
一种高速模(2n-2p-1)乘法器的设计
2016-12-03 05:12张清宇
电子技术应用 2016年11期
张清宇,李 磊
(电子科技大学 电子科学技术研究院,四川 成都 611731)
一种高速模(2n-2p-1)乘法器的设计
张清宇,李 磊
(电子科技大学 电子科学技术研究院,四川 成都 611731)
结合余数系统以及模乘法器本身的特点,一种高速的模(2n-2p-1)乘法器被提出。得益于剩余范围的扩展和新型的部分积压缩树的采用,该设计相较于传统的模乘法器在关键路径上减少了一个长度为2n的加法器且避免了此类 Booth编码模乘法器中复杂的负数修正问题。在90 nm工艺下的综合结果表明,该模乘(2n-2p-1)乘法器相较当前的模(2n-2p-1)乘法器有10.4%到49%的延迟性能提升。
余数系统;剩余范围扩展;部分积压缩树
0 引言
余数系统作为一种数值表征系统,凭借其在并行计算、数字信号处理以及大规模集成电路等领域的潜在应用前景,受到了广泛的研究。近些年来,随着冗余余数系统(Redundant Residue Number System,RRNS)及其相关算法在纠错领域的不断应用,余数基的选择和构建变得愈发重要。模乘单元的性能对于一种基的选择和构建起到了关键的作用,如何提供更多形式的高速模乘法器成为了余数系统发展的关键问题之一。
2n-2p±1形式的基可以构建出高平衡度的余数基,是RRNS中最常用的一种基。其对应的乘法器也已经被广泛的研究。在文献[4]中,一种通用形式的模乘法器被提出,虽然可以用来构造模(2n-2p-1)乘法器,但是效果不佳。在文献[5]中,我们提出了一种剩余范围的扩展方法,通过这种方法,在没有开销的情况下将剩余范围从[0,2n-2p-1]扩展到[0,2n-1],为化简模(2n-2p-1)乘法器的结构提供了便利。