
基于伪反馈的有效XML查询扩展*
2016-12-19 01:12钟敏娟万常选刘德喜江腾蛟刘爱红
计算机与生活 2016年12期
钟敏娟,万常选,刘德喜,江腾蛟,刘爱红
1.江西财经大学 信息管理学院,南昌 330013
2.江西财经大学 数据与知识工程江西省高校重点实验室,南昌 330013
基于伪反馈的有效XML查询扩展*
钟敏娟1,2+,万常选1,2,刘德喜1,2,江腾蛟1,2,刘爱红1,2
1.江西财经大学 信息管理学院,南昌 330013
2.江西财经大学 数据与知识工程江西省高校重点实验室,南昌 330013
ZHONG Minjuan,WAN Changxuan,LIU Dexi,et al.Effective XML query expansion based on pseudo relevance feedback.Journal of Frontiers of Computer Science and Technology,2016,10(12):1673-1682.
伪反馈(pseudo relevance feedback,PRF)一直以来都被认为是一种有效的查询扩展技术。然而传统的伪反馈容易带来主题漂移,从而影响检索性能。如何确定高质量的相关文档集,以及如何从相关文档集中挑选有用的扩展词项,是解决伪反馈中查询主题漂移的两个重要方面。对此,针对XML(extensible markup language)文档,提出了一个解决框架:一方面,研究了XML伪反馈文档查找方法,在充分考虑XML内容和结构特征的前提下,提出了基于检索结果聚类和两阶段排序模型相结合的高质量XML伪相关文档查找技术;另一方面,针对CO(content only)查询,对词项扩展进行了研究,提出了带结构语义的词项权值计算方法。一系列的相关实验数据表明,所提的XML伪反馈查询扩展方法能有效地减少查询主题漂移现象,获得更好的检索质量。
XML伪反馈;检索结果聚类;排序;查询扩展
1 引言
XML(extensible markup language)文档的大量涌现,产生了对XML数据管理的需求,基于XML的信息查询和检索成为研究重点[1-2]。其中,如何有效获取高质量的检索结果,提高最终检索性能一直是学术界和工业界致力解决的热点问题。然而,搜索引擎中用户提交的短小查询往往不能准确地描述自己的查询意图,使得返回结果里包含了大量无关的文档。伪反馈是提高信息检索性能的有效查询扩展技术,其不需用户参与的特性在众多查询扩展方法中备受关注。查阅XML伪反馈的相关文献资料,大部分的研究成果都是针对传统文本的伪反馈。
传统伪反馈以初始检索结果的前N篇文档作为查询词的扩展源,其隐含前提假设该N篇文档与查询是相关的。多方的实验数据也证实了该方法的有效性。但是近年来的研究表明,基于传统伪反馈的查询扩展方法容易产生“查询主题漂移(query drift)”现象。究其原因,伪反馈的隐含假设并不总是成立的,检索结果的前N篇文档有可能与查询主题并不相关,从不相关的文档中提取扩展信息显然会引入更多的噪音。因此,如何有效避免“查询主题漂移”现象需要从以下两方面着手:
(1)去除反馈源的噪音,获取高质量的相关文档集。传统伪反馈以初始检索结果的前N篇文档作为伪相关文档集。而实际情况是,该N篇文档与查询的相关性并不纯净,有时包含着大量的噪音。比如,有些查询本身比较歧义或者模糊,造成初始结果的前N篇里存在大量无关文档的现象,而后续的查询扩展基于此不相关的文档集显然会产生主题漂移,反而性能下降。因此,如何在初始检索结果里有针对性地挑选出相关文档,并基于此形成较高质量的伪相关文档集是避免“查询漂移”的首要关键问题。
(2)在获取较高质量反馈源的基础上,从中挑选扩展信息。对XML文档而言,扩展信息的特征选择不仅要考虑传统的内容特征,还要专门针对XML的结构特性。
对于如何确定相关文档,现有工作主要存在两种解决思路:一种是提出相应特征来衡量反馈文档的质量[2-4],或是借助机器学习方法[5-6]来保证反馈文档的质量;另一种解决思路是通过初始检索结果聚类进行取样与重取样,从而提高伪相关文档质量[7-10]。比如,Sakai等人[7]提出了基于取样的伪相关文档选择标准,对前N个返回文档进行筛选。Lee等人[8-9]提出了基于聚类分析的重新取样方法来更好地选择伪相关文档。Bashir[10]针对专利文档,提出了一种改进的聚类方法用于确认好的伪相关文档,提高了文档的检索率。
