
基于模糊聚类和模糊模式识别的数字图书馆个性化推荐研究
2016-11-19 16:22王敏嵇绍春
现代情报 2016年4期
王敏 嵇绍春


〔摘 要〕为提高图书馆个性化推荐的效果,采用模糊聚类和模糊识别技术建立数字图书馆的个性化推荐系统。通过分析用户的信息素质、兴趣爱好、网络和电子资源检索情况,对读者进行数学模糊聚类分析,确定最佳阈值λ,得到最佳聚类。根据个体用户的基本情况进行模糊识别,由识别结果的归属给出针对当前用户的个性化推荐。实验结果表明,在模糊聚类与模糊识别基础上的个性化推荐方案是可行的和有效的,为创新数字图书馆个性化服务提供了一种新的方法。
〔关键词〕数字图书馆;个性化;推荐系统;模糊聚类;模糊识别
DOI:10.3969/j.issn.1008-0821.2016.04.010
〔中图分类号〕G251 〔文献标识码〕A 〔文章编号〕1008-0821(2016)04-0052-05
〔Abstract〕In order to improve the effect of library personalized recommendation,personalized recommendation system of digital library is designed based on fuzzy clustering and fuzzy pattern recognition.The paper analyzed the users information literacy,discipline background,interests,electronic resources retrieval and history information.Then the readers were classified by using fuzzy clustering.The best threshold λ is determined and the optimal clustering is obtained.According to the basic situation of individual user,the paper used fuzzy pattern recognition to give the personalized recommendation for the current user.From the experiment result,it showed that the proposed approach is feasible and effective,and it provided a new way for the innovation of digital library personalized service.
〔Key words〕digital library;personalized;recommendation system;fuzzy clustering;fuzzy recognition
数字图书馆的个性化推荐是指通过有效利用不同层次、不同类别的数据资源,向不同兴趣特点、专业背景的读者推荐其期待看的信息资源,以满足不同用户的个性化需求。数字图书馆的个性化推荐系统已成为当前提高数字图书馆的服务质量、效率和信息资源利用水平的一种重要工具[1]。目前,很多高校也以不同的形式向其读者提供个性化的服务信息,如康奈尔大学图书馆的MyLibrary[2]、Stanford大学数字图书馆Fab系统[3]、NEC研究院的CiteSeer系统[4]等。图书馆构建一个有效的个性化信息推荐系统,快速高效地从海量的数据和信息中获取有关知识,提高资源检索和推荐的智能水平,满足各类用户不同的个性化需求,已成为数字图书馆领域研究的一项重要内容[5-11]。个性化推荐系统的核心是利用目标用户兴趣、专业背景、信息素质的相似程度产生对用户的个性化推荐。数学上的模糊聚类方法具有模糊特性,可以更好地体现用户兴趣的多样性特点,适合数字图书馆用户的分类需求。