在文献[6,7]中,基于Booth编码的模(2n-2p-1)乘法器被提出,但是由于 Booth编码引入了负数,而负数在模乘法器中的修正问题会造成较大的性能损失。文献[8]提出了一种高效且利于 EDA实现的TDM压缩树(Three Dimensional Minimization,TDM)算法。考虑到余数系统中乘法器是无符号的且位数不高(通常小于32),采用非Booth编码的TDM压缩树结构反而可以起到很好的效果。本文提出的模(2n-2p-1)乘法器沿用了剩余范围的扩展方法,采用 TDM压缩树解决[6,7]中出现的负数修正问题,取得了较大的性能提升。
本文首先介绍TDM压缩树及剩余范围的扩展方法,然后提出高速模(2n-2p-1)乘法器的结构并给出结构图,最后进行分析对比。
1 TDM压缩树算法
在全加器中,不同输入端到不同输出端的延迟是不同的。文献[8]中提出TDM算法可以将压缩树中不同全加器的最长延迟路径和最短延迟路径相连接。这种算法可以很方便地用脚本实现,具有通用性。为了解决布局布线的不规整的问题,TDM算法支持将全加器替换为4:2或者其他形式的压缩器,以进一步提升速度。最终通过TDM压缩树可以将部分积(Partial Product,PP)压缩至两行。需要注意的是,虽然相较文献[6,7]中采用的Booth编码的混合型压缩结构,TDM压缩树会产生较大的面积,但是考虑到Booth编码引入负数所带来的复杂修正问题,这些面积会被抵消且总的延迟更小。
2 剩余范围的扩展方法
对于任意整数 X,有〈X〉2n-2p-1=x,x∈[0,2n-2p-1]。也就是说,模(2n-2p-1)的剩余范围是[0,2n-2p-1]。为了化简运算,可以将剩余范围扩展到[0,2n-1]。因为有〈2n-2p-1+i〉2n-2p-1=i,i∈[1,2p+1],这样就可以使用2n-2p-1+i在乘法器中来表示 i。图1所示的 RNS系统中,这种扩展并不会产生计算错误,并且很容易在后向转换中进行修正。通过使用这种扩展方法,可以化简模(2n-2p-1)乘法器的结构,避免了重复将[2n-2p-1,2n-1]修正到[1,2p]所带来的浪费。