对于扩展词项的挑选,查询扩展往往基于各种不同的检索模型。经典概率模型里,扩展词项主要依据Roberton/Sparck-Jones权重[11]挑选。近年来,语言模型也应用到查询扩展技术中,比如基于混合模型的反馈方法[12]、基于相关模型的反馈方法[13]等。Cao等人[14]在混合模型的基础上提出了选择好词项的特征,比如词项之间的共现率、词项的距离信息等。文献[15]对相关模型进行了扩展,提出利用词项的位置信息作为线索来推断词项是否与查询主题相关。在国内,许多研究学者在Rocchio框架下也提出了伪反馈的查询扩展方法。丁国栋等人[16]基于词项与所有查询词在局部文档集合中的共现程度来挑选较高质量的扩展词。黄名选等人[17]提出基于矩阵加权关联规则挖掘的查询扩展方法。
上述工作中伪反馈所处理的数据对象都是普通文本,并没有专门针对XML格式的文档。纵观目前的研究成果,基于XML文档的伪反馈研究成果极少,现存的少数几篇论文都是相关反馈模型。为此,本文基于XML文档,针对伪反馈中存在的“查询主题漂移”问题展开研究,力图通过有效的查询扩展来避免或减少“查询主题漂移”的次数,从而最终实现提高XML检索整体性能的目的。
本文的主要贡献如下:
(1)提出了基于检索结果聚类和相关排序机制相结合的高质量XML伪相关文档查找策略。该策略与现有方法不同,不仅通过聚类将主题相似的文档聚簇在一起,而且能在此基础上充分利用聚类结果的相应特征,融入到所提排序模型中,从而获得更高质量的伪相关文档集。
(2)有效地减少了XML伪反馈中存在的“查询主题漂移”现象。一方面,通过检索结果聚类和有效的排序机制,获得了较高质量的扩展源;另一方面,结合XML文档的结构特性,基于所获取的XML伪相关文档扩展源,提出了带结构语义的查询词扩展方案,从中挑选出与初始查询语义相关的扩展词项,最终有效地提高了检索系统的检索质量。
(3)大量的实验验证了所提方法的有效性。一方面,实验数据表明基于检索结果聚类和相关排序机制相结合的XML伪反馈文档查找方法是行之有效的,相比传统的伪反馈方法,初始检索结果聚类有益于获取更高质量的XML伪相关文档集,有效地确保了扩展源的质量;另一方面,所提的查询词扩展方案能有效提高XML文档信息检索的质量,减少“查询主题漂移”现象,并最终获得较高的平均准确率和MAP(mean average precision)。
2 基于检索结果聚类的高质量XML反馈文档查找
有效避免“查询主题漂移”的首要关键问题是挑选与查询需求相关的文档,并汇聚在一起形成高质量的伪相关反馈文档集。
本文提出了高质量XML伪相关文档查找策略。其核心思想是借助聚类和相关排序机制共同对初始检索结果集进行取样与重取样,从而将与查询需求相关的文档查找出来,作为查询词的扩展源。聚类采用k-mediod方法实施,具体思路可参考文献[18],在此不再重述。相关排序机制主要基于文献[19]中提出的策略,包含候选簇的排序和候选簇中文档的排序两个阶段。通过两阶段的排序,挑选出N个相关文档组成伪相关文档集合,并以此作为后续查询词的扩展源。
2.1 候选相关簇的排序模型
初始检索结果聚类实现了文档的主题聚簇划分,也就是说,各个文档按照主题内容划分到了不同的簇中。本文的目的是要形成高质量的伪相关文档反馈源,因此任务并未结束,还需要对聚类结果进行后续的分析处理。其中第一个任务就是从众多的簇中挑选出候选的相关簇。考虑到相关文档可能分布在多个不同的簇中,相关簇的个数应该设置为多个,而不仅仅是单个。
最佳状态下,如果某个簇中包含的文档都是相关文档,则该簇应该是相似程度最高的簇,也理应被选为候选的相关簇。在前述的检索结果聚类中,k-mediod聚类算法会产生k个中心点,为此,利用这k个中心点与查询的相似性对簇进行选择。因为簇的中心点在一定程度上能够表征整个簇。通过相似性的计算,对各个簇进行排序,排在前N位的簇即为候选的相关簇。相似性计算基于文献[20],公式如下:
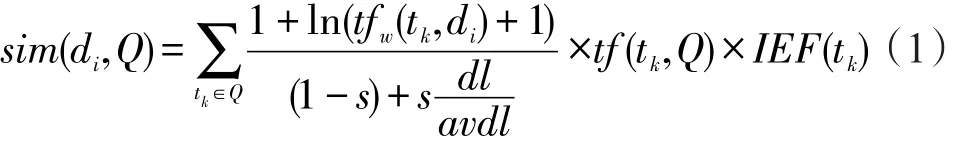
其中,tf(tk,Q)表示词项tk在查询Q中的出现频率;s是一个实验参数(通常取0.2);dl是簇中心文档di的长度;avdl是数据集中文档的平均长度;tfw(tk,di)表示词项tk在簇中心文档di中的权重频率,如下所示:

2.2 基于候选簇的文档排序模型