本文提出一种基于模糊聚类和模糊识别相结合的推荐技术,通过对用户全体进行聚类分析并统计每类群体的文献资源使用及浏览记录,得到最佳聚类中各类别用户的文献偏好,建立最佳分类的用户推荐模型库。在此基础上,对于目标用户,根据其注册信息、图书借阅记录、用户定制信息、Web 服务器日志等情况,通过模糊识别的方式归属在最佳聚类中的一类,为其推荐相应类别的图书。我们将这种个性化推荐模式应用于淮阴工学院图书馆,实践证明基于模糊聚类与模糊识别模式的个性化推荐系统是一个比较成功的推荐系统。
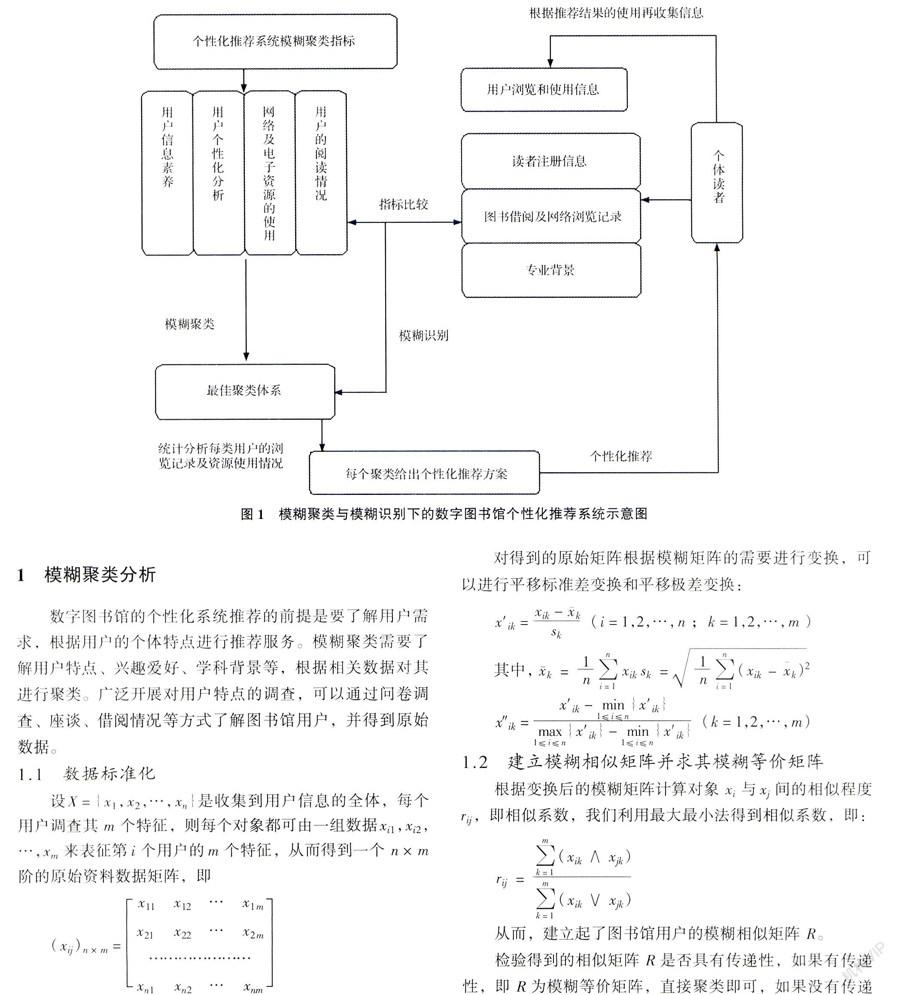
模糊聚类分析是模糊集与传统的聚类分析相结合的一种分析方法,常用的模糊聚类方法有:基于模糊等价矩阵的聚类方法、基于模糊相似矩阵的直接聚类法、基于目标函数的模糊聚类分析法[12-14]。近年来,模糊聚类分析在图书馆中也得到了应用:盘美英利用模糊聚类分析法对图书馆绩效进行评价[15],秦小铁等人利用模糊聚类分析提供了图书馆的选书决策方法[16]。我们利用等价矩阵的聚类方法对图书馆的用户进行模糊聚类分析,根据最佳聚类中的每类用户的浏览、借阅历史及电子资源的使用情况给出个性化推荐。针对目标用户的个体情况进行模糊识别,由识别结果给出推荐方案。具体思路如图1。
1 模糊聚类分析
数字图书馆的个性化系统推荐的前提是要了解用户需求,根据用户的个体特点进行推荐服务。模糊聚类需要了解用户特点、兴趣爱好、学科背景等,根据相关数据对其进行聚类。广泛开展对用户特点的调查,可以通过问卷调查、座谈、借阅情况等方式了解图书馆用户,并得到原始数据。
1.1 数据标准化
设X={x1,x2,…,xn}是收集到用户信息的全体,每个用户调查其m个特征,则每个对象都可由一组数据xi1,xi2,…,xm来表征第i个用户的m个特征,从而得到一个n×m阶的原始资料数据矩阵,即
(xij)n×m=x11x12…x1m
x21x22…x2m
xn1xn2…xnm
对得到的原始矩阵根据模糊矩阵的需要进行变换,可以进行平移标准差变换和平移极差变换:
x′ik=xik-ksk(i=1,2,…,n;k=1,2,…,m)
其中,k=1n∑ni=1xik?"sk=1n∑ni=1(xik-k)2
x″ik=x′ik-min1≤i≤n{x′ik}max1≤i≤n{x′ik}-min1≤i≤n{x′ik}?"(k=1,2,…,m)
1.2 建立模糊相似矩阵并求其模糊等价矩阵
根据变换后的模糊矩阵计算对象xi与xj间的相似程度rij,即相似系数,我们利用最大最小法得到相似系数,即:
rij=∑mk=1(xik∧xjk)∑mk=1(xik∨xjk)
从而,建立起了图书馆用户的模糊相似矩阵R。
检验得到的相似矩阵R是否具有传递性,如果有传递性,即R为模糊等价矩阵,直接聚类即可,如果没有传递性,为了进行聚类,我们要求其等价矩阵,即通过逐次平方求其传递闭包t(R),由其性质知t(R)为模糊等价矩阵。对t(R)再取适当的λ∈[0,1],由λ截矩阵Rλ便可得到动态聚类。
1.3 确定最佳阈值λ
设P为分类方案数,显然P≤n。设r为对应于λ值的类数,ni为第i类元素的个数,记ik=1ni∑nij=1xjk,k=1,2,…,m,为第i类元素的第k个特征的平均值,记k=1n∑nj=1xjk,k=1,2,…,m,为全体样本第k个特征的平均值。
引入F统计量:
F=∑ri=1ni∑mk=1(ik-k)2/(r-1)∑ri=1∑ni〖〗j=1∑mk=1(xik-jk)2/(n-r)F(r-1,n-r)
它服从自由度为r-1、n-r的F分布,其分子表征类与类间的距离,分母表征类内元素距离,因此F值越大,说明类与类间的距离越大,则分类就越好[17]。
对给定的信度α,查F临界值表得到Fα,然后将各F值与Fα作比较。如果F>Fα,根据数理统计方差理论,知类间差异显著,说明分类比较合理;在满足F>Fα的所有情况中,取F-Fα最大者的F所对应的λ作为最佳λ值,其所对应的分类即为最佳分类。
根据对读者的分析,本文给出可能影响读者使用图书馆的相关因素,根据相关因素进行读者的模糊聚类分析,聚类指标如表1。
表1中的各项指标值为7度量值,其中1最差,7最好。根据对读者的最佳模糊聚类中每一读者的历史借阅、浏览和查找历史、电子资源的使用和下载情况及在问卷中读者感兴趣图书和资源的反馈情况,统计并分析给出每个聚类的读者最佳推荐图书及电子资源类型。