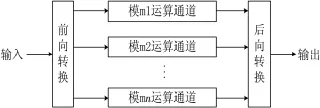
图1 RNS系统框图
3 高速模(2n-2p-1)乘法器的结构
假设A[n-1:0]是乘数,B[n-1:0]是被乘数,A[n-1:0]× B[n-1:0]所产生的 PP被 TDM压缩树压缩至两列,分别为 P0[2n-2:0],P1[2n-2:0]。模(2n-2p-1)乘法器可以被表示为:
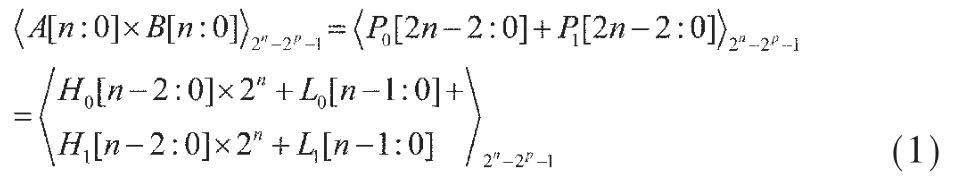
其中H0[n-2:0],L0[n-1:0]分别代表 P0[2n-2:0]的高n-1位和低n位。H1[n-2:0],L1[n-1:0]分别代表P1[2n-2:0]的高n-1位和低n位。根据文献[5]中模(2n-2p-1)乘法器的性质,有:
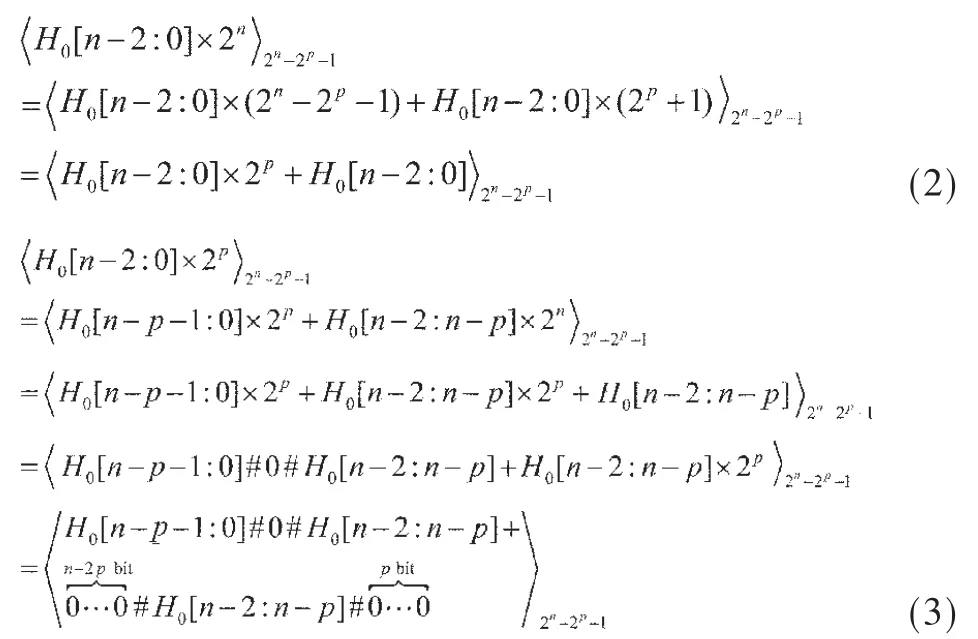
其中符号#用来连接各比特位。将式(2)、式(3)带入式(1),可以进一步得到:
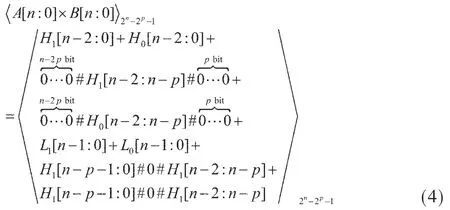
将式(4)中前四项和后四项分别两个(n-1)位的 CSA和两个n位的CSA进行处理,可以得到:

其中 MH[n-1:0],ML[n-1:0]为两个(n-1)位的 CSA的输出,NH[n:0],NL[n:0]为两个(n-1)位的 CSA的输出。NH[n:0]和NL[n:0]可以进一步折叠:
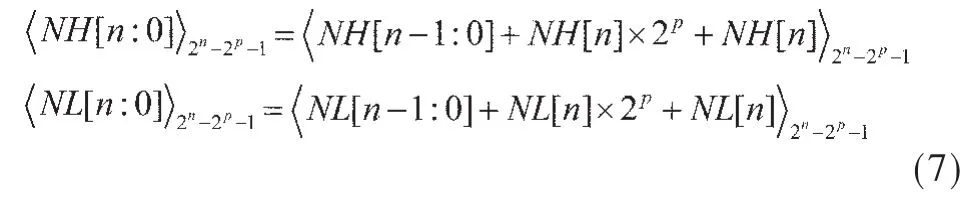