候选的相关簇敲定之后,接下来第二个任务就是从候选簇中确定与查询需求相关的文档。此过程实质就是对相关簇中的所有文档进行相似性计算,根据相似程度来排序。排序越靠前,说明与用户的查询意图越相关,越是反馈源中需要获取到的文档。因此,需要利用一些特征来表征查询需求的相关性,从而帮助相关文档的挑选。本文提出了以下几个特征:
(1)相关度值(R_Score)。在传统信息检索领域,相关度值表示与查询主题的相关程度,值越大,说明与用户的查询越相关,从而越应该被挑选为反馈源中的文档。
(2)与簇的相似性(Cluster_Sim)。挑选出的候选相关簇并不是一个纯相关簇,也就是说,该相关簇中既包含有高质量的相关文档,同时也存在不相关的噪音文档。因此,要尽可能地过滤掉这些噪音文档。根据前面基于簇中心的候选簇挑选方法,相关簇的簇中心应该与查询主题相关。为此,在挑选相关文档时,不仅要考虑该文档本身与查询主题的相关程度,还要考虑该文档与整个簇的相关性,即与簇中心的相关性。对于簇中心的衡量,可以借助簇标签来表征。文献[19]提出了均衡化权值的簇标签获取方法。簇标签和文档均可看成由中心词项所构成的向量。对于有n个不同中心词项的系统,簇标签ci可以表示为ci=(ti1,ti2,…,tin),文档dj也可以表示为dj= (tj1,tj2,…,tjn),利用两者之间的距离可以衡量文档与簇的相似性。
(3)所在簇的相对排名(Cluster_RValue)。在前述的候选相关簇排序模型中,多个候选相关簇按照相关程度依次排序,因此其排名也体现了该簇整体与查询意图的相关程度。候选文档隶属于候选簇中,假如该候选文档所在的候选簇排名越靠前,说明该簇所包含的文档在一定程度上与查询相关的概率越大。因此,利用其所在的候选簇的相对排名能间接地反映与查询的相似程度。
综合以上分析,定义伪相关反馈文档的评价公式为如下形式:

其中,R_Score(di,Q)代表文档di与用户查询Q的相似度,采用式(1)中基于PNW模型的计算方法。Cluster_RValuei表示文档di所在簇的相对排名,公式定义如下:

ClusterNum表示聚类结果中簇数;Ri表示文档di所在簇在所有簇中的排名位序。
3 XML查询词扩展
查询扩展中,研究者往往利用词项的权值来挑选扩展词项。区别于传统文档,XML文档具有内容和结构的双重特性,特别是结构特性会对扩展词的挑选产生影响。因此,需要将XML文档表征出的结构特点反映到词项的权重计算中。分析XML文档的表示模型,需要考虑以下几个方面因素:
(1)词项的元素频率。类似于传统信息检索中的词项频率,词项在某标签元素下出现的频率次数越多,说明该词项越重要,是该标签片段的中心词项。
(2)词项的反比元素频率。与经典信息检索中的反比文献频率相类似,反比元素频率反映了词项的通用性和普遍性特点。如果很多标签片段下面都涵盖有某词项,说明该词项很一般,不能用来区分各个标签片段。
(3)词项隶属元素的标签节点语义权重。在经典信息检索中,词项出现在文档的不同位置,其对文档的贡献程度是不同的。在XML文档里,不同的位置信息表现为不同的标签节点。比如,同一个词项既出现在标签节点“abs”(摘要)里,也出现在标签节点“title”(标题)中,显然出现在“title”标签下面的词项比出现在“abs”标签下的词项更为重要,因为title标签节点的语义权重高于“abs”标签节点的语义权重。
(4)词项隶属元素节点的路径距离。直观上认为,在XML文档的表示模型中,元素节点到根节点的距离越远,包含在此元素节点下面的词项对整篇文档内容的贡献程度越小,反之越大。因此,对同一标签而言,路径距离小的元素中词项的权重要大于路径距离大的元素中词项的权重。
综合上述分析,词项权值计算采用如下公式:
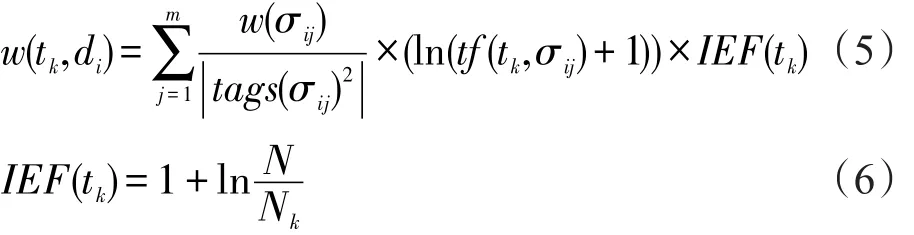
其中,σij表示文档di中第 j个标签节点;w(σij)是标签σij的节点语义权重;tf(tk,σij)表示词项tk在标签σij下出现的频率;tags(σij)表示标签节点σij与根节点的路径距离;m表示文档di中词项tk出现的叶子节点数目。IEF(tk)表示词项tk的反比元素频率;N为整个数据集中元素节点的个数;Nk是包含词项tk的元素节点个数。从中选择权重最大的几个词项作为候选查询扩展词。
4 实验与分析