2 模糊识别
在模糊识别的过程中,我们利用择近原则,设{A1,A2,…,An}是论域U上的n个模糊集A1,A2,…,An构成一个标准模型库,B为待识别模型。若存在i∈{1,2,…,n},使得σ0(Ai,B)=max1≤j≤nσ0(Aj,B),则认为B与Ai最贴近,应把B归为模型Ai。其中σ0(A,B)=12[AB+(1-AB)],这里AB=∨x∈U(A(x)∧B(x))和AB=∧x∈U(A(x)∨B(x))分别为A与B的内积和外积。
对每个具体读者根据其注册时提供的基本信息及其借阅、浏览和下载情况自动进行模糊识别,根据识别结果的类别进行数字图书馆个性化的读者推荐服务。对于个体用户进行模糊识别时,由于收集到的信息可能会缺项,所以对缺项的部分可以暂时不去考虑,根据收集到的相关信息进行识别,给出推荐方案,根据推荐效果情况的收集可以重新调整识别信息,直到推荐效果满意为止。
3 实验结果分析
以淮阴工学院图书馆为例,我们通过对读者的聚类分析和模糊识别,对数字图书馆个性化推荐方案进行了模拟测试。我们采用问卷调查形式收集原始的聚类数据,发放问卷1 000份,发放范围覆盖淮阴工学院全部13个院系的4个年级、在校硕士研究生、教师及继续教育学院的成人大学生,其范围覆盖了所有可能用户,收到的数据有普及性和代表性,共收回问卷982份,其中有效问卷980份。问卷调查中除了上述50个聚类指标的调查,另外还添加了“您的年级和专业”、“感兴趣和喜欢阅读的图书类别”、“喜欢或常用的电子资源及数据库”3个问题。调查结束后,我们通过图书馆的后台,调出每个用户的借阅历史,浏览和下载电子资源情况的记录,为了便于得到最佳聚类后,详细的了解该类群用户的喜好及特点,从而给出各类别的用户的推荐目录。
根据用户给出的资料信息得到聚类的原始数据(xij)980×50。利用数学工具Matlab对收集到的数据进行平移标准差变换和平移极差变换得到模糊矩阵(x″ij)980×50
x′ik=xik-ksk(i=1,2,…,980;k=1,2,…,50)
其中,k=1980∑980i=1xik,?"sk=1980∑980i=1(xik-k)2
x″ik=x′ik-min1≤i≤980{x′ik}max1≤i≤980{x′ik}-min1≤i≤980{x′ik}?"(k=1,2,…,50)
利用最大最小法建立起了980×980模糊相似矩阵R。
利用Matlab计算模糊相似矩阵R的传递闭包t(R),得到模糊等价矩阵t(R)。对t(R)再取适当的λ∈[0,1],由λ截矩阵Rλ便可得到动态聚类。
通过对F统计量的运算,对给定的信度α=0.05,查F临界值表得到Fα,得到表2:
通过对t(R)的聚类分析,可以看出淮阴工学院图书馆读者用户的调查中最佳聚类结果为50类。从最佳聚类结果,得到教师和硕士研究生其分类基本上是按照学科聚类,其借阅和浏览情况也大多数与自己的学科背景相关,所以对教师及研究生的推荐目录基本上可以结合问卷调查中用户感兴趣的图书及资源并请相关专业的学者综合制定。本科生群体的用户,从分类结果看到,聚类因素中学科、兴趣、社会实践、人生观等对其分类均有影响。例如在理科学生中有近1/4的学生用户感兴趣的资源非专业信息,这部分读者大致又分为两类:一类趋向于文学、历史类图书资源;一类取向于管理和计算机类资源。工科类学生读者的情况更为复杂,根据统计结果工科类学生的分类高达32类,几乎每类中都有来自工科不同专业的学生用户群体。我们统计在问卷调查中每个聚类感兴趣的图书情况及读者的历史借阅、浏览和查找历史、电子资源的使用和下载情况给出最佳推荐书目和资源。在实践过程中,我们利用Matlab对大量实验数据进行了处理和分析,这是一个较为困难和具体挑战性的工作,它对获取准确聚类结果又是必需的。
选取淮阴工学院的在校本科生、硕士研究生、教师100名,利用择近原则对其模糊识别并推荐相应的书目和电子资源,跟踪调查其对推荐结果的满意情况。实验证明通过模糊识别的个性化推荐系统得到用户的认可,其中56名用户对最佳聚类推荐的结果满意并使用了我们推荐的资源和图书,32名用户经过再次收集相关的信息资料,重新调整识别信息后对推荐结果给出满意答复,12名用户,经过三次识别分析后,对其推荐结果表示满意。实验结果表明本文提出的基于模糊聚类和模糊识别的数字图书馆个性化推荐系统方案是可行和有效的。
