
搜索引擎工作原理再探究
2016-11-16 14:35王姣徐海霞
电脑知识与技术 2016年25期
王姣+徐海霞


摘要:搜索引擎作为互联网发展中至关重要的一种应用,是获取网络信息资源的重要工具。搜索引擎是一个复杂的网络应用系统,本文从工具应用的角度,采用图表方式,介绍了搜索引擎的体系结构,分析其工作原理,重点探讨其核心部分——索引库的建立和搜索结果的排序。
关键词:搜索引擎;索引库;排序
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)25-0165-02
网页己经成为人们获取和发布信息的重要媒介。虽然网页给我们带来获取信息的方便,但如此海量的网络信息,很难用浏览的方式找到真正需要的信息。于是搜索引擎应运而生,并且成为Internet上非常重要的网络导航服务工具。
1 搜索引擎体系结构
搜索引擎基本结构一般包括:搜索器、索引器、检索器、用户接口等四个功能模块。
1)搜索器,也叫网络蜘蛛,是搜索引擎用来爬行和抓取网页的一个自动程序,在系统后台不停歇地在互联网各个节点爬行,在爬行过程中尽可能快的发现和抓取网页。
2)索引器。它的主要功能是理解搜索器所采集的网页信息,并从中抽取索引项。
3)检索器。其功能是快速查找文档,进行文档与查询的相关度评价,对要输出的结果进行排序。
4)用户接口。它为用户提供可视化的查询输入和结果输出的界面。
2 搜索引擎的工作原理
根据技术原理,可将多元化的搜索引擎归为三大主要类型,即全文搜索引擎、基于目录索引型(catalog)和元(meta)搜索引擎。其中,基于全文的robot搜索引擎原理具有典型性、普遍性。
robot的全文搜索引擎的技术基础文是全文检索技术。基于全文的robot搜索引擎实际上是全文检索技术的一种应用。一搜索引擎是架构在衡量搜索引擎的优劣标准体系范围之上的。衡量搜索引擎的评价指标,包括数据库模和内容、索引方法、检索功能、检索结果、用户界面等。随着互联网的深度发展,主流的搜索引擎设计更看重查询时间,能实现即时互动。
搜索引擎实际工作过程是极其繁杂的,图1所示是其工作过程简化图。便于梳理和理解,可将其整个工作过程视为三个部分:一是蜘蛛在互联网上爬行和抓取网页信息,并存入原始网页数据库;二是对原始网页数据库中的信息进行提取和组织,并建立索引库;三是根据用户输入的关键词,快速找到相关文档,并对找到的结果进行排序,并将查询结果返回给用户。下面对其工作原理做进一步分析。
1)网页抓取
Spider每遇到一个新文档,都要搜索其页面的链接网页。搜索引擎蜘蛛访问web页面的过程类似普通用户使用浏览器访问其页面,即 B/S模式。引擎蜘蛛先向页面提出访问请求,服务器接受其访问请求并返回HTML代码后,把获取的HTML代码存入原始页面数据库。搜索引擎使用多个蜘蛛分布爬行以提高爬行速度。搜索引擎的服务器遍布世界各地,每一台服务器都会派出多只蜘蛛同时去抓取网页。如何做到一个页面只访问一次,从而提高搜索引擎的工作效率。在抓取网页时,搜索引擎会建立两张不同的表,一张表记录已经访问过的网站,一张表记录没有访问过的网站。当蜘蛛抓取某个外部链接页面URL的时候,需把该网站的URL下载回来分析,当蜘蛛全部分析完这个URL后,将这个URL存入相应的表中,这时当另外的蜘蛛从其他的网站或页面又发现了这个URL时,它会对比看看已访问列表有没有,如果有,蜘蛛会自动丢弃该URL,不再访问。
2)预处理,建立索引
为了便于用户在数万亿级别以上的原始网页数据库中快速便捷地找到搜索结果,搜索引擎必须将spider抓取的原始web页面做预处理。
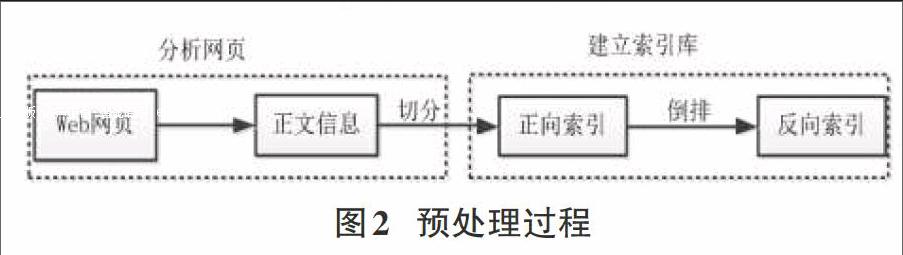
网页预处理最主要过程是为网页建立全文索引,之后开始分析网页,最后建立倒排文件(也称反向索引)。如图2所示。
Web页面分析有以下步骤:判断网页类型,衡量其重要程度,丰富程度,对超链接进行分析,分词,把重复网页去掉。