本文实验是通过伪反馈对用户的初始查询进行扩展,并力图减少或者避免伪反馈中存在的“查询主题漂移”现象,从而提高检索质量。实验数据采用INEX 2005提供的IEEE CS数据集,该数据集体现了以文档为中心的特点,并针对不同的主题(topic)给出了官方的评价标准,对数据集中的相关文档进行了标记。本实验根据每个主题的描述,对29个官方主题全部进行了查询构造,在文献[18]检索结果聚类的基础上从两大方面展开实验:一是检验本文所提方法是否获得了较高质量的XML伪相关反馈文档集;二是评价本文所提的伪反馈查询扩展方法是否能提高XML检索的性能,获得更高质量的检索结果,并能有效避免或解决传统伪反馈中存在的“查询主题漂移”现象。
4.1 XML反馈源的质量检测
本文首先对XML伪相关反馈文档集的质量进行了验证,分别比较了传统伪反馈的扩展源(traditional pseudo relevance feedback,TPRF)和本文提出的基于检索结果聚类和相关排序机制相结合的扩展源(clustering with structure and two ranking,CSTR_Method)的相关性质量。
4.1.1 排序模型中的参数优化
本文所提扩展源方法中利用了候选相关簇的排序及候选簇中文档排序两个阶段。在文档的排序过程中,从式(3)可以看出,文档与查询条件的相关度值和文档与所属簇的相似度两个因素对文档的最终排序起着不同程度的作用,因此首先对模型中不同的参数取值进行了优化测试。实验中采用逐步添加法,即以文档与查询条件的相似度因素为基准,每次变化0.1,多次的实验结果如表1和表2所示。
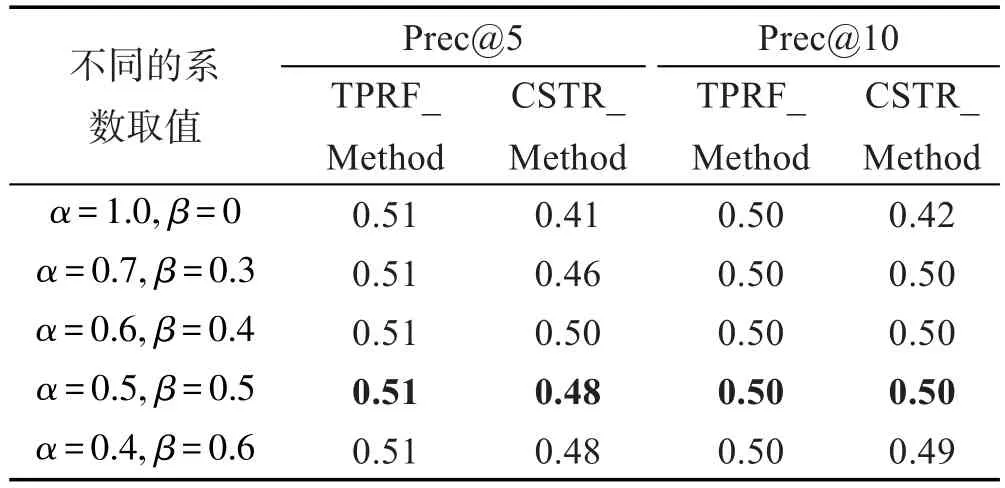
Table 1 Coefficient value and their performance results表1 系数取值及其性能结果(Prec@5、Prec@10)

Table 2 Coefficient value and their performance results表2 系数取值及其性能结果(Prec@15、Prec@20)
从表中可以得出以下结论:
(1)文档与查询条件的相似性和文档与簇的相似性共同对文档的最终评价值起作用。数据显示随着文档与簇的查询条件因素参与到评价值里,查准率逐渐增大,说明相关文档越来越多地排列在前。
(2)随着文档与簇的相似度因素权重值的增大,查准率逐渐提高,一直到两者因素平衡(α=0.5, β=0.5)时达到峰值,随后,随着此因素权重值的进一步加大,性能反而呈下降趋势。
(3)为了挑选出更多高质量的反馈文档,依据表中的数据,选择α=0.5,β=0.5而不是α=0.6,β=0.4作为最优解。后续的查询扩展也是在α=0.5,β=0.5所获得的文档里进行。
4.1.2 扩展源的相关性质量检测
对比传统伪反馈的扩展源和本文方法的扩展源,表1和表2的数据表明,在参数最优解的情况下(α=0.5,β=0.5),本文提出的检索结果聚类和相关排序相结合的扩展源具有更高的质量。一方面检索结果聚类可以首先将文档中大部分的相关文档在一定程度上聚簇在一起;另一方面,两阶段的排序机制在前述聚类基础上相继进行相关簇的选取和簇中相关文档的挑选,两方面的有效实施共同保证了反馈源的质量。而比较传统伪反馈,仅仅简单地认为前N篇文档是相关的,并作为扩展源。显然,前者更能保证选取文档的相关性质量。相关的数据表明,在Top@15以及Top@20的条件下,Prec@15和Prec@20性能分别提高了7%。与此同时,Top@5的条件下,Prec@5的平均精度不如传统伪反馈结果,说明有些相关文档尽管被挑选出来,但是并没有排序在前。分析原因,排序机制起着至关重要的因素。
(1)候选簇的选择问题。排序机制的第一阶段是选择相关簇,在此采用了簇中心文档与用户查询的相似度值来确定。簇中心文档是k-mediod聚类算法的结果,与聚类质量息息相关。假如聚类效果并不理想,则簇中心文档可能会偏离查询主题,这样会把带有噪音的候选簇给挑选出来,从而严重影响后续的相关文档排序,使得很多相关文档无法查找出来。
(2)相关文档排序模型中特征的选择问题。排序模型中,文档相关度评价值仅仅建立在查询词的频率基础上,并没有过多地考虑词项上下文等其他因素,因此挑选出的文档有可能与用户的查询意图并不相关,尽管该文档中某些查询词项出现次数较多。比如查询主题202(hidden Markov model),查找结果并不令人满意。深入分析原因,发现排序在前的文档大部分都包含了多次model词项,而考察这些文档内容,发现它们并不是关于hidden Markov方面的model,从而与用户的查询需求不相符合,造成查准率降低。