4 结 语
利用模糊聚类分析方法对图书馆用户的资源使用情况进行聚类,其先决条件是收集并得到大量的用户资源数据信息,并进行最佳聚类的分析整理。实践证明,基于模糊聚类和模糊识别数字图书馆的个性化推荐系统的推荐结果是得到用户认可的。利用推荐系统提供个性化信息服务,是数字图书馆发展的必然趋势,也是目前研究的一个热点问题。本文提出的个性化推荐系统方案,在提高数字图书馆个性化服务水平方面做了有益的探索与尝试。
参考文献
[1]徐伟芬.基于模糊聚类的数字图书馆个性化推荐系统方案设计[J].价值工程,2013,32(6):174-176.
[2]Balabanovic M,Shoham Y.Fab:Content-based,Collaborative Recommendation[J].Communications of the ACM,2007,40(3):6672.
[3]Rucker J,Polance M J.Siteseer:Personalized Navigation for the Web[J].Communications of the ACM,1997,40(3):7375.
[4]Giles L,Bollacker K,Lawrence S.CiteSeer:An Automatic Citation Indexing System[J].In:Proceedings of the 3rd ACM Conference on Digital Libraries.1998:89-98.
[5]刘剑涛.个性化推荐系统中用户多态聚类研究[J].现代图书情报技术,2012,28(2):18-22.
[6]黄晓斌.基于协同过滤的数字图书馆推荐系统研究[J].大学图书馆学报,2006,(1):53-57.
[7]张红燕.高校图书馆新书推荐系统的研究与实现[J].大学图书馆学报,2013,(5):106-113.
[8]唐秋鸿,曹红兵,唐小新,等.高校图书馆个性化专题推荐研究[J].图书馆学研究,2012,(13):53-58,24.
[9]何金晶.个性化信息推荐服务中用户潜在兴趣挖掘研究[J].现代情报,2013,33(4):8-11,16.
[10]杨亮,雷智雁.大数据环境下图书馆个性化服务研究[J].现代情报,2014,34(4):74-77.
[11]李微娜,马小琪,冯艳光.基于MADM方法的个性化推荐研究[J].现代情报,2011,31(4):20-22,25.
[12]秦如新,田英杰,陈静,等.双聚类的关联规则挖掘方法[J].北京工业大学学报,2009,(4):561-565.
[13]杜静,敖富江,杨学军,等.基于模糊聚类分析的构件并行技术研究[J].计算机学报,2007,30(11):1939-1946.
[14]CHATZIS S,VARVARIGOU T.Factor analysis latent subspace modeling and robust fuzzy clustering using t-distributions[J].IEEE Transactions on Fuzzy Systems,2009,17(3):505-517.
[15]盘美英.模糊聚类分析方法在图书馆绩效评估中的应用[J].现代情报,2008,28(10):210-213,216.
[16]秦小铁,郑辉昌.基于模糊聚类分析的图书馆选书决策方法[J].重庆科技学院学报:社会科学版,2011,(11):165-166.
[17]梁保松,曹殿立.模糊数学及其应用[M].北京,科学出版社,2007.
(本文责任编辑:孙国雷)
猜你喜欢
新闻传播(2018年12期)2018-09-19
计算机应用(2016年12期)2017-01-13
汽车与新动力(2016年6期)2017-01-04
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年24期)2016-11-14
企业导报(2016年12期)2016-06-17
中国卫生(2015年1期)2015-01-22