经过搜索引擎分析处理后,web网页已经不再是原始的网页页面,而是浓缩成能反映页面主题内容的、以词为单位的文档。数据索引中结构最复杂的是建立索引库,索引又分为文档索引和关键词索引。每个网页唯一的docID号是有文档索引分配的,每个wordID出现的次数、位置、大小格式都可以根据docID 号在网页中检索出来。最终形成wordID的数据列表。
倒排索引形成过程是这样的:搜索引擎用分词系统将文档自动切分成单词序列-对每个单词赋予唯一的单词编号-记录包含这个单词的文档。
倒排索引是最简单的,实用的倒排索引还需记载更多的信息。在单词对应的倒排列表除了记录文档编号之外,单词频率信息也被记录进去,便于以后计算查询和文档的相似度。
3)查询服务
在搜索引擎界面输入关键词,点击“搜索”按钮之后,搜索引擎程序开始对搜索词进行以下处理:分词处理、根据情况对整合搜索是否需要启动进行判断、找出错别字和拼写中出现的错误、把停止词去掉。接着搜索引擎程序便把包含搜索词的相关网页从索引数据库中找出,而且对网页进行排序,最后按照一定格式返回到“搜索”页面。
查询服务最核心的部分是搜索结果排序,其决定了搜索引擎的量好坏及用户满意度。实际搜索结果排序的因子很多,但最主要的因素之一是网页内容的相关度。影响相关性的主要因素包括如下五个方面。
(1)关键词常用程度。经过分词后的多个关键词,对整个搜索字符串的意义贡献并不相同。越常用的词对搜索词的意义贡献越小,越不常用的词对搜索词的意义贡献越大。常用词发展到一定极限就是停止词,对页面不产生任何影响。所以搜索引擎用的词加权系数高,常用词加权系数低,排名算法更多关注的是不常用的词。
(2)词频及密度。通常情况下,搜索词的密度和其在页面中出现的次数成正相关,次数越多,说明密度越大,页面与搜索词关系越密切。
(3)关键词位置及形式。关键词出现在比较重要的位置,如标题标签、黑体、H1等,说明页面与关键词越相关。在索引库的建立中提到的,页面关键词出现的格式和位置都被记录在索引库中。
(4)关键词距离。关键词被切分之后,如果匹配的出现,说明其与搜索词相关程度越大,当“搜索引擎”在页面上连续完整的出现或者“搜索”和“引擎”出现的时候距离比较近,都被认为其与搜索词相关。
(5)链接分析及页面权重。页面之间的链接和权重关系也影响关键词的相关性,其中最重要的是锚文字。页面有越多以搜索词为锚文字的导入链接,说明页面的相关性越强。链接分析还包括了链接源页面本身的主题、锚文字周围的文字等。
3 结尾语
基于全文检索技术在搜索引擎中应用至今,已经比较完善和成熟,但是随着人类知识的进步,查询用户将会对搜索引擎提出新的要求。基于内容特征的多媒体搜索引擎在多媒体通信需求下应运而生,它是直接对媒体内容特征和上下文语义环境进行的检索。同时,还有智能搜索引擎,是以人的自然语言技术为基础,对人脑中的知识有一定的理解与处理能力。智能搜索引擎的出现,将信息检索从目前基于关键词的层面提高到基于知识的层面。以上新型搜索引擎处于开发初期,普及应用尚待完善。
参考文献:
[1] 任鹏杰,陈竹敏,马军.一种综合语义和时效性意图的检索结果多样化方法[J].计算机学报,2015,38(10):76-91.
[2] 杨同峰,马军.图像的二维标注及在图像检索中的应用[J].模式识别与人工智能, 2013,26(1):70-75.
[3] 高玉良,张济强,白瑶.基于Lucene的多索引搜索的研究与应用[J].电脑知识与应用,2012(8):1471-75.
猜你喜欢
电子制作(2018年10期)2018-08-04
小朋友·快乐手工(2018年3期)2018-04-22
电子制作(2017年2期)2017-05-17
电子测试(2015年18期)2016-01-14
中国卫生(2015年12期)2015-11-10
小朋友·快乐手工(2015年1期)2015-03-13
警察技术(2015年3期)2015-02-27
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
计算机与网络(2014年7期)2014-03-25
技术经济与管理研究(2014年11期)2014-03-11