4.1.3 聚类对反馈文档查找的影响
扩展源的相关性质量检测实验中,可以清晰地看出本文方法获取的扩展源具有更高的质量,能够查找出更多的相关文档。究其原因,此性能的获取是检索结果聚类和排序这两方面因素造成的。在此,本文对聚类在反馈文档查找中的影响进行了实验分析,验证了聚类对高质量相关文档查找的影响。实验的目的不在于衡量聚类算法本身的性能,而主要验证通过聚类这种手段是否能够帮助查找到高质量的反馈文档以及更多数量的高质量反馈文档。
因此,本文对初始检索结果的前100篇文档重新进行了相似度计算,并对此进行排序,在相同文档数目的前提下,比较聚类前后相关文档的准确率。从表3的数据可以看出,聚类后排在前N的文档里相关文档数目要比聚类前的相关文档数目多,在Prec@10以及Prec@20指标上,平均查准率分别提高了11.1%和15.8%,因此获得了较好的性能。事实上,在相似度计算中,聚类利用了文档与簇的相似度以及文档所在簇的排名等聚类才能拥有的特征,这些特征能有效地帮助查找到更多相关文档,并且使得它们能够尽可能地排序在前。这充分说明了聚类能够有效地帮助查找到更多的高质量反馈文档,对有效避免伪相关反馈中的查询主题漂移奠定了前提基础。

Table 3 Average precision comparison between before and after clustering表3 聚类前后反馈文档平均查准率性能比较
4.2 查询关键词的扩展
实验主要考察在前述较高质量反馈源的前提下,本文基于XML文档结构特性的查询词扩展方案能否提高XML文档检索的质量。实验分3组进行。
第一组实验是将本文方法得到的扩展词项的检索结果与未进行扩展的用户初始查询(orginal query method,OQ_Method)的检索结果进行比较,得到性能比较图,如图1和图2所示。

Fig.1 Performance comparison on Prec@X图1 Prec@X性能比较图
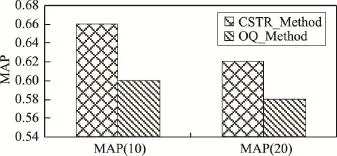
Fig.2 Performance comparison on MAP@X图2 MAP@X性能比较图
从图1和图2的数据可以明显看出,相比初始的查询结果,本文方法在性能指标Prec@X和MAP上具有更好的性能。说明此查询扩展是有效的,获取的扩展词与用户的查询意图较为吻合。扩展词与用户查询词之间具有较为接近的语义。
第二组实验是验证本文方法是否有效解决了传统伪反馈中“查询漂移现象”,比如查询漂移次数是否减少了。对此,将传统伪反馈的查询扩展方法(TranditionNoStructure method,TNS_Method)与本文方法进行了对比。同时,为了保证实验的一致性和公平性,设定扩展源文档数目均取值为20,查询词扩展都基于TFIDF方案进行,将所得的扩展词项和初始查询一同提交给同一搜索引擎,比较返回结果中前10和前20位文档的准确率,实验性能比较结果如图3和图4所示。
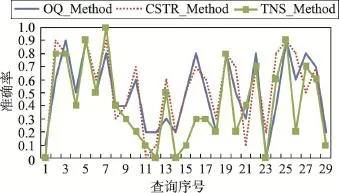
Fig.3 Performance comparison on Prec@10图3 性能比较图(Prec@10)

Fig.4 Performance comparison on Prec@20图4 性能比较图(Prec@20)
从图3和图4中数据可以看出,传统伪反馈的查询扩展方法显然产生了主题漂移,29个官方查询主题中17个查询主题的准确率相比扩展前的初始查询反而降低。而观察本文的扩展方法,在返回结果的前10篇和前20篇文档里,分别只有11和6个查询主题的准确率低于扩展前,这充分说明了本文的扩展方案减少了查询漂移现象,在Prec@10和Prec@20上性能分别提高了4%和15%,整体的检索质量得到了提高。
分析原因,扩展源的质量至关重要。传统伪反馈是选择初始检索结果的前N篇文档作为扩展源,此扩展源并非每次都包含有较多的相关文档,当用户查询需求比较模糊的时候,得到的检索结果可能会包含有较多的噪音,显然在此环境下进行查询词扩展必然会导致性能下降。对比本文提出的CSTR_ Method方法,该方法通过检索结果聚类和两阶段的相关排序机制在一定程度上比传统伪反馈更能保证扩展源的质量,使得挑选出的文档与查询需求更为接近,且数量也较多,为进一步查询扩展保证了源头质量。查询扩展在这种相对比较好的环境下进行,必然比传统伪反馈获得更好的检索性能。