将四个n位的部分项MH[n-1:0],ML[n-1:0],NH[n-1:0]以及 ML[n-1:0]继续用两个 n位 CSA进行处理,得到:
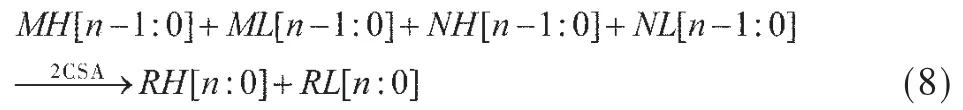
其中RH[n:0]和 RL[n:0]为这两个n位CSA产生的输出且可以继续折叠:
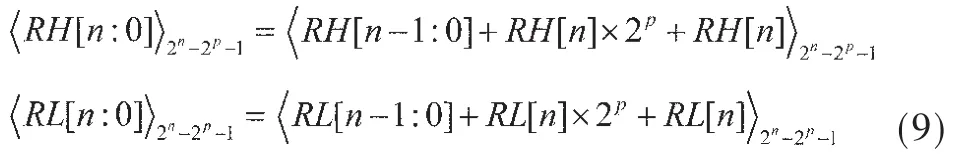
令 C[2:0]=NH[n]+NL[n]+RH[n]+RL[n],式(9)产生的四个部分项可以进一步用一个n位CSA压缩:
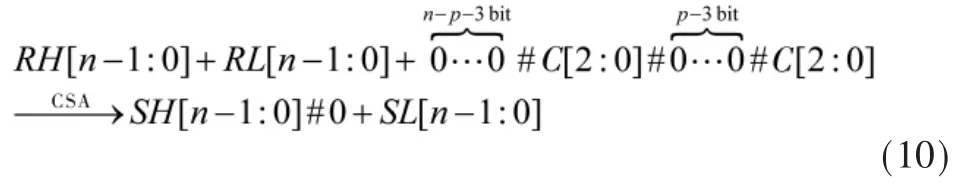
将得到的SH[n-1:0]修正为:
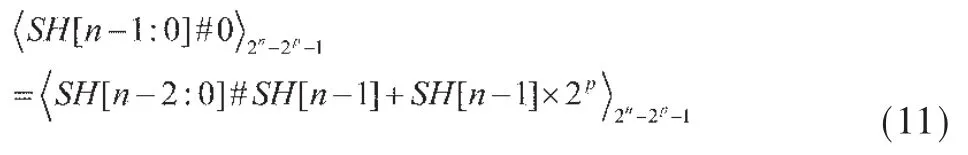
将 SH[n-2:0]#SH[n-1]和 SL[n-1:0]用一个 n位二进制加法器相加得到R[n:0]:

继续对R[n:0]折叠:
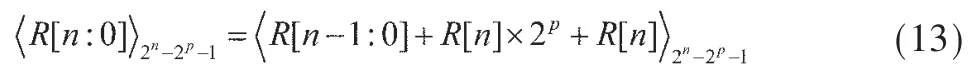
最终,得到最后结果Y[n-1:0]:
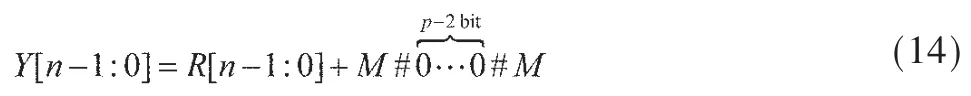
其中M=R[n]+SH[n-1]。实验证明当n≥2p时,结果不会溢出。整体结构如图2所示,在关键路径上包含1个TDM压缩树,5个CSA,以及2个n位的二进制加法器。
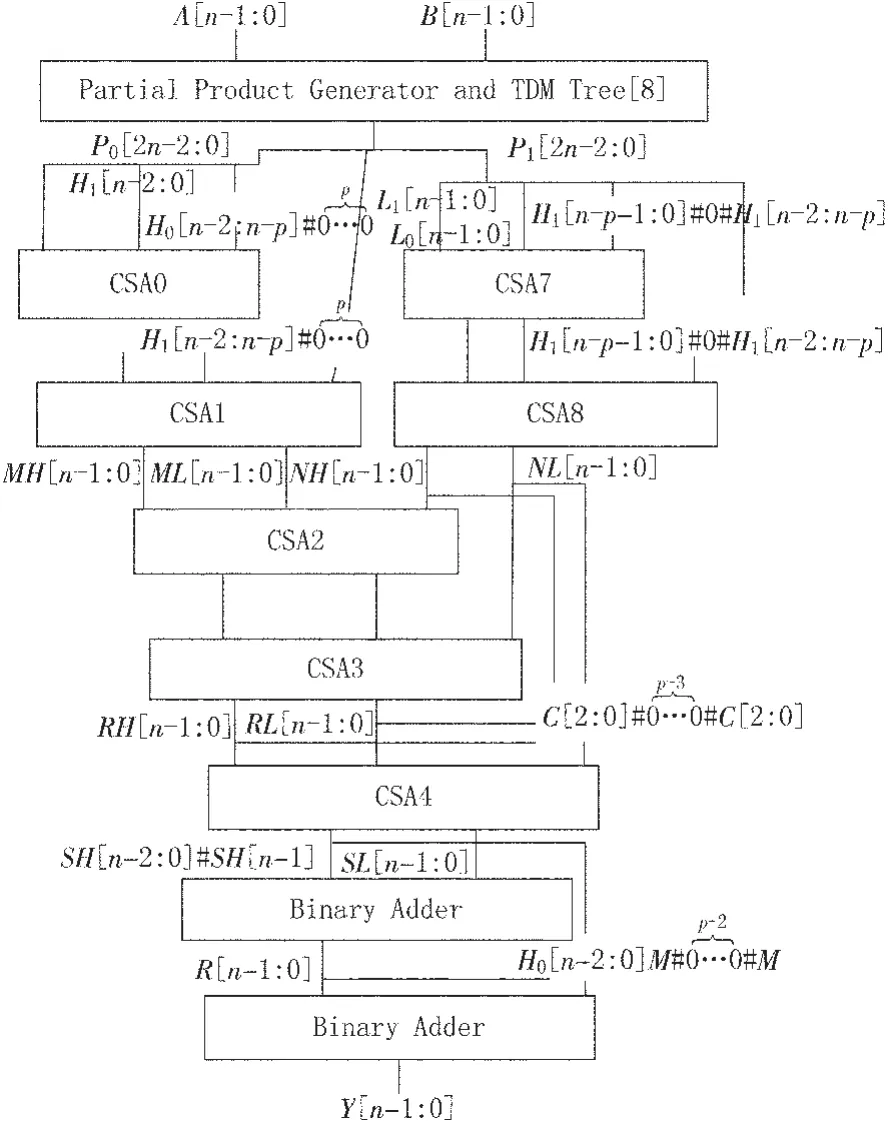
图2 模(2n-2p-1)乘法器的结构
4 分析与比较
我们将本文提出的模(2n-2p-1)乘法器和文献[4,5,6,7]中的模乘法器进行对比分析。所有的模乘法器都采用Verilog硬件描述语言进行建模,并采用Design Complier在90 nm COMS工艺下进行综合。
