、项目研究方法、项目考核指标、项目关键词、专家简介、技术职称、所学专业、熟悉学科、技术领域、专家学术专长和研究方向等文本数据,并采用一定的正则规则对抽取的数据进行清洗和规范处理,形成该系统的基础数据库。
文本分词模块采用汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System),将从不同角度表达科研项目信息和专家信息的汉字序列,分解成为能够独立运用的最小语言单位即词。
特征项选取模块首先对文本分词结果进行去除停用词处理,然后采用TF-IDF算法分别计算词在文本中的权重,根据词在文本中的重要程度,选取一定数量的词形成一个能准确表达科研项目信息和专家信息的文本特征子集。
2.2数据分析子系统
数据分析子系统包括项目相似性分析、项目分组、项目-专家匹配性分析三个功能模块。
项目相似性分析模块运用余弦相似性算法,分别计算一项目与其他项目的项目名称、简介、科学依据和意义、主要研究内容、研究方法、考核指标等多个角度的相似性,根据表达项目信息的重要性不同,对其赋予相应的权重进行加权平均,得出该项目与其他项目的综合相似性。
项目分组模块依据项目相似性分析结果,将研究方向相近科研项目归类到同一分组中。在项目评审时,将同一分组的项目分配给同一批评审专家,保证评审结果公平、公正。
项目-专家匹配性分析模块通过对项目信息和专家信息进行相似性分析,自动遴选出与项目研究内容最相符的评审专家,使项目按照细化专业精确地分配到省内外同行专家手中,提高项目评审的科学性、合理性。
2.3数据展示子系统
数据展示子系统包括项目相似性展示,科研合作关系分析,项目组人员科研动态分析三个功能模块。
项目相似性展示模块采用饼状图直观地显示出一项目与其他项目相似性的大小,点击饼状图可查看相似项目内容的具体比对,并将高相似项目向社会公开,发挥督导警示作用。
科研合作关系分析模块运用社会网络图形象地描绘出项目申请者的科研合作情况,包括合作的科研项目和科研人员,帮助科技管理部门理清科研合作关系,有助于加强科研合作交流,实现科研资源共享。
