
基于RL的遗传算法的制造车间生产调度研究
2016-11-16 15:17叶婉秋
电脑知识与技术 2016年25期
关键词:遗传算法
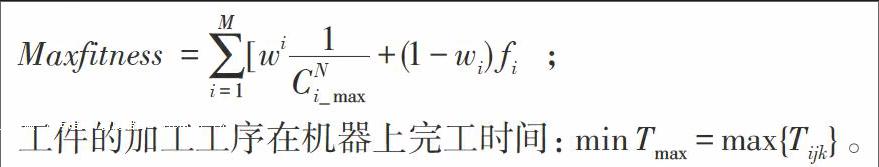

摘要:该文从工程应用角度给出了车间调度的问题建模和求解车间作业调度问题的标准遗传算法及优缺点,结合RL对动态的生产环境提出一种基于智能体RL的车间调度方法。该算法将遗传算法与RL相结合,根据弹性生产环境获取较优的交叉率,从而优化在线算法。
关键词:遗传算法;增强学习RL;交叉率;生产调度
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)25-0218-02
模具制造属于非重复性的离散生产过程,模具生产结构复杂、工艺制作繁琐。加工步骤及工时的不确定使得模具制造车间管理变得复杂。在制定车间作业计划时,由于没有样件的试制,有些问题会在生产过程中暴露出来。遇上突发事件如某台机器发生故障,相关的零件加工也要作相应的调整,前后相关的生产任务也要做修改,这就引发了动态的生产调度管理。要提高生产资源的利用率,对人力资源及现有生产设备如何按最优化的形式进行调配,使得对制造车间进行生产调度显得特别困难和重要。
1 模型建立
模具车间调度生产问题模型可以描述为:
(1)零件集:加工i个零件,需要机器j台,每零件有k道加工序列,在一个时间段一台机器只能加工一个零件的某道工序,并有零件加工顺序约束,每道工序可以占有若干台机器;
(2)机器集:因生产调度时有机床约束而不会出现人员约束,所以只给出工序的机器分配,车间内可用机床台,标号组成机床集;
(3)机器使用时间:每个零件使用每台机器的时间用T矩阵表示,tijk表示第i个零件在j台机器上加工第k道所消耗的时间,可以由n台机器加工第k道工序,第k道工序在n台机器上的加工时间随操作人员、设备性能的不同使加工时间有所不同,要表示加工时间值上下波动的不确定因素常采用三角数,最少时间、最大时间、最小时间 [1]。
则调度目标:零件i投入生产时间为(,,),完工期为 =,当零件的在内加工完成时用户满意度为1,反之为0;要用表示,当j台机床在加工第零件的第道工序时为1,反之为0;当第i工件第k道工序设定完工时间是,实际完成时间为,则满意度为设定完工时间的所属函数与完成期的所属函数交叉面积与完成期的所属函数面积的比[1],由满意度得到调度目标函数为:
工件的加工工序在机器上完工时间:。
2 遗传算法求解车间调度经验
遗传算法在求解车间作业问题时,将搜索空间中的参数转换成遗传空间中的染色体,通过一定规则进行逐步迭代产生新个体,新个体经交叉、变异和复制操作又产生新的个体,遗传算法的操作简单,全局搜索能力强,缺点是控制参数如个体规模、适应度指标、变异率、交叉率等较多,参数组合不同,搜索过程可能会出现多方面的功效,影响遗传算法行为和性能的关键因素是如何选择交叉概率和变异概率,交叉概率过小,会降低搜索过程,新个体结构产生不易;而交叉概率过大,加快产生新个体,也越有可能破坏遗传模式[1]。
要求出制造车间生产调度问题中遗传算法各参数的合适值是一件难事,必须通过反复试验才能获取当前最优值,因而这些参数如果能进行自适应动态实时的变动对遗传算法在解决生产调度问题上有着积极的作用。
3 智能RL模式