综合结果表明,相较于文献[4]中的设计,本设计的平均延迟降低49%,平均面积降低了 5.1%。与文献[5]中的设计相比,本设计的平均延迟降低了 10.4%,但是平均面积提升了 4.5%。和文献[6]相比,本设计平均延迟降低了23.2%而平均面积降低了26.1%。与文献[7]进行比较,本设计平均延迟降低了 10.3%,平均面积提升了1.3%。
文献[5,7]中的两种设计是两种典型的高效模(2n-2p-1)乘法器,下面将着重对本设计以及文献[5,7]进行静态分析。设计[5,7]都包含一个 Booth编码的压缩树,而本设计包含一个非 Booth的TDM压缩树,这两种结构的延迟相差不大。比较重点放在产生两个2n-1位PP后的路径,我们称之为关键路径。文献[5]的关键路径包含1个2n位二进制加法器,1个CSA,3个n位二进制加法器。文献[7]的关键路径包含 6个 CSA和三个二进制加法器。与文献[5]相比,本设计在关键路径上使用四个CSA替代了一个2n位的大加法器和一个n位的小加法器。与文献[7]相比,本设计在关键路径上减少了一个CSA和一个2n位加法器。采用文献[4]中的单位门评估方法,具体结果如表1所示。
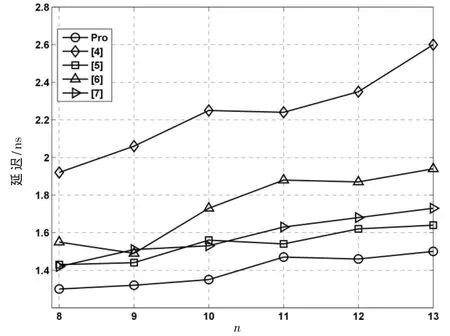
图3 p=3时模(2n-2p-1)乘法器的延迟性能
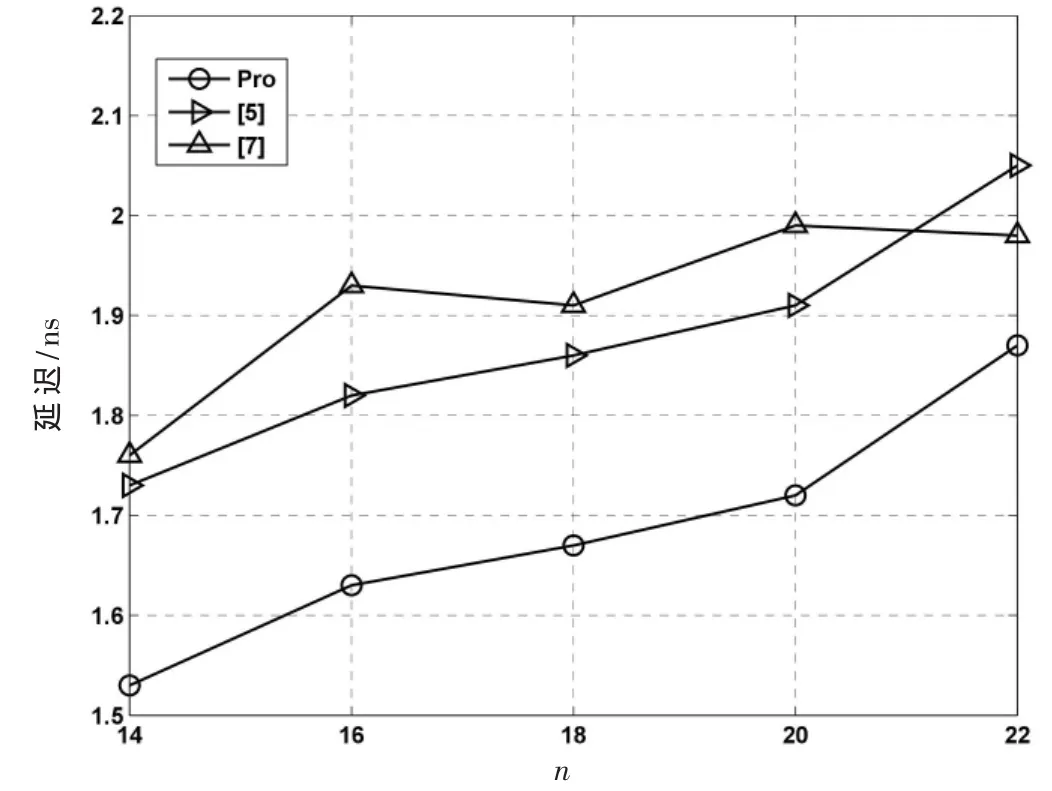
图4 p=4时模(2n-2p-1)乘法器的延迟性能

表1 静态时序分析
5 结论
得益于剩余范围的扩展和TDM压缩树的使用,本设计没有使用复杂的模加法器且避免了负数修正问题。相较于当前的模(2n-2p-1)乘法器有较大的延迟性能提升,是目前已知的延迟性能最佳的模(2n-2p-1)乘法器。
[1]马上,胡剑浩.余数系统在 VLSI设计中的基本问题研究与进展[C].中国通信集成电路技术与应用研讨会,2006.