项目组人员科研动态分析模块罗列出项目组人员的科研动态,用红色字体醒目的显示出项目组人员参与的未按期结题的项目,辅助科技管理部门掌握项目组人员的科研活跃度和科研诚信,在项目立项时合理分配,保证科研任务顺利实施。
3 系统实现的关键步骤
3.1主题词表建立
将北京大学计算语言学研究所加工的语料库和科技计划管理系统数据库中的项目关键词结合起来,并加入新术语、含字母词语等科研领域专业术语[6],形成科研领域专业语料库,使科研项目信息和评审专家信息的文本分词更加准确。
3.2文本信息分词
该系统基于ICTCLAS分词技术[7]对科研项目信息和评审专家信息进行文本切分。ICTCLAS分词技术基于层叠隐马尔可夫模型CHMM(cascaded hidden Markov model),将未登录词识别、排歧、分词等过程有机地融合到一个统一的理论模型当中。应用结果证明ICTCLAS具有良好的分词效果。
3.3文本特征项选取
系统采用张瑾提出的基于改进TF-IDF算法的情报关键词提取方法[8]对科研项目信息和评审专家信息进行文本特征项选取。首先对文本向量进行粗降维,然后采用TF-IDF的改进算法对每一个特征项进行评估,按照评估分数从高到低排序后,选取评估分数高于设定阈值的特征项,形成项目信息和评审专家信息的文本特征向量。基于TF-IDF的改进加权公式如式(1)所示:
(1)
其中fij为词语i在文档f中出现的频率,N为文档总数,Ni为文档中出现词语i的文档数,β为一个经验值,一般取0.01,li表示词语i出现的段数,L表示总段落数。
算法的迭代过程描述如下:
Step1输入文档集D={d1,d2,…,dn}、文档di对应的文本候选特征集Ti={t1,t2,…,tn};
Step2统计词语ti在文档di中出现的频率fi,并进行归一化处理,防止偏向长文档;
Step3计算词语ti在文档集D中逆文本频率idf;
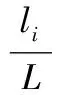