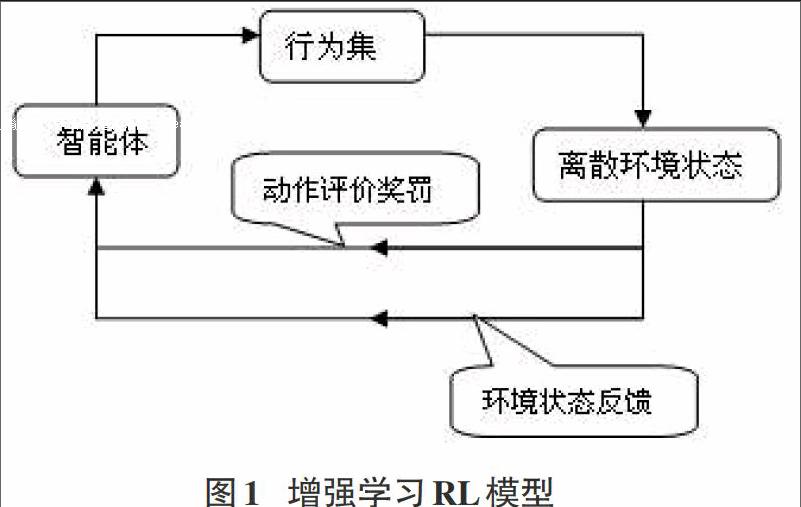
Muller提出的智能增强学习(Reinforcement Learning)是一种基于行为方法的半监督学习,它包括负责智能体之间信息交换的通讯层、完成指定任务的协作求解的协作层和接收命令来感知环境变化及改变环境任务的控制层[5]。增强学习RL的目的是动态调整参数从而实现信号强化,当一个动作行为作用于环境,RL将产生动作评价奖惩值合反馈环境状态给智能体,根据相关策略智能体选择下一个行为去影响环境状况,并对新环境做出调整,修改后的新环境状态所给出的信息和奖惩值重新影响智能体,RL中智能体依靠自身经历进行学习获取知识,从而改进行动方案来适应环境。基本的RL模型包括离散的状态信号反馈集合、行为集合、动作评价奖惩值和环境状态集合,如下图:
遗传算法中变异和交叉概率值的选择直接影响算法的收敛性,针对制造车间的工件加工顺序、机床调配和加工时间等生产调度问题,最佳的变异和交叉概率值得获取需要通过反复实验,当加工状况一旦变化最优概率值又要重新寻找,因而单一的遗传算法是不能满足实时动态的车间作业调度的决策过程,而且在调度规模较大时很难保证获取最优值的收敛速度[2],智能RL能根据行为和评价的环境获取知识进而改变行动方案来适应环境的能力可以有效地完成随机搜索,遗传算法如能结合RL可以提高获取最佳变异概率和交叉概率的速度。
4 基于RL的遗传算法的设计
增强学习RL在一个环境下的行为产生一个奖惩值,奖惩值越大,则该行为被采用的可能性越大[3],通过不断重复的学习积累奖惩值找到一个最优的变异概率和交叉概率的行为策略,这与人为调整概率值有很大的差异[4],因而作为一种解决复杂的车间动态作业生产调度问题,提出了结合增强学习与遗传算法的智能体自适应模型。
(1)强化学习RL决策过程
基于增强学习的智能体在遗传算法中起协调作用,它在增强学习决策过程中应包含行为集,环境状态集,反馈的信号映射集:,状态转移函数,值为:
独立的增强学习能感知其他智能体的行为,并从环境中得到反馈值Q,当智能体在状态选择行为,强化学习智能体在t时刻的奖惩值更新为:
处于环境状态时,增强学习RL对算法进行局部调整获取值,经过一轮自学习获取一个环境反馈值,算法在更新前的局部RL奖惩值简化为:
在结束局部RL更新并保存该+1,一轮算法结束获取全局奖惩值,保留该次学习所得值后对染色体的交叉变异率进行一次更新。
当增强学习协调作用于遗传算法中染色体交叉和变异时,RL能根据染色体的当前环境状态做出概率调整,在状态下,RL的行为会就当前环境状态及先前的奖惩值去选择一个值,被选中的合适的交叉和变异率可能性越大,过小或过大概率值被选中的可能性也越小,获取合适的交叉和变异率并得到一个状态转移函数值,根据这个函数值得出奖惩值;感知一次学习后记下遗传算法的交叉和变异率,奖惩值大的交叉和变异率在下一次行为中更有可能被选中的。由于奖惩值对交叉和变异率有明显的优化作用,形成正向反馈后的奖罚值使遗传算法的交叉和变异率最后落实到较优值上,个体就更好的遗传了父串的染色体,在算法更新时对该染色体结构中交叉及变异的适应度函数奖惩值也会更大,明显提高遗传算法的收敛速度[5]。