扩展源的质量得到保证之后,要获得好的检索质量,接下来还需要挑选好的扩展词项。在充分考虑XML文档结构特性的基础上本文提出了带结构语义的词项权值扩展方法。
第三组实验主要检验结构在查询扩展方案中的影响和作用。为了更加公平地测试,扩展源必须保证相同。为此,实验分两批进行:第一批实验在本文所获得的扩展源里进行,即经过检索结果聚类和两阶段的排序后选择前20篇文档组成伪相关文档集合,扩展词项的权重分别采取带结构的计算策略(CSTR_Method)与不带结构的计算方法(CNSTR_ Method)。第二批实验的扩展源基于传统伪反馈,即初始检索结果的前20篇文档,扩展词项的权重依然分别采取带结构的计算策略(TS_Method)与不带结构的计算方法(TNS_Method),实验性能比较结果如表4所示。
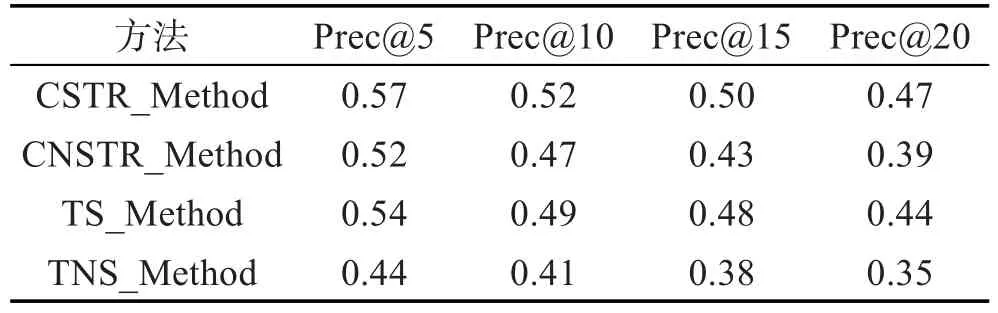
Table 4 Performance comparison表4 性能比较
表4中数据显示,相同扩展源的前提下,考虑XML文档结构因素的扩展策略比不考虑结构的方法所获得的性能普遍要好,体现在Prec@10和Prec@20性能指标上,CSTR_Method方法比CNSTR_Method方法平均查准率分别提高了9.6%和17%,带结构的传统伪反馈(TS_Method)方法比不带结构的伪反馈(TNS_Method)方法平均查准率分别提高了16%和20%。这说明结构特性能帮助挑选到更好的扩展查询词,从而带来更好的检索质量。
综合上述3组实验,汇总如下性能比较结果。本文所提方法(CSTR_Method)总的性能高于其他方法。通过前面一系列的实验与分析,把原因归结为以下两大方面:
(1)高质量的扩展源。这是查询扩展的首要因素。假如扩展源的质量不高,在此集合里挑选出的扩展词项就会和用户的真实查询意图相差较远。比如传统伪反馈,因为扩展源噪音太大,所以最终产生主题漂移。为此,在本文的扩展方案里,首先对检索结果聚类,并对聚类结果进一步分析,通过两阶段排序机制把与用户查询相关的文档聚簇在一起,从而在一定程度上先保证了扩展源的相关性。
(2)扩展词项的选择。好的扩展词项能带来最终检索性能的提高。为此,需要合理制定相应的挑选准则。在上述的实验中,综合考虑了XML文档的多个结构因素,提出了带结构语义的查询词扩展方案,相比不考虑结构特性的扩展词项挑选准则而言,能更好地挑选出相关扩展词,表5中Prec@10、Prec@ 20以及MAP指标上的数据充分说明了这一点。
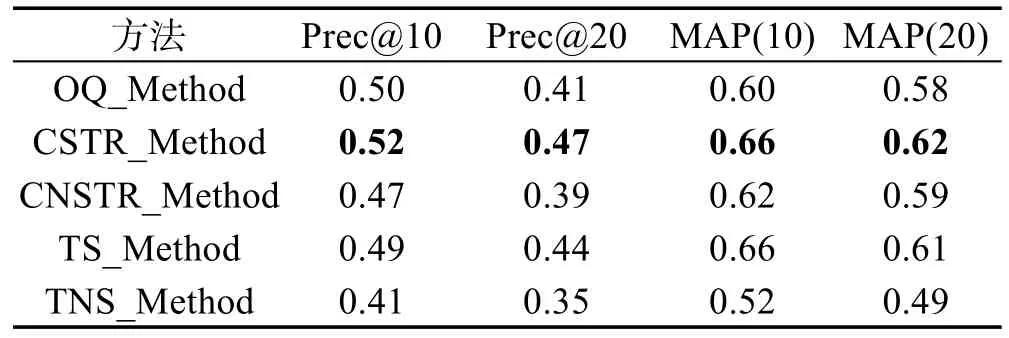
Table 5 Overall performance comparison表5 总的性能比较
5 结论
针对传统伪反馈中存在的查询主题漂移现象进行了研究,对如何有效避免“主题漂移”提出了系统的解决框架。一方面,提出了检索结果聚类和排序机制相结合的高质量扩展源获取方法;另一方面,在高质量的扩展源里,融合XML文档内容和结构的双重特性,提出了带结构语义的查询词扩展方法。一系列的实验数据表明,整个系统框架的实施能有效提高检索性能,在扩展源的质量检测中,本文方法获得的扩展源具有较高的用户查询相关性,相比传统的伪反馈扩展源,具有更高的质量;与此同时,结合了XML结构特点的查询扩展方案能获得与用户查询意图更为相关的扩展信息。高质量的扩展源和有效扩展信息的获取使得查询主题漂移现象得到了控制和减少,更有效地提高了搜索引擎的检索性能。
[1]Huang Qiang,Song Dawei,Rüger S.Robust query-specific pseudo feedback document selection for query expansion [C]//LNCS 4956:Proceedings of the 30th European Conference on Information Retrieval,Glasgow,UK,Mar 30-Apr 3, 2008.Berlin,Heidelberg:Springer,2008:547-554.