Step5使用式(1)计算词语ti的TF-IDF权值Wi;
Step7重复Step1-Step6,直到文档集D中所有文档的文本特征项选取完毕。
3.4相似度计算
(2)
余弦夹角的取值范围为[-1,1],由于文本特征项的词频不为负,所以两个文本向量余弦夹角的取值范围为[0,1]。余弦夹角为1表示两个文本向量完全匹配,余弦夹角为0表示两个文本向量相互独立,在0和1之间表示不同程度的相似。
算法的迭代过程描述如下:
Step1输入文档di特征项的词频向量Fi={fi1,fi2,…,fin}(词频向量经过归一化处理,防止偏向长文档)、待比较文档dj特征项的词频向量Fj={fi1,fj2,…,fjn};
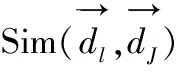
Step3重复Step1-Step2,直到文档di与其他待比较文档的余弦相似性计算完毕;
Step4重复Step1-Step3,直到文档集D中所有文档与其他待比较文档的余弦相似性计算完毕。
4 系统应用
以该系统在甘肃省科技厅科技计划项目管理中的应用为例,系统对2014年新申报的3443个科研项目进行综合分析,筛选出高度相似(相似度大于等于60%)的117个项目。其中同一申请者重复申报项目43项,同一申报单位重复申报项目54项,其他重复申报项目20项。高度相似项目主要是项目申请者对本单位或本人已立项的项目稍作改动,进行重复申报,有些项目尽管名称不同,但项目研究内容和研究方法却类同或相近似。系统按项目相似性降序排列界面如图2所示。
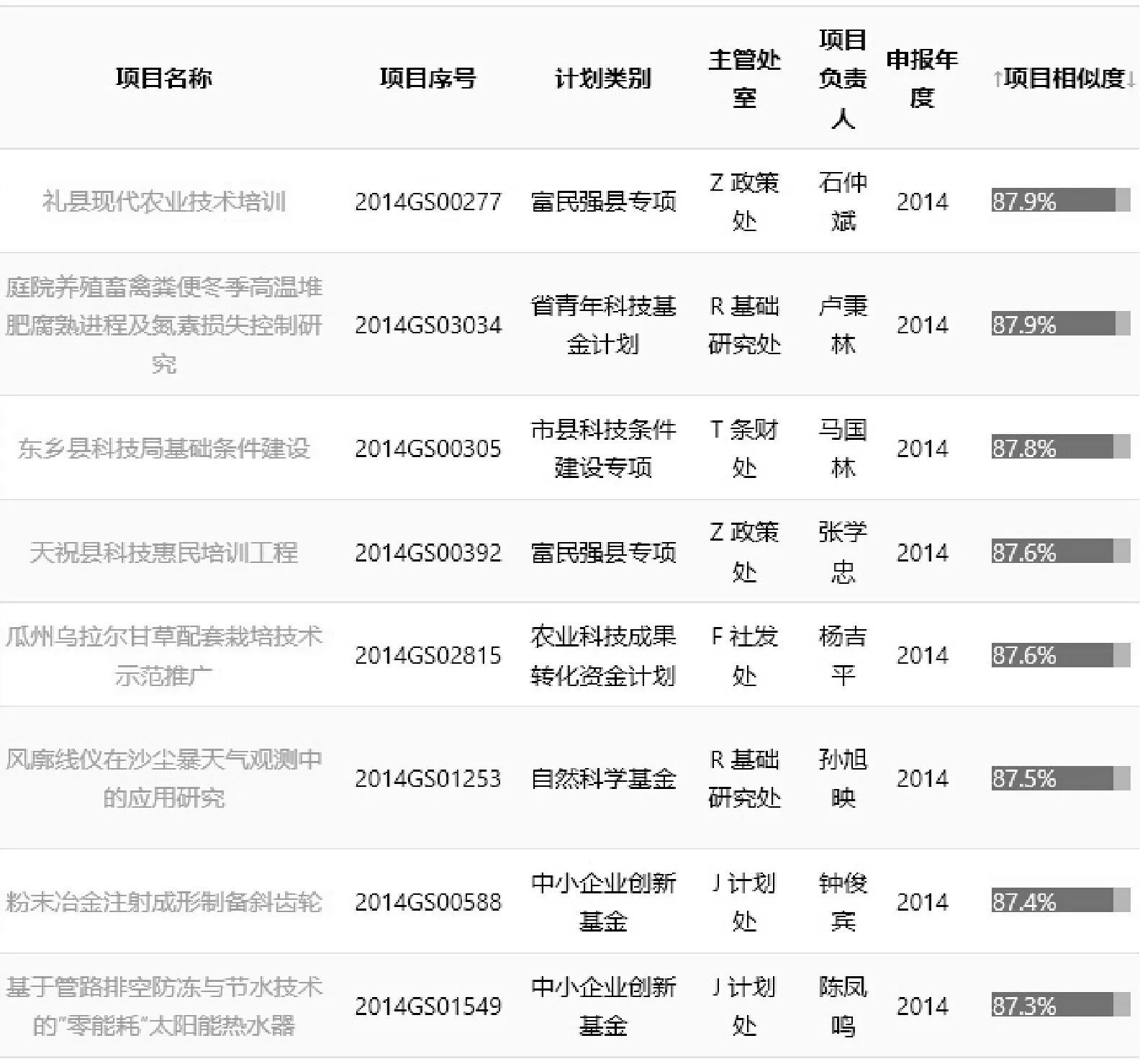
图2 项目相似性降序排列界面效果图
甘肃省科技厅依据系统的项目相似性分析结果,建立了科研诚信档案,对重复申报项目的单位或个人进行警告并取消本年度项目申报资格,对其以后年度申报的项目予以重点审查。采取该措施后,2015年度甘肃科研项目重复申报数量大幅减少,极大地提高了科研项目的申报质量。
表1、表2、表3列出了系统对甘肃2014年度新申报科研项目查重分析的部分结果。