RL要获取最佳行为必须不断探索环境状态,如何判断已最佳交叉变异率是决定重新探索还是利用已知的最佳值的关键点。智能增强学习体可参照行为预测设定值来减少学习过程中考虑的因素而缩短学习过程,避免陷入次优行为找不到全局最佳交叉变异率。在开始智能学习时,随机获取交叉变异率去探索第一轮新值,RL将奖惩值与历史记录比较,保存较优值淘汰较劣值,经过多次增强学习探索,最佳的概率值得以保留,已证明智能增强学习的收敛与行为选择策略无关,设定行为预测值不影响RL的过程。
(2)智能体RL实现的流程
为快速求取普通遗传算法染色体中交叉变异率的最优选择,结合普通遗传算法与智能体增强学习RL,智能体RL的自我学习能够就状态、行为、学习率等的情况做出决策,对遗传算法解决车间调度问题编码中的染色体进行个体种群初始化,求取个体适应度函数值并判断是否终止遗传算法,如果终止条件不符合,则根据适应度函数值对染色体进行局部遗传算子的交换和变异,奖惩初始值0,RL探索学习交叉变异率的进程中,当前奖惩值比较之前值并保留局部较优值,一次学习结束更新交叉变异率,记录全局奖惩值同时进行全局优化探索学习,通过反复学习获取经验,保留良好的奖惩值实现染色体的交叉变异概率的最佳选择,实现作业车间的智能调度的算法流程如图示:
交叉和变异率能随智能增强学习机制的奖惩值自动改变,奖惩值较大时交叉和变异概率增加,跳出局部最优,奖惩值较小时交叉和变异了降低,有利保留良好种群,由于RL是一种动态即时智能学习,随着智能体学习的推进,保留的交叉变异率值逐渐良好,染色体的种群逐渐优化,因此智能RL与遗传算法结合在保证染色体编码多样性的同时也保证了遗传算法的收敛特性,当适应度函数值不再有明显改进,智能增强学习结束,最优解求出算法终止。
5 总结
模具制造车间生产调度问题在企业中普遍存在,如何优化对提高企业竞争力有积极的影响,本文结合智能RL与遗传算法,建立了车间作业调度模型的在线调度,帮助企业合理安排工作进程。仿真实验证明该算法能有效提高企业资源的优化分配,合理安排加工任务,在动态的生产状况下能快速智能的做调整。
参考文献:
[1] 王万良,吴启迪.生产调度智能算法及其机器应用[M].科学出版社,2007.
[2] 宋毅. 基于遗传算法的生产调度方法及其软件实现[D].杭州:浙江工业大学,2003.
[3] 王雪辉,李世杰,张玉芝.Multi-Agent 技术在车间调度中的应用[J].河北工业大学学报,2005,34(2):106-109.
[4] 陈文,王时龙,黄河.基于多Agent的蚁群算法在车间动态调度中的应用研究[J].组合机床与自动化加工技术,2004.
[5] 李琼,郭御风,蒋艳凰.基于强化学习的智能I/O调度算法[J]. 计算机工程与科学, 2010, 32(7).
[6] 叶婉秋.基于智能强化学习的遗传算法研究[J].电脑学习,2010(4).
猜你喜欢
测控技术(2018年2期)2018-12-09
石油地球物理勘探(2017年2期)2017-11-23
池州学院学报(2017年3期)2017-10-16
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
水利规划与设计(2016年9期)2017-01-15
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
现代计算机(2016年34期)2016-02-28
舰船科学技术(2016年1期)2016-02-27
智能系统学报(2015年4期)2015-12-27