[2]李磊,胡剑浩,敖思远.高速Booth编码模(2^n—1)乘法器的设计[J].微电子学与计算机,2011,28(11):191-193.
[3]胡剑浩,唐青.面向低电压供电数字电路的容错计算系统结构设计[J].电子科技大学学报,2013(6):831-835.
[4]HIASAT A A.New efficient structure for a modular multiplier for RNS[J].IEEE Transactions on Computers,2000,49 (2):170-174.
[5]LI L,HU J,CHEN Y.An universal architecture for designing modulo(2n-2p-1)multipliers[J].Ieice Electronics Express,2012,9(3):193-199.
[6]LI L,LI S,YANG P,et al.Booth encoding modulo(2n-2p-1)multipliers[J].Ieice Electronics Express,2014,11(15).
[7]YAN H,LI L,ZHANG Q.A high speed modulo(2n-2p+1) multiplier design[J].Ieice Electronics Express,2015,12(23).
[8]OKLOBDZIJA V G,VILLEGER D,LIU S S.A method for speed optimized partial product reduction and generation of fast parallel multipliers using an algorithmic approach[J]. IEEE Transactions on Computers,1996,45(3):294-306.
A high speed modulo(2n-2p-1)multiplier design
Zhang Qingyu,Li Lei
(Research Institute of Electronic Science and Technology,University of Electronic Science and Technology of China,Chengdu 611731,China)
Based on the features of residue number systems(RNS)and modular multipliers,a high speed architecture which is more suitable for design high speed modulo(2n-2p-1)multipliers is proposed.Leveraging the novel partial production reduction tree,we eliminate the complicated correction components which is introduced to correct negative number without performance loss.On the other hand,At the cost of two Carry Save Adders(CSAs)on the critical path,we reduce the delay of a 2n-bit binary adder. Compared with the current modulo(2n-2p-1)multipliers,synthesized results in which based on 90 nm process technology demonstrate that the proposed(2n-2p-1)multipliers can achieve a 10.4%~49%delay saving.
residue number systems(RNS);residue set extending;partial production reduction tree
TN402
A
10.16157/j.issn.0258-7998.2016.11.037
张清宇,李磊 .一种高速模(2n-2p-1)乘法器的设计[J].电子技术应用,2016,42(11):137-140.
英文引用格式:Zhang Qingyu,Li Lei.A high speed modulo(2n-2p-1)multiplier design[J].Application of Electronic Technique,2016,42(11):137-140.
2016-08-02)
张清宇(1990-),男,硕士研究生,主要研究方向:专用集成电路(ASIC)和SOC设计。
李磊(1983-),男,博士,副研究员,主要研究方向:专用集成电路(ASIC)和SOC设计。
猜你喜欢
宁波大学学报(理工版)(2022年6期)2022-12-01
东莞理工学院学报(2022年5期)2022-11-02
小型微型计算机系统(2021年12期)2021-12-08
科学技术创新(2020年25期)2020-08-11
网络安全与数据管理(2017年4期)2017-03-10
中学生数理化·七年级数学人教版(2016年8期)2016-12-07
光学精密工程(2016年2期)2016-11-07
初中生世界·七年级(2016年9期)2016-10-09
初中生世界·七年级(2016年9期)2016-10-09
通信技术(2014年3期)2014-02-09