[2]He Ben,Ounis I.Finding good feedback documents[C]// Proceedings of the 18th ACM Conference on Information and Knowledge Management,Hong Kong,China,Nov 2-6, 2009.New York:ACM,2009:2011-2014.
[3]Ye Zheng.The research of machine learning techniques and external Web resources for relevance feedback[D].Dalian: Dalian University of Technology,2011.
[4]Raman K,Udupa R,Bhattacharya P,et al.On Improving pseudo-relevance feedback using pseudo-irrelevant documents [C]//LNCS 5993:Proceedings of the 32nd European Conference on Information Retrieval,Milton Keynes,UK,Mar 28-31,2010.Berlin,Heidelberg:Springer,2010:573-576.
[5]Lv Yuanhua,Zhai Chengxiang,Chen Wan.A boosting approach to improving pseudo-relevance feedback[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval,Beijing,Jul 25-29,2011.New York:ACM,2011:165-174.
[6]Zhou Dong,Truran M,Liu Jianxu,et al.Collaborative pseudorelevance feedback[J].Expert system with Application,2013, 40(17):6805-6812.
[7]Sakai T,Manabe T,Koyama M.Flexible pseudo-relevance feedback via selective sampling[J].ACM Transactions on Asian Language Information Processing,2005,4(2):111-135.
[8]Lee K S,Croft W B,Allan J.A cluster-based resampling method for pseudo-relevance feedback[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Singapore,Jul 20-24,2008.New York:ACM,2008:235-242.
[9]Lee K S,Croft W B.A deterministic resampling method using overlapping document clusters for pseudo-relevant feedback [J].Information Processing&Management,2013,49(4): 792-806.
[10]Bashir S.Improving retrievablity with improved clusterbased pseudo-relevance feedback selection[J].Expert System withApplication,2012,39(8):7495-7502.
[11]Robertson S E,Jones K S.Relevance weighting of search terms[J].Journal of the American Society of Information Science,1976,27(3):129-146.
[12]Zhai Chengxiang,Lafferty J D.Model-based feedback in the language modeling approach to information retrieval [C]//Proceedings of the 13th ACM International Conference on Information and Knowledge Management,Atlanta, USA,Nov 5-10,2001.New York:ACM,2001:403-410.
[13]Lavrenko V,Croft W B.Relevance-based language models [C]//Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,New Orleans,USA,Sep 9-13,2001.New York:ACM, 2001:120-127.
[14]Cao Guihong,Nie Jianyun,Gao Jianfeng,et al.Selecting good expansion terms for pseudo-relevance-feedback[C]// Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Singapore,Jul 20-24,2008.New York:ACM, 2008:243-250.
[15]Lv Yuanhua,Zhai Chengxiang.Positional relevance model for pseudo-relevance feedback[C]//Proceedings of the 33rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Geneva,Swizerland,Jul 19-23,2010.New York:ACM,2010:579-586.
[16]Ding Guodong,Bai Shuo,Wang Bin.Local co-occurrence based query expansion for information retrieval[J].Journal of Chinese Information Processing,2006,20(3):84-91.
[17]Huang Mingxuan,Yan Xiaowei,Zhang Shichao.Query expansion of pseudo-relevance feedback based on matrixweighted association rules mining[J].Journal of Software, 2009,20(7):1854-1865.
[18]Zhong Minjuan.Clustering XML search results based on content and structure of semantic integration[J].Journal of China Society for Scientific and Technical Information,2012, 31(5):515-525.
[19]Zhong Minjuan,Wan Changxuan,Liu Dexi,et al.FindingXML pseudo-relevance document based on search results clustering[J].Journal of Computer Science,2013,40(10): 172-177.