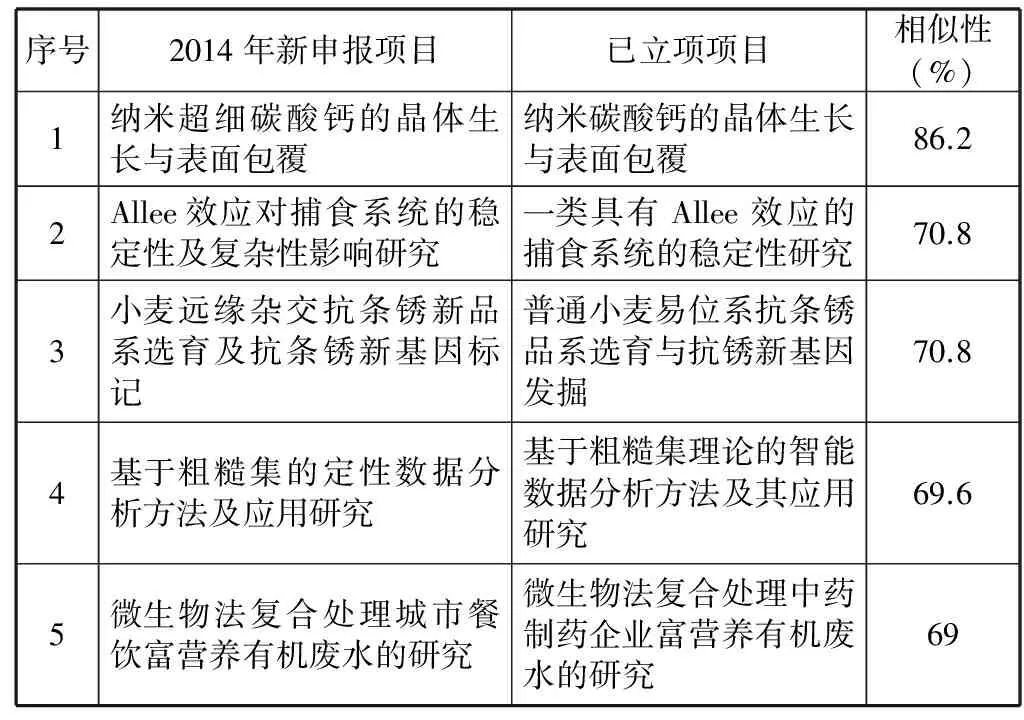
表1 同一申请者新申报项目与已立项项目相似性分析结果
表1是同一申请者重复申报已立项项目的案例中5个相似度最高的项目。这5个新申报项目的项目名称是对已立项项目的项目名称稍作改动,项目申报书中的内容也基本相同或相近似。
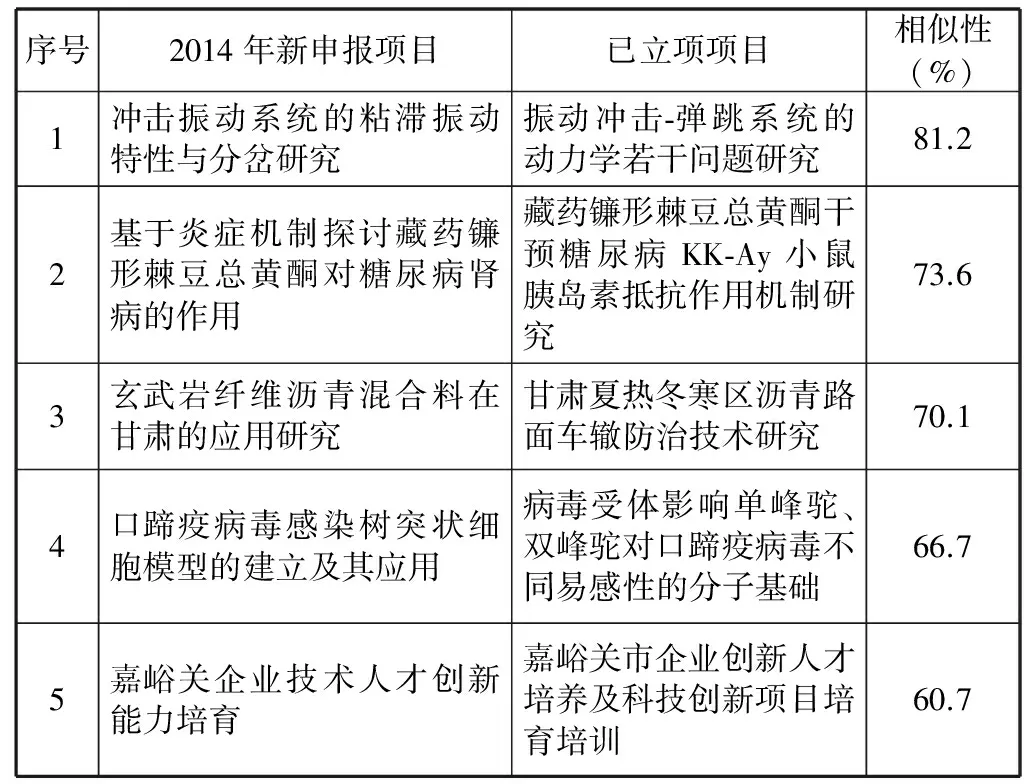
表2 同一申报单位新申报项目与已立项项目相似性分析结果
表2是同一申报单位重复申报已立项项目案例中相似度最高的5个项目。通过对全部新申报项目相似性分析结果统计得知,同一单位重复申报项目占全部重复申报项目的46%,占的比重最大。
表3记录了除同一申请者和同一单位的重复或相近似项目,这种情况主要是项目申请者对新申报项目的研究现状或创新性分析不足,而出现与已立项项目研究内容相近似的现象。

表3 新申报项目与已立项项目相似性分析结果(不包括同一申请者和同一单位的项目)
5 结 语
本文在深入研究自然语言处理、文本相似度计算等文本挖掘相关技术的基础上,设计实现了基于文本挖掘的科研项目管理辅助决策系统,实现了对科研项目申请书相似性综合分析和项目-评审专家匹配性分析,为科研项目科学立项提供了可靠的决策依据。该系统已在甘肃省科技厅投入运行,有效解决了科研项目重复申报、重复立项和相近似研究等问题,同时极大地减少了人工查重查新的工作量,提高了科研项目管理水平和科研资金使用效益。同时有助于形成严谨的科研作风,营造良好的创新环境。
目前系统仍有不足之处,如某些新申报项目是申请者在之前科研项目基础上做更深层次的研究,若系统对项目文本分词和文本特征项抽取不精确,则导致新申报项目和已立项项目相似度分析值较高,但实际并非重复申报或相近似研究。而如何进一步提高科研领域文本分词和文本抽取的准确性,都将成为本文下一步的重点研究工作。
[1] 杨洪涛,左舒文.国外科技评估发展新趋势及对上海的启示[J].科技管理研究,2014(22):15-17.
[2] 李建平,及俊川,吴登生,等.科研管理辅助决策模型研究:以ARP为例[J].科技促进发展,2012(10):18-22.
[3] 刘荫明,张福俊,刘谦.浅析科研管理之避免重复立项[J].科技管理研究,2010(21):198-200.
[4] Shengju Yang, Shaoting Shi, Jie Meng. Research and Safety Design on The Scientific Resarch Project Management System Based on J2EE[J]. Mechanical.Electronic and Information Technology Engineering, 2015, 743:633-640.
[5] 杨生举,赵昕晖.基于PHP+XML的人才信息管理系统实现与安全设计[J].计算机应用与软件,2012,29(2):221-223,257.
[6] 姜韶华.科研项目管理中的文本挖掘方法研究及应用[D].大连:大连理工大学,2006:63-68.
[7] 刘群,张华平,俞鸿魁,等.基于层叠隐马模型的汉语词法分析[J].计算机研究与发展, 2004,41(8):1421-1428.
[8] 张瑾.基于改进TF-IDF算法的情报关键词提取方法[J].情报杂志, 2014,33(4):153-155.
[9] 施侃晟,刘海涛,白英彩,等.余弦度量和适应度函数改进的聚类方法[J].电子科技大学学报,2013,42(4):621-624.
STUDY AND IMPLEMENTATION OF TEXT MINING-BASED ASSISTANT DECISION SUPPORT SYSTEM FOR SCIENTIFIC RESEARCH PROJECT MANAGEMENT
Meng JieYang ShengjuShi Shaoting
(Institute of Scientific and Technical Information of Gansu,Key Laboratory of Scientific and Technical EvaluationandMonitoringofGansu,Lanzhou730000,Gansu,China)
To solve the problems in scientific research project management including repetitive project declarations and approvals as well as matching the projects and assessment experts, by in-depth analysis of current status quo of assistant decision support for scientific research project management with literature analysis method, we presented a text mining-based solution of assistant decision support for scientific research project management. It adopts the ICTCLAS Chinese partition technology, the improved TF-IDF algorithm and the cosine correlation algorithm to determine the similarity between scientific research projects, the matching between projects and experts, and provides reliable decision support for scientific research project management. The paper introduces in detail the general system framework, key technologies and the system actualisation key steps. The solution has been applied in scientific research project management of Gansu province, and efficiently solves the problems listed above, raises the level of scientific research project management and the benefit of the use of scientific research funds.
Scientific research project managementAssistant decision support systemText miningSimilarity analysing
2015-06-24。甘肃省青年科技基金计划项目(1308R JYA100);甘肃省科技支撑计划项目(1304GKCA035)。蒙杰,工程师,主研领域:数据挖掘。杨生举,副研究员。施韶亭,研究员。
TP315
A
10.3969/j.issn.1000-386x.2016.09.006
猜你喜欢
数学物理学报(2022年5期)2022-10-09
江科学术研究(2022年3期)2022-09-26
校园英语·月末(2021年13期)2021-03-15
河北画报(2020年8期)2020-10-27
航天工业管理(2020年1期)2020-04-20
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
浙江大学学报(工学版)(2016年2期)2016-06-05
公民与法治(2016年4期)2016-05-17
西藏科技(2015年12期)2015-09-26