[20]Singhal A,Choi J,Hindle D,et al.AT&T at TREC-7[C]// Proceedings of the 7th Text Retrieval Conference,Maryland,Gaithersburg,Nov 9-11,1998:239-252.
附中文参考文献:
[3]叶正.基于网络挖掘与机器学习技术的相关反馈研究[D].大连:大连理工大学,2011.
[16]丁国栋,白硕,王斌.一种基于局部共现的查询扩展方法[J].中文信息学报,2006,20(3):84-91.
[17]黄名选,严小卫,张师超.基于矩阵加权关联规则挖掘的伪相关反馈查询扩展[J].软件学报,2009,20(7):1854-1865.
[18]钟敏娟.基于内容与结构语义相融合的XML检索结果聚类[J].情报学报,2012,31(5):515-525.
[19]钟敏娟,万常选,刘德喜,等.基于检索结果聚类的XML伪相关文档查找[J].计算机科学,2013,40(10):172-177.

ZHONG Minjuan was born in 1976.She is an associate professor at Jiangxi University of Finance and Economics, and the member of CCF.Her research interest is information retrieval.
钟敏娟(1976—),女,湖南临湘人,博士,江西财经大学信息管理学院副教授,CCF会员,主要研究领域为信息检索。

WAN Changxuan was born in 1962.He is a professor and Ph.D.supervisor at Jiangxi University of Finance and Economics,and the senior member of CCF.His research interests include data management and data mining,etc.
万常选(1962—),男,江西南昌人,博士,江西财经大学信息管理学院教授、博士生导师,CCF高级会员,主要研究领域为数据管理,数据挖掘等。

LIU Dexi was born in 1975.He is a professor at Jiangxi University of Finance and Economics,and the member of CCF.His research interest is text automatic summarization.
刘德喜(1975—),男,博士,湖南襄樊人,江西财经大学信息管理学院教授,CCF会员,主要研究领域为文本自动文摘。

JIANG Tengjiao was born in 1976.She is a Ph.D.candidate and lecturer at Jiangxi University of Finance and Economics.Her research interests include sentiment analysis and Web data management,etc.
江腾蛟(1976—),女,安徽怀宁人,江西财经大学信息管理学院讲师,博士研究生,主要研究领域为情感分析与Web数据管理等。

LIU Aihong was born in 1971.She is an associate professor at Jiangxi University of Finance and Economics.Her research interest is database technology.
刘爱红(1971—),女,江西南昌人,硕士,江西财经大学信息管理学院副教授,主要研究领域为数据库技术。.
Effective XMLQuery Expansion Based on Pseudo Relevance Feedback*
ZHONG Minjuan1,2+,WAN Changxuan1,2,LIU Dexi1,2,JIANG Tengjiao1,2,LIUAihong1,2
1.School of Information Technology,Jiangxi University of Finance and Economics,Nanchang 330013,China
2.Jiangxi Key Laboratory of Data and Knowledge Engineering,Jiangxi University of Finance and Economics,Nanchang 330013,China
+Corresponding author:E-mail:lucyzmj@sina.com
Pseudo relevance feedback(PRF)has been perceived as an effective solution for automatic query expansion.However,traditional pseudo relevance feedback can result in the query representation“drifting”away from the original query and a decreased retrieval performance.Therefore,the key issues in applying PRF are to identify the real relevant documents in the top retrieved results without any other assistant information,and expend the query based on the these relevant documents.This paper presents a solution framework from extensible markup language (XML)data.Firstly,this paper considers the XML content and structure features,and proposes a good XML query scheme based on pseudo relevance feedback documents by combining search results clustering with a two-stage ranking model.Furthermore,this paper explores the XML query expansion of CO(content only)query,and givesthe term weight computation with structure.The experimental results show that the proposed scheme can reduce the topic drift effectively and obtain the better retrieval quality.
XML pseudo relevance feedback;search results clustering;ranking;query expansion
10.3778/j.issn.1673-9418.1509082
A
TP391
*The National Natural Science Foundation of China under Grant Nos.61363039,61363010,71361012,61562032(国家自然科学基金);the National Social Science Foundation of China under Grant No.12CTQ042(国家社会科学基金);the Natural Science Foundation of Jiangxi Province under Grant Nos.20142BAB217014,20142BAB207010(江西省自然科学基金);the Humanities and Social Science Research Project in Colleges and Universities of Jiangxi Province under Grant No.TQ1504(江西省高校人文社会科学研究规划基金项目).
Received 2015-09,Accepted 2015-11.
CNKI网络优先出版:2015-11-24,http://www.cnki.net/kcms/detail/11.5602.TP.20151124.1430.008.html
猜你喜欢
客联(2022年3期)2022-05-31
苏州科技大学学报(社会科学版)(2022年5期)2022-03-15
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
中国新闻周刊(2021年26期)2021-07-27
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
哲学评论(2018年1期)2018-09-14
信息安全研究(2016年4期)2016-12-01
大家(2011年9期)2011-08-15
